Author: Denis Avetisyan
A new framework empowers robots to understand and perform complex physical tasks in three dimensions by leveraging the power of large language models and multi-agent reasoning.
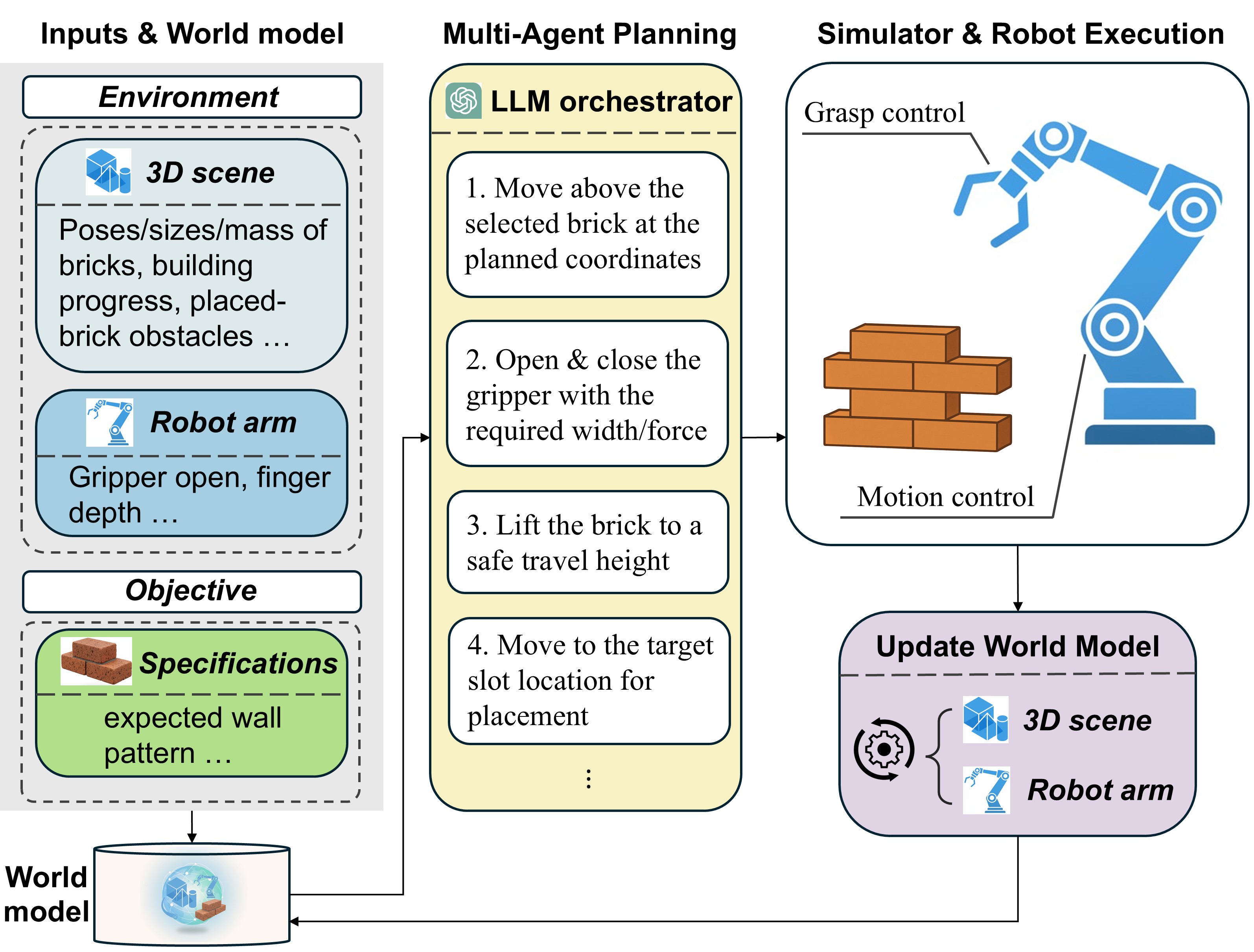
This work introduces ActionReasoning, an LLM-driven system for 3D action reasoning that enhances robot manipulation capabilities in tasks like brick stacking.
