Author: Denis Avetisyan
A new imitation learning approach allows robots to acquire complex manipulation skills simply by observing human demonstrations in video.
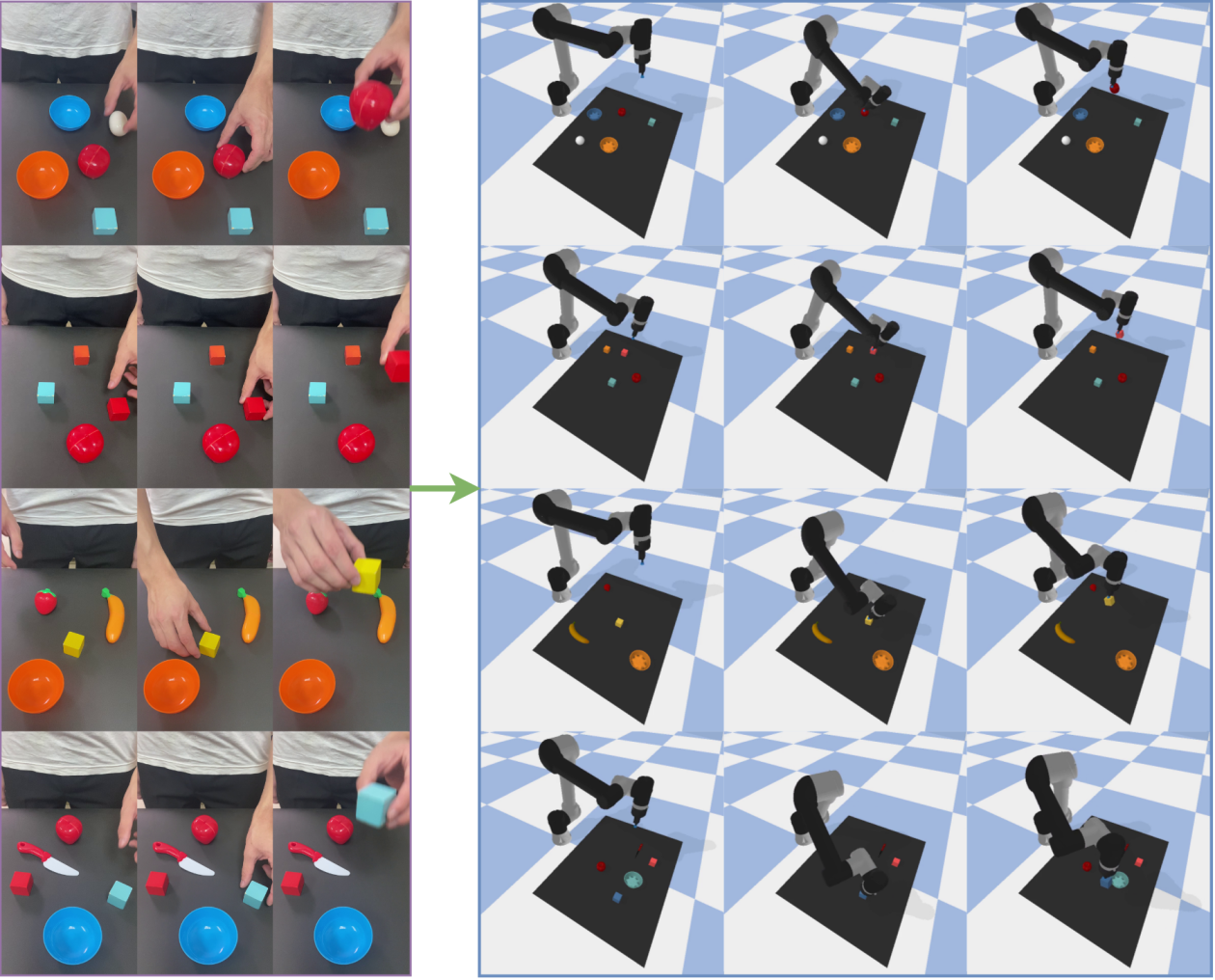
This work introduces a decoupled framework leveraging video understanding and object-centric perception to achieve robust robot imitation and generalization capabilities.
