Author: Denis Avetisyan
Researchers are developing new systems that enable robots to engage in more natural and grounded conversations by combining real-time sensory input with advanced language processing.
![The system integrates streaming egocentric vision and audio via a real-time multimodal language model to not only generate spoken dialogue but also to proactively issue low-latency function calls-such as directing gaze to specific people, objects, or areas-that dynamically update perceptual context and drive active perception through external tools like [latex]Look\_at\_Person[/latex], [latex]Look\_at\_Object[/latex], and [latex]Use\_Vision[/latex].](https://arxiv.org/html/2602.04157v1/figs/main_fig.png)
This review details a modern system architecture integrating multimodal language models, tool-mediated attention, and active perception for situated embodied human-robot conversation.
Achieving truly natural human-robot interaction demands more than just dialogue-it requires grounding conversation in shared perception and action. This paper, ‘A Modern System Recipe for Situated Embodied Human-Robot Conversation with Real-Time Multimodal LLMs and Tool-Calling’, introduces a system architecture that integrates real-time multimodal language models with tool-mediated attention and active perception capabilities. Through evaluations across diverse home-style scenarios, we demonstrate that this approach enables robots to dynamically shift focus and respond to their environment, improving the correctness of tool-use decisions and subjective interaction quality. Could this represent a scalable pathway towards more engaging and effective situated embodied conversational agents?
Deconstructing Dialogue: The Quest for Shared Reality
For human-robot interaction to move beyond simple command-response systems, a fundamental shift is required: robots must develop an understanding of the shared physical world. Conversational fluency, while important, is insufficient without the ability to perceive and reason about the environment – the objects present, their relationships, and the actions taking place within it. This ‘situatedness’ allows for richer, more intuitive dialogue, enabling humans to communicate using spatial references, demonstrations, and implicit cues that are effortlessly understood in human-to-human interaction. A robot capable of grounding conversation in real-world perception can not only respond to requests like “Pass the red mug,” but also anticipate needs, resolve ambiguities, and engage in collaborative tasks with a level of naturalness currently beyond the reach of most artificial intelligence systems. Ultimately, a shared understanding of the physical world forms the bedrock of truly natural and effective human-robot collaboration.
Contemporary conversational AI often falters not because of linguistic shortcomings, but due to an inability to connect dialogue with the immediate physical environment. These systems frequently process language as abstract symbols, divorced from the perceptual reality shared by humans – a critical flaw when interaction demands shared understanding of objects, locations, and ongoing actions. This disconnect results in interactions that feel disjointed and ineffective; a user might ask a robot to “pick up the red block,” but without real-time visual perception, the system cannot differentiate it from other objects or even confirm its presence. Consequently, the conversation devolves into frustrating clarification requests or, worse, incorrect actions, highlighting the crucial need for AI that can seamlessly integrate language processing with real-time sensory input to achieve truly natural and effective communication.
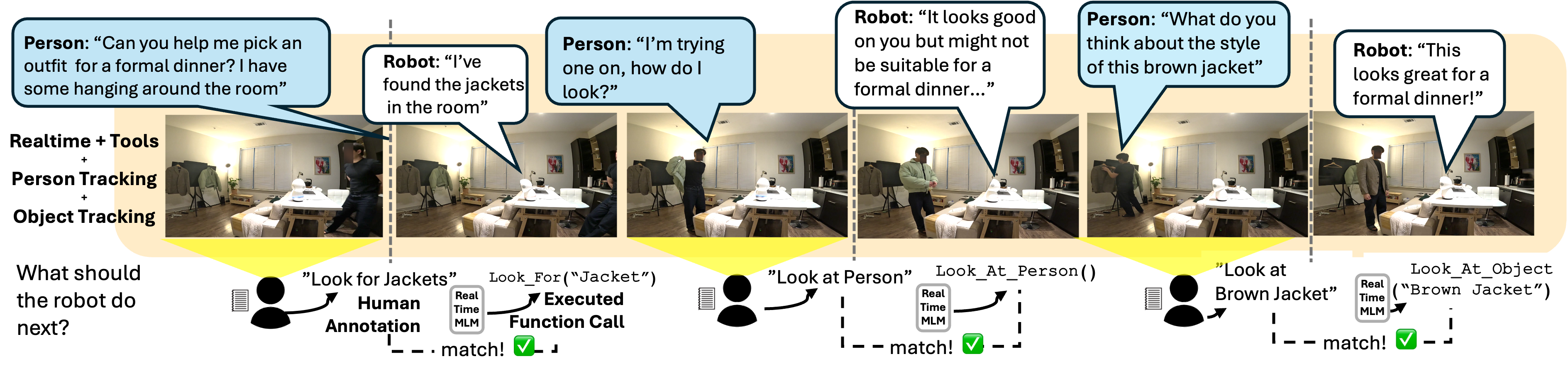
Real-time Perception: Weaving Sensory Input into the Conversational Fabric
The core of our system utilizes a Real-time Multimodal Language Model designed to ingest and process continuous, concurrent audio and video data streams. This model differs from traditional language models by directly accepting raw sensory input, eliminating the need for pre-segmentation or feature extraction. Input audio is processed using a waveform-based approach, while video is handled via a convolutional neural network to extract spatial and temporal features. These features are then fused and fed into a transformer-based architecture, allowing the model to jointly reason about both modalities and generate contextually relevant outputs in real-time. The model’s architecture is optimized for low-latency processing, enabling responses to be generated with minimal delay despite the continuous nature of the input streams.
