Author: Denis Avetisyan
This research details a novel framework for training teams of autonomous agents to map and navigate complex indoor spaces.
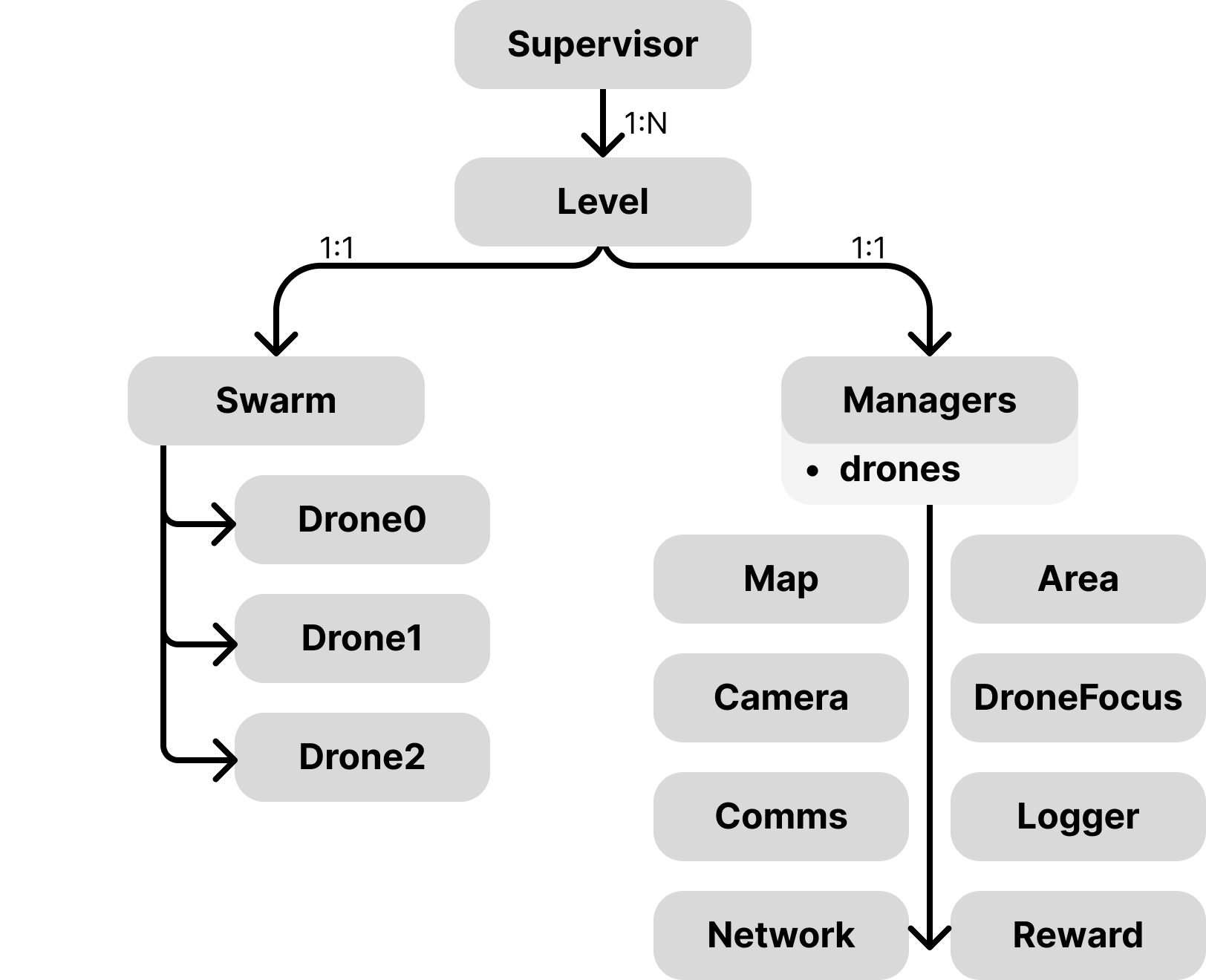
A multi-agent reinforcement learning approach using the Godot Engine and decentralized communication for efficient, collaborative exploration.
