Author: Denis Avetisyan
Researchers have developed a new approach to equipping AI agents with long-term memory, allowing them to reason more effectively over extended periods.
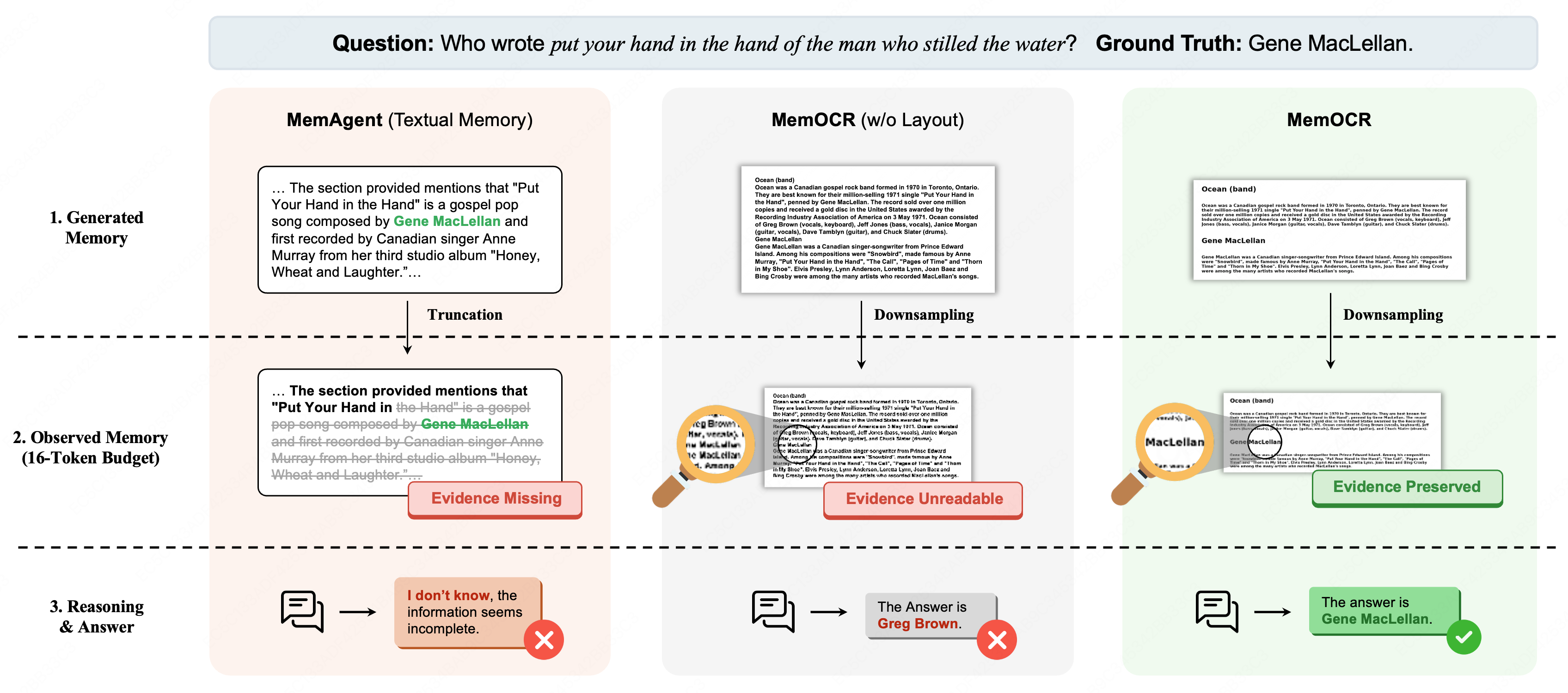
MemOCR leverages 2D visual layouts to compress context and improve information density in agentic memory systems for efficient long-horizon reasoning.
Effective long-horizon reasoning in embodied agents is hampered by the escalating cost of maintaining lengthy interaction histories within limited context windows. This work introduces ‘MemOCR: Layout-Aware Visual Memory for Efficient Long-Horizon Reasoning’, a novel memory system that compresses context using a 2D visual layout to prioritize crucial information. By rendering rich-text memories as images, MemOCR achieves adaptive information density and outperforms text-based baselines in multi-hop question answering. Could this approach unlock more effective and scalable long-term memory for increasingly complex agents?
