Author: Denis Avetisyan
New research demonstrates how leveraging human physiological data and off-policy evaluation can significantly improve the performance and usability of reinforcement learning agents in collaborative robotic systems.
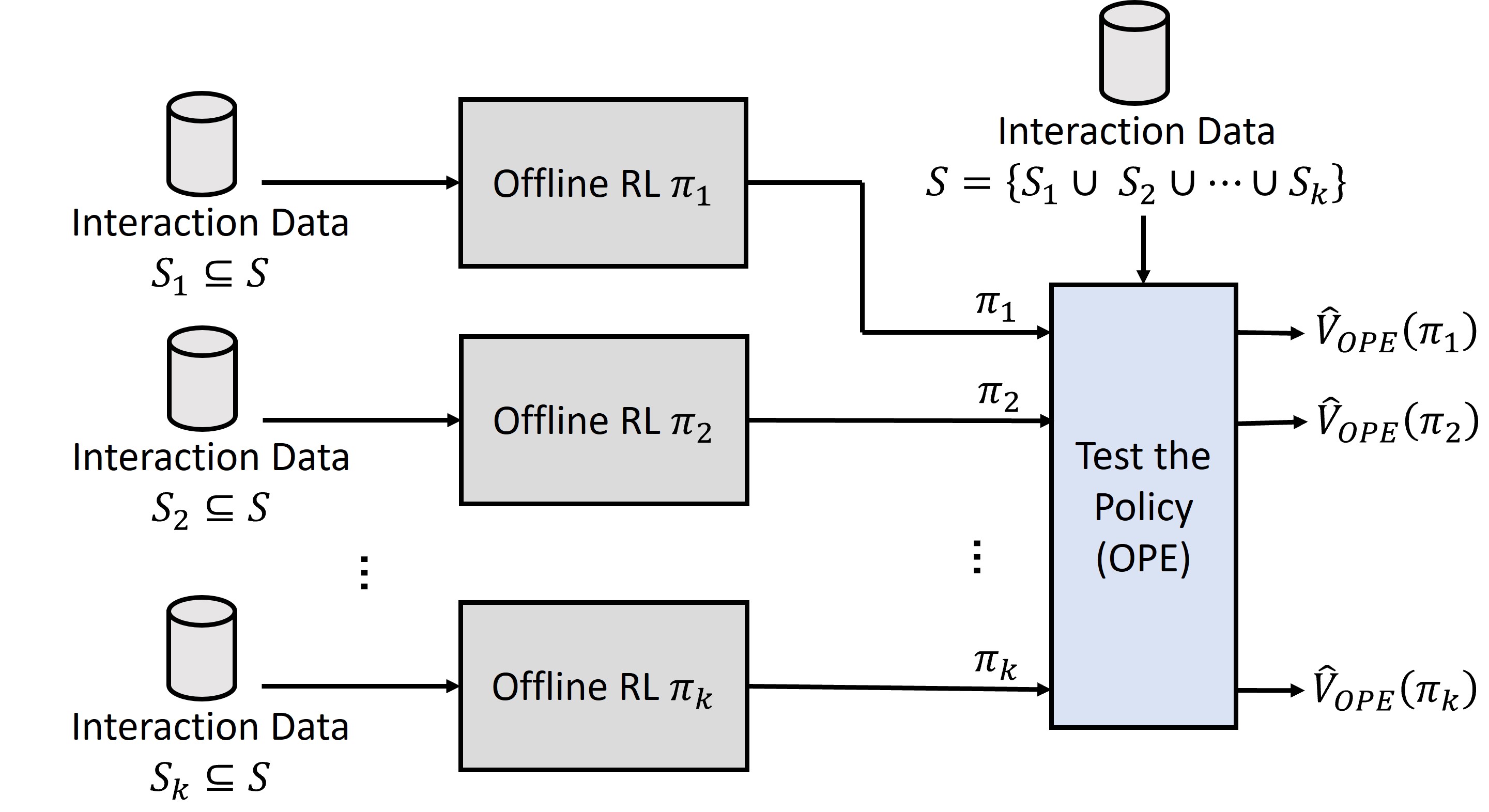
This review details a framework for optimizing human-robot collaboration through offline reinforcement learning and physiological state space selection, reducing operator workload and enhancing trust.
