Author: Denis Avetisyan
A new reinforcement learning framework guides vision-language models to master complex, long-duration manipulation tasks through interactive feedback.
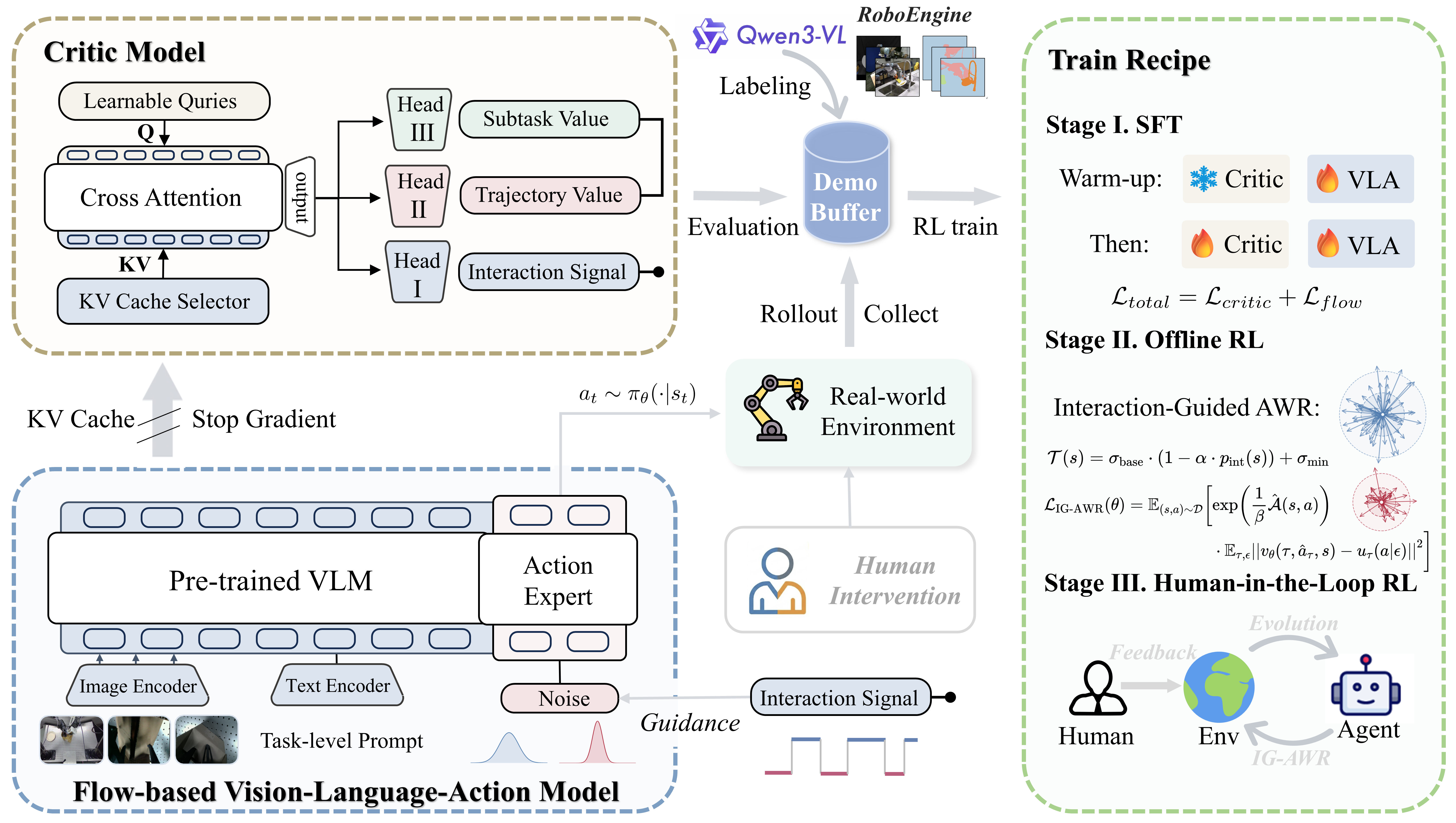
IG-RFT utilizes interaction guidance and a hybrid reward function to fine-tune flow-based Vision-Language-Action models for improved robotic manipulation performance.
