Author: Denis Avetisyan
Researchers are developing new ways to combine visual and auditory information with advanced artificial intelligence, enabling robots to better understand and respond to human commands.
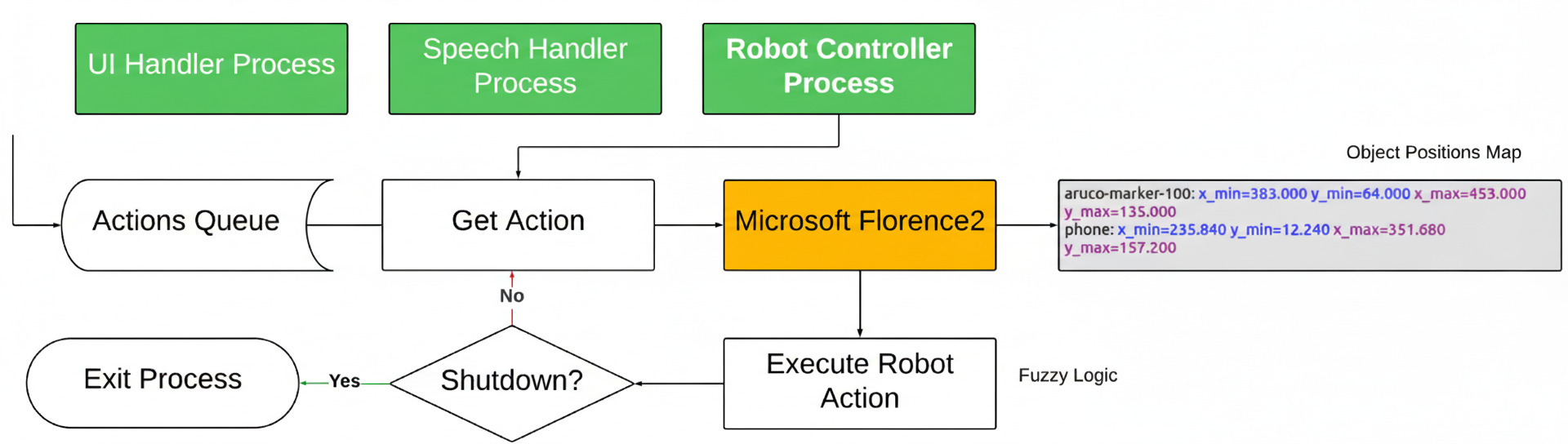
This review details a framework integrating large language models, vision-language models, and fuzzy logic control for improved human-robot interaction and object manipulation.
Achieving truly natural human-robot collaboration remains a significant challenge despite advances in artificial intelligence. This paper, ‘An Approach to Combining Video and Speech with Large Language Models in Human-Robot Interaction’, introduces a novel multimodal framework integrating vision-language models, speech recognition, and fuzzy logic to enable robots to interpret and execute natural language commands for object manipulation. Experimental results demonstrate a 75% command execution accuracy, highlighting the system’s potential for robust and adaptive control. Could this architecture pave the way for more intuitive and sophisticated human-robot partnerships through tightly coupled perception and action planning?
Beyond Scripts: The Fragility of Pre-programmed Systems
Historically, robotic systems have been largely confined by their reliance on meticulously pre-programmed sequences of actions. This approach, while effective in highly structured settings, proves brittle when confronted with the inherent unpredictability of real-world environments. A robot executing a fixed script struggles to respond to unexpected obstacles, altered conditions, or nuanced human requests, effectively halting operation or producing errors. This limitation stems from a lack of genuine understanding – the robot doesn’t ‘see’ a change and adjust, it simply attempts to follow instructions regardless of context. Consequently, advancements in robotics increasingly prioritize moving beyond these rigid frameworks, seeking systems capable of dynamic adaptation and real-time decision-making to thrive in complex, ever-changing surroundings.
Truly effective collaboration between humans and robots hinges on a system’s ability to synthesize information from multiple sources, specifically language and visual cues, to accurately discern user intent. A user might verbally request a “the blue box,” but without visual processing, the robot cannot distinguish it from other objects or even confirm its presence in the environment. This fusion of linguistic command with perceptual data enables robots to resolve ambiguities, understand context, and respond appropriately – moving beyond simple command execution towards genuine interaction. Such multi-modal understanding isn’t merely about recognizing words or objects in isolation; it’s about interpreting the relationship between them, allowing the robot to infer goals, anticipate needs, and ultimately, behave as a helpful and intuitive partner.
The future of robotics hinges on a fundamental shift toward systems possessing robust multi-modal perception and natural language understanding. Rather than relying solely on visual data or pre-programmed linguistic commands, these advanced robots integrate and interpret information from multiple sources – including images, sounds, and spoken language – to construct a comprehensive understanding of their surroundings and user intentions. This integration allows for more nuanced and flexible interactions, enabling robots to not just respond to commands, but to understand the context and infer the underlying goals. Consequently, robots can navigate dynamic environments, adapt to unforeseen circumstances, and collaborate with humans in a truly intuitive and efficient manner, moving beyond rigid automation toward genuine assistance and partnership.
