Author: Denis Avetisyan
A new study details how Kubernetes, enhanced with open-source tools, can efficiently manage the demanding workloads of modern generative AI applications.
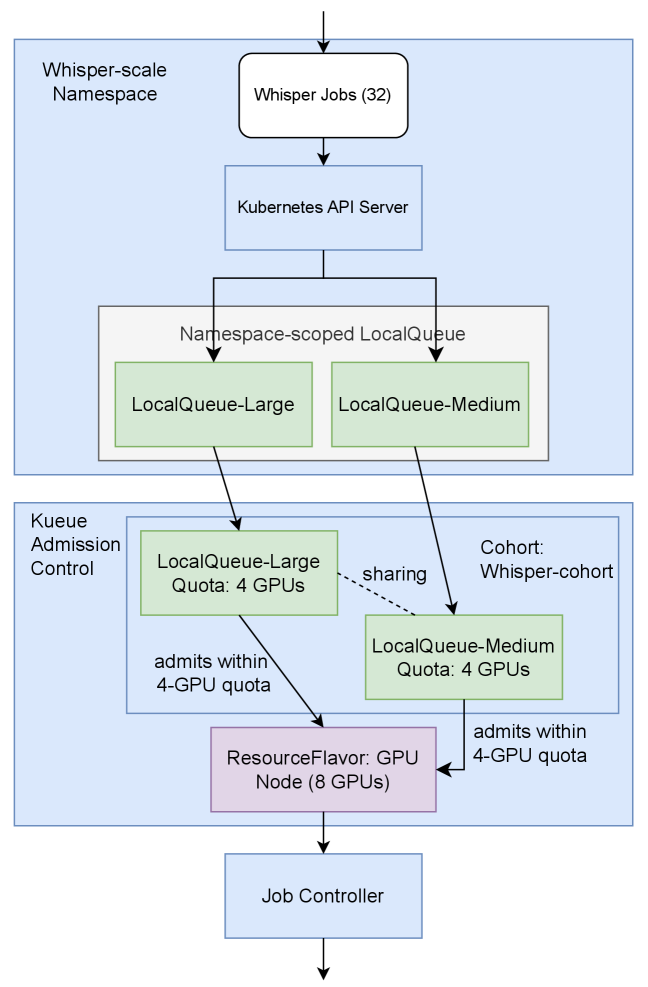
This research evaluates Kubernetes performance for AI inference, from speech recognition to large language model summarization, leveraging dynamic resource allocation and GPU slicing.
Despite the increasing demand for scalable and efficient infrastructure to support generative AI, orchestrating complex inference workflows remains a significant challenge. This paper, ‘Evaluating Kubernetes Performance for GenAI Inference: From Automatic Speech Recognition to LLM Summarization’, investigates how Kubernetes, enhanced with projects like Kueue, Dynamic Accelerator Slicer (DAS), and the Gateway API Inference Extension (GAIE), can effectively address this need. Our results demonstrate substantial performance gains-up to 15% reduction in makespan, 36% faster job completion, and 82% improvement in Time to First Token-proving Kubernetes’ potential as a unified platform for demanding GenAI workloads. Will this combination of technologies become the standard for deploying and scaling AI inference services in production environments?
The Inevitable Scaling Problem
Large language models, exemplified by Qwen3-8B, represent a substantial leap in artificial intelligence, demonstrating remarkable abilities in natural language processing, text generation, and complex reasoning. However, this power comes at a cost; these models are inherently computationally intensive. Their architecture, often involving billions of parameters, necessitates substantial memory, processing power, and energy consumption for both training and inference. Effectively deploying such models requires navigating the trade-off between performance and resource availability, as the sheer size of Qwen3-8B and similar architectures presents a significant hurdle for widespread adoption, particularly in latency-sensitive applications and resource-constrained environments. The demand for specialized hardware and optimized software solutions is therefore critical to unlock the full potential of these advanced AI systems.
Current deployment methods often fall short when attempting to serve large language models at scale, creating a bottleneck for applications demanding swift responses. The inherent computational intensity of models like Qwen3-8B, coupled with the sequential nature of text generation, leads to increased latency – the delay between a request and a response. Traditional approaches, such as relying on a single server instance, struggle to handle a high volume of concurrent requests, resulting in reduced throughput and potential service degradation. This poses a significant challenge for real-time applications like conversational AI, live translation, and interactive gaming, where even fractions of a second delay can negatively impact the user experience. Consequently, innovative solutions are needed to overcome these limitations and unlock the full potential of large language models in dynamic, user-facing scenarios.