Autonomous exploration in challenging, GPS-denied indoor environments demands robust coordination despite limited communication and uncertain perceptions. This is addressed in ‘IMAGINE: Intelligent Multi-Agent Godot-based Indoor Networked Exploration’ which presents a multi-agent reinforcement learning framework for collaborative UAV navigation, leveraging a high-fidelity Godot engine simulation and decentralized Partially Observable Markov Decision Processes (POMDPs). Results demonstrate that a scalable training paradigm, combined with curriculum learning and a simplified neural network architecture, enables rapid and robust autonomous exploration. Could this approach pave the way for deploying truly cooperative robotic systems in complex, real-world scenarios?
The Inevitable Swarm: Beyond Single Agents
Many real-world challenges, from robotic swarms navigating disaster zones to autonomous vehicles merging onto highways, present complexities that quickly overwhelm the capacity of a single intelligent agent. These environments are often characterized by incomplete information, dynamic obstacles, and the need for collaborative problem-solving. Attempts to address these scenarios with a solitary agent often result in brittle solutions-systems that fail when confronted with even minor deviations from their training data. The limitations stem from the exponential growth in computational demands as the state-space expands-a phenomenon that makes exhaustive planning or search impractical. Consequently, a distributed approach, leveraging the collective intelligence of multiple agents, becomes not merely advantageous, but fundamentally necessary to achieve robust and scalable solutions in such intricate systems.
Centralized control systems, while effective in static and predictable environments, encounter significant limitations when applied to dynamic multi-agent scenarios. The core issue lies in the exponential growth of computational complexity as the number of agents increases; a single controller must process information from, and issue commands to, every agent, rapidly becoming overwhelmed. Furthermore, these systems exhibit poor robustness; a single point of failure – the central controller – can cripple the entire system. Changes in the environment, or the failure of even one agent, necessitate recalculation of optimal strategies for all agents, leading to delays and inefficiencies. Consequently, traditional approaches struggle to adapt to the inherent uncertainty and evolving conditions characteristic of complex, real-world applications like robotic swarms, traffic management, and distributed sensor networks, paving the way for decentralized alternatives.
The increasing complexity of real-world problems is driving a fundamental shift in artificial intelligence, moving beyond single, monolithic agents to systems comprised of multiple interacting entities. Traditional centralized control falters when faced with the scale and dynamism of these environments, prompting exploration of decentralized approaches. Multi-Agent Reinforcement Learning (MARL) emerges as a particularly promising solution, allowing agents to learn optimal behaviors through trial and error, not in isolation, but in response to each other and the evolving environment. This learning paradigm fosters adaptability and robustness, as agents collectively discover strategies that outperform pre-programmed solutions, and can even exhibit emergent behaviors – complex, coordinated actions not explicitly designed but arising from the interactions themselves. Consequently, MARL is rapidly becoming a core methodology for tackling challenges in fields ranging from robotics and game theory to economics and traffic management, promising systems that are not only intelligent, but also resilient and scalable.