Despite the promise of generalist robotic policies, Vision-Language-Action (VLA) models struggle with complex, long-horizon tasks in real-world settings due to distribution shifts and limited data. This paper introduces ‘IG-RFT: An Interaction-Guided RL Framework for VLA Models in Long-Horizon Robotic Manipulation’, a novel reinforced fine-tuning system that leverages interaction guidance and a hybrid dense reward function to overcome these challenges. Through a three-stage reinforcement learning approach, IG-RFT achieves an average success rate of 85.0% on challenging robotic manipulation tasks, significantly surpassing existing methods. Could this framework unlock more robust and adaptable robotic systems capable of tackling increasingly complex real-world problems?
Bridging the Perception-Action Gap: Toward Adaptive Robotics
Conventional robotic systems often falter when confronted with tasks demanding more than pre-programmed responses. These machines typically excel at repetitive, well-defined actions, but struggle with the ambiguity and unpredictability inherent in real-world scenarios. This limitation stems from a reliance on explicit instructions and a lack of capacity for abstract thought – the ability to reason about goals, understand context, and adapt to unforeseen circumstances. Unlike humans, who seamlessly integrate vision, language, and prior knowledge to navigate complex environments, traditional robots require painstakingly detailed programming for each specific situation, hindering their deployment in dynamic and unstructured settings. Consequently, advancements in artificial intelligence are crucial to imbue robots with the cognitive flexibility necessary to perform tasks requiring high-level reasoning and genuine adaptability.
Initial Vision-Language-Action (VLA) models, notably RT-1 and RT-2, represented a significant leap toward robots that could interpret instructions and interact with the world in a more intuitive way. These models successfully demonstrated the capacity to connect visual input with natural language and translate that understanding into physical actions; for instance, a robot could follow a command like “bring me the red block.” However, these early systems often struggled when faced with scenarios differing even slightly from their training data. This limited generalization meant that a robot trained in a tidy lab environment might fail when encountering clutter, unfamiliar objects, or even variations in lighting-highlighting the need for more robust and adaptable architectures capable of bridging the gap between perception, language, and action in truly dynamic real-world settings.
Addressing the challenges of robotic generalization requires a fundamental shift in how robots perceive and interact with the world. Current limitations stem from inefficient processing of the diverse information streams – visual input, natural language commands, and the demands of physical action – necessitating novel architectural designs. Researchers are actively exploring methods to create more compact and effective multimodal representations, allowing robots to distill essential information from complex sensory data and language instructions. These emerging architectures prioritize efficient information flow and shared representations, enabling robots to learn more quickly from limited data and adapt to previously unseen scenarios. The ultimate goal is to build robotic systems capable of robust action, not through pre-programmed responses, but through genuine understanding and flexible problem-solving in dynamic, real-world environments.

Flow-Based VLAs: A Paradigm Shift in Robotic Control
Flow-based Variable Length Action (VLA) architectures represent a departure from traditional robotic control methods by utilizing flow matching techniques to forecast sequences of actions. Instead of relying on discrete action spaces or complex planning algorithms, these models learn a continuous flow that maps states to actions. This is achieved by training a diffusion model to learn the underlying distribution of successful action sequences, allowing the robot to generate plausible and dynamically feasible actions given its current state. The core principle involves transforming the action prediction problem into a probabilistic flow, enabling the model to predict not just a single action, but a distribution over possible actions, which enhances robustness and adaptability in complex environments. This approach contrasts with methods requiring explicit state-action mappings, offering a more flexible and data-driven solution for robotic control.