Delivering large language model capabilities at scale necessitates a departure from conventional serving methods. Simply increasing hardware isn’t a sustainable solution; instead, researchers are exploring dynamic resource allocation techniques that intelligently distribute computational load based on request complexity and priority. This involves sophisticated request scheduling algorithms, moving beyond first-come, first-served approaches to prioritize time-sensitive tasks and batch similar requests for improved throughput. Furthermore, innovative methods like model parallelism – distributing the model itself across multiple devices – and quantization – reducing the precision of model weights – are being actively investigated to minimize memory footprint and accelerate inference. These combined strategies aim to maximize the utilization of available resources, ultimately enabling responsive and cost-effective deployment of powerful LLMs for real-world applications.
Kubernetes: A Necessary Foundation, Not a Silver Bullet
Kubernetes provides a production-grade environment for deploying and managing containerized Large Language Model (LLM) inference servers through features like automated deployment, scaling, and self-healing. Its architecture allows for the distribution of LLM workloads across a cluster of nodes, increasing throughput and availability. Kubernetes’ declarative configuration manages the desired state of applications, automatically adjusting resources based on demand. This orchestration capability is crucial for LLM inference, which often requires significant computational resources and necessitates high availability to serve user requests efficiently. The platform’s support for containerization ensures consistency across different environments, simplifying the development and deployment pipeline for LLM-powered applications.
OpenShift builds upon Kubernetes by adding tools and features designed to streamline application development and deployment for enterprise environments. These include pre-built CI/CD pipelines, source-to-image capabilities for automated container image creation, and integrated monitoring and logging solutions. Furthermore, OpenShift incorporates enhanced security features such as Security Context Constraints and image vulnerability scanning. It also simplifies cluster management through features like automated updates, declarative configuration via GitOps principles, and a web console and CLI for streamlined administration, ultimately reducing operational overhead compared to a bare Kubernetes implementation.
Kubernetes’ dynamic resource allocation capabilities facilitate the efficient utilization of hardware accelerators, such as GPUs, by allowing multiple AI workloads to share access to these finite resources. Traditional static allocation often results in underutilization, as workloads may not consistently require the full capacity of the assigned GPU. Kubernetes addresses this through features like multi-scheduling and resource quotas, enabling the platform to dynamically assign GPU capacity to running containers based on demand. This is achieved by defining resource requests and limits for each workload, and the Kubernetes scheduler intelligently places pods onto nodes with available GPU resources, maximizing throughput and reducing costs associated with idle hardware. Further optimization is possible through technologies like Kubernetes Device Plugins, which allow Kubernetes to discover and manage GPU devices, and frameworks that support GPU virtualization and sharing at the software level.
Optimized Scheduling: A Necessary Layer of Complexity
Gang Scheduling is employed to improve inference performance by simultaneously scheduling all tasks belonging to a single inference request. This co-location of related tasks minimizes inter-task communication overhead, as data required by dependent tasks is readily available without requiring network transfers or memory access delays. By processing these tasks in parallel on the same hardware, throughput is significantly increased compared to scheduling tasks individually. This approach is particularly effective for models with sequential dependencies, where the output of one task serves as the input for the next, resulting in a more efficient and faster overall inference process.
