Author: Denis Avetisyan
A new vision for materials science leverages intelligent AI agents to orchestrate experiments, curate data, and ultimately design novel materials with minimal human intervention.

This review advocates for a pipeline-centric approach integrating agentic systems, reinforcement learning, and autonomous laboratories to advance scientific AI in materials discovery.
While artificial intelligence holds immense promise for accelerating materials discovery, realizing its full potential requires moving beyond isolated predictive models. This survey, ‘Towards Agentic Intelligence for Materials Science’, proposes a pipeline-centric framework integrating data curation, language models, and experimental feedback to enable autonomous agents capable of pursuing long-horizon discovery goals. By analyzing the field through both AI and materials science lenses, we demonstrate how aligning upstream design choices with downstream experimental success is crucial for tangible outcomes. Could this approach pave the way for fully autonomous laboratories capable of designing and synthesizing novel materials with unprecedented efficiency and purpose?
The Inherent Limitations of Manual Materials Discovery
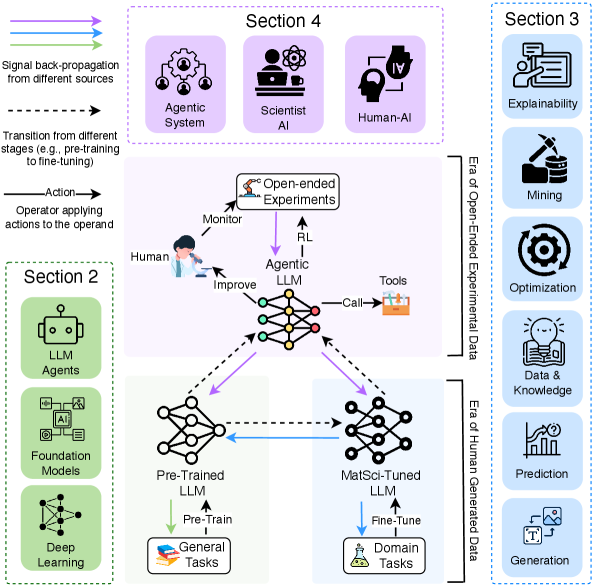
The development of novel materials has historically been a painstaking process, often requiring years of dedicated research and substantial financial investment. Traditional materials discovery largely depends on the expertise and, crucially, the intuition of individual scientists, who formulate hypotheses based on existing knowledge and then meticulously test them through experimentation. This reliance on human-driven research creates inherent bottlenecks; the vastness of possible material combinations far exceeds the capacity for manual exploration, and even subtle biases in hypothesis generation can limit the scope of discovery. Consequently, promising materials may remain undiscovered, and innovation is significantly constrained by the speed and cost associated with this largely manual, iterative process.
The sheer scale of possible materials-often described as ‘chemical space’-presents a fundamental barrier to innovation. Consider that even relatively simple compounds number in the millions, and combining these into more complex structures yields a combinatorial explosion of possibilities exceeding the capacity of human researchers to explore effectively. Traditional materials discovery relies on iterative cycles of synthesis, characterization, and analysis, a process inherently limited by the speed and intuition of individual scientists. This manual approach struggles to navigate the vastness of potential compositions, often focusing on well-trodden areas based on existing knowledge. Consequently, promising materials with novel properties may remain undiscovered, locked away within the unexplored regions of this immense chemical landscape. The limitations imposed by this insurmountable search space necessitate a move towards automated, high-throughput experimentation and data analysis to unlock the full potential of materials science.
Materials science is poised for a revolution, moving beyond the limitations of traditional, hypothesis-driven discovery towards a future defined by autonomous experimentation and data-driven insights. Current methods, reliant on human intuition and painstaking trial-and-error, can only explore a minuscule fraction of the vast chemical space available. The implementation of self-directing systems – robotic platforms coupled with machine learning algorithms – promises to dramatically accelerate the pace of innovation. These systems can independently design, execute, and analyze experiments, iteratively refining their approach based on real-time data. This shift isn’t merely incremental; projections suggest such methodologies could expand the experimentally accessible search space by a factor of ten, unlocking a wealth of novel materials with tailored properties and potentially solving critical challenges across diverse fields like energy, medicine, and sustainable technology.
Agentic LLMs: The Logical Progression for Autonomous Materials Science
Agentic Large Language Models (LLMs) represent a paradigm shift in materials science research by integrating LLM capabilities with automated experimental workflows. These systems move beyond simple prediction or data analysis; they autonomously formulate hypotheses, design experiments – including specifying materials, procedures, and instrumentation – and interpret results to iteratively refine their investigations. This is achieved through LLMs’ capacity for complex reasoning and planning, enabling them to navigate the scientific method without constant human intervention. The core functionality relies on the LLM’s ability to process scientific literature, identify knowledge gaps, and translate these into actionable experimental protocols, effectively functioning as an automated scientist capable of driving materials discovery and optimization.