Despite advances in robotic control, scaling embodied AI remains challenging due to the difficulty of generalizing across complex, continuous action spaces. This limitation motivates the research presented in ‘ActionReasoning: Robot Action Reasoning in 3D Space with LLM for Robotic Brick Stacking’, which introduces a novel framework leveraging large language models (LLMs) for physics-consistent action planning in 3D space. By structuring LLM-encoded physical priors within a multi-agent architecture, ActionReasoning enables more robust robotic manipulation, demonstrated through stable brick stacking. Could this approach of explicit action reasoning with LLMs unlock broader generalization and reduce reliance on low-level coding in robotic systems?
Beyond the Limits of Pre-Programmed Logic
For decades, robotic control has been fundamentally rooted in meticulously designed, hand-coded behaviors – a paradigm that, while providing predictability, inherently limits a robot’s capacity to adapt. Each movement, each reaction, is pre-programmed by engineers, creating a substantial bottleneck as complexity increases. This approach functions effectively in highly structured environments, but falters when confronted with the unpredictable nuances of the real world. Consider a robotic arm assembling a product; even minor variations in part placement necessitate re-coding. The sheer volume of potential scenarios in dynamic environments quickly overwhelms the ability to anticipate and program for every contingency, hindering true autonomy and creating a critical need for more flexible control architectures.
Classical robot controllers, built on meticulously programmed instructions, demonstrate remarkable reliability in predictable settings, but falter when confronted with the inherent ambiguity of real-world complexity. These systems, though effective in structured environments like assembly lines, struggle to interpret incomplete data, adapt to novel obstacles, or recover from unexpected events. Their limitations stem from an inability to generalize beyond explicitly programmed scenarios; a slight deviation from the expected-a misplaced object, an uneven surface, or an unanticipated interaction-can quickly overwhelm the pre-defined logic. Consequently, these controllers require constant human oversight or re-programming to maintain functionality in dynamic, unstructured environments, highlighting the need for more robust and adaptable approaches to robotic control.
The pursuit of increasingly complex robotic tasks necessitates a fundamental departure from traditional, hand-crafted control systems. While historically, robots have been programmed with explicitly defined behaviors for every conceivable scenario, this approach quickly becomes unsustainable as operational environments grow more dynamic and unpredictable. Scaling robotic capabilities beyond simple, structured tasks requires a transition towards reasoning-based architectures, allowing machines to infer solutions and adapt to novel situations without relying on pre-programmed instructions. This involves integrating techniques like knowledge representation, planning, and machine learning, enabling robots to not merely react to stimuli, but to understand their surroundings and make informed decisions – effectively moving from automation to true autonomy.

Bridging the Intelligence Gap: LLM-Based Robotic Control
LLM-based robot control moves beyond traditional methods by integrating high-level reasoning capabilities into robotic systems. Conventional robotic control relies on pre-programmed responses to specific stimuli or meticulously defined state machines, limiting adaptability in dynamic or unstructured environments. Utilizing Large Language Models (LLMs) allows robots to process complex instructions and contextual information, enabling them to infer intent and formulate actions without explicit programming for every scenario. This approach facilitates improved generalization to novel situations, increased robustness in uncertain environments, and the potential for more natural human-robot interaction by interpreting and responding to language-based commands and queries.
LLM-based robot control systems operate by accepting the current ‘Environment State’ – encompassing sensor data regarding the robot’s surroundings – and pre-defined ‘Robot Waypoints’ as input. The LLM processes this information to generate a sequence of actions intended to navigate the robot towards its designated waypoints while adhering to the constraints imposed by the environment. This contrasts with traditional robotic control which often relies on pre-programmed behaviors or complex, hand-engineered algorithms; the LLM dynamically determines the necessary actions, effectively translating high-level goals – represented by the waypoints – into low-level motor commands. The system’s functionality relies on the LLM’s capacity to interpret the environment state and plan a feasible path, generating actions such as velocity commands, joint angles, or gripper controls to achieve the desired movement.
