Author: Denis Avetisyan
A new framework, CUA-Skill, aims to bridge the gap between large language models and practical desktop automation by encoding reusable skills derived from human computer interaction.
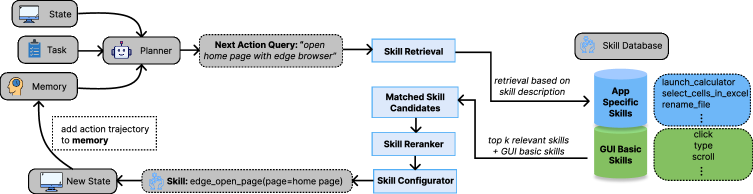
CUA-Skill introduces a structured skill library for computer-using agents, enabling improved performance and scalability in GUI-based tasks through skill composition and procedural knowledge.
While autonomous agents show promise in automating complex tasks, scaling these systems remains challenging due to a lack of reusable knowledge about human computer interaction. To address this, we introduce CUA-Skill: Develop Skills for Computer Using Agent, a large-scale library encoding human computer-use knowledge as parameterized skills and composition graphs. This approach substantially improves the success rate and robustness of computer-using agents on challenging desktop automation benchmarks, achieving state-of-the-art performance on WindowsAgentArena with a 57.5% success rate. Will this skill-based framework unlock a new generation of truly intelligent and adaptable computer-using agents capable of seamlessly interacting with desktop environments?
Deconstructing Automation: The Illusion of Control
The persistent challenge of automating commonplace computer tasks, despite significant strides in artificial intelligence, stems from the subtle complexities of human-computer interaction. While AI excels at defined problems with clear parameters, everyday computing often involves ambiguity, unexpected visual changes, and the need for flexible adaptation. Current automation systems frequently falter when confronted with slight variations in interface design, application updates, or even simple visual clutter. This isn’t a matter of lacking processing power, but rather a fundamental difficulty in replicating the human ability to interpret a visual scene, understand the intent behind an action, and recover gracefully from unexpected outcomes – skills that remain surprisingly elusive for even the most advanced algorithms.
The automation of even seemingly simple computer tasks is hampered by the unpredictable nature of graphical user interfaces. Unlike the precisely defined environments of robotics or game playing, GUIs present a constantly shifting landscape of visual elements, dynamic content, and user-driven events. Traditional automation techniques, often relying on image recognition or coordinate-based actions, struggle with variations in screen resolution, window positioning, and the subtle changes in appearance that occur with each software update. This inherent variability demands systems capable of robustly identifying interface elements despite superficial differences, and adapting to unexpected layouts or the appearance of new windows – a challenge that frequently necessitates more sophisticated approaches than simple pattern matching can provide.
Successfully automating common computer tasks demands more than simply reacting to visual cues; an agent must possess a functional memory of its preceding actions and the resulting system state. This requirement arises because graphical user interfaces are rarely static – elements shift, windows overlap, and responses to commands are not always predictable. Consequently, a system capable of true automation needs to establish a contextual understanding, retaining information about prior steps to intelligently navigate changing conditions and recover from unexpected outcomes. Without this capacity for retrospective analysis and adaptive behavior, agents become brittle and prone to failure when confronted with even minor deviations from pre-programmed scenarios, limiting their utility in real-world applications.
Successfully automating complex computer tasks demands a shift away from traditional stimulus-response systems. These conventional architectures treat each user interface element as an isolated problem, reacting to immediate visual cues without contextual understanding. Instead, effective automation requires an architecture capable of maintaining internal state – a ‘memory’ of prior actions and their consequences. This allows the system to interpret the current interface not as a static snapshot, but as an evolving situation influenced by its own past interactions. Such an architecture facilitates adaptation to unexpected changes, like pop-up windows or shifting element positions, and enables proactive behavior, anticipating future steps based on learned patterns. Ultimately, moving beyond simple reaction necessitates building agents that can reason about the user interface as a dynamic environment, mirroring the way a human user navigates and understands it.