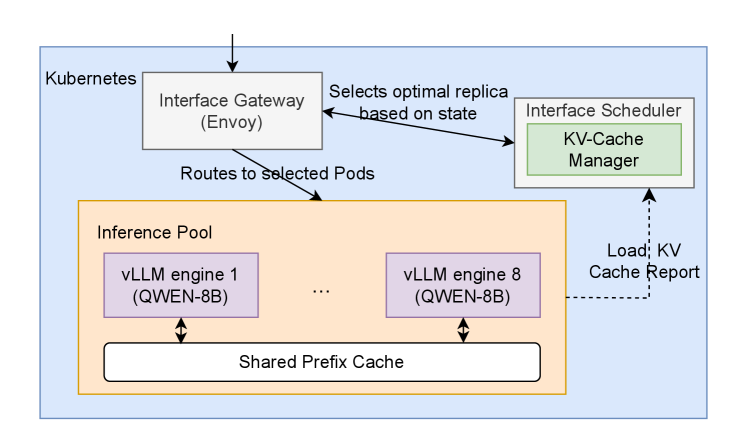
The Gateway API Inference Extension facilitates intelligent routing of incoming inference requests to available backend instances. This functionality enables enhanced scalability by distributing load across multiple instances, preventing overload on any single instance. Furthermore, the extension improves fault tolerance through automatic request redirection in the event of instance failures; requests are seamlessly routed to healthy instances without interruption. This dynamic routing is achieved by monitoring instance health and capacity, and leveraging the Gateway API’s traffic management capabilities to ensure optimal performance and reliability of inference services.
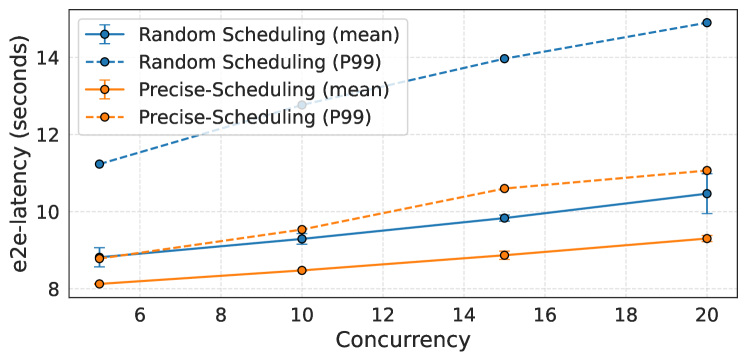
Precise Prefix-Cache Aware Scheduling significantly reduces inference latency by prioritizing requests that exhibit prefix overlap with previously processed requests. This scheduling method leverages a cached prefix store, allowing subsequent requests sharing common prefixes to bypass redundant computations. Benchmarking demonstrates a 6x improvement in Time to First Token (TTFT) and a corresponding 6x reduction in overall latency when compared to Random Scheduling. The performance gain is directly attributable to minimizing redundant processing and maximizing cache utilization, resulting in faster response times for subsequent, similar requests.
Dynamic Resource Partitioning: Squeezing Every Last Cycle
The innovative Dynamic Accelerator Slicer leverages NVIDIA’s Multi-Instance GPU (MIG) technology to fundamentally alter how GPU resources are allocated for inference workloads. Rather than dedicating an entire GPU to a single task, this approach partitions the GPU into multiple, isolated slices-effectively creating several virtual GPUs within a single physical device. This allows for the concurrent execution of multiple inference tasks, each operating on its dedicated slice, thereby increasing throughput and efficiency. By dynamically assigning these slices based on workload demands, the system avoids the bottlenecks inherent in traditional, static resource allocation, paving the way for substantial performance gains and reduced infrastructure costs.
The integration of Dynamic Accelerator Slicer with Kubernetes’ orchestration capabilities fundamentally alters how GPU resources are allocated and utilized. Kubernetes, a widely adopted container orchestration system, intelligently manages computational workloads and dynamically assigns them to available resources. By combining this with the GPU slicing technology, systems avoid the traditional need to dedicate entire GPUs to single tasks, even if those tasks don’t fully utilize the hardware. This allows multiple inference jobs to run concurrently on a single physical GPU, effectively maximizing its uptime and throughput. Consequently, organizations can achieve substantial cost savings by reducing over-provisioning – the practice of allocating more resources than necessary to guarantee performance – and optimizing the efficiency of their GPU infrastructure.
Evaluations utilizing both the Whisper speech recognition model and the Earnings 22 dataset reveal significant performance gains through this combined approach to resource allocation. Specifically, the system demonstrated a 15% reduction in makespan – the total time required to complete a batch of inference tasks – indicating improved throughput. Furthermore, analysis of job completion times showed a substantial 36% decrease in the mean time taken to process individual requests. These results suggest that dynamic partitioning, facilitated by NVIDIA MIG and Kubernetes, substantially optimizes GPU utilization, leading to faster processing and reduced latency for concurrent inference workloads.