Supervised fine-tuning is a critical step in deploying flow-based Variable Length Action (VLA) models for robotic control. While pre-trained flow matching models provide a foundational ability to generate action sequences, performance on specific robotic tasks requires adaptation through supervised learning. This process involves training the model on a dataset of demonstrations, where state-action pairs are provided for a target task. The model’s parameters are then adjusted to minimize the difference between its predicted actions and the demonstrated actions, effectively biasing the flow manifold towards successful task completion. Datasets used for fine-tuning typically consist of robot state observations and corresponding actions, enabling the model to learn task-specific policies and improve its accuracy, efficiency, and robustness in real-world scenarios.
Models π0 and π0.5 improve flow-based action prediction through the implementation of knowledge isolation and subtask decomposition. Knowledge isolation prevents interference between learned skills by maintaining separate pathways for different actions, enhancing generalization to novel situations. Subtask decomposition breaks down complex tasks into a sequence of simpler, manageable subtasks, allowing the model to learn and execute intricate behaviors more effectively. Specifically, π0 employs a purely generative approach, while π0.5 integrates discriminative components to refine subtask predictions and improve overall action sequence accuracy. This decomposition facilitates both efficient learning and robust performance in complex robotic manipulation scenarios.
![Dynamic Uncertainty Modulation in IG-AWR adjusts sampling noise based on interaction signals, increasing variance [latex]\sigma_{high}[/latex] during non-interaction to promote exploration and decreasing it to [latex]\sigma_{low}[/latex] during interaction to enhance precision in contact-rich manipulation.](https://arxiv.org/html/2602.20715v1/fig/IG_flow.png)
Reinforcement Learning: Cultivating Adaptable Virtual Learning Agents
Reinforcement Learning (RL) offers a robust methodology for training Virtual Learning Agents (VLAs) by enabling them to learn optimal policies through trial and error in dynamic environments. Unlike traditional control methods that rely on pre-programmed behaviors or explicit models, RL algorithms allow VLAs to maximize cumulative rewards over extended time horizons. This is achieved through an iterative process of exploration and exploitation, where the agent interacts with its environment, receives feedback in the form of rewards, and adjusts its actions to improve performance. The framework is particularly well-suited for complex environments characterized by high dimensionality, non-linearity, and uncertainty, where defining explicit control strategies is challenging or impractical. By learning directly from experience, RL-trained VLAs can adapt to changing conditions and optimize long-term objectives, exceeding the capabilities of conventional control systems in many applications.
Multi-stage training enhances the robustness and adaptability of Virtual Learning Agents (VLAs) by sequentially leveraging different learning paradigms. Initial Offline Reinforcement Learning (RL) utilizes previously collected datasets to pre-train the VLA, establishing a foundational policy. This is followed by Human-in-the-Loop RL, where human feedback refines the policy in real-time, addressing scenarios not adequately covered in the offline data. Finally, Supervised Fine-tuning, using labeled demonstrations, further optimizes performance and ensures adherence to desired behaviors. This staged approach mitigates the limitations of each individual method; Offline RL provides initial competence, Human-in-the-Loop RL improves generalization, and Supervised Fine-tuning ensures precise task execution, collectively leading to more robust and adaptable VLAs.