The system utilizes real-time streaming data from both audio and video sources to establish contextual awareness. This data, processed continuously, provides information regarding the surrounding environment, including visual cues and spoken content. The model analyzes this incoming stream to identify relevant entities, activities, and relationships, which are then incorporated into the dialogue management process. Specifically, the streaming data informs the model’s understanding of the current situation, enabling it to generate conversational responses that are contextually appropriate and relevant to the ongoing interaction. This continuous analysis allows for dynamic adaptation to changes within the environment, ensuring the model maintains an accurate representation of the context throughout the conversation.
Dialogue Management within the Real-time Multimodal Language Model is achieved through a recurrent neural network architecture incorporating both contextual embeddings from processed audio and video streams, and a state-tracking mechanism. This mechanism maintains a representation of the conversational history, allowing the model to predict appropriate responses based on previous turns and the current multimodal input. Specifically, the model utilizes a hierarchical approach, first encoding individual utterances, then aggregating these encodings into a dialogue state vector. This vector is used to condition the generation of subsequent responses, ensuring coherence and relevance by prioritizing information aligned with the established conversational context and avoiding repetition or contradictions. The system employs beam search during response generation, optimizing for both likelihood and diversity to produce more natural and engaging interactions.
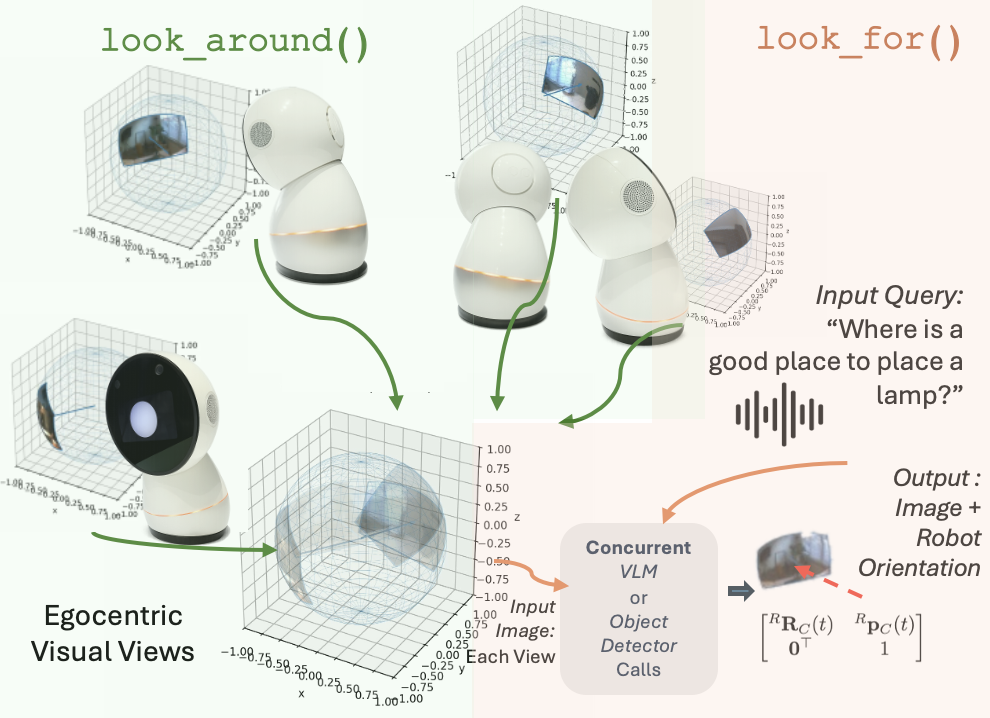
Active Perception: The Robot as an Investigator
Active Perception within the system is implemented to allow the robot to independently acquire visual data driven by the current conversational context. This means the robot does not passively receive images, but instead initiates visual scans and focuses its attention on elements relevant to the dialogue. The system correlates linguistic input with requests for visual information, enabling the robot to actively seek out and process imagery to enhance its understanding and inform its responses. This proactive approach contrasts with systems relying solely on pre-existing visual data or operator-directed viewpoints.
