Author: Denis Avetisyan
A new study rigorously compares how different sensor technologies – cameras, LiDAR, and their combinations – perform in detecting people across real-world indoor and outdoor environments.
![The research visualizes common data corruptions inherent in multi-sensor perception systems, specifically demonstrating how noise affects both camera imagery and [latex] 360^\circ [/latex] LiDAR point clouds- modalities labeled as C and L respectively-as captured within the JRDB dataset.](https://arxiv.org/html/2602.05538v1/x7.png)
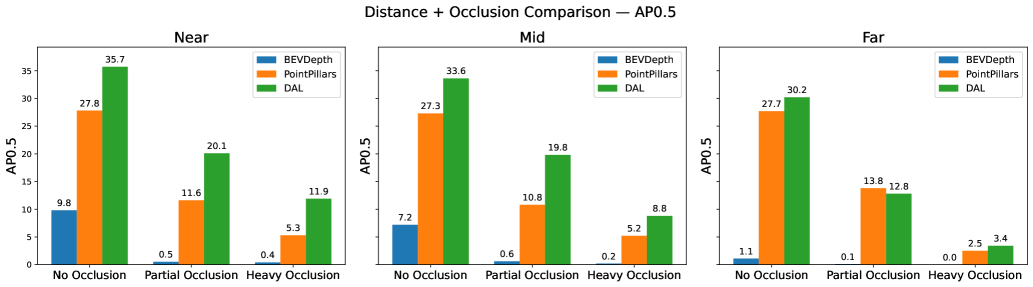
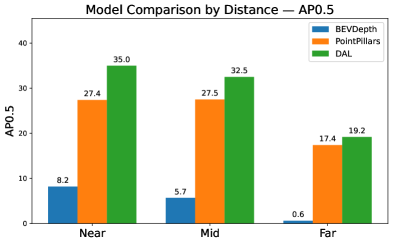
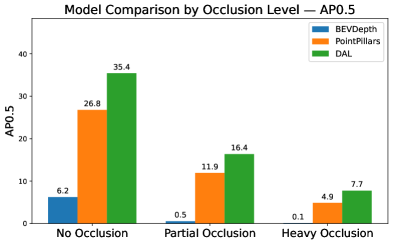
Comparative analysis of 3D person detection models utilizing camera, LiDAR, and sensor fusion on the JRDB dataset reveals the superior robustness of data association learning (DAL) techniques.
Achieving reliable 3D person detection remains a challenge, particularly in complex and variable environments. This is addressed in ‘A Comparative Study of 3D Person Detection: Sensor Modalities and Robustness in Diverse Indoor and Outdoor Environments’, which systematically evaluates the performance of camera, LiDAR, and sensor fusion approaches using the JRDB dataset. Our findings demonstrate that camera-LiDAR fusion consistently outperforms single-modality methods, offering improved robustness against occlusion, distance variations, and sensor imperfections. However, vulnerabilities to sensor misalignment and specific LiDAR corruptions persist – suggesting that further research is needed to build truly resilient 3D person detection systems for real-world applications?
The Imperative of Robust 3D Perception
The reliable identification of people in three dimensions is becoming increasingly vital for the functionality of autonomous systems and robotics, yet achieving this in unpredictable, real-world settings presents considerable obstacles. These systems, designed to navigate and interact with the physical world, depend on accurately perceiving their surroundings – and people are a core component of that environment. However, practical deployment often encounters difficulties stemming from the inherent complexity of outdoor and indoor spaces. Variable lighting conditions, cluttered backgrounds, and the dynamic nature of human movement all contribute to challenges in accurately capturing and interpreting 3D data. Consequently, advancements in 3D person detection must address these pervasive issues to unlock the full potential of robotics and autonomous technologies, ensuring safe and effective operation within complex and ever-changing environments.
The reliability of 3D person detection systems hinges on the quality of the sensor data they receive, which is frequently compromised by real-world conditions. Occlusion, where parts of a person are hidden by other objects, significantly limits the information available to the system. Simultaneously, noise – random errors in the sensor readings – can introduce false positives or obscure genuine detections. Furthermore, misalignment between different sensors, or inaccuracies in their calibration, creates distortions in the perceived 3D space, hindering the ability to accurately locate and identify individuals. These combined factors degrade performance, demanding advanced algorithms capable of filtering errors and inferring information even with incomplete or distorted data to ensure dependable operation in dynamic environments.
Current 3D person detection systems, while demonstrating success in controlled settings, frequently encounter diminished performance when deployed in realistic environments. Imperfections in sensor data – such as partial occlusions from surrounding objects, inherent sensor noise, and subtle misalignments between different data streams – introduce significant challenges. These data corruptions can lead to false positives, missed detections, and inaccurate pose estimations, critically impacting the reliability of autonomous systems that depend on precise spatial awareness. Consequently, research is increasingly focused on developing robust algorithms that can effectively mitigate the effects of these common imperfections, ensuring dependable person detection even in complex and unpredictable real-world scenarios.