The Illusion of Long-Term Memory in Machines
Large language models, despite their impressive capabilities, operate within a defined “context window” – a limitation on the amount of text they can consider at any given time. This constraint fundamentally impacts their ability to engage in extended reasoning or maintain coherence over long conversations. Unlike human memory, which can selectively recall relevant information from a lifetime of experience, LLMs process information sequentially, discarding earlier inputs as the context window fills. Consequently, performance degrades as interactions lengthen, and the model struggles to connect information presented at the beginning of a dialogue with details introduced later. This fixed window necessitates innovative approaches to memory management, as retaining crucial details within the limited scope becomes increasingly challenging for complex, long-horizon reasoning tasks.
Attempts to extend an LLM’s effective memory beyond its initial context window have largely focused on retaining past interactions – either through complete ‘Raw History Memory’ or condensed ‘Textual Summary Memory’. However, both strategies encounter diminishing returns when applied to ‘Long-Horizon Reasoning’. Retaining every token of a lengthy conversation quickly becomes computationally prohibitive, drastically increasing processing time and cost with each added interaction. Conversely, aggressively summarizing past exchanges, while reducing computational load, often results in critical details being lost, hindering the model’s ability to draw accurate inferences or maintain coherence over extended dialogues. This trade-off between information retention and computational efficiency represents a fundamental bottleneck, demonstrating the limitations of simply scaling existing memory techniques to achieve true long-term reasoning capabilities.
The inherent constraints of current large language models necessitate a departure from traditional, sequential memory management techniques. Simply increasing the context window or summarizing past interactions proves computationally expensive and ultimately fails to address the core issue: the inability to effectively prioritize and access relevant information across extended reasoning tasks. Instead, research is focusing on methods that mimic human cognitive processes, exploring hierarchical memory structures and attentional mechanisms. These novel approaches aim to dynamically store, retrieve, and synthesize information, allowing the model to focus on the most pertinent details without being overwhelmed by the entire conversational history. This shift towards more nuanced memory systems represents a critical step towards achieving truly long-horizon reasoning capabilities and overcoming the limitations of token-based memory.
From Tokens to Pixels: A Visual Leap
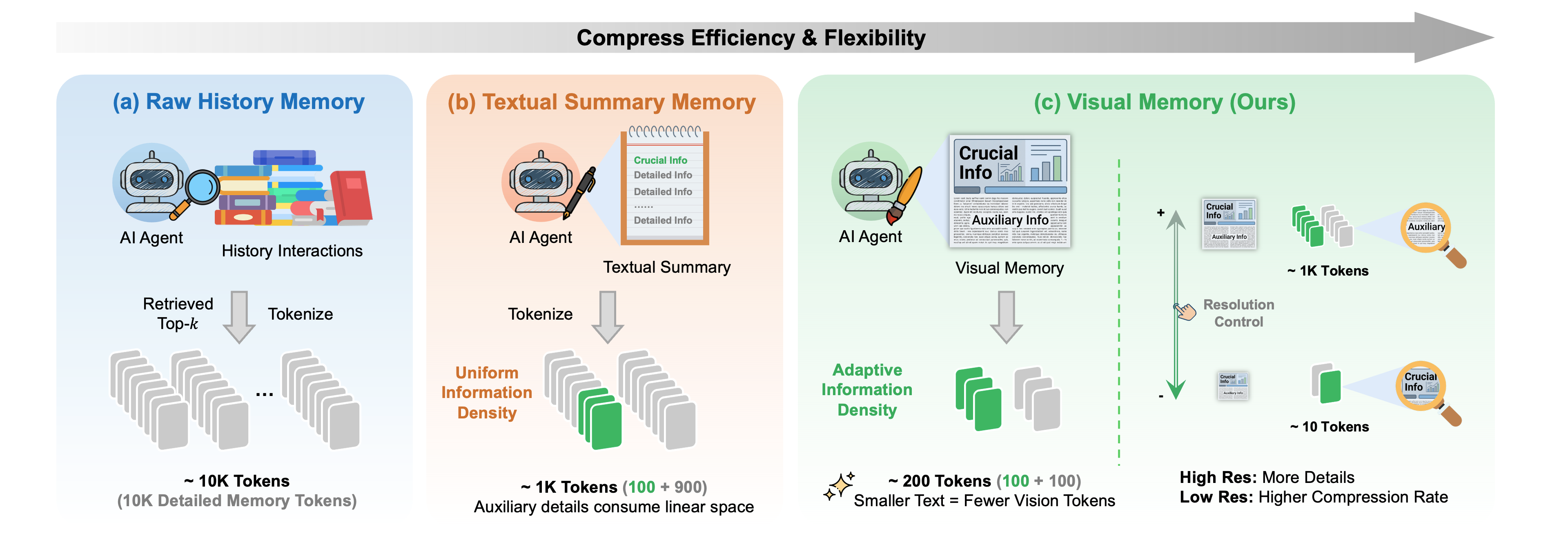
