Author: Denis Avetisyan
A new system leverages vision, tactile feedback, and inertial measurements to accurately interpret human actions in real-time, enabling safer and more effective human-robot interaction.

This review details a distributed multimodal sensing architecture for human activity recognition, combining tactile sensing, IMUs, and vision-based data with deep learning techniques for robust performance in collaborative robotics scenarios.
Effective human-robot collaboration requires nuanced understanding of human intent, a challenge given the complexity and variability of human actions. This is addressed in ‘A Distributed Multi-Modal Sensing Approach for Human Activity Recognition in Real-Time Human-Robot Collaboration’, which introduces a system integrating vision-based tactile sensing and inertial measurement units to robustly classify hand activities during robotic interaction. Experimental results demonstrate high accuracy in both offline analysis and dynamic, real-time scenarios, suggesting a pathway toward more adaptive and intuitive collaborative robots. Could this multimodal approach unlock even greater levels of dexterity and safety in future human-robot teams?
Decoding Intent: The Foundation of True Collaboration
Truly effective human-robot collaboration hinges on a robot’s ability to decipher not just what a human is doing, but why. Current robotic systems, however, often falter when tasked with recognizing the subtle nuances of human activity, relying on pre-programmed responses to limited actions. This limitation stems from the inherent complexity of human movement, which is rarely precise or predictable; gestures, body language, and even slight variations in force application all contribute to conveying intent. Without a robust understanding of these cues, robots struggle to anticipate human needs, leading to awkward interactions, potential safety hazards, and a diminished sense of partnership. Advancements in nuanced activity recognition, therefore, represent a critical step towards creating robotic collaborators that are not merely tools, but genuine teammates capable of seamlessly integrating into human workflows.
The ability of a robotic system to discern fundamental human actions – such as pinching, pulling, pushing, or rubbing – is paramount to fostering safe and intuitive human-robot collaboration. These seemingly simple gestures often precede more complex tasks, and a robot’s accurate interpretation allows it to anticipate human needs and react accordingly. Misinterpreting a push as a pull, for instance, could lead to collisions or unintended consequences, hindering effective teamwork. Consequently, robust recognition of these basic interactions isn’t merely about identifying what a person is doing, but understanding why, enabling the robot to provide timely assistance, avoid interference, and ultimately, build trust through predictable and helpful behavior.
The development of genuinely collaborative robotic systems hinges on a robot’s ability to accurately perceive and interpret human actions. This isn’t simply about identifying what a person is doing, but understanding the intent behind the movement, even with subtle gestures. Robust human activity recognition moves beyond basic object manipulation to deciphering complex sequences-a pinch followed by a pull, for example-allowing the robot to anticipate needs and respond appropriately. Without this foundational capability, robots remain limited to pre-programmed tasks or require constant, explicit direction, hindering true partnership and safe interaction in dynamic environments. A reliable system, capable of filtering noise and adapting to individual human styles, is therefore paramount to unlock the full potential of human-robot collaboration.

Sensing Beyond Sight: The Fusion of Modalities
The system architecture utilizes a sensor fusion approach, combining data streams from both wearable and optical sensors. Inertial Measurement Units (IMUs) provide data regarding acceleration and angular velocity, tracking movement and orientation. Flex sensors measure deformation, indicating bending or strain in articulated joints. These are integrated with data from RGB cameras, which provide visual information about the environment and the user’s actions. This multimodal input allows for a more comprehensive understanding of human behavior than could be achieved with any single sensor modality, enabling robust tracking and interaction capabilities.
Multimodal perception, in this context, combines data streams from multiple sensor types – such as wearable IMUs, flex sensors, and RGB cameras – to improve the detection and interpretation of nuanced human behavioral cues. By integrating these diverse data sources, the system moves beyond the limitations of any single modality; for example, visual observation of a hand gesture can be corroborated and refined by simultaneous measurement of joint flexion via flex sensors and inertial data indicating movement intention. This data fusion allows for a more robust and accurate assessment of subtle changes in behavior, including variations in force, gesture, and overall interaction dynamics, ultimately increasing the system’s sensitivity to a wider range of human actions and intentions.
