Author: Denis Avetisyan
Researchers have developed a new framework that allows humanoid robots to understand and react to natural language commands in real-time, enabling more intuitive and adaptable interactions.
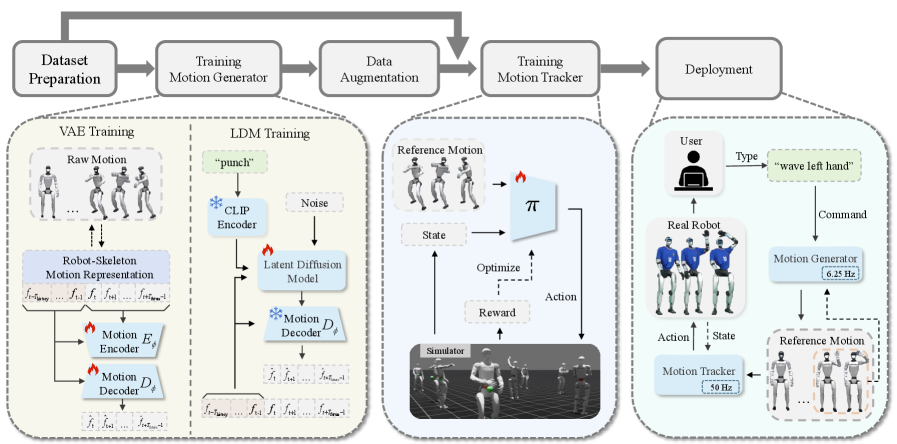
TextOp leverages diffusion models and reinforcement learning to translate natural language into continuous, whole-body control for humanoid robots.
Existing humanoid robot control systems struggle to balance responsiveness to changing user intent with the need for robust, autonomous execution. This limitation motivates the work presented in ‘TextOp: Real-time Interactive Text-Driven Humanoid Robot Motion Generation and Control’, which introduces a framework enabling real-time adaptation of complex whole-body movements based on natural language commands. TextOp achieves this through a two-level architecture combining an autoregressive motion diffusion model with a reinforcement learning-based tracking policy, allowing for seamless transitions between behaviors like dancing and jumping within a single continuous motion. Could this approach unlock truly intuitive and flexible human-robot interaction, paving the way for more adaptable and collaborative robotic systems?
The Illusion of Agency: Bridging the Gap Between Command and Motion
The creation of convincingly human-like movement in robots presents a significant hurdle for researchers, stemming from the sheer intricacy of coordinating a humanoid’s many joints and degrees of freedom. Unlike simpler robotic systems, a humanoid doesn’t just need to reach a point, but to do so with balance, fluidity, and a natural gait – requiring the simultaneous and precise control of dozens of actuators. Each movement isn’t isolated; it’s a cascade of adjustments across the entire body, demanding sophisticated algorithms to manage the interplay between limbs, torso, and head. This complexity isn’t merely a computational challenge; it’s a fundamental problem of physical coordination, mirroring the intricate neural processes that govern human motion and presenting a substantial barrier to creating robots capable of seamless interaction within human environments.
Conventional robotic systems frequently encounter difficulties when interpreting descriptive language and converting it into realistic physical movements. These methods often produce stiff, unnatural motions because they prioritize direct kinematic control over replicating the subtle dynamics inherent in human actions. While a robot might successfully execute a command like “walk forward,” it often fails to capture the slight variations in gait, the fluid weight transfer, or the responsive adjustments to uneven terrain that characterize natural human locomotion. This limitation stems from a reliance on pre-programmed sequences or simplified models that lack the complexity needed to represent the full range of human movement, resulting in robotic actions that, while technically correct, appear robotic – lacking the grace and adaptability expected of truly intelligent machines.
The persistent challenge of imbuing robots with truly natural movement necessitates a departure from conventional approaches. Current robotic systems often interpret textual commands literally, resulting in stilted or unnatural actions; a fundamental disconnect exists between the symbolic representation of language and the continuous demands of physical embodiment. A novel paradigm seeks to resolve this ‘semantic gap’ by focusing not merely on the words themselves, but on the underlying intention communicated within the language. This involves developing systems capable of inferring the desired outcome of a command – the goal the robot should achieve – and then dynamically generating the complex sequence of motor actions required to realize that goal in a physically plausible manner. Such an approach promises a future where robots respond to language with the same fluidity and adaptability as humans, moving beyond pre-programmed routines to engage with the world in a truly intelligent and responsive way.