Attention Control within the system functions by dynamically directing the robot’s visual focus – specifically its gaze – to entities identified as relevant to the ongoing interaction. This is accomplished by prioritizing visual input based on contextual cues derived from dialogue; for example, if a user references “the red mug,” Attention Control mechanisms will prioritize processing visual data pertaining to objects matching that description. The system then translates these identified targets into precise gaze commands, allowing the robot to actively observe and interpret the elements of its environment that are most pertinent to the current conversation or task.
The robot’s attention control is facilitated by a suite of tools designed to direct its visual focus. “Look at Person” and “Look at Object” commands allow for targeted gaze towards specified entities, while “Look Around” enables a broader scan of the environment. More complex queries are addressed by “Look For,” which initiates a search for particular items, and “Use Vision,” a generalized command to leverage visual input for task completion. These tools collectively support dynamic scene understanding by allowing the robot to actively acquire visual information relevant to the ongoing dialogue and its internal state.
The Geometric Binding Layer serves as the interface between processed image data and the robot’s gaze control system. This layer receives 2D image coordinates identifying target objects or people and transforms these into the 3D coordinates required for accurate robot head and eye movements. This transformation accounts for the robot’s physical dimensions, joint limitations, and the camera’s intrinsic and extrinsic parameters. The resulting output is a set of motor commands that direct the robot’s gaze to the specified target, ensuring visual focus is maintained even with changes in distance or orientation. Precise calibration of both the camera and robot kinematics is critical for the layer’s effective performance.
View Memory: Echoes of Experience
View Memory functions as a short-term episodic memory, storing a limited history of the robot’s visual observations as discrete viewpoints. This data includes both visual data – typically RGB images – and the associated pose information (position and orientation) from which the image was captured. The storage is designed to be lightweight, prioritizing recent observations and employing a fixed-size buffer to manage computational resources. Consequently, View Memory enables the system to reference previously seen scenes, facilitating contextual understanding during current interactions and allowing for responses grounded in past experience, rather than solely relying on immediate sensory input.
View Memory utilizes data acquired through the ‘Look Around’ tool to create a persistent record of the robot’s visual surroundings. This record isn’t a complete scene reconstruction, but rather a focused storage of previously observed viewpoints, including pose and associated visual features. The system can then retrieve and correlate these past observations with current sensory input. This allows the robot to recognize previously seen objects or locations even with partial occlusion or changes in lighting, and to maintain spatial consistency during interactions by referencing established viewpoints. The frequency and retention period of these stored viewpoints are configurable parameters, balancing memory usage against the need for contextual recall.
The system’s capacity for Situated Awareness is enhanced by integrating two distinct data streams into dialogue processing. Current perception, derived from real-time sensor input, is combined with information retrieved from View Memory – a record of previously observed viewpoints and associated data. This fusion allows the system to reference both immediate surroundings and past experiences when interpreting user requests or formulating responses. Consequently, the system can maintain contextual consistency across interactions and provide more relevant, informed dialogue, effectively ‘grounding’ conversation in a comprehensive understanding of the environment and its history.
Measuring Awareness: Beyond Task Completion
Turn-Level Tool-Decision Evaluation provides a granular method for quantifying a robot’s conversational competence. Rather than assessing overall dialogue success, this approach analyzes the appropriateness of each tool selected by the robot at every turn in the conversation. This meticulous evaluation focuses on whether the chosen tool logically follows from the preceding dialogue and effectively addresses the current conversational need. By breaking down the interaction into discrete turns, researchers can pinpoint specific instances where the robot demonstrates strong or weak reasoning, identifying areas for improvement in its tool selection process and, ultimately, its capacity for situated awareness. The technique allows for a detailed understanding of how a robot arrives at its decisions, not just what those decisions are, offering a nuanced perspective on its interactive intelligence.