Extracting precise manipulation commands from unstructured video remains a key challenge in robotics, despite recent advances in learning from demonstration. This limitation motivates the work ‘Human-to-Robot Interaction: Learning from Video Demonstration for Robot Imitation’, which presents a novel framework decoupling video understanding from robot control to enable skill acquisition directly from human demonstrations. By combining Temporal Shift Modules with Vision-Language Models for action and object identification, and employing a TD3-based reinforcement learning approach, the proposed system achieves high success rates and generalization across diverse scenarios. Could this modular approach pave the way for more intuitive and adaptable robot learning systems capable of seamlessly integrating human guidance?
The Illusion of Robotic Mastery: Why Simple Tasks Remain So Difficult
Historically, robotic manipulation has relied on precisely programmed instructions, demanding significant human effort for each new task. This approach necessitates detailed modeling of the robot’s kinematics and dynamics, alongside meticulous specification of trajectories and control parameters. While effective in structured environments, this methodology proves brittle when confronted with even slight variations – a misplaced object, an unexpected surface texture, or a minor deviation in the robot’s own mechanics can lead to failure. The limitations of this traditional paradigm highlight a critical need for robots capable of learning and adapting, rather than simply executing pre-defined sequences, paving the way for more versatile and autonomous systems capable of operating in complex, real-world scenarios.
The promise of rapidly deploying robotic solutions is frequently hampered by the ‘Sim-to-Real Gap’ – a significant performance decline when a skill mastered in a simulated environment is applied to a physical robot operating in the real world. This discrepancy isn’t simply a matter of scale; it stems from fundamental differences in dynamics, friction, and sensor noise between the virtual and physical realms. A robot trained to grasp an object flawlessly in simulation might fumble in reality due to unforeseen variations in lighting, surface texture, or even slight imperfections in the object itself. Consequently, extensive and costly real-world fine-tuning is often required, negating many of the efficiency gains anticipated from simulation-based learning and hindering the broader adoption of robotics in dynamic, unpredictable environments.
