Author: Denis Avetisyan
New research demonstrates how reinforcement learning, guided by human grasping patterns, enables robots to perform complex object manipulation tasks with greater dexterity and intention.

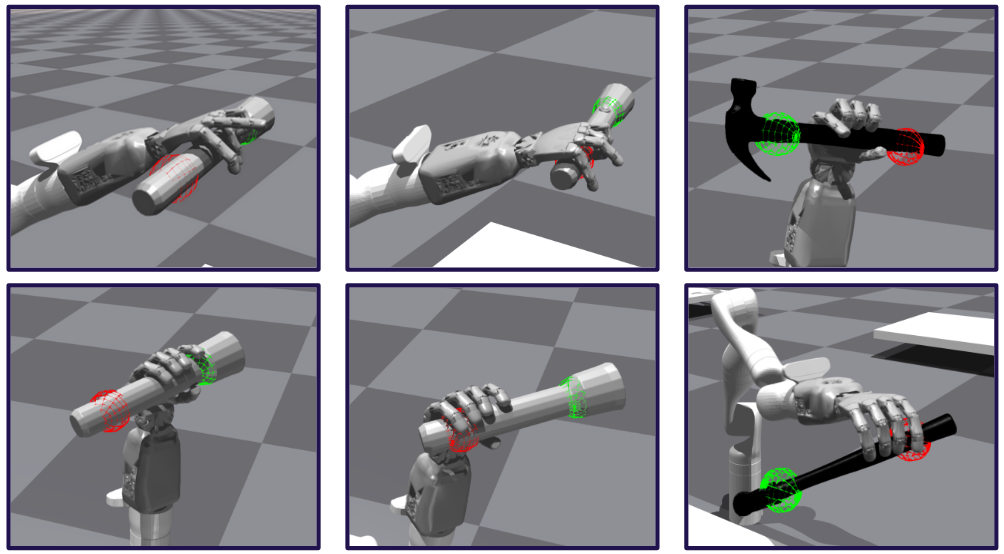
Researchers leverage postural synergies and reinforcement learning to create a grasping agent that anticipates post-grasp actions, improving both object use and handoff capabilities.
Achieving truly adaptive robotic manipulation remains challenging due to the difficulty of aligning grasping strategies with both task objectives and human expectations. This is addressed in ‘Task-oriented grasping for dexterous robots using postural synergies and reinforcement learning’, which introduces a reinforcement learning agent trained to prioritize post-grasp intention while mimicking human grasping behaviors. By leveraging a hand synergy model derived from the ContactPose dataset, the approach enables robots to grasp multiple objects in a manner informed by human preferences and specific downstream tasks. Could this integration of data-driven insights and learning by exploration pave the way for more intuitive and collaborative human-robot interactions in complex environments?
Beyond Simple Grasping: The Illusion of Robotic Dexterity
Conventional robotic grasping systems prioritize the mechanics of achieving a stable hold, often meticulously calculating grip force and trajectory without considering subsequent actions. This approach treats grasping as an isolated event, failing to integrate it with the overall task the robot is intended to perform. Consequently, a robot might successfully pick up an object, but lack the capacity to determine how that object will be used – whether it needs to be placed gently, spun for inspection, or firmly secured for assembly. This limitation necessitates pre-programmed sequences for each potential scenario, hindering the robot’s ability to adapt to unforeseen circumstances or operate effectively in dynamic environments where flexibility and purposeful manipulation are crucial. The focus on ‘how’ instead of ‘why’ ultimately restricts a robot’s potential for true dexterity and problem-solving.
Current robotic systems frequently struggle with unpredictable environments due to a reliance on pre-programmed responses to specific stimuli. This approach severely limits adaptability; when confronted with novel situations or slight deviations from expected parameters, performance degrades rapidly. Instead of reacting to immediate conditions, a truly versatile robot requires the capacity for flexible problem-solving, necessitating an ability to assess the broader context and dynamically adjust its actions. This isn’t simply about faster processing or more complex algorithms, but a fundamental shift away from stimulus-response behavior toward a system capable of anticipating challenges and formulating solutions on the fly – a capacity currently hindered by the lack of contextual understanding in many robotic designs.
Successful manipulation isn’t simply about securing an object; it fundamentally requires predicting what will happen after the grasp. Rather than reacting to an object’s presence, advanced robotic systems necessitate an ability to anticipate the intended use, allowing for the selection of a grasp optimized for subsequent actions. This proactive approach means considering not just the mechanics of holding, but the entire task sequence – will the object be lifted, rotated, assembled, or used as part of a larger process? By prioritizing post-grasp intentions, robotic manipulation moves beyond reflexive actions toward a more fluid and adaptable form of problem-solving, mirroring the efficiency and foresight observed in natural biological systems. This shift allows for choosing from a repertoire of possible grasps, each suited for a specific set of future manipulations, rather than relying on a single, generalized grip.