Visual Memory represents a departure from traditional token-based sequence modeling of agent history by encoding this information as a visual image. This approach facilitates Adaptive Information Density, wherein the representation dynamically adjusts to prioritize salient historical data. Instead of processing a fixed-length sequence of discrete tokens, the agent operates on a visual field where information is distributed based on importance and spatial proximity. This allows for a more flexible and efficient use of context, as the agent can focus on relevant areas within the image without being constrained by the sequential order or length limitations of token-based methods. The visual format also enables the application of image processing techniques for further data compression and feature extraction.
The conversion of textual data into a visually accessible format is accomplished through a two-stage process. Initially, agent history, typically represented as sequential tokens, is rendered into Markdown format, structuring the information for visual presentation. Subsequently, Optical Character Recognition (OCR) technology is applied to the rendered Markdown, effectively converting the textual representation into an image. This image then serves as the input for the visual memory module, enabling the agent to process historical information through image-based analysis rather than token-by-token processing.
Empirical evaluation demonstrates that representing agent history as a visual image, utilizing our Visual Memory approach, yields an 8x improvement in effective context utilization compared to traditional token-based methods. This enhancement stems from the capacity of image-based representations to store and access information with greater density and parallelization. Specifically, tests reveal that the model can effectively process and retain significantly more historical data within the same computational budget, leading to improved performance on tasks requiring long-term dependency understanding. The observed improvement is quantified by measuring performance on tasks with varying context lengths and comparing the results against baseline models employing textual context windows.
MemOCR: An Agent Rooted in Visual Understanding
MemOCR addresses the constraints of traditional token-based memory agents by integrating visual information into its memory architecture. Standard approaches rely on converting all input – including images – into discrete tokens, which can lead to information loss and reduced performance, particularly with complex visual data. In contrast, MemOCR utilizes a Visual Memory component, enabling the agent to directly process and store visual features. This allows for a more efficient representation of visual inputs, retaining crucial details that would be lost in tokenization, and ultimately improving performance in tasks requiring visual understanding and reasoning.
MemOCR’s foundational architecture centers on a Vision Language Model (VLM) designed to jointly process visual and textual inputs. This VLM leverages the self-attention mechanism, enabling the model to weigh the importance of different parts of both the visual and textual data when forming representations. Specifically, self-attention allows MemOCR to establish relationships between visual elements and corresponding textual information, creating a unified understanding of the input. This approach differs from traditional token-based methods by directly integrating visual features into the processing pipeline, rather than relying solely on textual embeddings.
