Author: Denis Avetisyan
Researchers are exploring how modeling the internal monologue humans use to guide actions can dramatically improve the realism, diversity, and controllability of artificial intelligence agents.
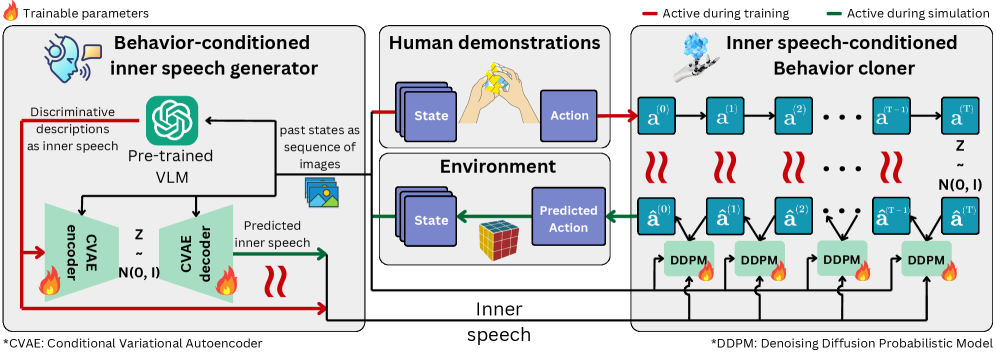
A new imitation learning framework, MIMIC, utilizes diffusion models to steer AI behavior based on learned representations of ‘inner speech’ for enhanced human-AI coordination.
Current imitation learning methods struggle to capture the nuance and adaptability inherent in human behavior, limiting their effectiveness in complex human-AI coordination scenarios. Addressing this, our work, ‘Inner Speech as Behavior Guides: Steerable Imitation of Diverse Behaviors for Human-AI coordination’, introduces MIMIC, a novel framework inspired by cognitive science that leverages ‘inner speech’ – an internal representation of intent – to guide artificial agent actions. By employing vision-language models and diffusion-based policies, MIMIC generates diverse and controllable behaviors, allowing for fine-grained steering without requiring additional training data. Could this approach unlock more natural and intuitive forms of collaboration between humans and artificial intelligence?
Breaking the Imitation Barrier: The Fragility of Learned Behavior
Conventional imitation learning, while effective at replicating demonstrated behaviors, frequently exhibits a surprising fragility when confronted with novel circumstances. These systems excel at mirroring the training data, but often falter when faced with even slight deviations from the observed scenarios – a phenomenon known as brittle behavior. This limitation stems from the tendency to prioritize surface-level correlations rather than developing a deeper understanding of the underlying principles governing successful action. Consequently, an agent trained solely through imitation may struggle to adapt its responses to unexpected obstacles, altered environments, or previously unseen states, highlighting the need for approaches that foster genuine generalization beyond simple mimicry.
The pursuit of truly intelligent agents demands a shift from mere imitation to the acquisition of fundamental principles governing behavior. Rather than simply replicating observed actions, advanced systems must learn the why behind those actions, enabling them to generalize effectively to novel scenarios. This necessitates the development of algorithms capable of inferring underlying causal relationships and abstracting away from superficial details; a system that understands, for example, the principle of balance can adapt to a variety of terrains, while one solely trained on examples might falter with even minor deviations. Such principle-based learning fosters robustness, allowing agents to not only reproduce demonstrated skills but also to creatively apply them, and even innovate, in response to unforeseen challenges – ultimately bridging the gap between brittle mimicry and genuine adaptability.
Many contemporary approaches to artificial intelligence struggle with real-world complexity because they treat observations as definitive inputs, failing to recognize the pervasive ambiguity inherent in sensory data. This limitation hinders an agent’s ability to reliably act in novel situations; a single observation rarely provides a complete or unambiguous picture of the environment. Consequently, successful navigation of unpredictable circumstances demands more than simply reacting to what appears to be present. Instead, intelligent systems require internal deliberation – a capacity to weigh multiple interpretations of incomplete data, consider potential outcomes, and formulate plans based on probabilistic reasoning. This process, mirroring human cognitive function, involves constructing internal models of the world, generating hypothetical scenarios, and selecting actions that maximize expected reward, even in the face of uncertainty and imperfect information.