CUA-Skill: Dissecting Intent into Reusable Components
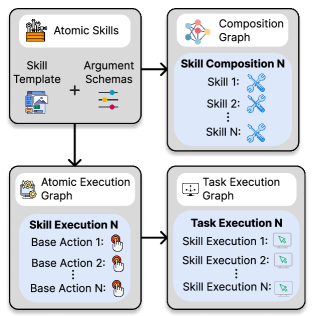
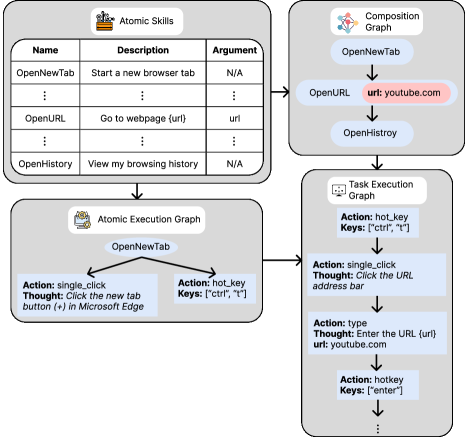
CUA-Skill represents human computer-use knowledge through a library of discrete ‘Skills’. Each Skill encapsulates a single, minimal user intent – representing the smallest identifiable unit of user action required to achieve a specific sub-goal. This decomposition allows for granular reuse; rather than storing entire workflows, CUA-Skill focuses on cataloging individual user intentions. The modularity of these Skills facilitates their combination and adaptation to various computing tasks and interfaces, independent of the specific application or operating system. This approach contrasts with monolithic automation systems by prioritizing the reusability of core user intentions over pre-defined, inflexible sequences.
Each CUA-Skill incorporates parameterized execution and composition graphs to facilitate adaptability across varying contexts. The execution graph defines the concrete steps – GUI interactions or script executions – required to fulfill the Skill’s intent, with parameters allowing for modification of these steps based on the current environment or user preferences. Simultaneously, the composition graph details how a Skill can be integrated into larger workflows; parameters within this graph control the Skill’s input and output connections, enabling dynamic chaining with other Skills. This dual-graph approach, coupled with parameterization, allows a single Skill definition to be reused in numerous scenarios without requiring code modification, increasing the overall flexibility and maintainability of the system.
The Skill Composition Graph serves as a declarative representation of complex workflows by defining the relationships and sequence of individual Skills. This graph is not an execution pathway itself, but rather a blueprint that specifies which Skills are required and the order in which they must be applied to achieve a specific user intent. Nodes within the graph represent individual Skills, while directed edges denote dependencies – indicating that the output of one Skill serves as input for the next. Crucially, the graph allows for branching and looping, enabling the construction of non-linear workflows and the representation of conditional logic within the overall process. This compositional approach facilitates the creation of complex behaviors from a library of simpler, reusable Skills, promoting modularity and maintainability.
The Skill Execution Graph functions as the runtime engine for CUA-Skill workflows, translating the abstract Skill Composition Graph into concrete actions. This realization is achieved through two primary mechanisms: direct manipulation of the Graphical User Interface (GUI) and execution of pre-defined scripts. GUI interactions involve programmatically controlling UI elements – such as button clicks, text entry, and menu selections – to simulate user behavior. Alternatively, executable scripts, written in languages like Python or Bash, can be invoked to perform more complex or system-level tasks, allowing Skills to extend beyond simple UI automation and integrate with external processes or data sources. The choice between GUI interaction and script execution is determined by the specific requirements of the Skill and the available system resources.
Retrieval and Planning: A Symphony of Observation and Action
The LLM Planner functions as the central decision-making component, interpreting natural language instructions and the current operational context to determine the optimal sequence of Skills for task completion. This selection process involves parsing the input to identify the desired objective and relevant parameters, then matching these to available Skills based on their defined capabilities and pre-conditions. Configuration of the selected Skills includes setting specific arguments and variables to tailor their execution to the current situation, ensuring alignment with the overall task goals and environmental constraints. The Planner dynamically adjusts Skill selection and configuration based on real-time feedback and changes in context, enabling adaptability and robustness in automated processes.
Retrieval-Augmented Planning (RAP) operates by dynamically integrating information retrieval with the agent’s planning process. Rather than relying solely on pre-defined plans, RAP actively queries both the current environment – gathering real-time data about the state of the world – and a dedicated ‘Memory Module’ during plan execution. This module stores data relating to task progression, observed outcomes, and historical interactions. Retrieved information is then used to refine the agent’s understanding of the situation, adjust its planned actions, and enable iterative refinement of its strategy as new data becomes available. This interweaving of retrieval and action allows for more flexible and robust automation, particularly in dynamic or unpredictable environments.
The Memory Module functions as a persistent store for task execution data, including completed steps, observed outcomes, and environmental states. This historical information is structured and represented as a Knowledge Graph, a network of entities and relationships that facilitates reasoning and inference. By leveraging the Knowledge Graph, the agent can analyze past performance, identify patterns, and update its internal beliefs about the environment and the effects of its actions. This capability allows for continuous learning and adaptation, enabling the agent to improve its planning and execution strategies over time and address novel situations more effectively.