Sensory Integration: Deconstructing the Environment
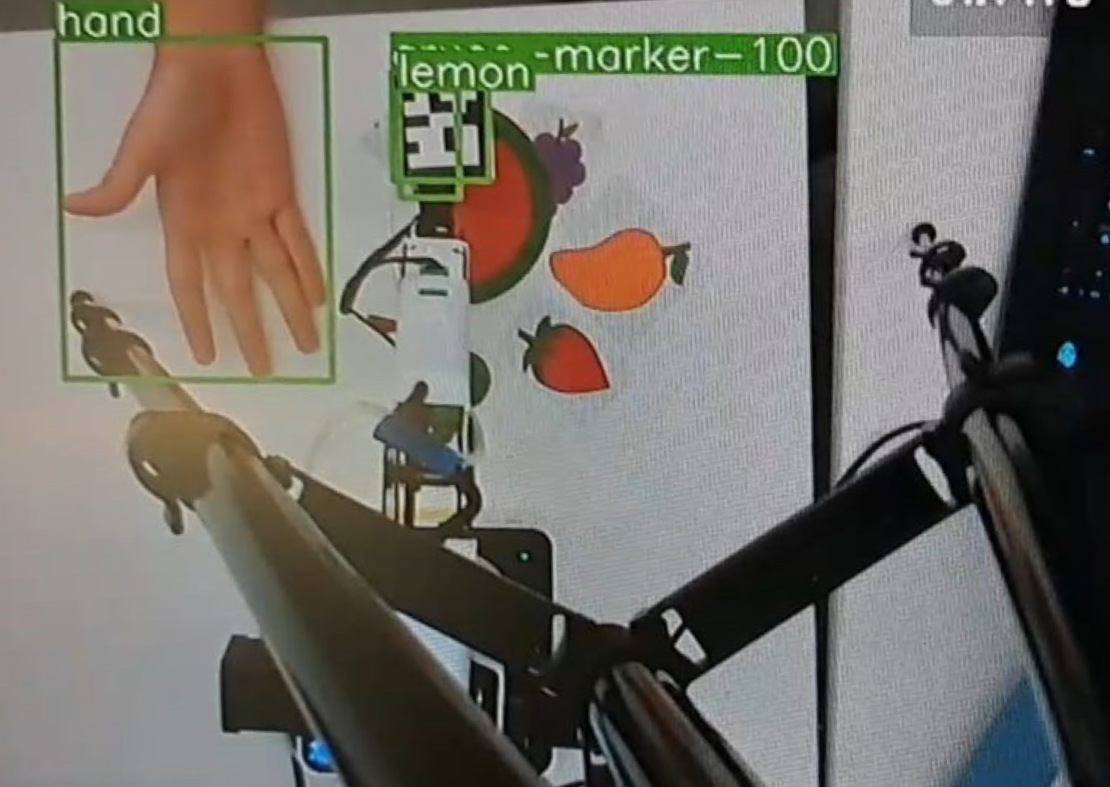
The system utilizes an Intel RealSense D435i camera to acquire real-time depth and RGB data of the surrounding environment. This data is then processed by Florence-2, a foundation model specifically designed for computer vision tasks. Florence-2 performs object detection, identifying and localizing objects within the camera’s field of view, and provides the necessary visual information for subsequent task planning and execution. The D435i’s integrated depth sensing capabilities enable accurate spatial understanding, crucial for object manipulation and navigation, while Florence-2’s foundation model architecture allows for generalization to novel objects and scenes without requiring extensive retraining.
The system’s speech processing pipeline utilizes OpenAI’s Whisper model for automatic speech recognition, converting spoken language into a textual representation. This transcription is then processed by LLaMA 3.1, a large language model, to perform semantic interpretation of the user’s commands. LLaMA 3.1 analyzes the transcribed text to determine the intent and meaning behind the spoken request, extracting key information necessary for task execution. This two-stage process ensures accurate conversion of audio input into actionable commands for the system.
The system achieves contextual awareness by integrating data from both visual and linguistic sources. Real-time scene understanding is derived from the Intel RealSense D435i camera, while user intent is determined through OpenAI Whisper speech transcription and subsequent semantic analysis using LLaMA 3.1. This fusion of visual perception and language understanding enables the system to correlate user commands with the observed environment, resulting in a reported 75% success rate for object manipulation tasks. This performance metric is based on controlled experiments evaluating the system’s ability to accurately identify and interact with specified objects in response to verbal requests.
Precision Embodied: Orchestrating Physical Action
The Dobot Magician robotic arm functions as the primary effector for physical tasks within the system. This six-degree-of-freedom arm provides the necessary range of motion and payload capacity for manipulation. It is fully integrated with a dedicated Robot Control system, which manages all aspects of arm movement, including trajectory planning, velocity control, and position feedback. The control system utilizes a modular architecture, allowing for easy integration of additional sensors and algorithms. Communication between the control system and the robotic arm occurs via a dedicated communication protocol, ensuring low-latency and reliable operation.