Vision-based tactile sensors, such as the TacLINK system, utilize optical data to estimate contact forces and deformations, offering complementary information to traditional tactile sensors that rely on physical pressure or strain measurements. TacLINK employs a high-resolution camera and marker-based tracking to monitor the deformation of a soft, tactile surface when in contact with an object. Analysis of these deformations allows for the calculation of contact forces and the identification of contact locations with a precision that enhances the overall sensitivity and robustness of robotic manipulation and perception systems. This approach is particularly effective in scenarios where traditional tactile sensors may be limited by their spatial resolution or susceptibility to noise.
Robotic skin, comprised of integrated sensor arrays including Inertial Measurement Units (IMUs), flex sensors, and optical sensors like RGB cameras, enables robots to perceive physical contact and respond to external forces. This functionality extends beyond simple contact detection to include measurement of force magnitude, contact location, and surface deformation. The data acquired through these sensors facilitates a range of robotic capabilities, including improved manipulation of objects, adaptive grasping, and safe human-robot interaction. By providing a sense of ‘touch’, robotic skin allows robots to navigate and interact with their environment in a more nuanced and reliable manner than systems relying solely on visual or proximity data.
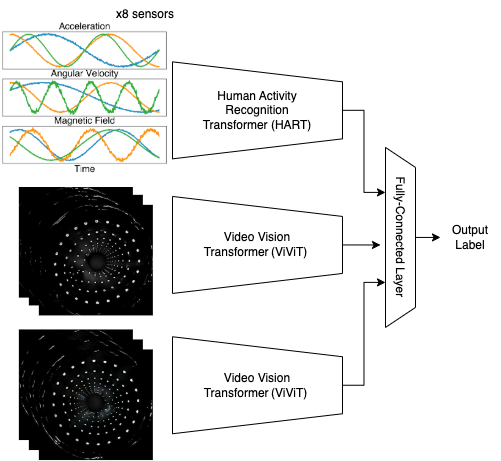
Inferring Purpose: Deep Learning for Action Understanding
The system utilizes deep learning architectures – specifically the Video Vision Transformer and the Human Activity Recognition Transformer – to process multimodal data streams consisting of visual and tactile information. The Video Vision Transformer is employed for analyzing the visual component of the action, leveraging its capabilities in processing sequential video frames. Simultaneously, the Human Activity Recognition Transformer focuses on the tactile data provided by the TER Glove’s inertial measurement units (IMUs). These two Transformer models operate in parallel, with their outputs combined to provide a comprehensive understanding of the performed action. This architectural choice allows for the effective fusion of heterogeneous data types, enhancing the overall accuracy and robustness of the action recognition system.
The TER Glove utilizes Inertial Measurement Units (IMUs) to capture detailed motion data critical for training deep learning models used in action recognition. These IMUs, consisting of accelerometers and gyroscopes, measure linear acceleration and angular velocity across multiple axes, providing a precise record of hand and arm movements. This data, representing the kinematic properties of the action, is then used as input for the Video Vision Transformer and Human Activity Recognition Transformer models. The high-resolution, time-series motion capture data provided by the TER Glove significantly contributes to the system’s ability to accurately classify and interpret human actions, supplementing visual information and improving overall performance.
The action recognition system utilizes Transformer networks – specifically the Video Vision Transformer and Human Activity Recognition Transformer – to process data from both visual sensors and tactile input provided by the TER Glove’s IMUs. During offline validation, this multimodal analysis achieved a 95.60% F1-score, indicating a high degree of accuracy in identifying and classifying performed actions. The F1-score represents the harmonic mean of precision and recall, providing a balanced measure of the system’s performance across both correctly identified positive cases and the avoidance of false positives.
Current action recognition systems primarily categorize observed movements; this system is engineered to progress beyond action identification toward action understanding by inferring the user’s intended goal. This is achieved through the fusion of visual data with tactile information from the TER Glove, allowing the model to contextualize actions and predict the underlying purpose. The ability to discern intent is crucial for applications requiring proactive assistance or nuanced interaction, enabling the system to anticipate needs and respond appropriately, rather than simply reacting to performed motions.
From Validation to Integration: The Path to Collaborative Robotics
Initial assessment of the system’s performance relied on Offline Validation, a rigorous process utilizing pre-segmented data to establish a baseline for activity recognition accuracy. This methodology allowed for controlled evaluation, isolating the system’s ability to correctly identify actions from clearly defined data segments. The resulting accuracy of 94.64% demonstrated a strong capacity for discerning intended activities under ideal conditions, providing a crucial foundation for subsequent testing in more complex, real-world scenarios. This high level of precision in the offline phase signified the system’s potential for effective operation and informed the development of strategies to address challenges inherent in continuous, dynamic environments.