Chain-of-Thought (CoT) reasoning is a prompting technique used with Large Language Models (LLMs) that encourages the model to explicitly state the intermediate reasoning steps leading to a final answer. Rather than directly outputting an action, the LLM first generates a textual explanation of its thought process, detailing how it interprets the current ‘Environment State’ and ‘Robot Waypoints’ to determine appropriate actions. This articulation of reasoning improves reliability by allowing for external verification of the LLM’s logic and facilitating error detection; furthermore, the detailed reasoning trace can be used for debugging and refinement of the prompting strategy. Empirical results demonstrate that CoT prompting consistently outperforms direct prompting methods in complex robotic control tasks, increasing the accuracy and consistency of generated actions.
Structured prompting is critical for successful LLM-based robot control as it provides the necessary context and formatting for the model to generate appropriate actions. This technique involves constructing prompts with clearly defined sections detailing the current ‘Environment State’ – encompassing sensor data and world observations – and the desired ‘Robot Waypoints’ specifying the goal location or task. Furthermore, effective structured prompts often include explicit instructions regarding the expected output format, such as a sequence of robot commands or a justification for the chosen action, thereby guiding the LLM’s reasoning process and improving the reliability and predictability of its responses. Without this structured input, LLMs may struggle to interpret ambiguous requests or generate actions that are inconsistent with the robot’s operational constraints.

ActionReasoning: Grounding Logic in the Physical World
The ActionReasoning framework addresses limitations of Large Language Models (LLMs) by integrating physical grounding into their operational scope. LLMs, while proficient in language processing, lack inherent understanding of physical constraints and robotic interactions. ActionReasoning bridges this gap by embedding LLM-driven reasoning within a physics-based simulation of the robot’s environment. This allows the LLM to not only generate plans but also to evaluate their feasibility and predict outcomes based on physical principles, effectively translating linguistic commands into executable actions within a 3D workspace. This approach moves beyond purely symbolic planning, enabling LLMs to reason about forces, collisions, and spatial relationships crucial for successful robotic manipulation.
SE(3) reasoning, utilized within the ActionReasoning framework, provides a mathematical formalism for representing and manipulating rigid body transformations in three-dimensional space. This allows the system to model the robot’s pose – position and orientation – and the poses of objects within its environment as elements of the Special Euclidean group [latex]SE(3)[/latex]. By operating within this group, the system can accurately predict the outcomes of actions, such as grasping or placing objects, and plan complex manipulations that require precise geometric reasoning. This capability extends beyond simple kinematic calculations to encompass the physical constraints imposed by the environment and the robot’s morphology, enabling robust and reliable execution of tasks in 3D space.
Physics-based simulation is central to the ActionReasoning framework, providing a predictive model of the robot’s physical interactions. This simulation explicitly models the dynamics of the environment and objects, allowing the system to anticipate the consequences of actions before execution. The ‘Robot Arm’ serves as the primary physical effector within this simulated environment, with its kinematics and dynamics accurately represented. The simulation calculates forces, torques, and resulting motions, enabling the robot to plan trajectories and manipulate objects in a virtual space before transferring those plans to the physical world. This approach facilitates robust performance by mitigating potential errors and ensuring stable interactions with the environment.
Effective contact detection and collision avoidance are essential for robotic manipulation, ensuring both the safety of the robot and the reliability of task execution. The implemented system utilizes these methods to accurately predict and prevent unwanted interactions during operation. Quantitative performance, as demonstrated in a brick laying task, yielded a mean 3D Intersection over Union (IoU) of 0.8803, indicating a high degree of geometric accuracy in the robot’s physical interactions and validating the effectiveness of the contact and collision management strategies.