Defining effective state representations and reward functions remains a critical bottleneck in deploying reinforcement learning (RL) for real-world applications, particularly in human-robot interaction. This work, ‘Formulating Reinforcement Learning for Human-Robot Collaboration through Off-Policy Evaluation’, introduces a novel framework that leverages off-policy evaluation (OPE) to automate the selection of optimal state spaces and reward functions using only logged data. By systematically evaluating candidate formulations offline, this approach eliminates the need for costly and time-consuming real-time interaction with the environment or human operators. Will this data-driven approach unlock scalable and reliable RL solutions for complex human-robot teaming scenarios, ultimately fostering more effective and trustworthy collaboration?
Deconstructing the Data Bottleneck: Why Traditional Reinforcement Learning Struggles
Conventional reinforcement learning algorithms typically demand a substantial amount of trial-and-error interaction with an environment to effectively learn an optimal policy. This necessitates countless episodes of an agent performing actions and receiving feedback, a process that proves both time-consuming and resource-intensive. Consequently, applying these methods in real-world contexts – such as robotics, healthcare, or finance – often presents significant hurdles. The cost associated with each interaction can be substantial, ranging from physical wear and tear on robotic systems to the potential risks involved in experimenting with medical treatments or financial strategies. Furthermore, certain environments may not allow for real-time interaction at all, or may only permit a limited number of trials, rendering traditional online learning approaches infeasible. The need for extensive data collection thus represents a major bottleneck in the broader adoption of reinforcement learning technology.
The practical deployment of reinforcement learning often faces significant hurdles due to its inherent need for substantial interaction with an environment to learn effectively. This reliance on extensive data collection proves problematic in numerous real-world applications where gathering such data is either prohibitively expensive – think robotics requiring physical wear and tear, or personalized medicine demanding extensive patient trials – or carries unacceptable risks, as seen in autonomous driving or critical infrastructure control. Consequently, scenarios demanding rapid adaptation or operating in sensitive environments frequently find traditional RL methods impractical, highlighting the need for alternative learning paradigms that can effectively utilize existing, static datasets without requiring continuous, potentially costly, or dangerous exploration.
Offline reinforcement learning presents a compelling alternative to traditional methods by utilizing datasets compiled independently of the learning agent’s current policy, circumventing the need for costly or dangerous online interactions. However, this approach introduces a significant hurdle: distribution shift. Because the agent learns from a static dataset, its actions, guided by an evolving policy, may deviate from the data’s original distribution – the states and actions the data was collected under. This discrepancy can lead to overestimation of out-of-distribution actions, causing the agent to pursue strategies that appeared beneficial within the dataset but perform poorly in real-world deployment. Addressing this distribution shift requires sophisticated techniques, such as conservative policy optimization or uncertainty-aware learning, to ensure the agent generalizes effectively and avoids extrapolating beyond the bounds of its training data.