The Illusion of Control: Training and Execution
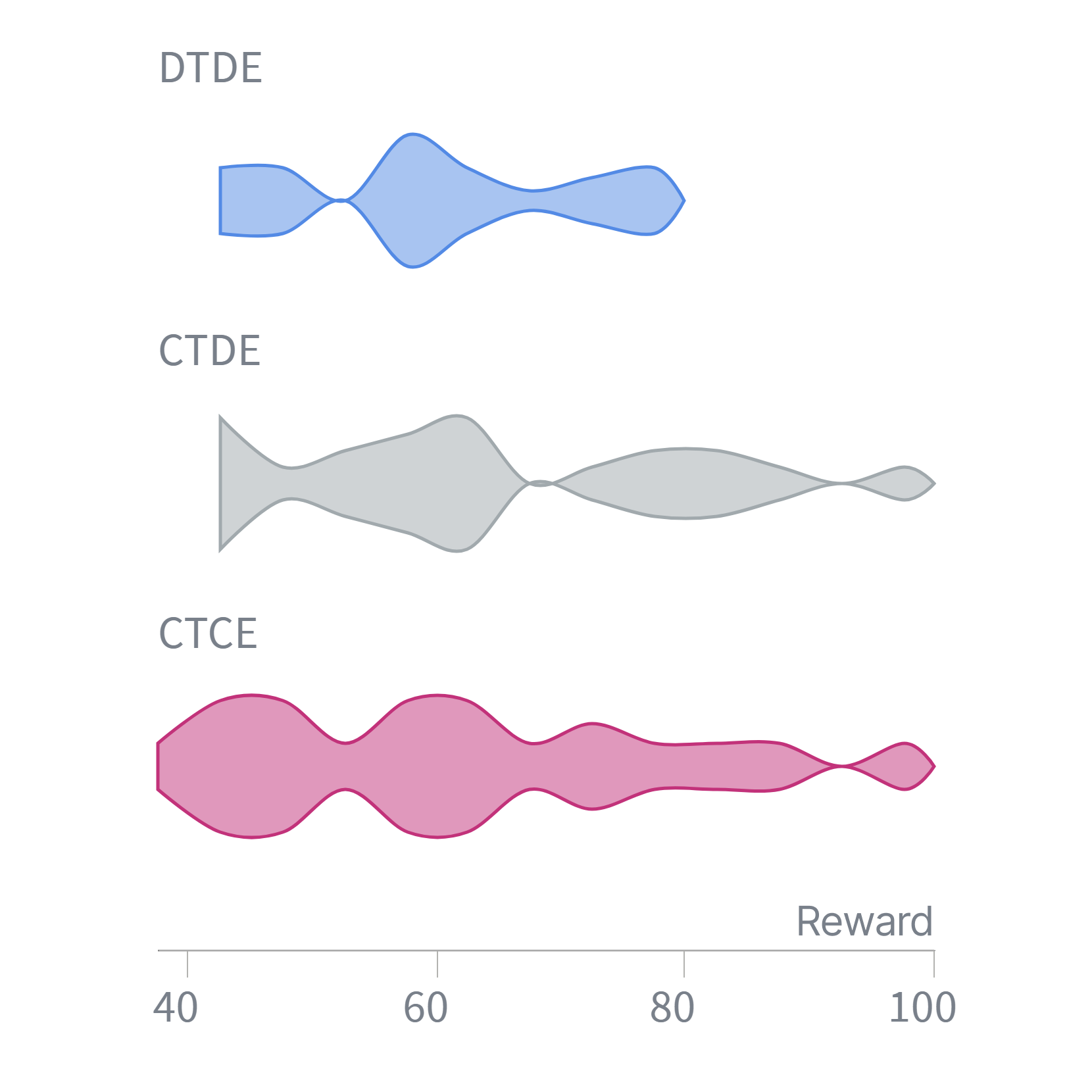
Centralized Training, Decentralized Execution (CTDE) and Centralized Training, Centralized Execution (CTCE) represent prominent methodologies for developing cooperative policies in multi-agent systems. CTCE involves both the training and execution phases occurring under a centralized control mechanism, allowing for complete information access and coordinated action selection. CTDE, conversely, utilizes a centralized training process to learn optimal policies, but then distributes the execution of these policies to individual agents acting independently. Both approaches benefit from the stability and efficiency afforded by centralized learning, while CTDE specifically addresses scalability concerns by enabling decentralized action during deployment, which is crucial for complex and dynamic environments.
Both Centralized Training Centralized Execution (CTCE) and Centralized Training Decentralized Execution (CTDE) utilize a centralized critic during the training phase to enhance the accuracy of value estimations. This centralized critic has access to global state information, allowing it to compute a more precise assessment of the long-term reward achievable by each agent’s actions than would be possible with decentralized critics relying only on local observations. The improved value estimates provided by the centralized critic directly facilitate more efficient learning of optimal policies for the individual agents, as they reduce the variance and bias in the policy gradient updates and accelerate convergence to a stable solution.
The use of a centralized critic, while effective for training multi-agent systems, presents challenges regarding scalability and real-time application. A single critic requires access to the observations and actions of all agents, creating a communication bottleneck as the number of agents increases. This centralized dependency also limits the system’s ability to operate efficiently in dynamic environments demanding low-latency responses. Consequently, fully decentralized approaches, where each agent learns and acts independently based on its local observations, are gaining prominence as solutions to overcome these limitations and enable deployment in complex, real-world scenarios.