Adapting pre-trained large language models (LLMs) for materials science applications necessitates both Domain Adaptation and Instruction Tuning. Domain Adaptation modifies the LLM’s existing parameters to better understand and process materials science terminology, data formats, and relationships – typically achieved through continued pre-training on large corpora of materials science literature and databases. Subsequently, Instruction Tuning further refines the model’s behavior by training it on specific task instructions and corresponding outputs – for example, “predict the band gap of this material” paired with the correct prediction. This process optimizes the LLM to not only comprehend materials science language but also to consistently generate accurate and relevant responses to defined materials science tasks, improving performance beyond general-purpose LLM capabilities.
Reinforcement Learning (RL) is essential for training agentic Large Language Models (LLMs) in materials science by enabling iterative improvement through interaction with an environment – typically a simulation or automated laboratory setup. The process involves defining a reward function that quantifies the desirability of experimental outcomes; for example, a reward could be assigned based on proximity to target material properties or successful synthesis of a desired compound. Through trial and error, the LLM learns a policy – a strategy for selecting actions – that maximizes cumulative reward. Crucially, RL addresses the alignment problem by directly optimizing the LLM’s behavior towards achieving defined experimental goals, thus improving the correlation between model predictions and tangible, real-world results and mitigating potential discrepancies arising from the LLM’s pre-training data or inherent biases.
Virtual Validation and Real-World Deployment: A Rigorous Two-Pronged Approach
A VirtualEnvironment provides a preliminary testing ground for autonomous agents prior to physical deployment, significantly reducing development costs and safety risks. This environment allows for rapid iteration on agent algorithms and control strategies without the expense or potential damage associated with real-world experimentation. The incorporation of DigitalTwin technology can further enhance the fidelity of the virtual environment by creating a highly accurate representation of the target physical system, enabling more realistic simulations and improved transferability of learned behaviors. This approach facilitates exhaustive testing of edge cases and failure modes, identifying and mitigating potential problems before they manifest in a physical setting, ultimately accelerating the development cycle and improving agent robustness.
Real-world experimentation is a critical phase in agent development, serving to validate performance metrics established in simulated environments against physical constraints and unpredictable conditions. Data gathered during these experiments is used to refine agent algorithms, improving robustness and generalization capabilities. The integration of simulation data with real-world data significantly reduces experimental costs; simulation can predict outcomes and narrow the scope of physical tests, minimizing the need for extensive and potentially damaging real-world trials. This combined approach allows for more efficient data collection and iterative improvements to the agent’s performance, accelerating the development lifecycle and reducing overall expenses.
The RewardFunction is a critical component of reinforcement learning, providing scalar feedback to the agent based on its actions and the resulting state of the environment. This function quantifies the desirability of different outcomes, guiding the agent towards optimal behavior. Effective learning, however, requires not only receiving this reward signal, but also determining which actions contributed to it; this is achieved through CreditAssignment. CreditAssignment algorithms analyze the sequence of actions leading to a reward, distributing credit to those actions that were instrumental in achieving success and minimizing credit to those that were not. This process enables efficient learning by focusing refinement on impactful behaviors and discarding ineffective ones, significantly increasing data efficiency and accelerating the agent’s iterative improvement.
![Pre-trained and materials-science-tuned language models function as a unified memory, enabling an agentic language model to perform trial-and-error search-interacting with either simulated or real environments-and leveraging past successes, quantified by directed information [latex]\mathbb{I}(X\to Y)[/latex], to improve future performance.](https://arxiv.org/html/2602.00169v1/x3.png)
Data-Driven Discovery: Active Learning and Curation for Optimal Performance
Active Learning is an iterative annotation strategy designed to maximize model performance with reduced labeling effort. Instead of randomly selecting data points for annotation, Active Learning algorithms prioritize instances that, when labeled, are predicted to yield the greatest improvement in model accuracy. This is typically achieved through uncertainty sampling, where the algorithm requests labels for data points it is least confident in predicting, or through query-by-committee, where multiple models disagree on a particular instance. By focusing annotation resources on the most informative data, Active Learning significantly reduces the volume of manually labeled data required to achieve a target performance level, offering substantial cost and time savings compared to traditional supervised learning approaches.