Sensor Degradation and its Algorithmic Consequences
LiDAR and camera sensors are susceptible to various forms of data corruption that directly impact the reliability of perception systems. Density reduction manifests as a decrease in the number of returned points or pixels, hindering accurate object representation. Cutout effects involve the complete loss of data within specific regions of the sensor input, potentially obscuring critical features. Field-of-view loss restricts the sensor’s observable area, limiting the system’s ability to detect objects outside the reduced range. These corruptions introduce noise and uncertainty into the input data, demanding robust algorithms capable of mitigating their effects and maintaining performance even under adverse conditions.
Temporal misalignment between sensors arises from the asynchronous operation and differing acquisition rates of LiDAR and camera systems. This asynchronicity introduces uncertainty in data association, as the precise temporal correspondence between a LiDAR point and the corresponding pixels in a camera image is not guaranteed. Consequently, data fusion algorithms must account for these temporal offsets, often through interpolation or probabilistic modeling, to minimize errors in object detection and tracking. Failure to adequately address temporal misalignment can lead to inaccurate 3D reconstructions, ghost detections, and reduced overall system reliability, particularly in dynamic environments where objects are undergoing rapid motion.
Sensor corruption effects are not uniform across all operating conditions; performance degradation is markedly increased with distance and the presence of heavy occlusion. This is due to the reduced signal strength and increased noise at greater ranges, combined with the limited visibility caused by occluding objects. Consequently, detection algorithms exhibit lower precision and recall when operating in these challenging scenarios. To mitigate these effects, adaptive detection strategies are required, which dynamically adjust algorithm parameters or employ specialized processing techniques based on the observed level of corruption and the distance to the target object. These strategies may include increased noise filtering, more aggressive data interpolation, or the utilization of multi-sensor fusion techniques to compensate for data loss.
The JRDB Dataset is designed to provide a realistic evaluation environment for algorithms operating under conditions of sensor corruption and data degradation. Performance benchmarks within the dataset demonstrate significant variance between different approaches; specifically, the DAL algorithm achieves an Average Precision (AP) of 88.86% at an Intersection over Union (IoU) threshold of 0.3 in favorable conditions – defined as scenarios with no occlusion and near-range detection. This represents a substantial improvement over the performance of BEVDepth (67.76% AP at IoU 0.3) and PointPillars (75.28% AP at IoU 0.3) under the same conditions, highlighting DAL’s robustness in less challenging scenarios and serving as a baseline for evaluating performance under increasing levels of data corruption.
Mitigation Through Principled Sensor Fusion
Sensor fusion techniques, exemplified by the DAL (Depth-Aware LiDAR) method, address limitations inherent in single-sensor autonomous vehicle perception by integrating data from both LiDAR and camera systems. LiDAR provides accurate 3D depth information but can struggle with texture and object recognition in adverse conditions. Cameras offer rich textural data and semantic understanding, but are susceptible to illumination changes and lack direct depth perception. DAL and similar methods leverage the complementary strengths of these sensors; LiDAR data is used to establish precise geometric boundaries, while camera imagery provides contextual information for object classification and improves robustness in challenging environments. This combined approach reduces false positives and enhances the overall reliability of object detection and tracking systems.
PointPillars and BEVDepth represent distinct single-sensor methodologies for object detection, utilizing either LiDAR point clouds or camera imagery respectively. PointPillars converts 3D point clouds into a pseudo-image representation, enabling the application of 2D convolutional neural networks for faster processing. BEVDepth, conversely, directly estimates depth from camera images and projects the resulting data into a Bird’s Eye View (BEV) format. These approaches serve as crucial baselines for evaluating the performance gains achieved by more complex, multi-sensor fusion techniques like the DAL method, allowing for a direct comparison of detection accuracy and computational efficiency when operating with limited sensor input.
Bird’s Eye View (BEV) representation simplifies object detection by transforming 3D sensor data – typically from LiDAR and cameras – into a 2D overhead map. This projection effectively removes perspective distortions and reduces the complexity of scene understanding, as height is represented directly within the 2D plane. By operating on this simplified 2D representation, algorithms require less computational power for feature extraction and object classification, leading to improved processing efficiency and reduced latency. The BEV format also facilitates the use of 2D convolutional neural networks, which are well-established and optimized for image processing tasks, further enhancing detection speed and accuracy.
Accurate calibration is critical for multi-sensor detection systems due to inherent discrepancies between sensor data. Misalignment, encompassing both extrinsic parameters like position and orientation, and intrinsic parameters affecting individual sensor readings, introduces errors in object localization and classification. Furthermore, asynchronous data acquisition, where LiDAR and camera data are not time-synchronized, creates ghost objects or inaccuracies in motion estimation. Calibration procedures typically involve identifying transformation matrices to map data between sensor coordinate frames, and implementing time synchronization algorithms to compensate for data latency. Regular recalibration is also necessary to account for environmental factors, sensor drift, and mechanical vibrations that can alter sensor alignment over time, ensuring consistent and reliable performance of the detection system.