GUI Grounding establishes a direct correspondence between natural language instructions and specific graphical user interface (GUI) elements. This process involves identifying on-screen targets – such as buttons, fields, or icons – that correspond to the actions described in the instruction. The system utilizes computer vision techniques and object recognition to locate these elements within the screen capture. Once identified, the system can accurately direct actions – like clicks or text input – to the correct GUI component, effectively translating linguistic intent into concrete user interface interactions. This capability is crucial for automation tasks requiring precise control of desktop applications and virtual environments.
Beyond the Benchmark: Towards a Truly Autonomous Digital Agent
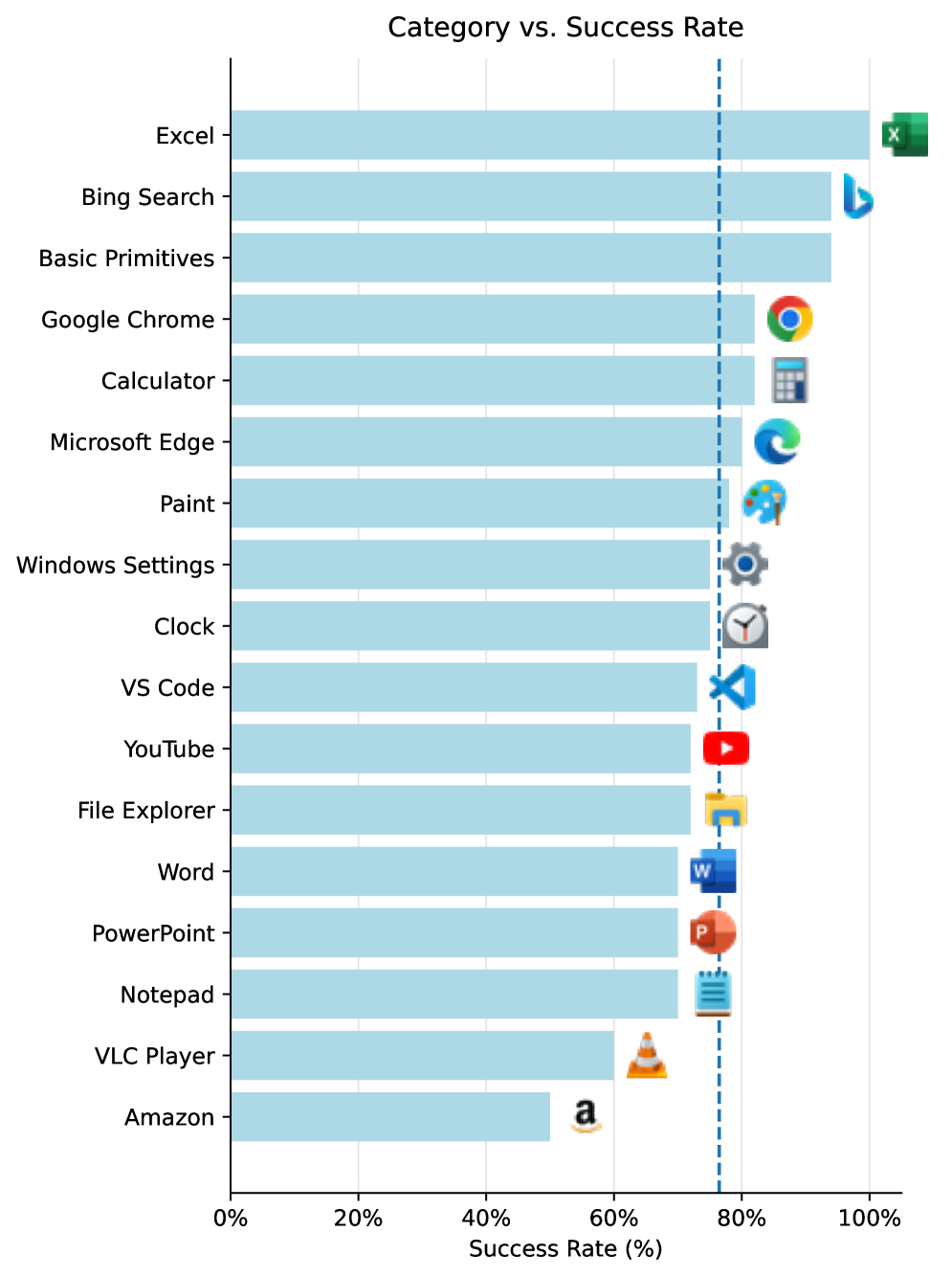
CUA-Skill’s capabilities were rigorously tested using ‘WindowsAgentArena’, a specialized benchmark created to evaluate the proficiency of artificial agents in performing tasks within a standard Windows environment. This benchmark presents a complex series of challenges requiring agents to navigate graphical user interfaces, interpret visual information, and execute commands – mirroring the actions of a human computer user. By assessing performance on ‘WindowsAgentArena’, researchers gain valuable insights into an agent’s ability to reliably automate computer-based workflows, a crucial step towards developing truly versatile and helpful AI assistants. The platform facilitates a standardized comparison of different agent architectures and allows for quantifiable measurement of progress in the field of computer-using AI.