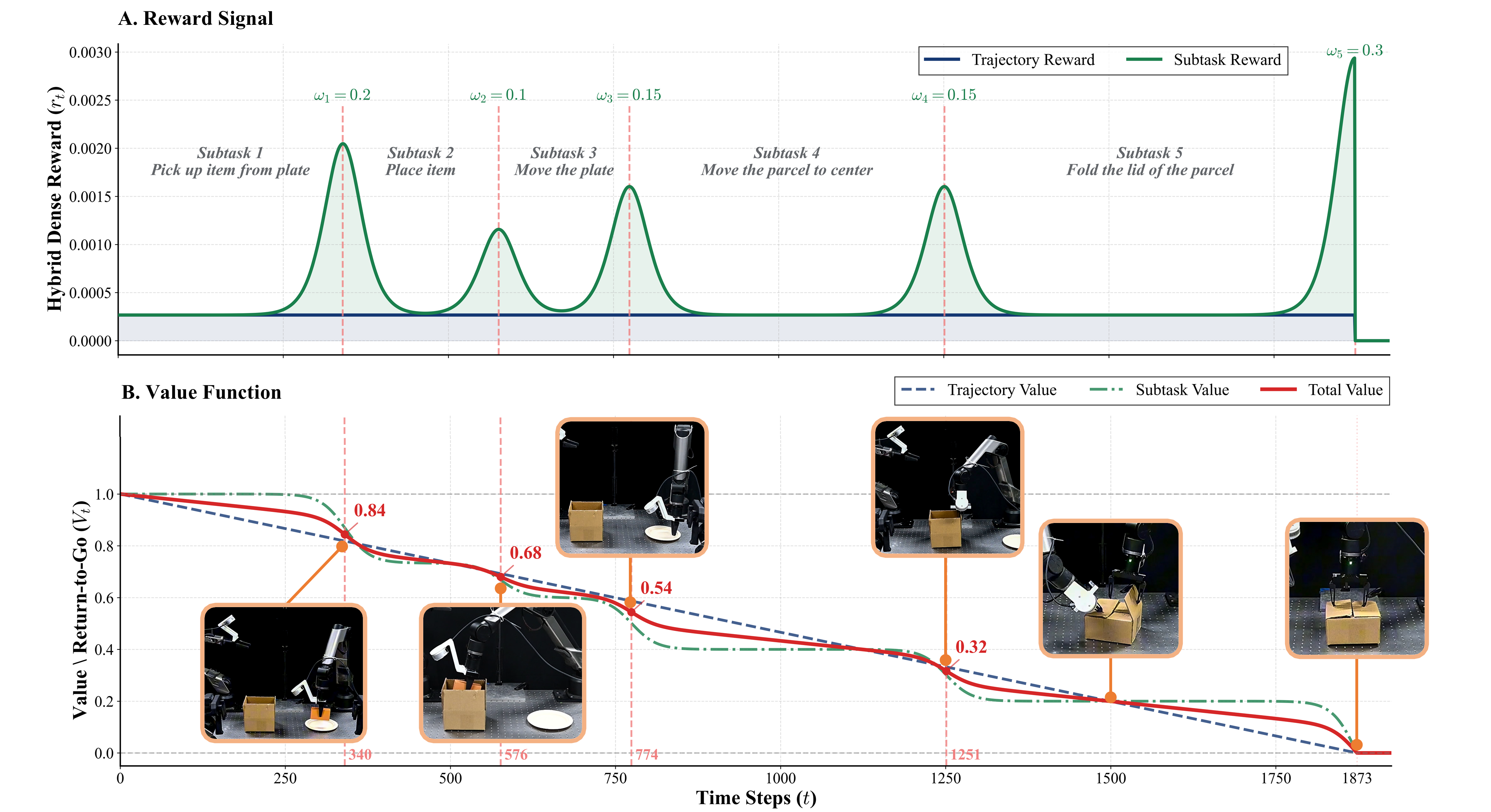
The reinforced fine-tuning system achieved an 85% overall success rate when tested on four complex robotic manipulation tasks. This performance represents a significant improvement compared to baseline methods. The system’s reward structure is a Hybrid Dense Reward system, integrating both Trajectory-Level Reward, which assesses the overall task completion, and Subtask-Level Reward, providing feedback on individual steps within the manipulation sequence. This combined approach facilitates more efficient learning and improved robustness in complex robotic operations.
Optimizing Exploration: The Impact of Interaction-Guided Advantage Weighted Regression
Interaction-Guided Advantage Weighted Regression, or IG-AWR, represents a significant advancement in reinforcement learning algorithms designed for robotic manipulation. This approach moves beyond static exploration strategies by dynamically modulating the intensity of exploration based on the robot’s current interaction with its environment. Essentially, IG-AWR prioritizes investigation in states where the robot is less certain about the optimal action, fostering more efficient learning. By focusing exploratory efforts where they are most needed – during periods of high uncertainty or when encountering novel situations – the algorithm enables faster adaptation and improved performance in complex tasks. This targeted exploration contrasts with conventional methods, which often expend resources on already-understood scenarios, and allows robots to more rapidly master challenging manipulation skills.