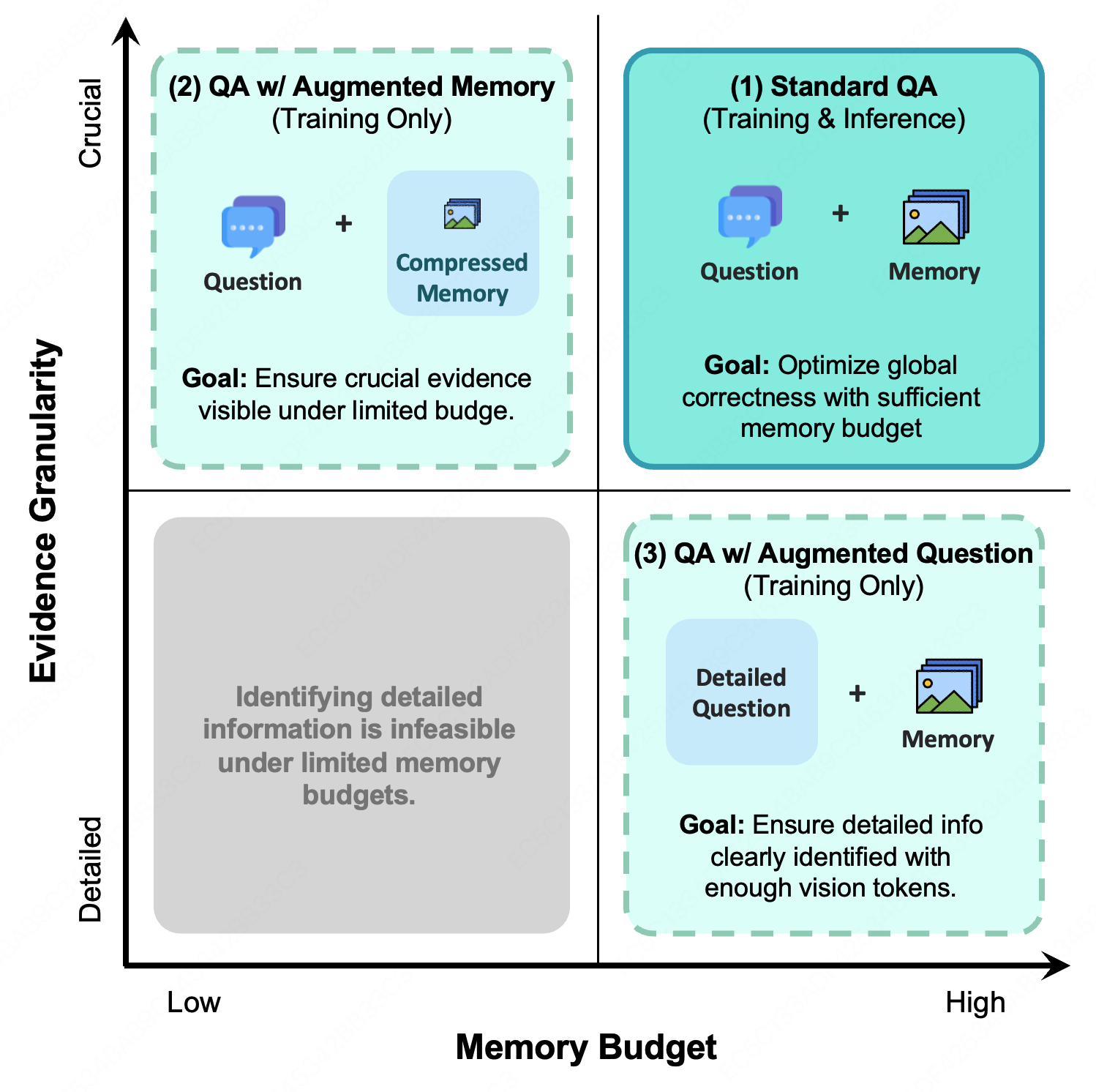
MemOCR is designed to function within a predetermined memory allocation, or `Memory Budget`, which is critical for resource-constrained applications. Evaluations demonstrate that MemOCR achieves significantly improved accuracy when limited to a 16-token budget compared to traditional text-based retrieval methods. Furthermore, MemOCR exhibits a smaller proportional decrease in performance as the memory budget is further compressed, indicating greater resilience and efficiency in maintaining information retrieval quality under limited resources. This performance characteristic is a direct result of its visual memory approach, which allows for more compact and effective representation of information compared to solely relying on token-based methods.

