Author: Denis Avetisyan
New research evaluates the best methods for equipping AI chatbots with the knowledge they need to answer questions about complex scientific literature.
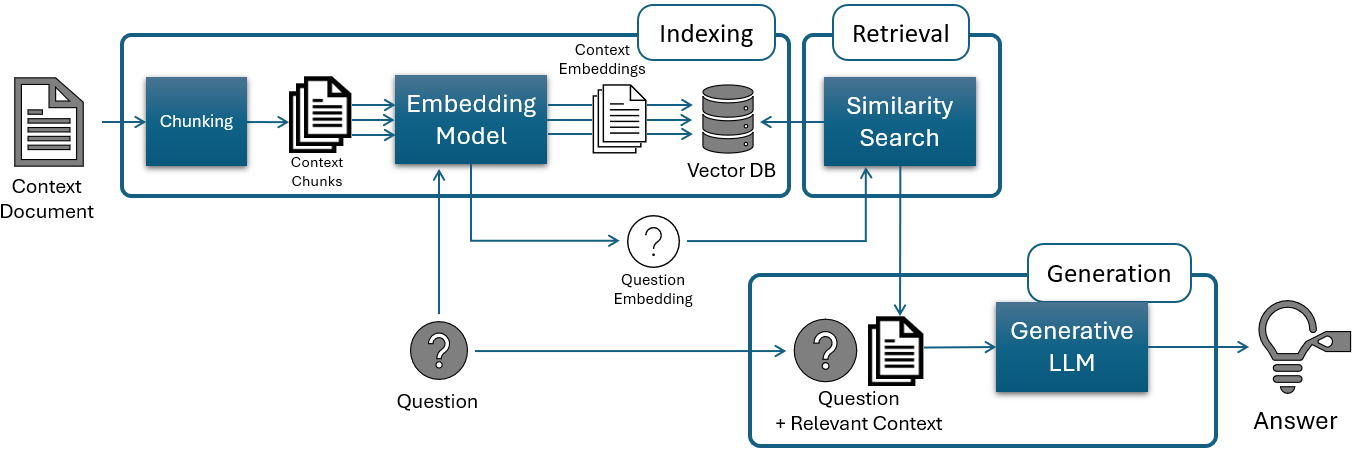
A performance evaluation of vector and graph-based retrieval-augmented generation (RAG) systems reveals that a hybrid approach generally outperforms standalone methods for scientific literature chatbots.
Despite the increasing volume of scientific literature, efficient knowledge synthesis remains a significant challenge. This is addressed in ‘Enhancing Scientific Literature Chatbots with Retrieval-Augmented Generation: A Performance Evaluation of Vector and Graph-Based Systems’, which investigates the use of retrieval-augmented generation (RAG) to improve chatbot performance. Our comparative analysis of vector- and graph-based RAG systems, alongside a hybrid approach, demonstrates that combining these methods generally yields superior retrieval accuracy and response relevance for scientific queries. Will these advancements pave the way for more accessible and reliable evidence-based decision-making in research and beyond?
The Illusion of Understanding: LLMs and the Pursuit of True Knowledge
While Large Language Models demonstrate a remarkable capacity for generating human-quality text, their proficiency often masks underlying limitations in factual recall and logical inference. These models operate by identifying statistical patterns within vast datasets, enabling fluent composition but not necessarily genuine understanding. Consequently, LLMs can produce convincingly written outputs that contain inaccuracies, contradictions, or lack substantive reasoning-a phenomenon often referred to as ‘hallucination’. The models may confidently assert information not present in their training data or fail to connect concepts requiring deeper cognitive processing, highlighting a crucial distinction between linguistic competence and true knowledge integration. This inherent weakness poses a significant challenge to deploying LLMs in applications demanding reliability and trustworthiness, particularly those involving critical decision-making or expert-level analysis.
Conventional approaches to equipping large language models with external knowledge frequently stumble, resulting in outputs that, while grammatically correct, are factually inconsistent or entirely fabricated – a phenomenon often termed “hallucination.” These methods, such as simple information retrieval followed by text concatenation, struggle to discern the reliability of sources or to synthesize information in a coherent and logically sound manner. The models often treat all retrieved data as equally valid, leading to the propagation of errors and a lack of nuanced understanding. Consequently, reliance on these techniques yields outputs that, despite appearing convincing, can be demonstrably unreliable, hindering the deployment of these systems in applications demanding accuracy and trustworthiness.
The development of truly trustworthy artificial intelligence hinges on effective knowledge grounding – the ability of a system to consistently anchor its responses and actions in verified, external information. Without this crucial link to reliable sources, even the most sophisticated large language models are prone to generating plausible but inaccurate statements, often termed ‘hallucinations’. This grounding isn’t simply about accessing data; it requires a nuanced understanding of information provenance, the ability to discern credible sources from unreliable ones, and a mechanism for seamlessly integrating this external knowledge into the reasoning process. Consequently, advancements in knowledge grounding are not merely incremental improvements, but foundational steps toward building AI systems capable of tackling complex tasks with demonstrable reliability and fostering genuine user trust.