A crucial component of assessing a conversational agent’s performance lies in understanding not just what it says, but how attentively it engages with the user; the Networked Minds Questionnaire offers a rigorous, standardized approach to this evaluation. This tool moves beyond simple task completion metrics to directly measure a participant’s perception of the agent’s attentiveness and overall interaction quality. By employing a validated set of questions, researchers can objectively quantify how well the agent allocates its ‘attention’ – effectively, how appropriately it responds to user cues and maintains conversational coherence. The questionnaire’s standardized nature allows for meaningful comparisons across different agents and experimental conditions, providing valuable insights into the factors that contribute to truly engaging and effective human-robot interaction and ultimately, a more natural and intuitive user experience.
The system demonstrates a substantial capacity for discerning the correct course of action during conversational exchanges, achieving a macro-averaged tool-decision accuracy of 0.72 when integrated with the OpenAI Realtime backend. Performance improves slightly to 0.77 utilizing the Gemini Live backend, indicating a robust foundation for practical application. This metric reflects the system’s ability to appropriately select tools – ranging from information retrieval to task execution – at each turn of a conversation, suggesting a high degree of functional intelligence and paving the way for more nuanced and effective human-robot interactions. The consistency of results across different language models highlights the system’s adaptability and potential for broader implementation.
The system’s ability to accurately identify when to utilize the ‘look_for’ tool proved remarkably consistent across both the OpenAI Realtime and Gemini Live backends, achieving perfect precision – meaning every instance where the tool was activated was correct and relevant. While precision remained flawless, recall varied, indicating a 70% success rate in identifying all situations requiring the ‘look_for’ tool with OpenAI, and a slightly lower 60% with Gemini. This suggests the system reliably knows when not to search, but opportunities exist to improve its ability to consistently recognize all instances where a search would be beneficial, potentially enhancing its overall situational awareness and responsiveness during interactions.
A robust evaluation of a conversational agent’s performance requires more than simply assessing task completion; it demands a quantifiable understanding of its situated awareness – its ability to perceive and react appropriately to the nuances of an ongoing interaction. The metrics employed in this research – tool-decision accuracy, precision, and recall – provide a framework for objectively measuring this capacity. By analyzing the robot’s choices at each conversational turn and correlating them with expected actions, researchers can determine how effectively the system maintains context and responds to user needs. This detailed assessment not only highlights strengths, such as the perfect precision observed with the ‘look_for’ tool, but also pinpoints areas for improvement, ultimately driving the development of more natural and effective conversational experiences. The resulting data offers a valuable benchmark for comparing different backend models, like OpenAI and Gemini, and tracking progress towards truly intelligent and contextually aware robotic communication.
The architecture detailed within this work doesn’t merely allow for situated embodied conversation; it actively necessitates a degree of controlled imperfection. The system’s reliance on tool-mediated attention and active perception, while striving for seamless interaction, inherently introduces points of potential failure – moments where perception is limited or action is imperfect. As such, it echoes a sentiment articulated by Henri Poincaré: “Mathematics is the art of giving reasons.” The ‘reasons’ here aren’t purely mathematical, but represent the system’s internal logic exposed through its limitations. Each successful tool-call, each refined attention focus, is a testament to overcoming inherent imperfections, a pragmatic dance with the unavoidable gaps in complete understanding. The best hack, ultimately, is understanding why the system worked, even – or especially – when it didn’t work perfectly.
What Breaks the Illusion?
The architecture detailed here achieves a functional, if presently fragile, loop between perception, language, and action. But one pauses to consider: is ‘grounding’ merely statistical convergence, or does true understanding demand a model of its own fallibility? The system reacts to its environment; it does not, presently, question it. Future work must deliberately introduce inconsistencies, illogical prompts, and outright deception to probe the limits of this ‘situated’ intelligence. What happens when the robot’s sensors report a contradiction – does it resolve it, or does the system simply…fail gracefully?
Current attention control mechanisms, while effective, remain largely reactive. The next iteration should explore predictive attention – anticipating salient features before they fully manifest, driven not by immediate sensory input, but by internal models of likely events. Could such a system learn to ‘look around the corner’, so to speak, and preemptively address potential issues? Or, conversely, would this introduce a cascade of false positives, crippling its responsiveness?
Finally, the reliance on tool-calling, while pragmatic, raises a curious point. Is the robot solving problems, or simply executing pre-defined scripts with greater dexterity? The true test lies not in what it can do, but in its ability to creatively repurpose tools for unforeseen tasks. Perhaps the bug isn’t a flaw, but a signal-an indication that the system is beginning to truly improvise.
Original article: https://arxiv.org/pdf/2602.04157.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Limbus Company 2026 Roadmap Revealed
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
2026-02-05 16:50