Toward Adaptive and Robust 3D Perception
Average Precision (AP) stands as a pivotal evaluation metric in the field of 3D person detection, particularly when assessing performance under realistic and adverse conditions. This metric quantifies the precision of detections at varying recall levels, providing a comprehensive measure of accuracy that moves beyond simple hit rates. Crucially, AP allows researchers to systematically compare different detection methods – like those utilizing sensor fusion or relying on single modalities – when faced with common environmental challenges such as occlusion, distance, or sensor corruption like Gaussian noise or LiDAR crosstalk. By consistently evaluating performance through AP across these diverse corruption scenarios, developers can pinpoint weaknesses in their algorithms and drive improvements in robustness and reliability, ultimately leading to safer and more dependable 3D perception systems.
Evaluations reveal a clear advantage for sensor fusion techniques, particularly the DAL method, when applied to 3D person detection in difficult scenarios. Comparative analysis indicates DAL consistently surpasses the performance of systems relying on a single sensor, demonstrating its resilience in challenging conditions like heavy occlusion and long detection distances. In the most demanding tests, DAL achieves an Average Precision (AP) of 29.61% at an Intersection over Union (IoU) threshold of 0.3 – a significant result given the complexity of the environment. However, performance is not immune to all forms of degradation; under conditions simulating severe LiDAR crosstalk corruption, DAL’s AP decreases to 12.80%, highlighting the continuing need for robust data processing and error mitigation strategies even within advanced multi-sensor systems.
Advancing 3D person detection in real-world scenarios necessitates a shift toward algorithms capable of intelligently responding to unpredictable sensor degradation. Current methodologies often assume static corruption models, limiting their effectiveness when faced with the dynamic and varied challenges of environments prone to occlusion, noise, or crosstalk. Future research should prioritize the development of adaptive techniques-algorithms that can actively monitor sensor data quality, identify the type and severity of corruption, and dynamically adjust processing parameters or weighting schemes accordingly. This could involve employing machine learning approaches to learn corruption patterns or utilizing Bayesian frameworks to estimate sensor reliability in real-time, ultimately allowing systems to maintain robust performance even as individual sensors fail or become compromised. Such adaptability promises to unlock the full potential of multi-sensor fusion for reliable and safe autonomous operation.
The performance of 3D person detection systems is acutely sensitive to the precision of sensor calibration and the synchronization of data streams. Studies reveal a dramatic disparity in accuracy based on these factors; for example, the DAL method achieves a strong average precision (AP) of 62.98% when no corruption is present, highlighting its potential. However, the BEVDepth approach suffers a precipitous drop to just 1.82% AP under conditions of severe Gaussian noise corruption, underscoring the critical need for improved methodologies. These results emphasize that advancements in detection algorithms alone are insufficient; robust calibration and synchronization are foundational to maximizing reliability and achieving consistently high performance in real-world applications.
The pursuit of reliable 3D person detection, as detailed in this comparative study, demands a commitment to mathematical rigor. The findings consistently highlight that sensor fusion, specifically the DAL approach, provides demonstrable robustness against real-world challenges like occlusion and sensor noise. This aligns with a core tenet of computational elegance: a system is only as strong as its weakest link, and redundancy, grounded in mathematically sound integration, mitigates vulnerability. As Fei-Fei Li once stated, “AI is not about replacing humans; it’s about empowering them.” This principle is reflected in the fusion approach, which doesn’t aim to replicate human perception, but to enhance it by combining the strengths of multiple sensor modalities, creating a more mathematically complete and reliable system. The JRDB dataset evaluation reinforces this – a robust solution isn’t merely ‘working’ on curated tests, but provably resilient in diverse and demanding environments.
Future Directions
The observed superiority of sensor fusion, specifically the DAL approach, does not, of course, represent a final solution. It merely shifts the problem. The inherent complexities of aligning and interpreting data from disparate sources introduces new potential failure modes-modes that, while different, are no less fundamental. The current reliance on empirical evaluation, even with datasets like JRDB, remains unsatisfactory. A truly elegant solution would involve a formal, mathematical characterization of robustness – a provable guarantee of performance under defined conditions of noise and occlusion, rather than simply demonstrating improved metrics on a benchmark.
Furthermore, the persistent challenge of occlusion highlights a deeper issue: the models continue to extrapolate from observed data. A more robust approach might involve a shift towards predictive modeling, where the system anticipates potential occlusions and proactively compensates, grounded in a probabilistic understanding of human movement and spatial reasoning. This, however, demands a departure from purely data-driven methods and a return to first principles of physics and geometry.
Ultimately, the field remains trapped in a cycle of incremental improvement. While larger datasets and more complex architectures may yield marginal gains, a genuine leap forward requires a re-evaluation of the underlying assumptions and a commitment to mathematical rigor. The pursuit of ‘accuracy’ is a distraction; the goal should be provable correctness, even if it means sacrificing performance on contrived benchmarks.
Original article: https://arxiv.org/pdf/2602.05538.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Gold Rate Forecast
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- ‘Project Hail Mary’s Soundtrack: Every Song & When It Plays
- Total Football free codes and how to redeem them (March 2026)
- All Mobile Games (Android and iOS) releasing in April 2026
- Top 5 Best New Mobile Games to play in April 2026
2026-02-08 22:32