The notorious “Sim-to-Real Gap” isn’t simply a matter of imperfect simulation; it’s a complex interplay of physical realities. Discrepancies in dynamics – the nuanced ways forces and motion behave – between the virtual and physical worlds create immediate challenges. Moreover, differences in sensing modalities and fidelity-how a robot ‘perceives’ its surroundings-introduce further errors. However, the most significant obstacle often lies in unforeseen environmental variations-unexpected lighting changes, subtle shifts in surface friction, or the presence of unmodeled objects-that simulations struggle to anticipate. These combined factors necessitate the development of more robust learning paradigms, such as domain randomization and meta-learning, which aim to train robots to be resilient to these unpredictable conditions and generalize their skills beyond the confines of the simulated environment.
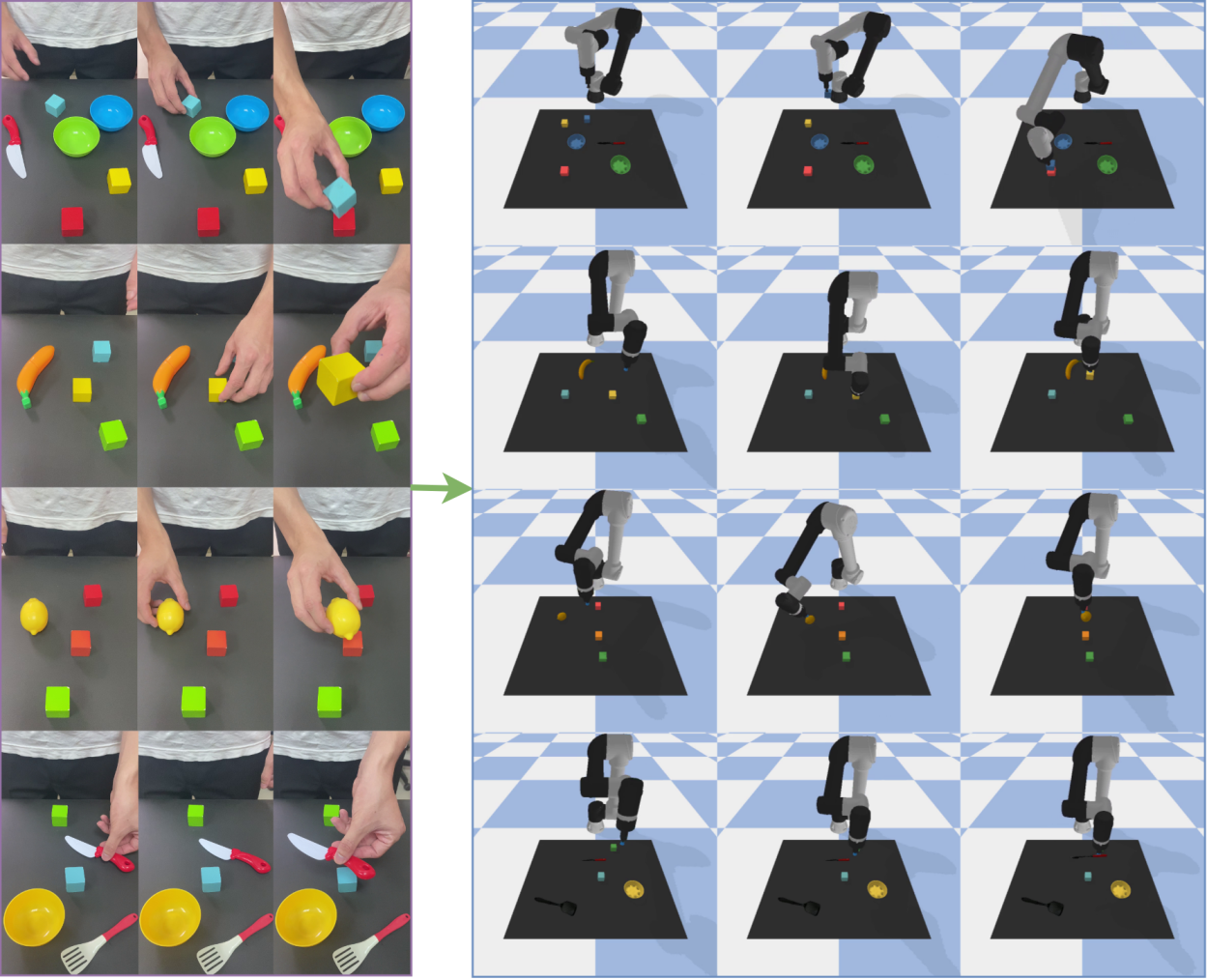
Learning by Watching: The Illusion of Intelligence
Learning from Demonstration (LfD) offers a method for robots to acquire new skills by observing and generalizing from human performance, eliminating the requirement for manually coded instructions. This approach circumvents the complexities of traditional robotic programming, which demands precise specification of every movement and action. Instead, LfD systems utilize sensory data – such as motion capture, video, or force sensor readings – recorded from a human demonstrator performing the desired task. This data is then processed to create a mapping between observed states and corresponding robot actions, allowing the robot to replicate the demonstrated behavior. The resulting system is adaptable and can be applied to tasks where defining explicit rules is difficult or impractical, offering a more intuitive and efficient pathway to robotic skill acquisition.
Learning from Demonstration (LfD) incorporates multiple methodologies for skill transfer. Teleoperation involves a human operator directly controlling the robot’s movements to create a demonstration dataset. Passive Observation allows the robot to learn from observing a human performing a task without any physical assistance, relying on sensor data like vision or force-torque sensors. Kinesthetic Teaching entails a human physically guiding the robot through the desired motions, providing direct feedback and correction. Each approach presents distinct advantages; teleoperation is suitable for complex tasks but can be slow, passive observation requires robust perception, and kinesthetic teaching offers precise guidance but may not scale to entirely new scenarios.
The fundamental process in Learning from Demonstration (LfD) involves establishing a correspondence between observed human actions and the robot’s control signals. This mapping is typically achieved through data collection, where human demonstrations are recorded as state-action pairs – representing the robot’s perceived state and the corresponding action taken by the human demonstrator. These pairs are then used to train a learning algorithm, such as supervised learning or imitation learning, to predict the appropriate robot action given a new state. The resulting learned policy allows the robot to replicate the demonstrated behavior, effectively enabling imitation of the human’s skill without requiring explicit, hand-coded programming of each movement or task component.