![Unlike behaviorist inverse reinforcement learning which maps states directly to actions [latex]s_t \mapsto a_t[/latex], the MIMIC cognitive framework incorporates an internal linguistic layer [latex]s_t \rightarrow m_t \rightarrow a_t[/latex] to enable more diverse and contextually-aware behavior through internal deliberation.](https://arxiv.org/html/2602.20517v1/figs/cognitive.png)
Injecting Inner Monologue: The MIMIC Framework
MIMIC addresses limitations in traditional imitation learning by incorporating an internal monologue, termed ‘inner speech’, into the agent’s decision-making process. This framework moves beyond simply replicating demonstrated behaviors by enabling the agent to generate textual reasoning about its intended actions. The generated text serves as an internal representation of the agent’s planned behavior, allowing for a more nuanced understanding of the demonstrated policy and facilitating exploration of alternative, potentially more effective, strategies. Essentially, MIMIC allows the agent to ‘think’ about what it is doing, bridging the gap between observed actions and the underlying rationale, and improving generalization capabilities beyond the training data.
The incorporation of an internal representation, functionally analogous to inner monologue, enables agents to perform iterative reasoning about potential actions prior to execution. This process facilitates the evaluation of multiple behavioral options beyond the initially predicted action, leading to increased exploration of the action space. Consequently, agents demonstrate a wider range of successful strategies for completing tasks, effectively increasing behavioral diversity and improving robustness to varying environmental conditions. The agent isn’t limited to a single, deterministic response, but can internally simulate and compare different courses of action before committing to one.
The MIMIC framework employs a Transformer architecture to integrate policy learning and inner speech modeling into a single, cohesive system. This implementation utilizes a shared Transformer network where both the agent’s policy – defining action selection – and the internal monologue are modeled as sequential outputs. Specifically, the Transformer receives environmental observations as input and generates both action tokens, representing the chosen behavior, and speech tokens, composing the inner monologue. This unified approach allows for bidirectional influence; the inner speech can inform action selection, and anticipated consequences of actions can be reflected in the generated monologue, creating a closed-loop reasoning process within the agent’s decision-making pipeline. The Transformer’s attention mechanism facilitates the modeling of dependencies between observations, actions, and the internal speech representation.
Conditioning Action Through Internal Dialogue
Inner Speech Conditioning allows an agent to utilize an internal monologue – a sequence of tokens representing a thought process – as a basis for action selection. This is achieved by training the agent to map these internal speech representations to appropriate actions within its environment. Specifically, the agent learns to interpret the semantic content of its “thoughts” and translate that interpretation into a corresponding motor command or behavioral output. This conditioning process effectively creates a learned relationship between the agent’s internal cognitive state, expressed through its inner speech, and the external actions it performs, enabling goal-directed behavior driven by internal reasoning rather than solely by external stimuli.
MIMIC utilizes Diffusion Models to enhance policy learning by addressing limitations in traditional reinforcement learning exploration strategies. These models operate by progressively adding noise to data, then learning to reverse this process to generate new samples; in this context, they generate diverse action sequences. This approach enables the agent to explore a significantly broader State Space and Action Space than methods relying on greedy or epsilon-greedy policies. The diffusion process facilitates the discovery of robust policies by allowing the agent to sample from a distribution of potential actions, rather than being constrained by immediate rewards or limited exploration horizons. This is achieved by training the diffusion model to condition action generation on the agent’s internal state and, crucially, on the associated inner speech representation, promoting both diversity and controllability in learned behaviors.
The agent’s capacity to learn a distribution over actions, conditioned on inner speech, facilitates the generation of varied behavioral responses to a given state. This is achieved by modeling the probability of different actions given the internal monologue, rather than selecting a single, deterministic action. By sampling from this distribution, the agent can produce diverse behaviors while maintaining alignment with the expressed intention within its inner speech. Furthermore, manipulating the inner speech input allows for direct control over the agent’s resulting actions, enabling targeted behavioral modification and the exploration of alternative responses without retraining the core policy. This probabilistic approach enhances adaptability and allows the agent to navigate complex environments with greater flexibility.