Unveiling the Past: Off-Policy Evaluation as a Diagnostic Tool
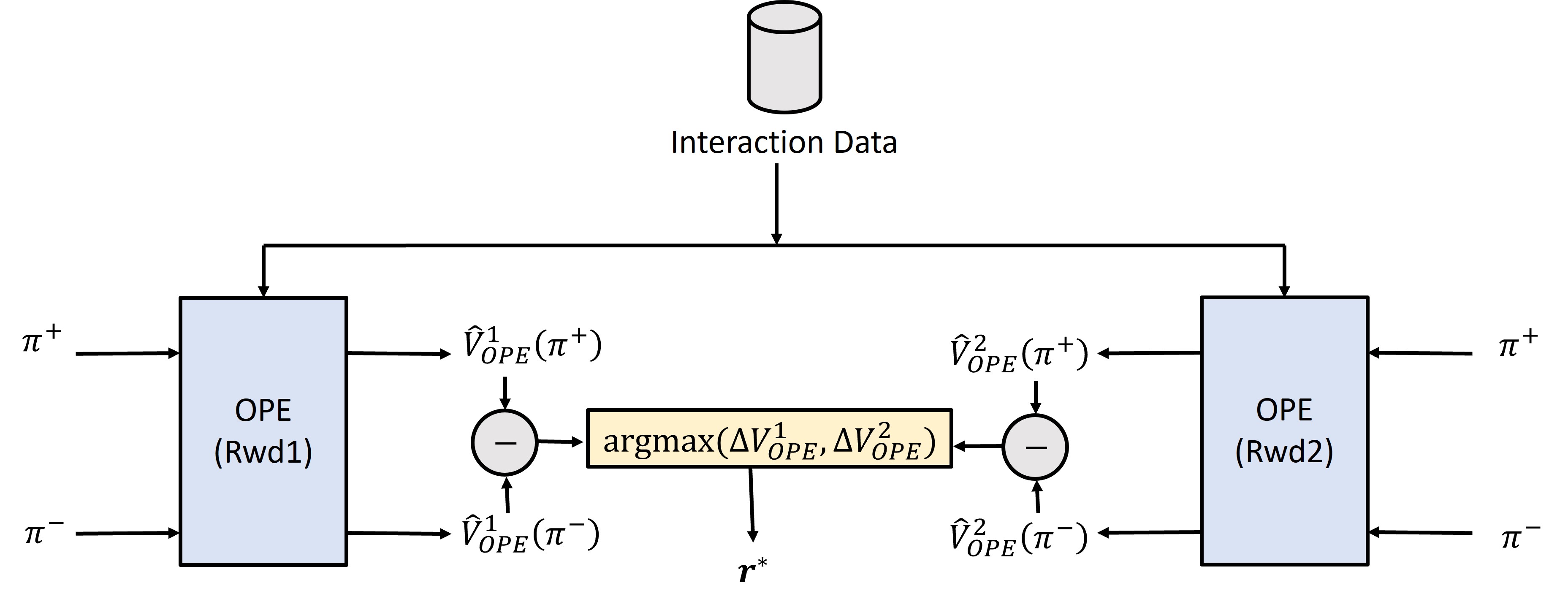
Off-policy evaluation (OPE) addresses the common reinforcement learning scenario where assessing the performance of a target policy relies on data collected from a separate behavior policy. This decoupling is frequently necessary due to constraints on data collection – for example, evaluating a new policy without interrupting a currently deployed one, or leveraging historical datasets. The core challenge in OPE stems from the distributional shift between the target and behavior policies; data generated under one policy may not accurately reflect the outcomes under another. Consequently, direct estimation of the target policy’s value function using behavior policy data introduces bias. Accurate OPE is therefore critical for safe and efficient policy improvement, allowing for the comparison of different policies without extensive, potentially costly, on-policy experimentation.
Importance Sampling (IS) is a foundational off-policy evaluation technique, but its practical application is limited by its susceptibility to high variance. This variance arises because the importance weights, calculated as the ratio of probabilities of actions taken under the target policy versus the behavior policy, can be significantly different, especially when the policies diverge substantially. A single, unlikely action under the behavior policy, when favored by the target policy, can result in a very large importance weight, disproportionately influencing the estimate and leading to instability. Consequently, while unbiased, IS estimates often exhibit high error, requiring a large amount of data to achieve reliable performance. To mitigate this, more sophisticated techniques such as weighted importance sampling, trimmed importance sampling, and doubly robust estimators are employed to reduce the impact of these high-variance weights and provide more stable and accurate off-policy evaluations.