Mapping the Unknown: Perception and Localization
Simultaneous Localization and Mapping (SLAM) addresses the chicken-and-egg problem of determining both the agent’s location and a map of its surroundings concurrently. Traditional methods required a priori knowledge of either the map or the agent’s pose; SLAM algorithms overcome this limitation by iteratively refining both the map and the pose estimate. This is achieved through sensor data – typically from LiDAR, cameras, or inertial measurement units – which is used to identify landmarks or features in the environment. These features are then used in optimization algorithms, such as Kalman filters or graph-based methods, to minimize the uncertainty in both the map and the agent’s estimated trajectory. The resulting map can take various forms, including occupancy grids, feature maps, or topological maps, depending on the application and sensor suite.
LiDAR sensors provide dense 3D point cloud data representing the surrounding environment, which serves as primary input for many SLAM systems. This raw data is often computationally expensive to process directly; therefore, Convolutional Neural Networks (CNNs) are frequently integrated to extract meaningful features and reduce dimensionality. CNNs can be trained to identify and classify objects, edges, and planes within the point cloud data, facilitating robust environment perception. The processed data is then used to construct occupancy grid maps (OGMs), which discretize the environment into a grid of cells, each representing the probability of being occupied by an obstacle. OGMs provide a compact and efficient representation of the environment suitable for path planning and navigation algorithms within the SLAM framework.
Unmanned Aerial Vehicles (UAVs) necessitate robust Simultaneous Localization and Mapping (SLAM) capabilities due to the inherent challenges of aerial operation in complex and dynamic environments. Unlike ground-based robots, UAVs experience six degrees of freedom, increasing positional error and requiring more frequent map updates. Furthermore, environments containing moving obstacles, variable lighting conditions, and limited GPS availability – such as indoor spaces, forests, or urban canyons – degrade the performance of traditional localization methods. Consequently, accurate and real-time SLAM is critical for UAV path planning, obstacle avoidance, and successful mission completion in these conditions, enabling autonomous navigation and data collection where reliance on pre-existing maps or external positioning systems is insufficient.