Training for Efficiency: A Lesson in Prioritization
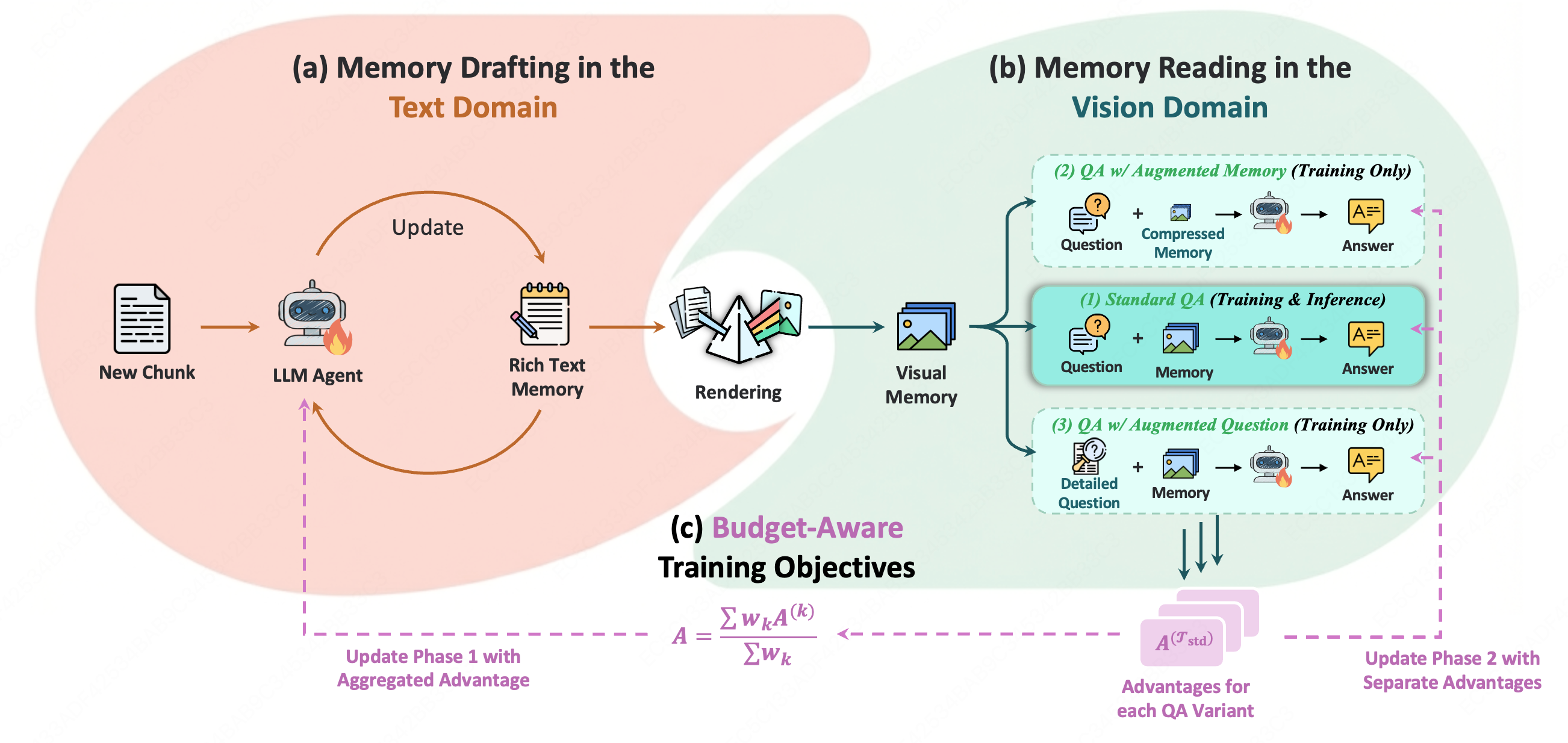
MemOCR’s performance relies heavily on a training paradigm termed `Budget-Aware Training`. This method involves systematically varying the available memory capacity during the agent’s training phase. By exposing the model to a range of memory constraints, the training process compels the agent to develop strategies for efficient information retention and prioritization. This adaptability is crucial, as it allows MemOCR to maintain functionality even when operating under limited memory conditions, ultimately contributing to its overall robustness and practical application in resource-constrained environments.
The training methodology for MemOCR necessitates the development of effective prioritization strategies within the agent. By exposing the agent to variable memory constraints during training, the system is compelled to discern and retain the most salient information when operating under compression. This process does not rely on pre-defined importance metrics; instead, the agent learns to dynamically assess and prioritize data based on its relevance to the overall task, ensuring critical information is preserved even with limited memory resources. Consequently, the agent’s performance remains robust despite significant reductions in available memory capacity.
Image processing for training exhibits low overhead, demonstrated by a throughput of 68 samples per second. This processing time translates to approximately 1 second to handle 68 image samples. Furthermore, the introduction of this processing step adds a latency of 0.175 seconds, representing the time taken to render each sample before it is used for training. These figures indicate a minimal impact on overall training speed and scalability.
