Author: Denis Avetisyan
Researchers are leveraging the power of large language models and real-world data to create more believable and scalable simulations of how people move and interact.
![The M2LSimu framework establishes a methodology for modeling and simulating multi-legged locomotion, enabling the analysis of dynamic stability and gait planning through the application of [latex] \mathbf{q}, \dot{\mathbf{q}}, \ddot{\mathbf{q}} [/latex] representing joint positions, velocities, and accelerations, respectively.](https://arxiv.org/html/2602.16726v1/x6.png)
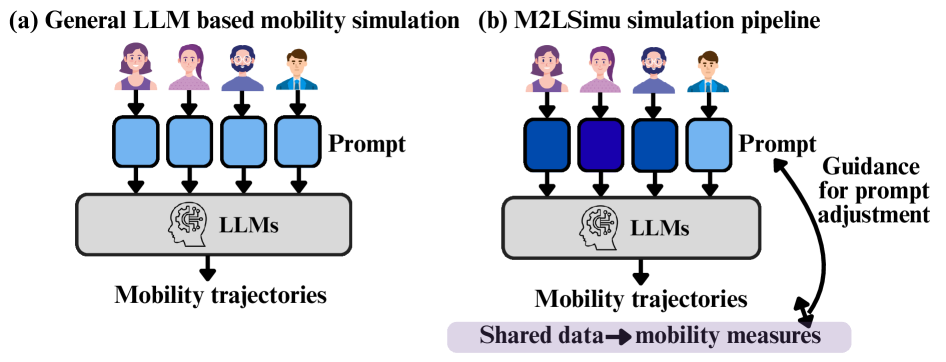
This work introduces M2LSimu, a framework that utilizes mobility measures to refine prompts and improve the fidelity of large language model-based human mobility simulations at both individual and population scales.
While large language models show promise in simulating realistic human mobility, current approaches often struggle to generate population-level behaviors that reflect real-world patterns. This paper, ‘Guiding LLM-Based Human Mobility Simulation with Mobility Measures from Shared Data’, introduces M2LSimu, a framework that leverages shared mobility data to refine prompts and coordinate individual trajectories within LLM-based simulations. By iteratively adjusting prompts guided by population-level mobility measures, M2LSimu significantly improves the realism of both individual and collective movement patterns. Could this approach unlock more accurate and scalable simulations for applications ranging from urban planning to epidemic modeling?
The Illusion of Motion: Deconstructing Realistic Human Mobility
Conventional models designed to simulate how people move often fall short of capturing the intricacies of real-world human behavior. These systems frequently rely on simplified assumptions – such as individuals consistently choosing the shortest path or adhering to rigid daily routines – which fail to account for the spontaneous detours, social interactions, and contextual factors that shape actual mobility patterns. This limitation significantly impacts the effectiveness of these models in fields like urban planning, where accurate predictions of traffic flow and resource allocation are essential, and in epidemiology, where understanding population movement is critical for controlling disease outbreaks. Consequently, insights derived from such simulations may be unreliable, leading to suboptimal strategies and potentially flawed conclusions about human activity and its impact on various systems.
The creation of synthetic mobility data – artificially generated records of how people move – is increasingly vital for simulating real-world scenarios, yet current techniques face significant hurdles. Achieving high fidelity – accurately mirroring the complexities of human travel patterns – often demands immense computational resources, rendering large-scale simulations impractical. Conversely, computationally efficient methods frequently sacrifice crucial details, resulting in unrealistic data that compromises the validity of subsequent analyses. Compounding these challenges is the imperative of preserving individual privacy; traditional data generation approaches can inadvertently leak sensitive location information, necessitating complex anonymization procedures that further impact data utility and introduce potential biases. Consequently, researchers are actively seeking innovative solutions that can strike a delicate balance between realism, efficiency, and the robust protection of personal data.
Researchers are increasingly turning to Large Language Models (LLMs) as a promising avenue for generating realistic human mobility data, driven by the critical need for both scalability and privacy preservation. Traditional methods often struggle to simulate the intricate patterns of daily life at a population level without revealing sensitive individual information. LLMs, however, offer a unique capacity to learn and reproduce complex behaviors from anonymized datasets, generating synthetic mobility traces that statistically resemble real-world movement while mitigating privacy risks. This approach allows for the creation of large-scale, detailed simulations useful for applications like urban planning, disease modeling, and transportation optimization – all without directly exposing personal data. The inherent ability of LLMs to generalize from patterns, rather than memorize specific trajectories, provides a powerful mechanism for balancing data fidelity with robust privacy guarantees, potentially revolutionizing how human movement is studied and predicted.