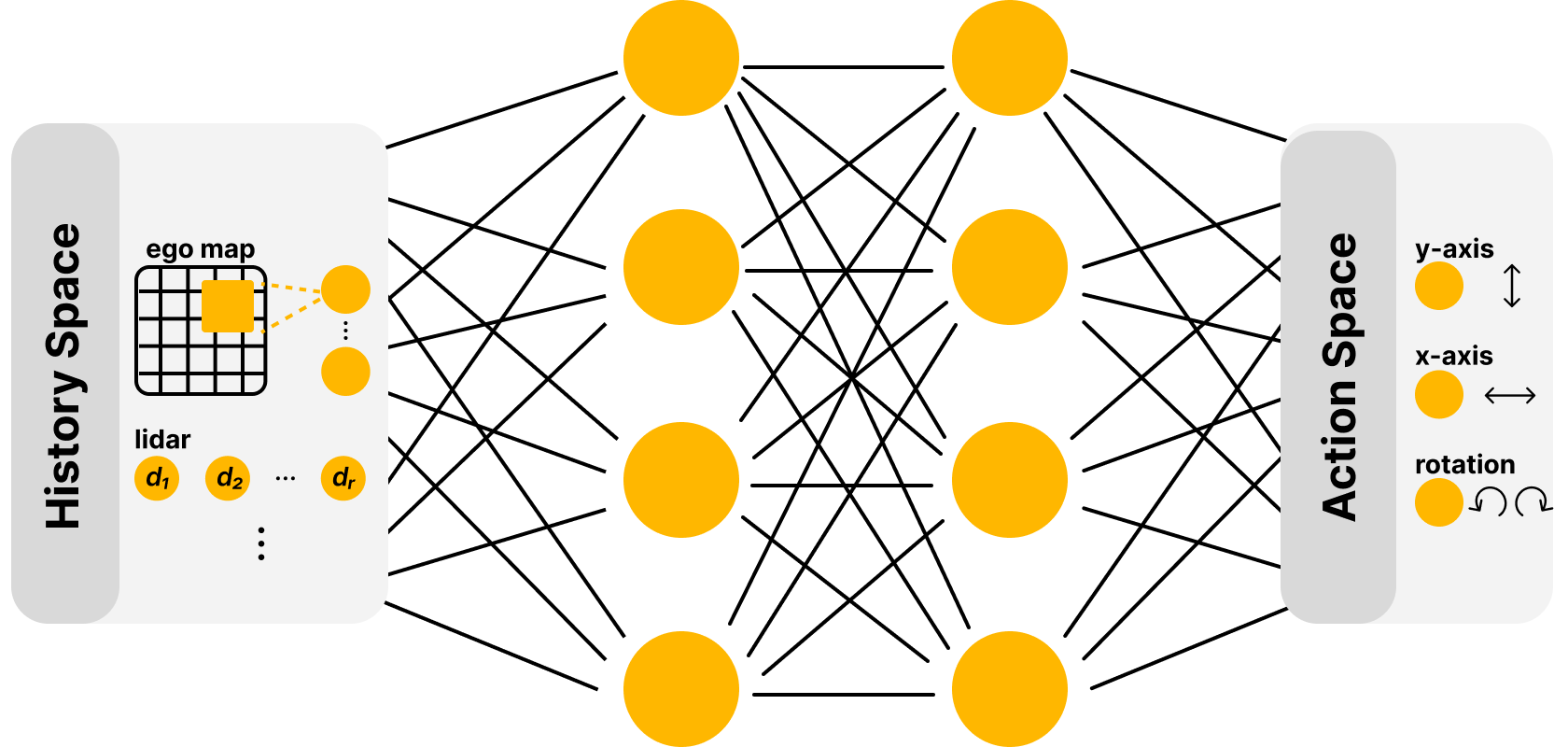
![The UAV utilizes simulated [latex] ext{LiDAR}[/latex] rays to construct a local map (red) and provides an egocentric view (yellow) to its policy network for navigation.](https://arxiv.org/html/2602.02858v1/drone_lidar_obs_map.png)
The Architecture of Intelligence: Algorithms and Infrastructure
Deep Reinforcement Learning (DRL) algorithms have become foundational within Multi-Agent Reinforcement Learning (MARL) due to their capacity to enable agents to learn sophisticated behaviors through trial and error. Algorithms like Proximal Policy Optimization (PPO) are particularly favored; PPO refines the balance between exploring new strategies and exploiting existing ones, preventing drastic policy changes that could destabilize the learning process. This is achieved through a ‘trust region’ approach, ensuring that each update to the agent’s policy remains relatively close to the previous one. Consequently, agents can effectively navigate complex environments and learn coordinated actions, even when operating within a dynamic, multi-agent system where the actions of others constantly reshape the landscape. The result is a robust learning framework capable of tackling intricate challenges that demand adaptability and strategic interaction.
Multi-agent reinforcement learning (MARL) often faces challenges when scaling Deep Reinforcement Learning (DRL) to scenarios involving numerous interacting agents. Algorithms such as MAPPO and QMIX address these difficulties by extending foundational DRL techniques. MAPPO, building on the popular PPO algorithm, facilitates efficient parallel training of multiple agents, enabling them to learn coordinated strategies. QMIX, conversely, employs a centralized training with decentralized execution paradigm, allowing for a more comprehensive understanding of the multi-agent system during training while maintaining individual agent autonomy during operation. These advancements result in improved stability and scalability, allowing agents to effectively navigate complex environments and achieve collective goals that would be unattainable with traditional single-agent methods.