Evaluations on the ‘WindowsAgentArena’ benchmark reveal CUA-Skill’s robust capability in executing intricate computer-based tasks. The agent achieved a state-of-the-art success rate of 57.5% when completing tasks in a best-of-three format, demonstrating a marked advancement over current methodologies. This performance isn’t simply about completing tasks, but doing so reliably, indicating a significant leap toward agents capable of consistently navigating and interacting with desktop environments. The results highlight the effectiveness of the system’s design, suggesting a pathway to more dependable and user-friendly automated interactions with computers.
The achieved performance signifies a substantial leap forward in the field of autonomous agent capabilities, demonstrably exceeding the limitations of prior methodologies. This advancement isn’t simply about achieving a higher success rate; it underscores the powerful synergy between reusable skills and retrieval-augmented planning. By predefining a library of adaptable skills, the agent avoids redundant problem-solving, instead focusing on intelligently retrieving and combining these skills to address new challenges. This approach not only accelerates task completion but also enhances robustness and adaptability, allowing the agent to navigate complex environments with greater efficiency and reliability compared to systems reliant on monolithic planning or purely reactive behaviors. The results validate the potential of this skill-based architecture to unlock more sophisticated and versatile artificial intelligence.
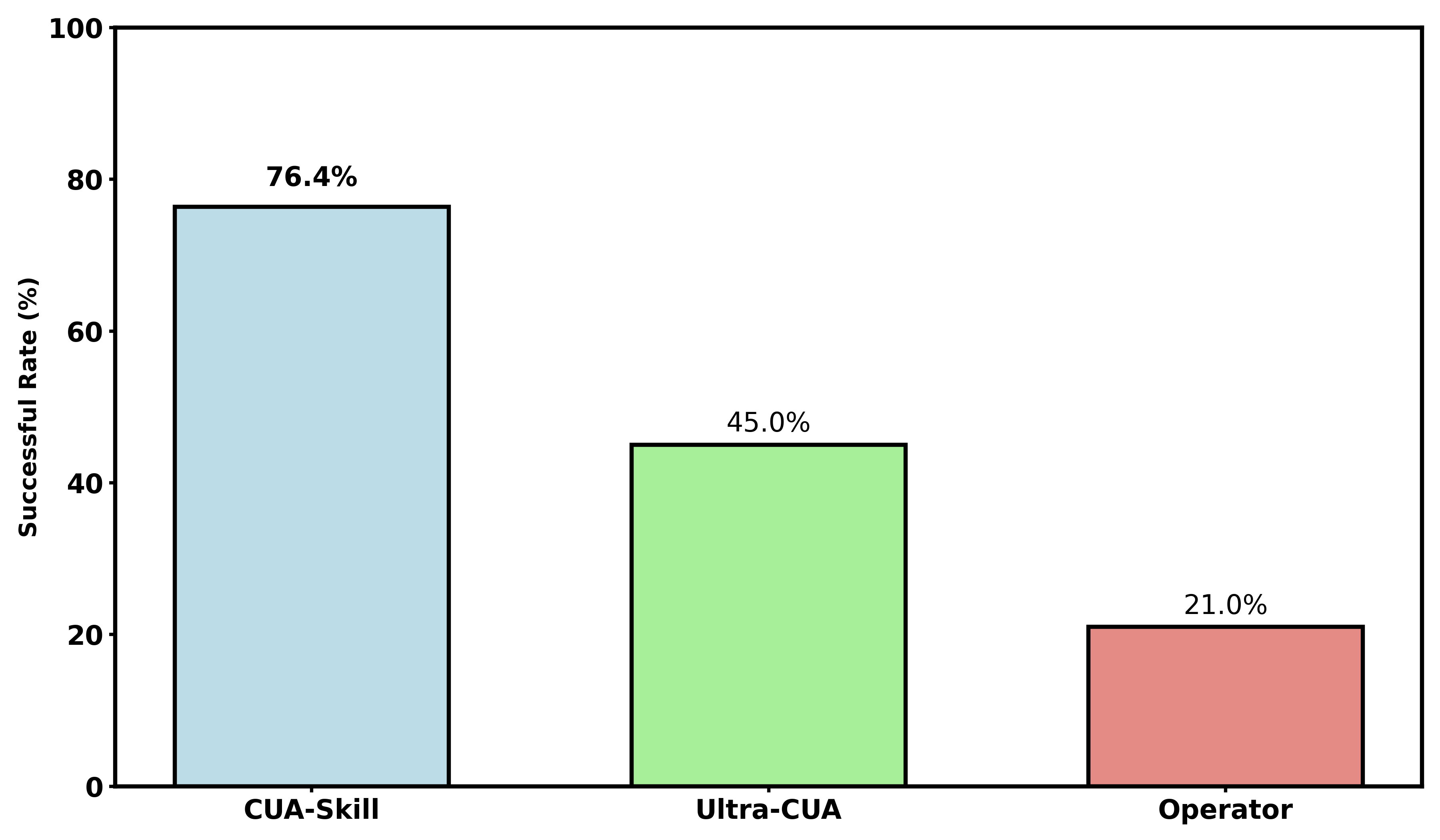
CUA-Skill demonstrates a marked advancement in navigational planning, achieving a 76.4% success rate in generating effective task trajectories. This figure notably surpasses the performance of existing agents, Ultra-CUA and Operator, with improvements ranging from 1.7 to 3.6 times greater efficacy. This enhanced trajectory generation suggests CUA-Skill’s architecture facilitates more robust and reliable task completion, likely due to its skill-based approach and retrieval-augmented planning capabilities. The substantial increase in successful trajectories underscores the potential of this methodology for building more capable and autonomous computer-using agents.
Continued development of this agent centers on expanding its repertoire of executable skills, moving beyond the current library to encompass a broader range of computer-using actions. Simultaneously, researchers are prioritizing enhancements to the agent’s robustness when encountering novel or unexpected scenarios – situations not explicitly covered in its training data. A key component of this involves integrating mechanisms for real-time learning from user feedback, allowing the agent to adapt its behavior and refine its skill execution based on direct human input. This adaptive learning capability promises to significantly improve the agent’s overall performance and usability in dynamic, real-world environments, paving the way for more intuitive and effective human-computer interaction.