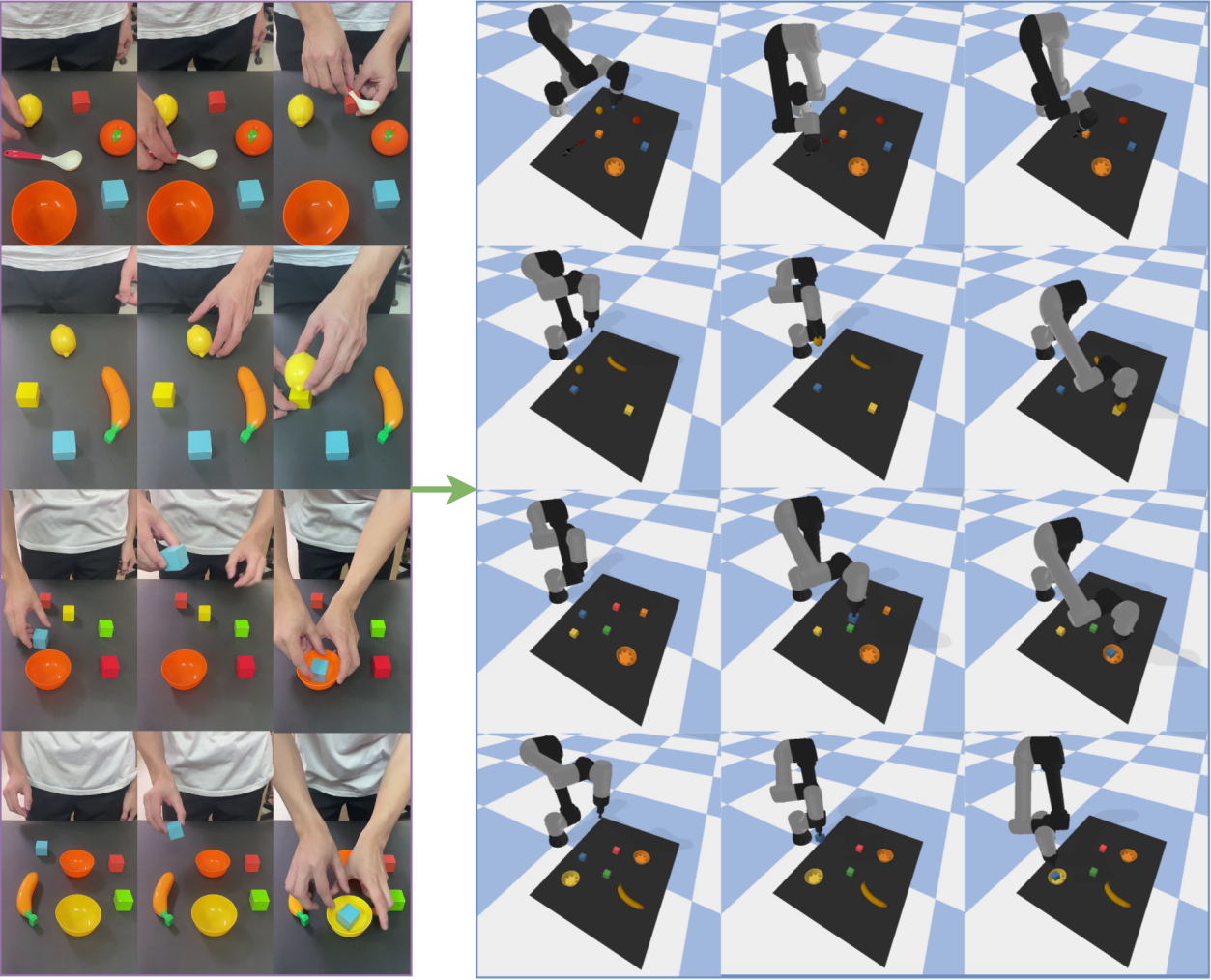
Seeing is Believing? The Limits of Robotic Vision
Video understanding forms the core of Learning from Demonstration (LfD) systems, allowing robots to process and interpret visual data from demonstration videos. This capability enables the robot to identify and categorize objects within the video, performing object recognition to establish what items are present and their locations. Crucially, it also facilitates action classification, where the robot determines what actions are being performed on those objects, and the sequence in which they occur. By extracting this meaningful information – object identity, location, and associated actions – the robot can then learn to replicate the demonstrated behavior, forming the basis for skill acquisition through observation.