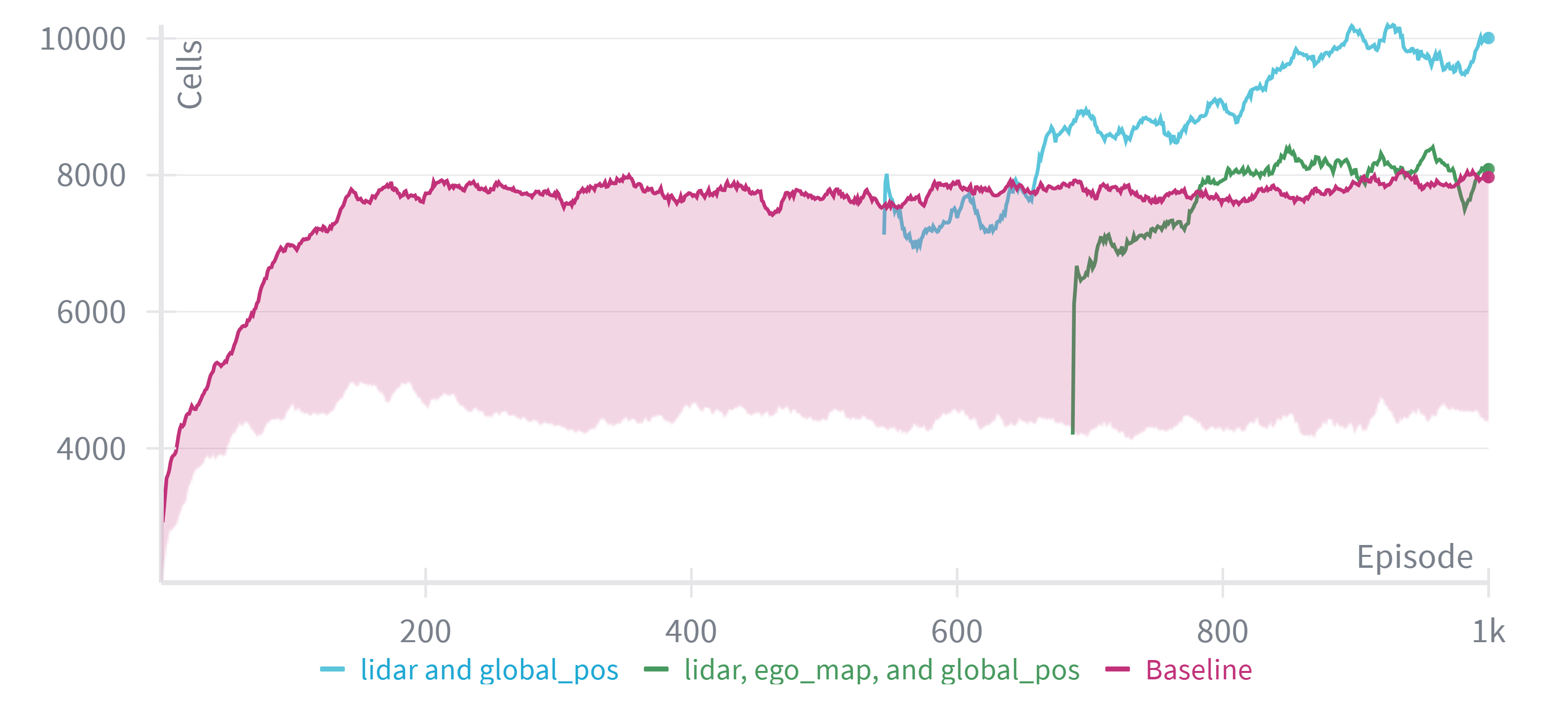
Effective training of multi-agent reinforcement learning algorithms demands considerable computational power, frequently necessitating the utilization of High-Performance Computing (HPC) clusters. These systems, often orchestrated by workload management tools such as SLURM, enable the parallel processing essential for complex simulations. Recent advancements demonstrate the efficacy of this approach; the implementation of LiDAR convolutions yielded a 20% improvement in algorithmic performance, while the integration of curriculum learning-a technique that gradually increases the complexity of training scenarios-resulted in a remarkable 250% acceleration of the training process itself. This synergy between advanced algorithms and robust computational infrastructure is proving crucial for scaling multi-agent systems to tackle increasingly challenging real-world problems.