Leveraging LLMs: A Data-Driven Approach to Mobility Simulation
LLM-based mobility simulation utilizes large language models, specifically transformer architectures, to generate synthetic trajectories representing the movement of entities. This approach departs from traditional physics-based or rule-based simulation methods by leveraging the LLM’s capacity to learn and reproduce patterns from observed mobility data. The LLM is trained on datasets of real-world trajectories, enabling it to predict plausible future movements given an initial state or context. By framing trajectory generation as a sequence prediction task, this method offers a data-driven alternative for creating realistic and varied mobility scenarios, particularly useful in applications like autonomous vehicle development and urban planning where extensive simulation data is required.
Initial prompting of Large Language Models (LLMs) for mobility simulation typically yields trajectories that lack statistical fidelity to real-world movement data. LLMs, while capable of generating sequences, require specific guidance to accurately represent characteristics such as speed distributions, heading changes, and inter-agent spacing. Without prompt adjustment, generated trajectories often exhibit unrealistic behaviors – for example, excessively uniform speeds, abrupt turns, or collisions – due to the LLM’s inherent lack of domain-specific knowledge regarding traffic flow or pedestrian dynamics. Consequently, careful refinement of prompts with parameters reflecting realistic mobility patterns is crucial for producing synthetic data suitable for validation of autonomous systems or transportation planning.
Prompt adjustment is crucial for generating statistically valid mobility patterns with Large Language Models (LLMs) because initial, unrefined prompts often result in trajectories that deviate from observed real-world data. This adjustment involves iteratively refining the input prompts with specific parameters and constraints related to speed, acceleration, turning radii, and route preferences. By incorporating these parameters, the LLM’s output distribution can be steered to more closely match empirical distributions of mobility behavior. Techniques include providing examples of realistic trajectories within the prompt, utilizing negative prompting to discourage unrealistic behaviors, and employing reinforcement learning to optimize prompts based on statistical validation metrics against ground truth datasets. The efficacy of prompt adjustment is typically measured by comparing statistical properties of the generated trajectories – such as average speed, distance traveled, and turning angle distributions – to those observed in real-world mobility data.
M2LSimu: Automating Prompt Optimization with Markov Decision Processes
M2LSimu leverages the principles of Markov Decision Processes (MDPs) to automate the optimization of prompts used in Large Language Model (LLM)-driven mobility simulations. In this framework, prompt adjustments are treated as discrete actions within a defined state space representing the current prompt configuration. The LLM’s response to a given prompt, evaluated through quantitative mobility measures, constitutes the reward signal. This allows M2LSimu to iteratively refine prompts, learning a policy that maximizes simulation realism. By formally defining the prompt optimization process as an MDP, M2LSimu enables systematic exploration of the prompt space and the identification of prompts that elicit more accurate and representative mobility patterns from the LLM.
Prompt refinement within M2LSimu operates through iterative adjustments guided by quantitative feedback from Mobility Measures. These measures – Radius of Gyration, Travel Distance, and Visitation Frequency – provide data on the simulated population’s movement patterns. Radius of Gyration quantifies the spatial dispersion of individuals, Travel Distance represents the total distance moved by the population, and Visitation Frequency indicates how often locations are visited. The system analyzes these metrics after each simulation run and modifies the prompt to encourage behaviors that improve alignment with desired mobility characteristics, effectively creating a closed-loop optimization process.
M2LSimu demonstrably enhances the fidelity of human mobility simulations generated by Large Language Models. Evaluation across multiple metrics – including Radius of Gyration, Travel Distance, and Visitation Frequency – reveals performance improvements ranging from 11.29% to 64.08% compared to the strongest baseline models. This optimization is achieved through the implementation of Monte Carlo Tree Search (MCTS), an algorithm used to efficiently explore the prompt space and identify adjustments that maximize simulation realism. MCTS enables a targeted refinement of prompts, focusing computational resources on the most promising areas for improvement and accelerating the convergence towards more accurate mobility patterns.