The efficacy of Interaction-Guided Advantage Weighted Regression (IG-AWR) stems from its ability to focus exploratory actions on states where the robot’s knowledge is limited, thereby accelerating the learning process for Visual Locomotion Agents (VLAs). Unlike standard Advantage Weighted Regression, which explores uniformly, IG-AWR utilizes feedback from the agent’s interactions to dynamically adjust exploration intensity – prioritizing areas of high uncertainty. This targeted approach results in a demonstrably improved performance in complex environments, evidenced by a 15% increase in task success rates compared to traditional AWR methods. Through concentrating learning efforts on genuinely novel situations, IG-AWR enables VLAs to acquire robust policies more efficiently, as demonstrated across various tasks with average completion times of 1731 steps for Parcel Packing, 2517 for Fruit Bagging, 1899 for Block Stacking, and 2931 for Drink Shelving.
A crucial component of successful robotic task learning lies in accurately assessing the value of each state, a function primarily fulfilled by the Critic Network – frequently implemented using architectures like Q-Former. This network provides the reinforcement learning agent with a predictive understanding of future rewards, thereby directing exploration towards the most promising areas of the state space. Empirical results demonstrate the effectiveness of this approach across a variety of manipulation tasks; robots utilizing this system completed Parcel Packing in an average of 1731 steps, Fruit Bagging in 2517 steps, Block Stacking in 1899 steps, and Drink Shelving in 2931 steps, indicating a consistent ability to efficiently navigate complex environments and achieve task goals through informed exploration.

The pursuit of robust robotic manipulation, as demonstrated by IG-RFT, echoes a fundamental tenet of system design: elegance arises from simplicity. This framework’s interaction guidance and hybrid reward function, while seemingly complex in implementation, aim to distill long-horizon tasks into manageable, learnable components. As Claude Shannon observed, “The most important thing in communication is to get the message across, not to make it clever.” Similarly, the system needn’t exhibit dazzling intricacy; its value lies in reliably achieving the desired manipulation, even if that necessitates a deliberate sacrifice of superficial sophistication. A fragile display of ingenuity offers little practical benefit; instead, the focus should be on a structure that dictates predictable, repeatable behavior.
Future Directions
The presented Interaction-Guided Reinforcement Learning framework, IG-RFT, represents a step towards more robust Vision-Language-Action models, yet the inherent limitations of any localized optimization become readily apparent. Achieving competence in long-horizon manipulation is not simply a matter of denser rewards or more interactive guidance; it is a problem of systemic coherence. The system’s behavior over time will always reveal the tensions created by any particular design choice. A refined reward function, for example, merely shifts the locus of failure, potentially creating unforeseen sensitivities to initial conditions or environmental variations.
Future work should resist the temptation to endlessly refine components in isolation. Instead, attention must turn towards holistic architectural principles. How can the model’s internal representation of action affordances be better aligned with the inherent symmetries and constraints of the physical world? The pursuit of ‘generalization’ often overlooks the fact that all systems operate within specific ecological niches. True robustness emerges not from eliminating constraints, but from explicitly modeling them.
Ultimately, the field requires a move away from treating robotic manipulation as a sequence of discrete actions. It is, at its core, a continuous process of negotiation between the agent and its environment. A truly elegant solution will not ‘solve’ the problem of manipulation, but rather dissolve it into a seamless interplay of perception, action, and anticipation.
Original article: https://arxiv.org/pdf/2602.20715.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Gold Rate Forecast
- Limbus Company 2026 Roadmap Revealed
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Total Football free codes and how to redeem them (March 2026)
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- All Mobile Games (Android and iOS) releasing in April 2026
2026-02-25 20:17