A DataCurationPolicy defines the procedures for verifying and maintaining the integrity of the dataset used for agent training. This policy encompasses protocols for identifying and correcting errors, handling missing values, and resolving inconsistencies across data sources. Crucially, it establishes guidelines for mitigating bias through techniques such as data balancing, outlier detection, and careful feature selection. Consistent application of a DataCurationPolicy ensures the reliability of the training data, preventing the propagation of inaccuracies or skewed representations that could negatively affect the agent’s performance and generalization capabilities. The policy should also document the rationale behind data transformations and the criteria used for data acceptance or rejection, promoting transparency and reproducibility.
The integration of MultiModalData – encompassing text, images, and numerical values – significantly improves RepresentationLearning within materials science applications. By combining these data types, the agent gains access to a more comprehensive understanding of material properties and relationships than would be possible with any single modality. Textual data, such as scientific literature or experimental notes, provides contextual information; images, including microscopy or diffraction patterns, offer visual representations of material structure; and numerical data, like composition or mechanical properties, offer quantitative measurements. This combined input allows the agent to develop more robust and accurate representations, leading to enhanced predictive capabilities and accelerated materials discovery.
Safe and Transparent Automation: The Future of Materials Innovation
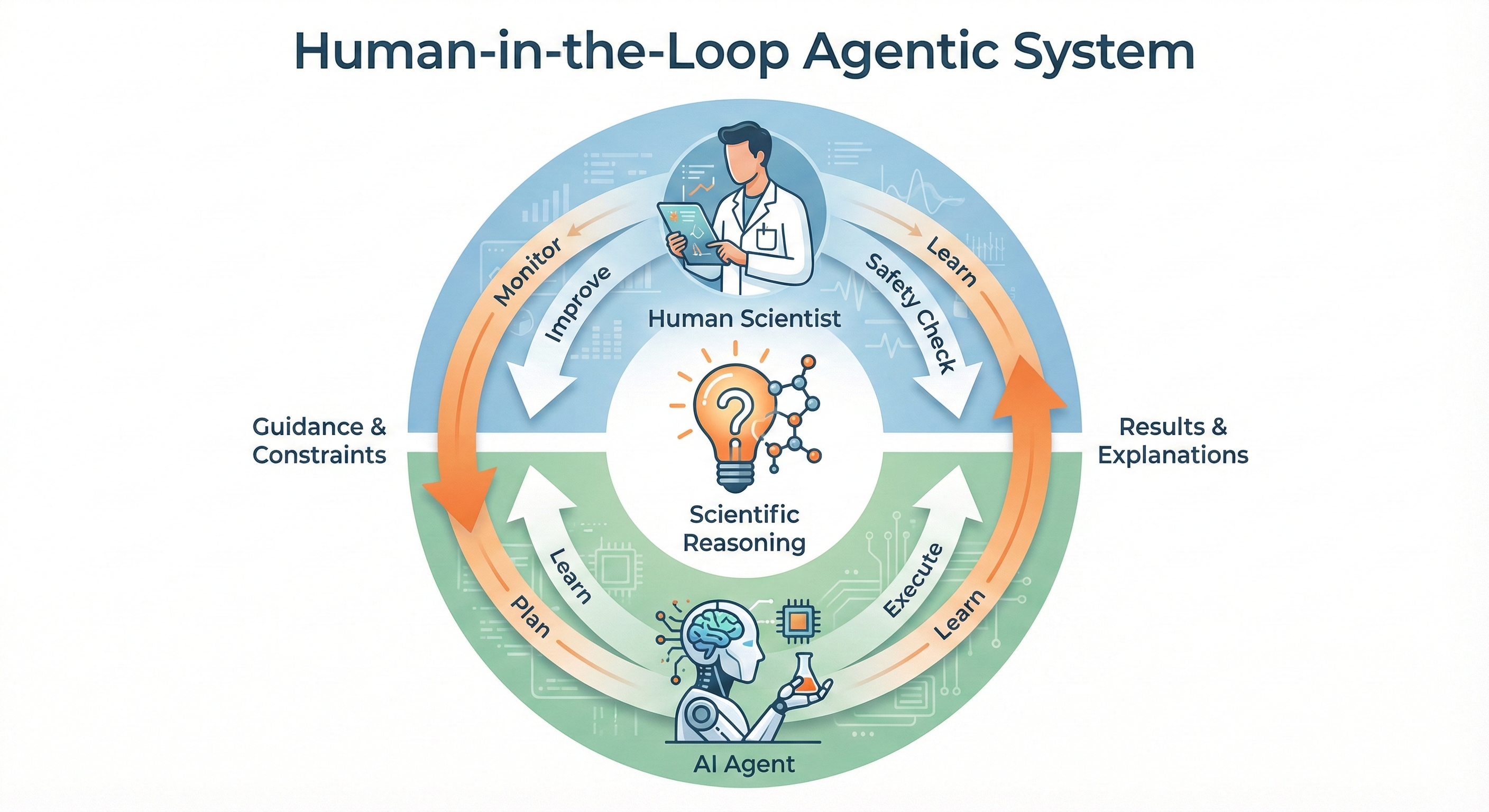
The deployment of large language models as autonomous agents in materials science necessitates robust safety protocols, and SafeAI principles address this critical need by establishing operational boundaries. These principles don’t aim to stifle innovation, but rather to constrain the agent’s actions within pre-defined, physically plausible, and experimentally feasible parameters. This involves specifying acceptable ranges for material compositions, reaction conditions, and even instrument settings, effectively creating a ‘sandbox’ for exploration. By proactively limiting the scope of experimentation, SafeAI mitigates the risk of unintended consequences – such as synthesizing unstable compounds or damaging sensitive equipment – ensuring that the agent operates responsibly and predictably. The result is a system capable of autonomous discovery without sacrificing experimental integrity or posing safety hazards, fostering confidence in the generated hypotheses and accelerating the pace of materials innovation.