Fitted Q-Evaluation (FQE) and Doubly Robust (DR) estimators represent a hybrid approach to off-policy evaluation, mitigating the limitations of purely model-based or model-free techniques. FQE addresses high variance by learning a Q-function using data generated from the behavior policy, then evaluating the target policy using this learned function; this leverages the benefits of function approximation. DR estimators, conversely, reduce bias by requiring accurate estimation of either the reward function or the state-action visitation distribution, but not both. By combining learned models with importance sampling weights, both FQE and DR estimators achieve more stable and reliable performance estimates compared to methods relying solely on direct policy evaluation or inaccurate models. This robustness is particularly valuable in scenarios with complex state spaces or limited data.
Expanding the Horizon: Augmenting Static Datasets for Robust Learning
Trajectory augmentation addresses limitations in offline datasets by synthetically increasing the volume and diversity of experienced states. This is achieved through techniques that perturb existing trajectories or generate new ones based on learned models of the environment. The primary goal is to improve coverage of the state space, which is often sparse in real-world data collection. By expanding the represented states, the algorithm gains a more complete picture of possible scenarios, enabling it to better estimate the performance of different policies across a wider range of conditions and ultimately improving generalization capability.
Trajectory augmentation improves the generalization capability of Offline Policy Evaluation (OPE) methods by increasing the diversity of the training data. OPE relies on accurately estimating policy performance from a fixed dataset; however, limited coverage of the state-action space can lead to biased or unreliable evaluations. By synthetically expanding the dataset with augmented trajectories, OPE algorithms encounter a wider range of scenarios during training. This broader exposure reduces the variance of performance estimates and allows the evaluation to more accurately reflect the policy’s expected return across the entire state-action space, ultimately leading to more robust and trustworthy results.
Offline Reinforcement Learning (RL) methods are fundamentally limited by the quantity and diversity of data available in the offline dataset; trajectory augmentation directly mitigates this constraint. Insufficient data leads to poor generalization and unreliable performance estimates, particularly in states not well-represented in the original dataset. By synthetically expanding the dataset with augmented trajectories, typically generated through techniques like state perturbation or dynamics modeling, the effective data scarcity is reduced. This allows Offline Policy Evaluation (OPE) methods to more accurately assess policy performance across a broader state space, leading to improved policy selection and a realization of the potential benefits of offline RL algorithms when applied to complex, real-world problems.
Bridging the Gap: Offline RL for Seamless Human-Robot Collaboration
The effective integration of robots into human workflows necessitates robust methods for evaluating and refining collaborative strategies, and offline reinforcement learning (RL) coupled with offline policy evaluation (OPE) techniques are proving critical in this domain. Unlike traditional RL which requires extensive real-world interaction, offline RL leverages pre-collected datasets of human-robot interactions to train and assess policies without the risks and costs associated with on-the-fly learning. This approach allows researchers to systematically analyze and optimize robot behavior based on existing data, identifying policies that maximize collaboration quality, minimize human workload, and enhance overall team performance. By focusing on data-driven insights, offline RL and OPE provide a safe and efficient pathway to develop human-robot teams capable of seamlessly tackling complex tasks and fostering trust between human and robotic partners.
Advancements in evaluating human-robot collaboration hinge on the availability of rich datasets that move beyond simple task success metrics. Datasets derived from complex tasks, such as those found in the NASA-MATB-II challenge, are proving invaluable because they incorporate physiological data – measurements of human stress, cognitive load, and engagement – alongside traditional performance indicators. This integration allows for a more nuanced understanding of collaboration quality, moving beyond simply whether a task is completed to how it is completed and the cognitive burden placed on the human operator. By analyzing physiological signals, researchers can now assess a robot’s impact on human workload, trust, and overall interaction fluency, providing insights unattainable through conventional evaluation methods and paving the way for truly collaborative robotic systems.