Successfully translating textual commands into realistic humanoid motion necessitates a system that moves beyond simple keyword recognition and delves into the underlying intent of the instruction. Such a system doesn’t merely parse words; it infers the desired outcome, anticipating the necessary physical actions and their sequential coordination. This requires advanced algorithms capable of semantic understanding, allowing the robot to interpret ambiguous phrasing and contextual cues – for example, distinguishing between “walk towards the table quickly” and “approach the table cautiously.” The resulting movements aren’t pre-programmed responses, but dynamically generated actions, precisely calibrated to achieve the intended goal while maintaining physical stability and natural fluidity. Ultimately, the ability to decode intent unlocks a new level of responsiveness and adaptability in humanoid robots, allowing them to seamlessly integrate into human environments and perform complex tasks with intuitive grace.
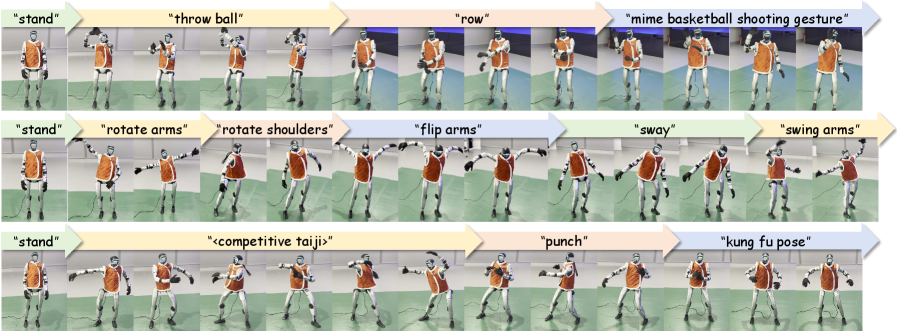
![The robot demonstrates continuous and diverse skill execution, seamlessly performing tasks like dancing, jumping, playing instruments, and expressive gestures, with complex motions uniquely labeled using [latex]\langle\cdot\rangle[/latex] markers.](https://arxiv.org/html/2602.07439v1/x3.png)
TextOp: A Framework for Orchestrated Motion
TextOp is a framework engineered for the real-time generation and control of humanoid robot movements directly from textual input. The system translates natural language commands into actionable robot behaviors, enabling users to direct robot actions without requiring specialized robotics expertise or pre-programmed motion libraries. This is achieved through an integrated pipeline that processes text, generates corresponding motion sequences, and then efficiently translates those sequences into control signals for the robot’s actuators. The framework’s design prioritizes low-latency performance, allowing for responsive and interactive control in dynamic environments, and is intended for applications requiring immediate execution of commands, such as teleoperation or interactive task execution.
Interactive Motion Generation within TextOp functions as the initial stage in translating natural language commands into robotic action. This process involves synthesizing a preliminary motion sequence – a reference trajectory – directly from the input text. Unlike direct motor control, this generated sequence provides a high-level plan for the robot to follow, defining the desired movement without specifying precise joint angles or velocities. This reference motion serves as the foundation for subsequent control layers, enabling the system to interpret complex textual instructions – such as “walk to the table and pick up the glass” – and translate them into a feasible and coordinated series of actions for a humanoid robot.
The Autoregressive Motion Diffusion Model within TextOp generates humanoid movements by iteratively refining a sequence of poses. This process begins with random noise and, through multiple steps, progressively denoises the data, conditioned on the textual command. The model is autoregressive, meaning it predicts each subsequent pose based on the previously generated poses in the sequence, ensuring temporal coherence. Diffusion models are utilized for their capacity to generate diverse and plausible motions, surpassing limitations of traditional generative approaches. By learning the distribution of human movements, the model can synthesize novel, physically realistic sequences that respond to the given textual input.
TextOp utilizes a ‘Robot-Skeleton Motion Representation’ designed to maximize control efficiency in humanoid robots. This representation encodes motion data as a series of 3D joint angles and positions relative to a skeletal structure, rather than relying on full body pose data or complex kinematic calculations during runtime. This approach significantly reduces computational demands, allowing for real-time control even on platforms with limited processing power. Furthermore, the representation is optimized for direct mapping to robot actuators, minimizing latency and enabling precise and responsive movement execution. The system represents motion as a sequence of these skeletal configurations, facilitating efficient storage, transmission, and manipulation of movement data.