The development of CUA-Skill exemplifies a systematic deconstruction of human-computer interaction. This framework doesn’t merely automate tasks; it dissects them into fundamental, reusable skills – a process akin to reverse-engineering the very act of using a computer. As G.H. Hardy observed, “A mathematician, like a painter or a poet, is a maker of patterns.” Similarly, CUA-Skill constructs patterns of procedural knowledge, allowing agents to not simply perform actions, but to understand and recombine them for novel desktop automation challenges. The skill library becomes a palette, and the agent, an artist, composing solutions from fundamental components, thus showcasing the power of structured knowledge representation.
Beyond the Skillset
The construction of CUA-Skill represents, predictably, a local maximum. The system successfully externalizes procedural knowledge, encoding human computer interaction as modular, reusable components. However, the very act of formalizing this knowledge reveals its inherent messiness. The ‘skill’ itself proves a surprisingly brittle construct; a successful desktop automation isn’t simply a composition of perfect skills, but a negotiation with the inevitable imperfections of the interface. Future work must address the limits of discrete skill representation – how to encode the ‘art’ of adaptation, the quick course corrections inherent in even the simplest human-computer dialogue.
A genuine exploit of comprehension will lie in moving beyond skill composition towards skill evolution. The framework currently positions the human as the sole architect of these procedural building blocks. The next iteration must consider autonomous skill refinement – an agent capable of observing its own failures, reverse-engineering the underlying causes, and generating improved skill variants. This isn’t merely about improved performance; it’s about replicating the fundamental characteristic of intelligence: self-modification.
Ultimately, the true challenge isn’t automating tasks, but automating the learning of tasks. CUA-Skill provides a useful scaffolding, but the real system to be built resides in the space between defined skills – in the agent’s ability to navigate ambiguity, to generalize from incomplete information, and to, occasionally, break the rules in order to discover new ones.
Original article: https://arxiv.org/pdf/2601.21123.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
2026-02-01 04:06