A recent investigation into human-robot collaboration revealed a significant performance boost through the implementation of an offline reinforcement learning framework. This approach yielded a Trust Score of 4.54, establishing a new benchmark as the highest level of trust achieved by any agent within the study’s comparative analyses. The framework’s success isn’t merely quantitative; the elevated Trust Score suggests a more seamless and reliable interaction, fostering greater confidence in the robot’s capabilities and enhancing the overall collaborative experience for human partners. This result highlights the potential of offline RL to not only optimize task completion but also to cultivate a more positive and productive human-robot dynamic.
The implemented reinforcement learning agent demonstrably eased the cognitive burden on human collaborators, as evidenced by a NASA Task Load Index (TLX) score of just 55.8 – the lowest recorded in the study. This suggests a significantly reduced mental demand placed on the human operator during joint task execution. Complementing this finding, the agent achieved a Fluency Score of 5.2, a metric reflecting the naturalness and ease of interaction. This high score indicates that the agent’s actions were predictable and aligned with human expectations, fostering a seamless and intuitive collaborative experience – crucial for effective human-robot teaming and minimizing potential for errors or frustration during complex operations.
The study revealed significant improvements in task completion metrics attributable to the reinforcement learning agent. Specifically, the agent demonstrated a root mean squared error (RMSE) of 24.19 during tracking tasks, indicating high precision in maintaining target alignment and minimizing deviation. Furthermore, the agent exhibited a rapid response time of 9.12 seconds when monitoring system performance, suggesting an ability to quickly identify and react to critical changes or anomalies. These quantitative results collectively demonstrate the agent’s capacity to execute tasks efficiently and accurately, thereby enhancing overall human-robot team performance and potentially reducing cognitive load on the human operator.
![The frequency with which the automation system switched between tasks in the NASA Multi-Attribute Task Battery II (MATB-II) demonstrates the adaptability of its control strategy, with statistically significant differences ([latex]p<0.05[/latex], [latex]p<0.01[/latex], [latex]p<0.001[/latex]) observed between agent conditions using Mann-Whitney U tests.](https://arxiv.org/html/2602.02530v1/images/rocoa.png)
The research meticulously details a system built upon iterative testing, mirroring a fundamental principle of understanding through deconstruction. It observes that achieving seamless human-robot collaboration necessitates a constant challenging of established parameters – specifically, the state space selection and reward function design. This echoes Tim Berners-Lee’s sentiment: “The Web is more a social creation than a technical one.” The study isn’t merely about optimizing algorithms; it’s about building a system that adapts to the nuances of human interaction – a social ‘web’ of feedback gleaned from physiological data. By prioritizing off-policy evaluation, the framework actively seeks out the edges of its operational limits, much like reverse-engineering a complex system to reveal its underlying principles.
Unraveling the Code
The presented work, while a step forward, merely highlights the profound limitations in current approaches to human-robot collaboration. The reliance on physiological data, though promising, feels like reading a debug log without the source code. It reveals what is happening – increased workload, decreased trust – but not why, at a fundamental level. The true challenge isn’t optimizing a reward function; it’s reverse-engineering the human operator’s internal model of the task, the robot, and the shared environment. Reality, after all, is open source – it’s just that the language is extraordinarily complex.
Future iterations must move beyond treating the human as a black box, and embrace techniques that allow for a more direct interrogation of cognitive processes. Active learning, coupled with interpretable AI, could allow the robot to ask the human for clarification, effectively querying the source code. Furthermore, the limitations of offline reinforcement learning become glaringly apparent when considering the inherent variability of human behavior. A static dataset, no matter how large, can never fully capture the nuances of a dynamic interaction.
Ultimately, the field needs to acknowledge that perfect prediction is an illusion. The goal shouldn’t be to eliminate uncertainty, but to manage it gracefully. A truly collaborative robot will not attempt to anticipate every human action, but rather, will be robust to unexpected inputs, and capable of learning from its mistakes – much like a skilled apprentice. The next breakthrough will likely come not from more data, but from a fundamentally different approach to modeling human agency.
Original article: https://arxiv.org/pdf/2602.02530.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Limbus Company 2026 Roadmap Revealed
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Last Furry: Survival redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
2026-02-04 12:22