Retrieval-Augmented Generation: Bridging the Knowledge Gap
Retrieval-Augmented Generation (RAG) addresses limitations of Large Language Models (LLMs) by supplementing their inherent knowledge with information retrieved from external sources. LLMs, while powerful, are constrained by the data they were trained on and may lack up-to-date or specialized information. RAG systems mitigate this by first retrieving relevant documents from a knowledge base – such as a database, file system, or the internet – based on a user’s query. These retrieved documents are then incorporated into the prompt provided to the LLM, effectively augmenting its knowledge and enabling it to generate more informed and contextually accurate responses. This approach allows LLMs to access and utilize information beyond their original training data, improving their performance on tasks requiring specific or current knowledge.
Vector-Based Retrieval-Augmented Generation (RAG) systems utilize vector embeddings to facilitate semantic search within large document collections, such as PubMed. This process involves converting text documents into numerical vectors – high-dimensional representations capturing the semantic meaning of the text. A query is similarly transformed into a vector, and the system identifies relevant documents by calculating the similarity between the query vector and the document vectors, typically using cosine similarity. Documents with the highest similarity scores are then retrieved, enabling the LLM to access and incorporate relevant external knowledge during generation, improving the accuracy and contextuality of its responses.
The OpenAI Embedding Model utilizes a deep neural network to convert text strings into dense vector representations, typically with a dimensionality of 1536. These vectors capture the semantic meaning of the input text, allowing for the quantification of textual similarity. The model processes text by tokenizing it and then mapping each token to a corresponding vector in the embedding space. Similarity between texts is then determined by calculating the cosine similarity between their respective embedding vectors; higher cosine similarity scores indicate greater semantic relatedness. This vector-based approach facilitates efficient retrieval of relevant documents from a large corpus because similarity searches can be performed using optimized vector databases and algorithms, bypassing the need for keyword matching or complex string comparisons.
Graph-Based RAG: Structuring Knowledge for Deeper Insight
Graph-Based Retrieval Augmented Generation (RAG) employs Property Graphs – a database technology featuring nodes representing entities and relationships represented as edges – to structure knowledge for retrieval. Unlike traditional document-based approaches, this method explicitly defines connections between concepts, allowing the system to understand context beyond keyword matching. Nodes in a Property Graph store data as key-value pairs, facilitating complex queries and the storage of rich metadata associated with each entity. The relationships, or edges, are also typed, defining the nature of the connection between nodes – for example, “authored,” “located_in,” or “is_a.” This structured representation enables more precise and nuanced knowledge retrieval compared to methods reliant on embedding similarity alone.
Traditional vector-based Retrieval-Augmented Generation (RAG) systems represent knowledge as isolated embeddings, potentially losing nuanced relationships between concepts. Graph-based RAG, conversely, explicitly models knowledge as a network of entities and relationships – a Property Graph. This networked structure allows the system to capture semantic connections, such as hierarchical relationships (e.g., ‘is a type of’), causal links, or associations based on shared properties. Consequently, queries can traverse these relationships to retrieve information based not only on keyword similarity but also on the meaning of the connections between entities, yielding more relevant and contextually accurate results compared to approaches solely reliant on vector similarity.
Neo4j is a graph database management system specifically designed for storing and querying Property Graphs. It utilizes a schema-less approach, allowing for flexible data modeling and easy adaptation to evolving knowledge domains. Data is stored as nodes, relationships, and properties, facilitating complex relationship traversals that are computationally expensive in relational databases. Neo4j employs Cypher, a declarative graph query language, optimized for pattern matching and graph algorithms. This enables efficient reasoning and retrieval of interconnected information, going beyond simple keyword searches to uncover nuanced relationships between entities. The system’s scalability and ACID compliance ensure data integrity and reliable performance, even with large and complex knowledge graphs.
Synergistic Knowledge: The Power of Hybrid RAG
Hybrid Retrieval Augmented Generation (RAG) combines the capabilities of both vector-based and graph-based information retrieval techniques. Vector-based retrieval excels at semantic similarity searches, identifying documents conceptually related to a query, while graph-based retrieval focuses on relationships and connections between entities within the knowledge source. By integrating these approaches, Hybrid RAG aims to capitalize on the strengths of each; vector search efficiently narrows the document pool, and graph traversal refines results by prioritizing contextually relevant information based on established relationships. This integration allows the system to consider both the meaning of the query and the structural connections within the data, ultimately improving the quality and accuracy of generated responses.
Combining vector-based and graph-based retrieval methods in a Hybrid RAG system demonstrably enhances both the relevance and accuracy of information delivered to the user. Evaluation metrics indicate a mean cosine similarity of 0.687 and a faithfulness score of 0.845, representing improvements over individual Vector RAG (0.670, 0.841) and Graph RAG (0.654, 0.785) implementations. This suggests that leveraging the strengths of both approaches-vector search for semantic similarity and graph traversal for relational context-results in more pertinent and factually consistent responses, thereby increasing the overall quality of the generated output.