Vision-Language Models (VLMs) and Temporal Shift Modules represent key advancements in robotic video understanding. VLMs enable robots to connect visual observations with natural language descriptions, facilitating a more nuanced interpretation of actions and object relationships within a scene. Temporal Shift Modules specifically address the challenge of varying action speeds and temporal dependencies by allowing the model to analyze video frames with shifted perspectives, improving recognition of actions performed at different rates or with pauses. This combination allows robots to better generalize to new scenarios and interpret complex visual sequences, ultimately enhancing their ability to learn from demonstration videos and execute tasks accordingly.
The performance of video understanding systems is quantitatively assessed using metrics like the BLEU score, which evaluates the similarity between generated commands and a set of reference commands. Recent implementations have achieved a BLEU-4 score of 0.351 when processing videos of standard objects and 0.265 for novel objects; these results represent a 76.4% and 128.4% improvement, respectively, compared to previously established methods. These scores indicate a substantial increase in the accuracy and relevance of the commands generated from video input, demonstrating improved capabilities in translating visual information into actionable instructions.

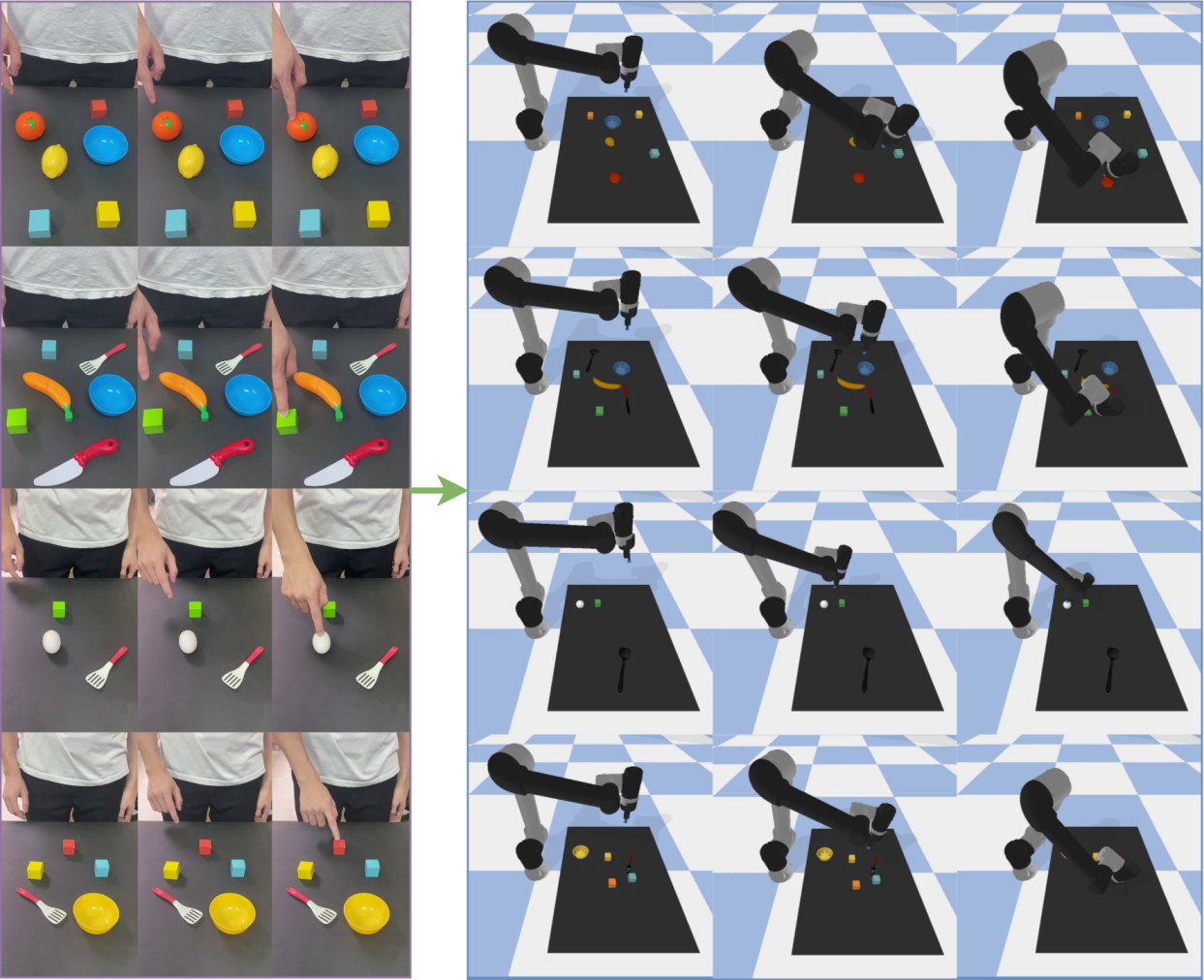
The Illusion of Mastery: When Imitation Meets Reality
Robot imitation represents a crucial intersection of artificial intelligence and robotics, focusing on the translation of observed human or demonstrated actions into commands a robot can physically execute. This process isn’t simply recording and replaying; instead, it often employs sophisticated techniques like Deep Reinforcement Learning, where the robot learns to map observations to actions through trial and error, guided by a reward system. The core challenge lies in bridging the gap between the abstract understanding of a demonstrated skill – such as grasping an object or navigating a space – and the precise motor commands needed for a robot to replicate it reliably. This allows robots to acquire complex behaviors without explicit programming, instead learning from examples, fostering adaptability and potentially enabling robots to perform tasks in dynamic and unpredictable environments.