Validating Intelligence in Collaborative Chaos
MIMIC’s capabilities were stringently tested within the complex dynamics of the Overcooked environment, a widely recognized benchmark for assessing multi-agent coordination skills. This virtual kitchen presents significant challenges, demanding agents to effectively communicate, share resources, and synchronize actions to successfully fulfill recipe orders. The environment’s inherent complexity, characterized by limited workspaces and time pressure, forces agents to learn not just individual tasks, but also how to cooperate seamlessly – a crucial test for any artificial intelligence aiming for robust collaborative behavior. Utilizing Overcooked allowed for a quantifiable evaluation of MIMIC’s ability to navigate these challenges and demonstrate adaptable teamwork strategies, providing a rigorous foundation for assessing its performance against simpler imitation learning approaches.
Evaluations reveal that MIMIC consistently surpasses traditional imitation learning techniques, demonstrating a marked improvement in both the reliability and flexibility of learned behaviors. On the challenging ‘Aligning’ dataset, MIMIC achieved a success rate of 57.16%, a substantial 16.47% higher than the baseline Behavior Cloning (BC) method. This performance advantage extends to the ‘Sorting’ dataset, where MIMIC secured a success rate of 78.5%, exceeding BC by a significant 7%. These results indicate that MIMIC not only replicates observed actions, but also generalizes effectively to novel situations within the collaborative environment, resulting in more dependable and adaptable multi-agent coordination.
Evaluations within the demanding Overcooked – Cramped Room environment reveal that MIMIC achieves a collective reward of 94.72%, demonstrably exceeding the performance of baseline imitation learning techniques. This success isn’t simply about achieving a higher score; MIMIC’s behavior closely mirrors the ‘gold standard’ demonstrated by expert agents, as evidenced by a small Wasserstein Distance. This metric quantifies the dissimilarity between MIMIC’s actions and those of the expert, with a lower distance indicating greater fidelity in behavior reproduction – suggesting MIMIC doesn’t just achieve results, but does so in a manner consistent with optimal strategies, fostering more robust and adaptable collaborative performance.
The pursuit of increasingly realistic AI agents, as demonstrated by MIMIC, isn’t simply about flawless reproduction of observed behaviors. It’s about probing the boundaries of those behaviors, understanding the underlying ‘rules’ that govern them. This resonates with David Hilbert’s assertion: “We must be able to answer the question: what are the ultimate foundations of mathematics?” Similarly, this research doesn’t just clone actions; it investigates the cognitive ‘inner speech’ process, the internal modeling that allows for variation and control. The framework intentionally introduces a degree of ‘noise’ – a controlled disruption – to reveal the latent structure of behavior, much like a systems engineer deliberately stresses a design to uncover hidden vulnerabilities. The goal isn’t perfection, but a deeper comprehension of the generative principles at play.
Deconstructing the Dialogue
The pursuit of believable agency often stalls on the shoals of predictability. This work, by introducing an internal, speech-like bottleneck into the imitation process, doesn’t so much solve that problem as expose its underlying structure. The framework elegantly demonstrates that diversity isn’t simply a matter of injecting randomness, but of modulating the internal representation-the ‘thought’-that mediates between stimulus and response. One naturally asks: how robust is this ‘inner voice’ to adversarial perturbation? Could a carefully crafted, subtle distortion of the internal representation yield disproportionately large behavioral changes, effectively ‘hijacking’ the agent’s actions?
The current formulation treats inner speech as a latent space, a convenient conduit for control. The next step isn’t necessarily to refine the diffusion models themselves, but to interrogate the content of that internal monologue. Can the system learn to articulate its intentions, even in rudimentary terms? Could this internal ‘self-talk’ be leveraged for planning, counterfactual reasoning, or even the detection of anomalous situations? The true test will lie in pushing beyond mere imitation and toward genuinely adaptive, autonomous behavior.
Ultimately, this research isn’t about building better AI; it’s about reverse-engineering intelligence. By deconstructing the cognitive loop, the framework invites a more fundamental question: what is the minimal scaffolding required for a system to appear intentional, and can that illusion be sufficient for meaningful human-AI collaboration? The answers, undoubtedly, will be uncomfortable.
Original article: https://arxiv.org/pdf/2602.20517.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Limbus Company 2026 Roadmap Revealed
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- Total Football free codes and how to redeem them (March 2026)
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
2026-02-25 18:48