Evaluations of chatbot responses demonstrate that Hybrid Retrieval-Augmented Generation (RAG) achieves a mean cosine similarity of 0.687, indicating a higher degree of relevance between the retrieved context and the query, and a faithfulness score of 0.845, reflecting the accuracy of the generated response based on the source material. These metrics represent a performance improvement when compared to Vector RAG, which achieved a cosine similarity of 0.670 and a faithfulness of 0.841, and Graph RAG, which yielded a cosine similarity of 0.654 and a faithfulness of 0.785. These results suggest that the integration of vector and graph-based retrieval methods yields more relevant and accurate responses than either method used independently.
Toward Robust Intelligence: Scaling and Refining Knowledge-Augmented Generation
The capacity to rigorously test and refine Retrieval-Augmented Generation (RAG) systems hinges on the availability of diverse and challenging datasets. GPT-4o-mini offers a novel solution by functioning as a synthetic data engine, capable of generating varied question-answer pairs tailored to specific knowledge domains. This automated dataset creation bypasses the limitations of relying solely on manually curated resources, which can be both time-consuming and prone to bias. By systematically altering the complexity of questions, the scope of required knowledge, and the presence of potentially misleading information, researchers can effectively probe the boundaries of Hybrid RAG systems. This allows for targeted optimization, identifying specific weaknesses and ultimately leading to more robust and reliable knowledge-augmented generation capabilities – crucial for applications demanding accuracy and trustworthiness.
Evaluations utilizing synthetically generated test sets demonstrate the robust performance of Hybrid Retrieval-Augmented Generation (RAG) systems. Specifically, when tasked with answering questions based on information from a single research paper, Hybrid RAG achieves a high degree of context relevance – correctly identifying and utilizing pertinent information in 94.2% of instances – alongside a strong answer completeness rate of 92%. While performance is modestly reduced when the system must synthesize information across multiple papers, reaching 81.6% context relevance and 85% answer completeness, these results suggest that Hybrid RAG effectively bridges the gap between information retrieval and knowledge synthesis, offering a promising avenue for building more informed and accurate language models.
Continued advancements in knowledge-augmented generation necessitate exploration beyond current limitations, with future research poised to address the challenges of scale and complexity. Expanding these techniques to encompass substantially larger knowledge bases-potentially integrating entire digital libraries or specialized datasets-will demand innovations in indexing, retrieval, and knowledge fusion. Simultaneously, progressing towards more complex reasoning tasks requires moving beyond simple question answering to tackle problems involving multi-hop inference, nuanced understanding of context, and the ability to synthesize information from disparate sources. Successfully navigating these hurdles promises to unlock the full potential of hybrid retrieval-augmented generation, enabling systems capable of not only accessing information but also applying it to solve increasingly sophisticated problems and generate truly insightful outputs.
The pursuit of effective scientific literature chatbots, as detailed in this evaluation of Retrieval-Augmented Generation systems, demands a ruthless simplification of complexity. The study demonstrates how hybrid vector and graph-based approaches achieve superior performance by integrating diverse knowledge representations-a testament to elegant design. This aligns perfectly with Gauss’s observation: “If I have seen further it is by standing on the shoulders of giants.” The research effectively builds upon existing techniques, refining them into a more powerful system capable of delivering accurate and faithful responses. The authors prioritize a streamlined architecture, mirroring a commitment to clarity over unnecessary intricacy.
What Remains?
The pursuit of intelligent access to scientific literature invariably distills to a question of efficient reduction. This work demonstrates the practical, if unsurprising, benefit of combining retrieval strategies. The hybrid approach, predictably, retains more relevant information while discarding less. Yet, the gains, while measurable, suggest diminishing returns. The fundamental bottleneck is not solely retrieval, but the inherent ambiguity within scientific discourse itself. A chatbot, however sophisticated, cannot resolve contradictions in the source material; it merely reflects them.
Future iterations will undoubtedly explore more elaborate embedding models and graph structures. However, a truly significant advance requires a shift in focus. Less emphasis should be placed on finding information, and more on assessing its validity. The field needs methods to automatically detect inconsistencies, biases, and limitations within the literature. A system capable of articulating what is not known is, paradoxically, more valuable than one that regurgitates what is.
Ultimately, the ideal scientific chatbot is not an oracle, but a skeptical interlocutor. It should challenge assumptions, expose weaknesses, and force the user to confront the inherent uncertainties of knowledge. The remaining work, then, is not about building a better search engine, but about constructing a digital embodiment of scientific rigor – a machine capable of reasoned doubt.
Original article: https://arxiv.org/pdf/2602.17856.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- Clash of Clans April 2026 Gold Pass Season introduces a Archer Queen skin
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Gold Rate Forecast
2026-02-23 19:27