Current robotic grasping strategies are increasingly recognizing the necessity of moving beyond simply securing an object to considering its subsequent utilization. A fundamental shift is occurring towards task-oriented grasping, where the intended purpose of an object dictates the grasp selection itself. This approach acknowledges that the most effective grasp isn’t necessarily the most stable, but rather the one that best facilitates the actions to follow – whether that’s pouring a liquid, assembling a component, or handing an object to a person. By integrating an understanding of the object’s functional role into the grasping process, robots can anticipate necessary manipulations and proactively choose grasps optimized for those specific tasks, leading to more versatile and adaptable robotic systems capable of true problem-solving in complex environments.

Task-Aware Grasping: Finally, A Reason to Pick Things Up
Task-oriented grasping represents a shift from pre-defined or reactive grasping strategies to a system where the robot’s hand configuration is directly informed by the intended outcome of the manipulation. Traditional robotic grasping often focuses on stability and force closure without considering why an object is being grasped. This approach directly addresses this limitation by formulating grasping as a goal-conditioned problem; the robot doesn’t simply reach for an object, but selects a grasp specifically suited to performing a subsequent task, such as assembly, insertion, or tool use. This intention-aware manipulation allows for more efficient and adaptable robotic systems capable of handling a wider range of objects and tasks compared to systems relying on generalized grasping strategies.
Task-oriented grasping utilizes Reinforcement Learning (RL) to develop policies that directly link task specifications to appropriate grasp configurations. These RL policies are trained through interaction with an environment, receiving rewards based on successful task completion with a given grasp. The input to the policy is a representation of the task – for example, object pose, desired manipulation, or scene context – and the output is a set of control signals that dictate the robot’s hand configuration. Through iterative learning, the policy optimizes the selection of grasps that maximize the probability of successful task completion, effectively mapping high-level task descriptions to low-level motor commands for manipulation.
Synergy Models are integral to the efficiency of task-oriented grasp policies by reducing the complexity of the robot’s control space. Traditional robotic manipulation often involves controlling a high number of joint angles, creating a large and computationally expensive action space for Reinforcement Learning algorithms. Synergy models constrain these movements to a smaller set of statistically significant, coordinated patterns – effectively reducing the number of independent variables the learning policy must optimize. This dimensionality reduction not only accelerates the learning process but also improves generalization to novel situations, as the policy learns to control underlying movement primitives rather than individual joint positions.
Variational Autoencoders (VAEs) are utilized to generate a range of hand postures suitable for task completion while maintaining stability. Experimental results indicate a correlation between the dimensionality of the VAE’s latent space and performance; synergy spaces exceeding one dimension demonstrably improved grasping success rates. Conversely, restricting the latent space to a single dimension negatively impacted performance, suggesting that a higher-dimensional representation is necessary to capture the complexity of effective hand configurations for varied tasks. This implies that a minimum level of representational freedom within the latent space is crucial for generating the diverse yet stable hand postures required for robust manipulation.

Sampling Grasp Candidates: Throw Enough Darts and You’ll Hit Something
Grasp sampling is the initial step in robotic grasp planning, involving the generation of a multitude of potential 2D or 3D hand configurations that could successfully interact with an object to achieve a specified task. This process does not attempt to determine the best grasp, but rather to create a sufficiently diverse set of candidate grasps to enable subsequent evaluation and selection. The diversity is crucial; a limited sample may miss optimal or robust grasps, especially given the inherent uncertainty in real-world conditions. Techniques used in grasp sampling include uniformly sampling grasp poses, or more advanced methods that prioritize areas likely to result in stable grasps based on object geometry and task requirements. The output of this stage is a set of grasp candidates, each defined by a pose (position and orientation) and a corresponding hand configuration.
Grasp candidate generation is enhanced through several machine learning methodologies that encode relationships between objects and task requirements. Graph Convolutional Neural Networks (GCNs) process object geometry as a graph, enabling the network to learn contextual features relevant to grasping. Bayesian Neural Networks (BNNs) provide a probabilistic framework, quantifying uncertainty in grasp predictions and allowing for more robust sampling. Gaussian Mixture Models (GMMs) represent the distribution of possible grasp poses, capturing the inherent variability in successful grasps and facilitating the generation of diverse candidates; these models statistically represent multiple potential grasp locations and orientations based on observed data.
Affordance detection enhances grasp candidate sampling by pre-identifying object regions compatible with the intended task. This process utilizes sensory input – typically visual and tactile – to analyze an object’s shape, surface properties, and potential interaction points. The system then filters grasp candidates to prioritize those aligned with detected affordances, such as handle-like protrusions for grasping, flat surfaces for parallel gripping, or cavities suitable for enveloping the object. By focusing sampling on these compatible regions, the computational cost is reduced and the probability of generating successful grasps is increased, as the system avoids exploring configurations on geometrically unsuitable parts of the object.