Following initial offline assessments, the system’s capabilities were further tested through online validation, a process designed to evaluate performance with continuous action sequences. This phase moved beyond pre-segmented data to analyze actions as they naturally unfold, mirroring real-world human activity. The system achieved an accuracy of 83.92% in correctly identifying these continuous actions, demonstrating a substantial capacity to process and interpret dynamic movements. This result highlights the system’s ability to maintain recognition rates even when faced with the complexities of uninterrupted, flowing actions, a critical feature for responsive and reliable human-robot collaboration.
The system’s capabilities were ultimately proven through Dynamic Validation, a trial conducted within a live human-robot collaboration (HRC) environment. This real-time assessment gauged the system’s performance not on isolated actions, but within the fluid context of ongoing human activity. Results indicated a median reaction time of 3.54 seconds – the duration between an action’s initiation and the system’s successful recognition – demonstrating its ability to keep pace with human workers. This responsiveness is critical for safe and effective collaboration, suggesting the system can accurately interpret human intent and facilitate seamless interaction in practical, dynamic settings.
The demonstrated advancements in activity recognition accuracy and system responsiveness represent a crucial step towards more natural and secure human-robot collaboration. Achieving high levels of recognition, even within continuous action sequences, allows robots to anticipate human intent and react accordingly, minimizing potential errors and enhancing safety. This improved performance isn’t simply about technical metrics; it fundamentally alters the interaction dynamic, enabling robots to move beyond pre-programmed responses and engage in more fluid, intuitive exchanges with humans. Consequently, these findings suggest a future where robots can seamlessly integrate into human workspaces and homes, offering assistance and companionship without compromising safety or creating frustrating delays – a paradigm shift driven by increasingly perceptive and agile robotic systems.
![Dynamic validation shows the system consistently classifies labels within a predictable timeframe, as indicated by the median [latex] extbf{black line}[/latex] and identified outliers [latex] extbf{black circles}[/latex].](https://arxiv.org/html/2602.07024v1/images/bplot_time3.png)
The pursuit of accurate human activity recognition, as detailed in this research, mirrors a fundamental principle of systems understanding: to truly grasp a mechanism, one must push its boundaries. This paper doesn’t merely observe human-robot interaction; it actively tests the limits of multimodal sensing – vision, tactile feedback, and IMUs – to achieve reliable classification. Tim Berners-Lee aptly stated, “The Web is more a social creation than a technical one.” Similarly, effective human-robot collaboration isn’t solely about technical prowess, but about accurately interpreting the nuanced ‘social’ signals of human action-a challenge this research directly addresses through robust sensor fusion and deep learning methodologies. The system’s ability to function in dynamic, real-time scenarios underscores the power of iterative refinement and the courage to challenge established paradigms.
What’s Next?
The demonstrated fusion of visual, tactile, and inertial data represents a functional, if predictably iterative, step toward more robust human-robot interaction. However, the system’s reliance on pre-defined activity classes exposes a fundamental constraint: real-world action is rarely so neatly categorized. The true challenge lies not in recognizing known activities, but in anticipating and interpreting the novel, the ambiguous, the frankly messy execution of intent. The current paradigm excels at labeling what was done; a truly intelligent system must infer what is about to be done, and why.
Further refinement will undoubtedly focus on minimizing latency and maximizing sensor robustness, but these are merely engineering challenges. The deeper question concerns generalization. How does one move beyond training on a limited set of demonstrations to accommodate the infinite variability of human behavior? The answer likely resides in moving away from classification altogether, towards systems capable of learning affordances – the possibilities for action inherent in an environment – rather than discrete activity labels.
Ultimately, the best hack is understanding why it worked, and every patch is a philosophical confession of imperfection. This work, while successful within its defined scope, implicitly acknowledges the limitations of imposing structure on a fundamentally unstructured world. The next iteration should embrace that chaos, not attempt to tame it.
Original article: https://arxiv.org/pdf/2602.07024.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Gold Rate Forecast
- Magicmon: World redeem codes and how to use them (March 2026)
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Total Football free codes and how to redeem them (March 2026)
- Seeing in the Dark: Event Cameras Guide Robots Through Low-Light Spaces
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Simulating Humans to Build Better Robots
2026-02-10 10:00