The Networked Future: Beyond Idealized Systems
Current approaches to multi-agent reinforcement learning often assume perfect communication, a simplification rarely found in real-world scenarios. Researchers are now focusing on extending the foundational Markov Decision Process (MDP) framework to explicitly model communication constraints, leading to the development of Network Distributed Partially Observable Markov Decision Processes (ND-POMDPs). These ND-POMDPs allow for the representation of limited bandwidth, noisy channels, and intermittent connectivity between agents, creating a more realistic and challenging environment for algorithm development. By incorporating these communication limitations directly into the problem formulation, algorithms can be designed to learn robust policies that account for imperfect information and adapt to dynamic network conditions, ultimately paving the way for more reliable and scalable multi-agent systems in complex environments.
Decentralized Training Decentralized Execution (DTDE) signifies a fundamental shift in the development of multi-agent systems, moving away from centralized control and monolithic architectures. This paradigm prioritizes scalability and robustness by distributing both the learning process and subsequent operational control across individual agents. Rather than relying on a single, potentially vulnerable, coordinating entity, DTDE enables agents to learn independently, adapting to local information and collaboratively achieving global objectives. This approach not only mitigates single points of failure, enhancing system resilience, but also allows for significantly greater scalability as the number of agents increases, as computational demands are shared rather than concentrated. The benefits extend to environments characterized by uncertainty or dynamic change, where decentralized agents can respond more quickly and effectively to localized events without requiring global re-planning or communication bottlenecks.
Integrating Rapidly-exploring Random Trees (RRT)-based motion planning with multi-agent systems offers a pathway to more effective navigation and task execution for robotic platforms like Unmanned Aerial Vehicles (UAVs). Recent studies demonstrate a 13% performance improvement when Recurrent Neural Networks (RNNs) are incorporated to enhance temporal reasoning within the RRT framework. This allows the system to better anticipate and react to dynamic environments. However, this integration isn’t without trade-offs; optimized configurations prioritizing temporal reasoning resulted in a 12.5% reduction in overall area coverage compared to the highest-performing standalone RNN setup, highlighting the ongoing challenge of balancing responsiveness with comprehensive environmental exploration.
The pursuit of decentralized multi-agent systems, as demonstrated in this exploration of UAV navigation, inevitably courts increasing systemic dependency. The architecture detailed here, leveraging a high-fidelity simulation and curriculum learning, isn’t simply building robots; it’s cultivating an ecosystem where individual agents’ fates become inextricably linked through communication and shared perception. As Claude Shannon observed, “Communication is the conveyance of meaning, not just information.” This framework understands that successful exploration isn’t merely about collecting data, but about agents interpreting and acting upon a shared, evolving understanding of the environment-a fragile consensus perpetually threatened by the inherent complexities of decentralized systems. The more connections are forged, the more vulnerable the whole becomes, mirroring the tendency toward dependency that defines complex systems.
What Lies Beyond?
This work, like all attempts to choreograph intelligence, reveals less about controlling agents and more about the illusions of control itself. The framework presented offers a compelling simulation, a contained garden where coordinated exploration blooms. But every garden eventually abuts a wilderness. The true test won’t be achieving consensus in a predictable environment, but graceful degradation when communication frays, sensors fail, or the unknown truly resists categorization.
The emphasis on curriculum learning feels less like a solution and more like a postponement. It acknowledges the brittleness of these systems, the need for carefully sculpted training regimes. Yet, complexity accrues. Each added constraint, each hand-tuned progression, adds to the surface area for future failure. Order is, after all, just a temporary cache between inevitable collapses. The field will likely shift toward architectures that embrace – rather than resist – emergent behavior, systems designed to recover from chaos, not prevent it.
Ultimately, this isn’t about building intelligent agents; it’s about cultivating ecosystems where intelligence can arise. The Godot Engine provides a compelling substrate, but the real challenge lies in designing for adaptation, for resilience, and for the beautiful, unpredictable messiness of true exploration. The future belongs not to those who seek to command, but to those who learn to listen.
Original article: https://arxiv.org/pdf/2602.02858.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Limbus Company 2026 Roadmap Revealed
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Total Football free codes and how to redeem them (March 2026)
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- Gold Rate Forecast
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Peaky Blinders: The Immortal Man brought back a ‘missing’ Shelby – and you didn’t notice
2026-02-04 19:18