The integration of ExplainableAI – often referred to as XAI – is crucial for building confidence in autonomous materials discovery systems. These techniques move beyond simply what an agentic LLM decides, and instead illuminate why a particular material or experimental pathway was selected. By providing insights into the reasoning process – perhaps highlighting key atomic properties or previously unseen relationships within the data – XAI fosters trust among researchers. More importantly, this transparency isn’t merely about understanding; it enables targeted human intervention. If an agent’s logic appears flawed, or if an unexpected result arises, experts can readily identify the source of the decision, correct any biases, and refine the agent’s learning process, ensuring both the validity and acceleration of materials innovation.
The convergence of autonomous agents with robust safety protocols and transparent reasoning promises a revolution in materials discovery. By allowing artificial intelligence to navigate complex experimental landscapes while remaining constrained by defined boundaries and offering clear explanations for its choices, researchers anticipate a dramatic expansion of the materials innovation pipeline. This approach doesn’t simply automate existing methods; it fundamentally alters the scale of exploration, potentially increasing the experimental search space by an order of magnitude. Such a leap forward isn’t limited to a single field; it has the potential to accelerate advancements across diverse disciplines, from energy storage and sustainable manufacturing to biomedical engineering and advanced electronics, ushering in an era where material innovation is no longer limited by the constraints of traditional, manual experimentation.
The pursuit of agentic intelligence in materials science, as detailed in the paper, necessitates a rigorous framework-one where data isn’t simply processed, but meticulously curated and validated. This echoes Marie Curie’s sentiment: “Nothing in life is to be feared, it is only to be understood.” The paper champions a pipeline-centric approach, moving beyond isolated AI tasks to an autonomous cycle of prediction, experimentation, and analysis. This isn’t merely about achieving functional results; it demands a provable understanding of the underlying scientific principles, mirroring Curie’s dedication to uncovering fundamental truths about the natural world. Only through such disciplined inquiry can the chaos of materials data yield genuinely novel and useful discoveries.
What’s Next?
The pursuit of ‘agentic’ intelligence in materials science, as presented, fundamentally rests on the premise of reproducible experimentation and verifiable prediction. A pipeline, however elegantly constructed, is only as robust as its weakest link – and the tendency to treat large language models as oracles, rather than stochastic pattern-completion engines, remains a significant vulnerability. The current emphasis on automating existing workflows, while pragmatic, risks merely accelerating the propagation of existing biases embedded within datasets and algorithmic choices. True progress demands a shift towards explicitly modeling uncertainty and rigorously quantifying the limits of predictability.
A crucial, and often overlooked, aspect is the formal verification of these agentic systems. Demonstrating that an agent will consistently converge on optimal solutions – or, crucially, reliably indicate when a solution is unattainable – requires more than empirical validation. The field needs to embrace formal methods, potentially drawing from control theory and game theory, to provide guarantees about agent behavior. Without such guarantees, the promise of autonomous materials discovery remains a sophisticated form of educated guesswork.
Ultimately, the success of this approach hinges not on the sheer scale of datasets or the complexity of the models, but on the development of a demonstrably correct framework for scientific reasoning. It is not enough for an agent to find a material; it must be able to explain why that material possesses the desired properties, and to do so in a manner that is mathematically rigorous and independent of the specific training data. The challenge, therefore, is not simply to automate science, but to formalize it.
Original article: https://arxiv.org/pdf/2602.00169.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Limbus Company 2026 Roadmap Revealed
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Last Furry: Survival redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
2026-02-03 09:46