The robot’s ability to replicate demonstrated actions relies heavily on sophisticated algorithms capable of refining its control policy. Techniques like Twin Delayed Deep Deterministic Policy Gradient (TD3) are employed, iteratively improving the robot’s responses through trial and error. Central to this process is a carefully constructed Reward Function, which provides feedback on the quality of each action, guiding the algorithm toward desired behaviors. Further optimization can be achieved through Hierarchical Reward Design, breaking down complex tasks into smaller, more manageable sub-goals, each with its own associated reward. This layered approach not only accelerates learning but also enhances the robot’s adaptability and precision, enabling it to consistently execute learned skills with increasing proficiency.
The culmination of this research lies in a demonstrated success rate of 87.5% for the “pick” action, a key indicator of the framework’s ability to translate learned behaviors into reliable physical execution. This figure isn’t merely a statistical result; it represents a significant step towards robust robot skill transfer, meaning the system can consistently perform the desired task in a real-world setting despite inherent environmental variations and the challenges of physical manipulation. The achievement underscores the effectiveness of the imitation learning and reinforcement learning techniques employed, showcasing a pathway for robots to acquire complex skills from demonstrations and then adapt those skills for dependable performance, minimizing the need for painstaking manual programming or constant human intervention.
The pursuit of seamless human-to-robot interaction, as detailed in this work, feels…familiar. They’ve decoupled video understanding from robot control, promising generalization from unstructured demonstrations. It’s a lovely idea, really. It reminds one of Barbara Liskov’s observation: “It’s one thing to design a system and another thing to have it actually work in the real world.” This paper attempts to bridge that gap, and while object-centric perception and temporal shift modules sound impressive, the inevitable entropy of production environments will, predictably, introduce unforeseen complications. They’ll call it AI and raise funding, of course. But anyone who’s seen a ‘simple’ bash script evolve into a sprawling monstrosity knows this elegant framework will, eventually, accrue tech debt. It always does.
What’s Next?
This decoupling of visual understanding from robotic actuation is, predictably, not a resolution, but a deferral. The framework successfully shifts the burden – from making robots see to making them interpret what they see – but merely externalizes the core problem. Vision-Language Models are brittle, and the inevitable domain shift will reveal that the ‘generalization capabilities’ demonstrated are, at best, a temporary reprieve. The temporal shift module is a clever patch, but the universe has an infinite capacity to generate out-of-sync events.
Future iterations will undoubtedly focus on scaling this complexity – larger datasets, more elaborate architectures, and increasingly desperate attempts to anticipate every edge case. A more honest approach might involve accepting the inherent limitations of imitation. Can a robot truly learn a skill from observation, or is it merely memorizing a sequence of actions, destined to fail the moment the world deviates from the training video?
The pursuit of ‘unstructured’ video is particularly optimistic. Noise, occlusion, and the sheer variability of human action will always present challenges. One suspects that the real progress will come not from better algorithms, but from more rigorous control of the demonstration environment – a fact that will likely remain unstated in subsequent publications. Documentation is a myth invented by managers, and similarly, ‘generalization’ is a promise rarely kept.
Original article: https://arxiv.org/pdf/2602.19184.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-24 10:28