The Illusion of Fluidity: Modeling Motion with Diffusion
The Autoregressive Motion Diffusion Model leverages a Transformer Architecture to capture temporal dependencies within motion data sequences. Transformers, originally developed for natural language processing, excel at processing sequential data by employing self-attention mechanisms which allow the model to weigh the importance of different parts of the input sequence when predicting future states. In the context of motion data, this means the model considers the relationships between past and present poses to accurately forecast subsequent movements. This approach differs from recurrent neural networks (RNNs) by enabling parallel processing of the entire sequence, improving training efficiency and allowing the model to capture long-range dependencies more effectively. The Transformer’s attention mechanism calculates a weighted sum of all previous states to determine the current state, represented mathematically as [latex]Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V[/latex], where Q, K, and V are query, key, and value matrices, and [latex]d_k[/latex] is the dimension of the key vectors.
A Latent Diffusion Model (LDM) enhances motion generation efficiency by operating within a compressed latent space created by a Variational Autoencoder (VAE). The VAE first encodes high-dimensional motion data into a lower-dimensional latent representation, reducing computational demands. The LDM then performs the diffusion process – iteratively adding and removing noise to generate new motion sequences – within this latent space. Finally, the VAE’s decoder reconstructs the generated latent representation back into a full motion sequence. This approach significantly reduces memory usage and processing time compared to performing diffusion directly on the raw motion data, enabling the generation of more complex and lengthy animations.
The model utilizes OpenAI’s CLIP (Contrastive Language-Image Pre-training) to translate natural language commands into a numerical vector representation. This process, known as text embedding, creates a high-dimensional vector that captures the semantic meaning of the input text. The resulting vector is then incorporated into the motion generation process, serving as a conditioning signal that guides the model to produce movements aligned with the specified textual description. CLIP was pre-trained on a massive dataset of image-text pairs, enabling it to effectively map language to visual concepts, and consequently, to the desired characteristics of the generated motion.
The model achieves motion generation by integrating textual and kinematic conditioning. Specifically, language prompts are encoded via CLIP into a vector space that modulates the diffusion process within the Latent Diffusion Model. Simultaneously, the model incorporates preceding motion sequences as input, effectively using previous movements to inform and constrain the generation of subsequent frames. This dual conditioning-on both language and prior kinematic data-enables the creation of motions that are both semantically aligned with the text prompt and temporally coherent with the established movement history, resulting in diverse and realistic outputs.
![Time-aligned data integrates text labels with synchronized [latex]SMPL[/latex] human motions and corresponding robot actions for coordinated control.](https://arxiv.org/html/2602.07439v1/x2.png)
From Simulation to Reality: Bridging the Physical Divide
Dynamic Motion Tracking constitutes the foundational control layer within the robotic system, directly translating planned motion sequences into physical actions. This component receives reference trajectories – specifying desired positions, velocities, and accelerations for each joint – and implements the necessary control signals to drive the robot’s actuators. It operates at a low level, managing the real-time feedback loops and compensating for disturbances to ensure accurate tracking of the intended motion. The system utilizes actuator commands, continuously adjusted based on sensor data, to minimize the error between the desired trajectory and the robot’s actual pose, effectively bridging the gap between motion planning and physical execution.
The robot’s ability to generalize to diverse movements is achieved through a ‘Universal Motion Tracker’ policy implemented using Reinforcement Learning. This policy is trained with the Proximal Policy Optimization (PPO) algorithm, an on-policy method that iteratively improves the policy by maximizing a surrogate objective function. PPO facilitates stable learning by limiting the policy update step to prevent drastic changes that could destabilize the tracking process. The resulting policy allows the robot to adapt its control strategies to unseen motions, effectively transferring learned behaviors to novel scenarios without requiring explicit reprogramming for each new movement.
Whole-Body Control (WBC) is implemented within the dynamic motion tracking system to manage the coordination of all robotic joints during movement execution. This approach calculates the necessary torques at each joint to achieve desired motions while simultaneously maintaining overall balance and stability. By considering the robot’s full kinematic and dynamic model, WBC enables precise control of both position and orientation, allowing the robot to respond effectively to external disturbances and adapt to varying payloads. The system optimizes joint trajectories to minimize energy expenditure and ensure smooth, coordinated movement across the entire body, resulting in improved responsiveness and robustness in dynamic scenarios.
The dynamic motion tracking system facilitates the transfer of robotic movements developed in simulation to physical robot execution by addressing discrepancies between the virtual and real environments. These differences, stemming from factors like sensor noise, actuator limitations, and unmodeled dynamics, are mitigated through the Universal Motion Tracker policy. This policy, trained via reinforcement learning, allows the robot to adapt its control actions in real-time based on sensory feedback, effectively closing the loop between the planned trajectory and the actual robot behavior. Consequently, motions successfully validated in simulation can be reliably reproduced on the physical robot, reducing the need for extensive real-world tuning and accelerating the development cycle.