The Essence of Movement: Capturing Statistical Realism and Protecting Privacy
M2LSimu fundamentally prioritizes the preservation of realistic human movement through its innovative use of Statistical Shared Data and Coarse-Grained Data. Rather than attempting to replicate the intricacies of individual paths, the simulation focuses on capturing the aggregate statistical properties that govern mobility patterns. This approach is rooted in the understanding that many aspects of human movement adhere to specific Scaling Laws – predictable relationships between variables across different scales. By ensuring these laws are accurately represented in the generated data, M2LSimu achieves a high degree of realism, even with simplified individual behaviors. The simulation effectively distills complex movement into essential statistical characteristics, allowing it to generate plausible and representative datasets that accurately reflect real-world distributions and avoid the computational cost – and privacy risks – associated with modeling every nuance of individual trajectories.
M2LSimu distinguishes itself through a focus on macroscopic patterns of movement, deliberately shifting away from the reconstruction of individual paths. This strategy allows the simulation to capture the essential characteristics of human mobility – how people generally explore space – rather than being constrained by the specifics of any single person’s journey. Consequently, generated datasets exhibit a stronger correspondence to real-world observations, particularly in key metrics like the Exploration Exponent α. This exponent, which quantifies the rate at which an individual explores new areas, is a fundamental property of movement, and M2LSimu’s ability to accurately reproduce its distribution confirms the simulation’s capacity to generate statistically realistic and representative human mobility data.
M2LSimu’s design deliberately sidesteps the reconstruction of individual movement patterns, offering a significant advantage in terms of data privacy. By concentrating on statistically shared, coarse-grained data – aggregate trends in mobility rather than precise trajectories – the system avoids the need to model, store, or represent the behavior of specific individuals. This approach not only minimizes the risk of re-identification but also enhances the robustness of the generated data; the focus on collective behaviors ensures the simulation reflects broad population-level dynamics while inherently safeguarding personal movement histories. Consequently, M2LSimu provides a pathway to create realistic mobility data without compromising the privacy of those it represents, offering a responsible solution for research and development in fields like urban planning and epidemiological modeling.
The pursuit of realistic simulation, as demonstrated by M2LSimu, necessitates a rigorous foundation in quantifiable metrics. This echoes Ken Thompson’s sentiment: “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” The framework’s reliance on mobility measures-objective, reproducible data-directly addresses the challenge of verifying simulation fidelity. Without such deterministic benchmarks, assessing the validity of LLM-generated trajectories, and thus population-level behavior, becomes an exercise in subjective approximation rather than provable correctness. The focus on quantifiable results is not merely about achieving functional simulations, but about establishing a foundation of reliability and reproducibility.
What’s Next?
The present work, while demonstrating a path toward LLM-guided mobility simulation, merely scratches the surface of a fundamental dissonance. The framework’s reliance on ‘mobility measures’ as corrective signals implies an external validation – a ‘ground truth’ – that is itself a statistical construct. To what extent does forcing LLM output to conform to observed patterns truly model behavior, versus simply recreating it? The pursuit of realism, without a rigorous mathematical underpinning for what constitutes ‘realistic’ mobility, risks a sophisticated form of curve fitting.
Future investigation must address the limitations of prompt engineering as a control mechanism. The current approach, akin to adjusting knobs on a complex system without understanding the underlying equations, is inherently brittle. A more robust solution demands the formalization of mobility patterns within a predictive framework – perhaps leveraging Markov Decision Processes not as a descriptive tool, but as a constraint on the LLM’s generative process. Scaling laws, observed empirically, require a corresponding theoretical justification.
Ultimately, the true challenge lies not in generating plausible trajectories, but in constructing a provably correct model of human movement. Optimization without analysis is self-deception, and a simulation that appears realistic, without being grounded in mathematical principles, is little more than an elaborate illusion. The field must strive for elegance – for a solution that is not merely effective, but demonstrably true.
Original article: https://arxiv.org/pdf/2602.16726.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Limbus Company 2026 Roadmap Revealed
- Clash of Clans April 2026 Gold Pass Season introduces a Archer Queen skin
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Total Football free codes and how to redeem them (March 2026)
- Gold Rate Forecast
2026-02-23 00:50