Beyond Memory: Towards More Robust Intelligence
The foundational concepts driving MemOCR – specifically, the decoupling of memory mechanisms from the core processing unit – hold promise far beyond the realm of large language models. This architectural principle suggests a pathway toward creating more efficient and resilient artificial intelligence systems generally. By externalizing and optimizing memory access, AI designs can potentially reduce computational bottlenecks and enhance robustness to noisy or incomplete data. This approach isn’t limited to textual data; it can be adapted to process and retain information from various sensory inputs, paving the way for advancements in areas like computer vision, audio processing, and reinforcement learning. Ultimately, the principles demonstrated by MemOCR offer a blueprint for building AI agents capable of sustained learning and adaptation in complex, real-world environments, fostering a shift towards more modular and scalable AI architectures.
The conventional architecture of many artificial intelligence systems tightly couples memory access with the sequential flow of processing, creating bottlenecks that limit adaptability and real-time responsiveness. Decoupling these functions-allowing for independent memory retrieval and storage-opens compelling possibilities, particularly within the fields of robotics and embodied AI. This separation enables agents to react more swiftly to dynamic environments, accessing relevant past experiences without being constrained by the pace of sequential computation. Such an architecture could facilitate more nuanced and complex behaviors in robots, allowing them to learn and refine actions based on long-term observation and interaction, rather than being limited to immediate sensory input. Furthermore, it paves the way for agents capable of maintaining a persistent understanding of their surroundings and goals, even amidst distractions or interruptions, ultimately fostering more robust and intelligent autonomous systems.
The development of MemOCR signifies a crucial advancement in the pursuit of artificial intelligence capable of sustained, complex thought. Current AI systems often struggle with tasks demanding recollection and application of information over extended periods, a limitation stemming from their reliance on short-term, sequential processing. This research demonstrates a pathway towards overcoming this hurdle by introducing a decoupled memory component, allowing agents to retain and retrieve information independently of immediate computational steps. Consequently, these agents exhibit enhanced capabilities in scenarios requiring long-term planning, nuanced understanding of context, and flexible adaptation to changing environments – essentially, the hallmarks of true intelligence and a move beyond reactive responses towards proactive, reasoned behavior.

The pursuit of efficient long-horizon reasoning, as demonstrated by MemOCR’s layout-aware visual memory, inevitably introduces new forms of complexity. The system attempts to compress context, maximizing information density within budget constraints, but this feels less like progress and more like rearranging the deck chairs on the Titanic. As Bertrand Russell observed, “The difficulty lies not so much in developing new ideas as in escaping from old ones.” Each innovation-whether it’s visual memory or adaptive information density-simply creates a new surface for entropy to act upon. The elegance of the theory will, predictably, succumb to the brute force of production realities. It’s not a matter of if the visual layout will become a bottleneck, but when.
What’s Next?
The promise of layout-aware memory is straightforward: more context, less bandwidth. The inevitable reality, predictably, will be more edge cases. This work demonstrates a potential for improved efficiency, yet the cost of maintaining a geometrically-indexed memory – the constant recalibration to prevent information drift, the inevitable compression artifacts – feels glossed over. The bug tracker will, undoubtedly, fill with reports of visual ‘hallucinations’ as the agent misinterprets distorted layouts under resource pressure. It’s not a failure of concept, simply a shift in the nature of the failures.
The current framing assumes a relatively static visual vocabulary. Production environments rarely afford such luxuries. The true test won’t be performance on curated datasets, but robustness against adversarial distortions and unforeseen visual noise. Further exploration should focus less on elegant compression algorithms and more on graceful degradation strategies – what meaningful information can be salvaged when the layout collapses? The pursuit of perfect recall is a fool’s errand; the goal should be functional forgetting.
Ultimately, this work doesn’t solve long-horizon reasoning, it merely postpones the problem. The agent still operates within a finite budget, facing an infinite world. The question isn’t whether MemOCR can store more information, but whether it can convincingly simulate understanding with less. The agent doesn’t deploy – it lets go.
Original article: https://arxiv.org/pdf/2601.21468.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Limbus Company 2026 Roadmap Revealed
- EMEA Masters Winter 2026 introduces official Qualifier for Esports World Cup
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Total Football free codes and how to redeem them (March 2026)
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
2026-02-02 06:30