Towards Seamless Interaction and Anticipatory Adaptability
Recent advancements in robotic control have yielded TextOp, a framework representing a substantial leap towards robots capable of interpreting and executing natural language instructions with minimal delay. Through a combination of large language models and robotic control algorithms, TextOp successfully translates human commands into physical actions in real-time, as demonstrated by a high success rate in practical robotic experiments. This isn’t simply about recognizing keywords; the system understands nuanced phrasing and context, allowing for more intuitive interaction. The architecture facilitates a direct mapping from language to robot behavior, bypassing the need for complex intermediate programming, and opening possibilities for broader applications where robots can readily assist humans in dynamic and unstructured environments.
The system’s adaptability is significantly bolstered by the implementation of Geometric Mapping with Representations, or GMR. This innovative technique bridges the gap between generalized motion plans and the specific kinematic constraints of a robot’s unique skeletal structure. Rather than requiring pre-programmed motions for each robot model, GMR effectively translates standardized movement directives into a form directly executable by the robot’s joints. This translation process isn’t merely a geometric transformation; it intelligently accounts for varying limb lengths, joint limitations, and body proportions. Consequently, the framework achieves a remarkable degree of hardware independence, allowing it to readily deploy on diverse robotic platforms without extensive re-engineering or recalibration. The benefit is a substantial reduction in development time and cost, alongside the enhanced potential for wider robot deployment in dynamically changing environments.
The developed framework fosters remarkably natural human-robot interaction, moving beyond pre-programmed sequences to enable collaborative assistance across diverse tasks. This is achieved through a system designed for responsive communication; user commands are processed with an average latency of only 0.73 seconds, effectively minimizing the delay between instruction and robotic action. This near real-time responsiveness is crucial for establishing a sense of seamless cooperation, allowing individuals to intuitively guide robots through complex procedures as if working alongside a human colleague. Consequently, the system’s adaptability broadens the scope of potential applications, promising robotic support in fields ranging from manufacturing and logistics to personal assistance and healthcare.
Continued development of this robotic framework prioritizes enhanced resilience in unpredictable environments, moving beyond controlled laboratory settings. Researchers aim to significantly broaden the system’s linguistic capabilities, enabling it to interpret a more diverse range of commands and nuanced phrasing. Crucially, future iterations will incorporate learning from demonstration, allowing the robot to acquire new skills simply by observing human performance – a shift that promises to dramatically accelerate task adaptation and foster more natural, collaborative interactions. This approach anticipates a future where robots can seamlessly integrate into everyday life, responding intelligently to complex requests and evolving alongside human partners.
The pursuit of responsive, adaptable robotic systems, as demonstrated by TextOp, inevitably courts increasing systemic complexity. The framework’s reliance on continuous adaptation via natural language suggests a shift from pre-programmed behaviors to emergent ones. This echoes a fundamental truth about interconnected systems: they do not simply respond to stimuli, they evolve within them. As Carl Friedrich Gauss observed, “If other sciences or branches of knowledge offer no further assistance, it will always be possible to determine the unknown by means of observation.” TextOp, in essence, operationalizes this principle, leveraging real-time interaction to observe and refine robotic movement – accepting that complete control is an illusion, and adaptation the only constant.
What Lies Ahead?
TextOp, and systems like it, do not solve the problem of control. They merely displace it. The seeming responsiveness to natural language is not mastery, but a shifting of complexity. Long stability in such a system will not indicate success, but mask a brittle dependence on a narrow distribution of prompts. The true test will come not with the expected commands, but with the elegantly phrased failures – the requests that expose the system’s unarticulated assumptions.
The pursuit of ‘real-time’ interaction is itself a curious objective. The illusion of immediacy often obscures a pre-computed landscape of possibilities. Future work will inevitably focus on closing the loop – not with faster processing, but with a more honest accounting of uncertainty. The robot will not ‘understand’ intent, but probabilistically map language onto a space of plausible actions, forever hedging its bets.
This is not a path toward intelligent machines, but toward increasingly sophisticated mirrors. The system will not do as instructed, but reflect the structure of the instruction itself. The eventual form of such a system is not a tool, but an echo – a complex resonance between human expression and mechanical possibility. It will not fail spectacularly, but fade into a comfortable, predictable mediocrity.
Original article: https://arxiv.org/pdf/2602.07439.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Magicmon: World redeem codes and how to use them (March 2026)
- Gold Rate Forecast
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- Seeing in the Dark: Event Cameras Guide Robots Through Low-Light Spaces
- Mobile Legends Advanced ServerPatch 2.1.66 Update: Hero Adjustments, Battlefield Changes and more
2026-02-11 06:14