The Long View: Sustainable AI Requires Pragmatism
Large Language Models (LLMs) demand substantial computational resources, yet achieving both scalability and efficiency in their deployment presents a significant challenge. Modern infrastructure increasingly relies on Kubernetes, an orchestration system capable of managing containerized applications across a cluster of machines. When coupled with advanced scheduling algorithms – which intelligently allocate LLM workloads based on resource availability and priority – and dynamic resource partitioning, this creates a highly adaptable system. This approach moves beyond static resource allocation, allowing LLMs to utilize only the necessary compute power, thereby maximizing cluster utilization and minimizing operational costs. The result is an infrastructure capable of handling growing LLM demands with lower latency, increased throughput, and a more sustainable resource footprint – critical for widespread AI adoption.
Organizations are increasingly able to deploy artificial intelligence applications with significant improvements in performance and economic viability through optimized workflows. By strategically combining resource management techniques, these deployments achieve lower latency – the delay between request and response – enabling more responsive and real-time interactions. Simultaneously, throughput – the volume of requests processed over a given period – is substantially increased, allowing for greater scalability and user capacity. This combination of speed and volume directly translates into reduced operational costs, as fewer resources are needed to handle the same workload, ultimately making advanced AI solutions more accessible and sustainable for a wider range of applications and industries.
The llm-d project demonstrates a pragmatic pathway for integrating large language model capabilities into pre-existing infrastructure. By leveraging Kubernetes’ ClusterIP service type and the high-throughput serving framework vLLM, llm-d sidesteps the complexities often associated with deploying and scaling LLMs. This approach allows organizations to expose LLM endpoints as internal services, readily accessible to other applications within their Kubernetes clusters, without requiring extensive architectural overhauls. The result is a streamlined deployment process, reduced operational overhead, and the ability to rapidly prototype and scale AI-powered features, effectively showcasing how advanced scheduling and resource partitioning can be immediately beneficial within current systems.
The pursuit of elegant resource orchestration, as detailed in this evaluation of Kubernetes and its extensions, inevitably leads to a familiar outcome. They’ll call it AI and raise funding, of course. The paper painstakingly demonstrates how Kueue, DAS, and GAIE attempt to tame the beast of GenAI inference, promising improved utilization and scalability. But one suspects that each clever optimization, each dynamic resource allocation scheme, merely delays the inevitable accumulation of tech debt. It’s a constant battle against production’s relentless ability to expose the cracks in even the most carefully constructed systems. The documentation lied again, promising a world where Kubernetes effortlessly handles LLM summarization – as if a simple bash script hadn’t once achieved the same, albeit less ‘efficiently’.
What’s Next?
The demonstrated capacity of Kubernetes – augmented, naturally, by a supporting cast of projects like Kueue, DAS, and GAIE – to manage GenAI inference feels less like a breakthrough and more like a necessary complication. Resource orchestration always solves one problem by creating several others, and the observed improvements in utilization and responsiveness will inevitably be challenged by the realities of production. Someone, somewhere, will find a way to overload the scheduler, exhaust the GPU slices, or discover a previously unforeseen bottleneck. It’s not a matter of if, but when.
Future work will likely focus on automating the automation. The configuration complexity inherent in these systems demands more sophisticated auto-scaling and resource provisioning. Expect a proliferation of ‘observability’ tools, each promising to reveal the chaos hidden beneath the surface. The real challenge, however, isn’t simply monitoring the system, but accepting that perfect optimization is an illusion. If the dashboards look pristine, it means no one has actually deployed anything substantial.
The current focus on Kubernetes as the solution is also worth noting. History suggests that every elegant architecture becomes tomorrow’s tech debt. While the flexibility is appealing, the overhead is considerable. The next iteration will likely involve a trade-off: a more specialized, less general-purpose system designed specifically for GenAI inference. It won’t be ‘revolutionary,’ just… pragmatic.
Original article: https://arxiv.org/pdf/2602.04900.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Gold Rate Forecast
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- ‘Project Hail Mary’s Soundtrack: Every Song & When It Plays
- Total Football free codes and how to redeem them (March 2026)
- All Mobile Games (Android and iOS) releasing in April 2026
- Top 5 Best New Mobile Games to play in April 2026
2026-02-09 03:51