Nvidia has unleashed Nemotron 3 Super, a 120-billion-parameter behemoth that promises to make running AI agents cheaper than a thrift store sweater. Because who doesn’t love saving money while pretending to be a tech genius?
Key Takeaways (For Those Who Skipped the Manual):
- Nemotron 3 Super: 120B parameters, but only 12.7B actually work at a time. It’s like a corporate meeting-lots of people, minimal effort.
- Delivers up to 7.5x more throughput than Qwen3.5-122B-A10B. Because why be fast when you can be that fast?
- Fully open under Nvidia’s license, because sharing is caring, even in the cutthroat world of AI.
The latest Nvidia model is like a lazy genius-it only activates 12.7 billion parameters per forward pass, leaving the rest to nap. This Mixture-of-Experts (MoE) architecture is perfect for developers who want to save on compute costs without admitting they’re cheap. It’s also great for multi-step AI agents, which apparently have a habit of running up the bill like a teenager with a credit card.
Nemotron 3 Super is the second in Nvidia’s Nemotron 3 family, following the slightly less impressive Nemotron 3 Nano. It was announced around March 10, 2026, because nothing says “future” like a press release in the year 2026.
The model uses a hybrid Mamba-Transformer backbone across 88 layers, which sounds like a dance craze but is actually just really efficient. Mamba-2 blocks handle long sequences with linear-time efficiency, while Transformer attention layers keep things precise. It’s like having a marathon runner and a chess champion in the same body.
Nvidia also threw in a LatentMoE routing system, which compresses token embeddings into a low-rank space before sending them to 512 experts per layer. Only 22 experts are activated at a time, because even AI needs to delegate. This allows for finer task specialization, like separating Python logic from SQL handling. Because, you know, multitasking is overrated.
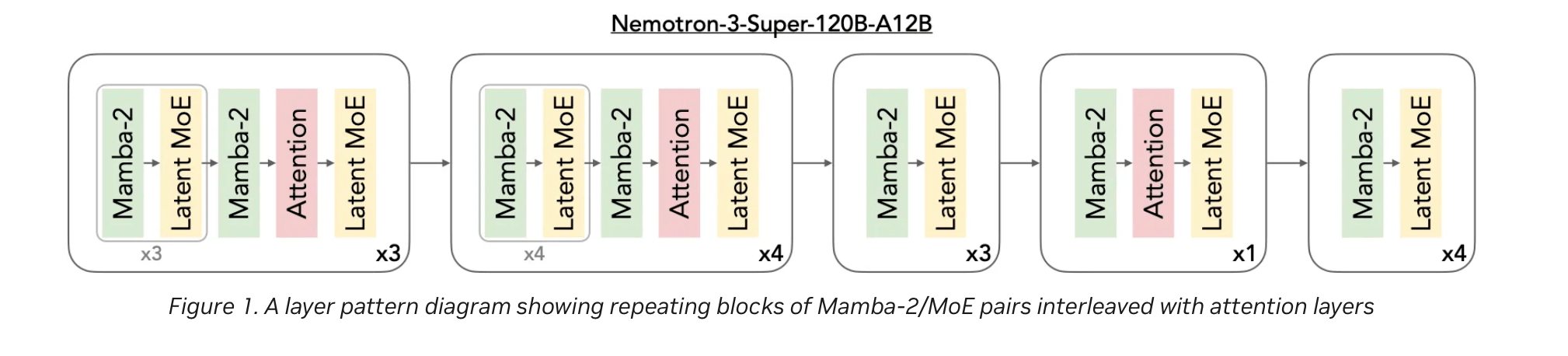
Multi-Token Prediction layers speed up chain-of-thought generation, which is great for when your AI needs to think faster than you do. Nvidia claims it’s up to three times faster on structured tasks, because who has time to wait?
The model was pre-trained on 25 trillion tokens, which is roughly the number of words in every boring meeting you’ve ever attended. It scored impressively on benchmarks like MMLU-Pro, AIME25, and SWE-Bench, because apparently AI needs to prove itself too.
Compared to GPT-OSS-120B, Nemotron 3 Super delivers 2.2 times the throughput. Against Qwen3.5-122B-A10B, it’s 7.5 times faster. It’s like comparing a snail to a cheetah, but with more zeros.
Trained in Nvidia’s NVFP4 format, the model runs up to four times faster on B200 hardware compared to FP8 on H100. Quantized checkpoints retain 99.8% of full-precision accuracy, because even AI needs to look good on paper.
Nemotron 3 Super also powers the Nvidia AI-Q research agent, which topped the Deepresearch Bench leaderboard. Because nothing says “success” like being the best at something no one’s ever heard of.
The model is fully open under the Nvidia Nemotron Open Model License, with checkpoints and data available on Hugging Face. Inference is supported through Nvidia NIM, Google Cloud, AWS, Azure, and more. Because if you can’t access it, does it even exist?
Developers can access training recipes, fine-tuning guides, and inference cookbooks through the NeMo platform. Because even AI needs a good recipe.
Read More
- These Cartoon Reboots Totally Missed the Point of the Originals (& Went Downhill Fast)
- Gold Rate Forecast
- $292M KelpDAO Exploit: LayerZero Uncovers Single-Verifier Flaw in Massive Hack
- Total Football free codes and how to redeem them (March 2026)
- Netflix’s Best Stranger Things Replacement Officially Takes America By Storm
- 6 Animated Movie Trilogies Where Every Entry Is Near-Perfect
- Zenless Zone Zero version 2.8 ‘New: Eridan Sunset’ update will release on May 6, 2026
- Top 5 Best New Mobile Games to play in May 2026
- Maggie Smith’s sons “deeply touched” by huge honour to the late “national treasure”
- STARBUCKS STAND by BEAMS Channels Kenyan Coffee Heritage Into Its Latest Spring/Summer Wardrobe
2026-04-20 06:57