ArUco Markers facilitate accurate robot localization and object tracking by establishing a known reference frame. These markers, which are square binary patterns, are detectable by the robot’s vision system, allowing for real-time pose estimation – determining both position and orientation – of both the robot end-effector and targeted objects. The use of ArUco Markers minimizes the impact of visual noise and varying lighting conditions, providing a consistently reliable input for the robot’s control system. This method allows the system to translate visual data into precise spatial coordinates, enabling accurate path planning and manipulation tasks.
The robotic arm’s movement control utilizes an Interval Type-2 Fuzzy Logic System, an advancement over traditional Fuzzy Logic Control designed to improve performance in unpredictable environments. This system allows the robot to manage uncertainties inherent in real-world tasks by incorporating a wider range of membership functions and rules. Performance metrics demonstrate an average total task completion time of 35.37 seconds, with a standard deviation of 2.69 seconds, indicating consistent and reliable operation across multiple trials.

Beyond Automation: Towards True Collaborative Intelligence
The convergence of Foundation Models and robust control strategies represents a substantial advancement in Human-Robot Interaction, moving beyond pre-programmed responses towards genuinely adaptive collaboration. This system leverages the perceptual capabilities of Foundation Models – large AI networks pre-trained on vast datasets – to interpret complex environments and user intentions with greater accuracy. Crucially, this understanding isn’t simply relayed to the robot; it’s integrated with control algorithms that enable dynamic, real-time adjustments to the robot’s actions. The result is a system capable of responding to nuanced commands, navigating unpredictable situations, and completing tasks with a level of flexibility previously unattainable, effectively blurring the line between human instruction and autonomous robotic behavior. This approach promises a future where robots aren’t merely tools, but collaborative partners capable of understanding and responding to human needs in a truly intuitive manner.
Recent advancements in human-robot collaboration prioritize intuitive interaction, moving away from complex programming requirements through the fusion of speech and vision processing. This integrated approach enables robots to interpret natural language commands coupled with visual understanding of the environment, streamlining task execution. Quantitative analysis reveals that object detection currently constitutes 25.72% of the total time required for task completion, while the physical execution of robot actions accounts for a slightly larger 28.49%. These figures highlight the significant, yet distinct, contributions of perceptual and manipulative processes, suggesting that optimizing both areas is crucial for achieving truly seamless and efficient human-robot teamwork.
Ongoing development centers on enhancing the system’s capacity for independent learning, with the ultimate goal of predictive assistance and self-optimization during human-robot collaboration. Current error analysis reveals that inaccuracies primarily stem from the execution of robotic actions – accounting for 40% of total errors – and difficulties in accurately extracting intended actions from user input, which contributes 33.33%. Addressing these specific areas through improved algorithms and expanded datasets promises to move beyond reactive task completion towards a collaborative partner capable of anticipating needs and refining its performance without explicit instruction, ultimately streamlining workflows and increasing efficiency in shared workspaces.
The pursuit of robust human-robot interaction, as detailed in this work, inherently demands a willingness to push the boundaries of established systems. The framework presented-combining large language models, vision-language models, and fuzzy logic-is not about flawless execution, but about intelligently navigating ambiguity. This aligns perfectly with John McCarthy’s assertion: “It is better to deal with reality, even if it is messy, than with neat, convenient fictions.” The research acknowledges the ‘moderate reliability’ of current object manipulation-a pragmatic acceptance of imperfection. It’s a process of reverse-engineering the complexities of human instruction and robotic action, finding utility in the ‘messy’ interface between them. The study isn’t aiming for a perfect simulation of understanding, but a functional approximation that allows for meaningful interaction, even amidst inevitable errors.
What’s Next?
The demonstrated coupling of foundation models with robotic actuation, while promising, inevitably highlights the brittleness inherent in any system built upon statistical correlation. Success, in this context, isn’t about achieving seamless obedience, but about meticulously documenting failure. The current framework, while able to manipulate objects with ‘moderate reliability’, still relies on a world that largely conforms to the training data. The true test lies in graceful degradation – how does the system respond to the novel, the unexpected, the deliberately misleading command?
Future work must move beyond simply increasing the volume of training data. The focus should shift to internal models of uncertainty – not just ‘what is likely to happen’, but ‘what could happen, and how do those possibilities affect the robot’s actions?’ Fuzzy logic provides a starting point, but a truly robust system will require a more nuanced understanding of probabilistic reasoning and, crucially, the ability to question its own perceptions.
Ultimately, the best hack is understanding why it worked; every patch is a philosophical confession of imperfection. The pursuit of genuinely intelligent robotic interaction isn’t about eliminating error, but about building systems that are fascinatingly, and predictably, wrong in novel ways.
Original article: https://arxiv.org/pdf/2602.20219.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Limbus Company 2026 Roadmap Revealed
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Total Football free codes and how to redeem them (March 2026)
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- ‘Project Hail Mary’s Soundtrack: Every Song & When It Plays
2026-02-25 08:24