Decomposition and Collaboration: The Power of Multi-Agent Systems
To address intricate challenges, such as the precise demands of a brick stacking task, the ‘ActionReasoning’ framework employs a sophisticated multi-agent system architecture. This approach diverges from traditional robotic control by distributing the overall problem into a network of specialized agents, each responsible for a specific facet of the task. By enabling these agents to operate concurrently and collaboratively, the system achieves a level of efficiency and adaptability previously unattainable. This decomposition not only streamlines the planning and execution phases but also introduces inherent robustness, as the failure of one agent does not necessarily compromise the entire operation-a key benefit when dealing with the unpredictable nature of physical environments and complex manipulations.
The architecture leverages a strategy called task decomposition, wherein a complex objective-such as assembling a structure-is systematically divided into a series of smaller, more easily achievable sub-tasks. This modular approach isn’t merely about simplification; it enables parallel execution, meaning multiple agents can work on different sub-tasks concurrently, dramatically increasing overall efficiency. By distributing the workload and minimizing sequential dependencies, the system avoids bottlenecks and accelerates the completion of intricate processes. This capability is crucial for real-world applications demanding speed and adaptability, allowing the robotic system to handle dynamic environments and complex challenges with greater agility and precision.
A central component of the multi-agent system is the ‘World Model’, which constructs a unified representation of the environment accessible to all agents. This shared understanding isn’t merely a static map; it’s a dynamic, continually updated reconstruction incorporating perceptions and predicted outcomes of actions. By referencing this common framework, agents can effectively coordinate their efforts, avoiding collisions and redundant actions during task execution. More importantly, the World Model empowers robust planning, as agents can simulate potential trajectories and assess their feasibility before committing to a course of action, greatly enhancing the system’s adaptability to unforeseen circumstances and contributing to precise task completion.
The implemented multi-agent system demonstrably improves robotic precision in complex tasks; evaluations revealed a substantial 30.0% reduction in mean rotation error, measured at 0.703 cm, and an even more pronounced 85.2% decrease in mean center offset error, registering at 0.637 cm, when contrasted with a traditional, classical controller. These gains aren’t merely numerical; they signify a fundamental advancement in a robot’s capacity to not just perform actions, but to reason about them – to understand spatial relationships and adjust accordingly. This capability paves the way for robotic systems that are significantly more versatile, adaptable to unforeseen circumstances, and capable of tackling a wider range of challenges than previously possible.
The pursuit within ActionReasoning-deconstructing the complexities of robotic brick stacking into manageable, reasoned steps-echoes a fundamental principle of understanding any system. It’s akin to reverse-engineering the world, peeling back layers to reveal the underlying code. As Blaise Pascal observed, “The eloquence of angels is no more than the silence of reason.” This framework doesn’t aim to simulate intelligence, but to systematically deduce action through logical decomposition. The multi-agent system, functioning as a distributed reasoning engine, treats reality as open source-a code waiting to be read and manipulated. Each agent’s contribution isn’t about pre-programmed responses, but about interpreting the world model and formulating the next logical step in task completion, mirroring the methodical dismantling of a complex problem.
Beyond the Stack
The current framework, while demonstrating competency in brick stacking, implicitly assumes a static definition of ‘success’. But what if the instability isn’t a bug in the reasoning, but a signal of a more efficient, if unorthodox, structure? The system currently optimizes for a prescribed outcome; future iterations might benefit from allowing the agent to discover outcomes, to explore the solution space beyond pre-defined parameters. This demands a reassessment of reward functions – are they truly incentivizing robust manipulation, or merely reinforcing conformity?
Furthermore, the multi-agent approach, while elegant, raises the question of emergent behavior. How readily can this system adapt when agents develop conflicting, yet logically consistent, strategies? The current focus appears to be on coordination; a more profound challenge lies in harnessing the creative tension of disagreement. True robustness isn’t achieved by eliminating error, but by anticipating and accommodating it.
Ultimately, the limitations aren’t in the mechanics of stacking, but in the very definition of ‘action’. Can this framework be extended to encompass actions that modify the environment, or even the task itself? The next step isn’t simply more bricks, but a system capable of questioning the foundations upon which the tower is built.
Original article: https://arxiv.org/pdf/2602.21161.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-26 03:04