Grasp candidates generated through sampling and refinement techniques undergo evaluation via both simulated environments and real-world robotic testing to determine stability and effectiveness. Experimental results indicate a higher grasp success rate compared to baseline methodologies; specifically, testing across 1000 trials per object/intention demonstrated consistent alignment between the robotic hand’s position and the intended grasp location, providing quantitative evidence of the approach’s efficacy. This assessment process allows for iterative improvement of grasp planning algorithms and optimization of robotic manipulation strategies.

From Simulation to Reality: It Works, But Don’t Expect Miracles
The culmination of the simulated training involved deploying the developed policies onto a physical robotic system, specifically a Kinova Gen3 Robotic Arm equipped with a Seed Robotics Hand. This hardware configuration allowed for a direct translation of the learned grasping strategies into real-world actions. The Kinova Gen3 provides seven degrees of freedom, enabling a wide range of motion and precise positioning, while the Seed Robotics Hand offers a compliant and adaptable gripping surface. This combination facilitated the execution of complex grasping maneuvers, validating the effectiveness of the simulation-to-reality transfer and demonstrating the potential for automated robotic manipulation in unstructured environments.
The successful execution of learned grasping policies hinges on accurately translating desired hand configurations into the specific movements of each robotic joint. This is achieved through an Operational Space Controller, a crucial component that bridges the gap between high-level task goals and low-level motor commands. Rather than directly controlling joint angles, the controller operates in the robot’s operational space – the three-dimensional space where the hand physically interacts with objects. By specifying the desired position and orientation of the hand, the controller employs inverse kinematics to compute the corresponding joint angles required to achieve that pose. This approach allows for precise and coordinated movements, enabling the robotic hand to reach for, grasp, and manipulate objects with dexterity, and ensures that the robot arm navigates its environment smoothly and efficiently while maintaining a stable grasp.
The development of robust robotic grasping policies benefits greatly from accelerated training environments, and IsaacGym provides a powerful solution through physics-based simulation and parallelization. This simulator allows for the creation of numerous, independent environments which can be trained simultaneously, dramatically reducing the time required to develop effective grasping strategies. Rather than relying on slow, real-world interactions for learning, the agent can experience the equivalent of years of training within a matter of hours. This accelerated learning not only speeds up the research and development process, but also enables the exploration of more complex and nuanced grasping behaviors that would be impractical to achieve through traditional methods, ultimately enhancing the adaptability and efficiency of robotic manipulation systems.
The successful transfer of learned policies to a physical robotic system-a Kinova Gen3 arm and Seed Robotics hand-validates the potential for task-oriented grasping in realistic environments. This implementation demonstrates that a robotic agent can reliably acquire objects, maintaining a consistent success rate even when deprived of explicit object category information. However, the study revealed a critical dependency on contextual cues; the agent struggled to select appropriate grasp locations if not provided with information regarding the intended post-grasp action. This highlights that effective robotic manipulation requires not only the ability to grasp, but also an understanding of the task’s ultimate goal, suggesting future research should prioritize integrating intention-based learning for truly versatile and adaptable robotic systems.
The pursuit of natural grasping, as outlined in this work, feels predictably optimistic. The researchers attempt to imbue robots with human-like dexterity, leveraging postural synergies and reinforcement learning to anticipate post-grasp actions. It’s a noble effort, yet one destined to encounter the realities of production environments. As Vinton Cerf once stated, “Any sufficiently advanced technology is indistinguishable from magic…until it breaks.” This paper, with its elegant synergy model and reinforcement learning agent, is certainly aiming for magic. The inevitable cascade of edge cases – the oddly shaped object, the unexpected collision – will quickly remind everyone that even the most sophisticated algorithms are ultimately just brittle code, praying to the CI gods for a passing build.
Future Shocks
The pursuit of ‘natural’ grasping, as demonstrated, introduces a new layer of complexity. While aligning robotic manipulation with human preferences may improve collaboration, it merely shifts the failure modes. The system will inevitably encounter scenarios – object variations, environmental disturbances, the sheer unpredictability of production – that expose the limitations of the learned synergy model. Human grasps are not flawless; they are reactive, adaptive, and often brute-force solutions. Replicating the style of human grasping without addressing the underlying robustness will yield only marginally better failures.
The reliance on reinforcement learning, while yielding demonstrable results, highlights a recurring problem. Each learned policy is a brittle encapsulation of a specific training distribution. Scaling these systems requires either infinite training data or a willingness to accept graceful degradation in novel situations. The current approach implicitly assumes the ‘intended post-grasp action’ will remain constrained. A truly robust system must anticipate – and tolerate – arbitrary user intent, a problem that is less about grasping and more about general-purpose reasoning.
The field doesn’t require more sophisticated grasp planners; it needs fewer illusions of competence. The focus should shift from replicating human behavior to addressing fundamental limitations in sensing, actuation, and control. The next iteration won’t be a more elegant algorithm; it will be a more honest assessment of what remains stubbornly difficult.
Original article: https://arxiv.org/pdf/2602.20915.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-25 10:11