Author: Denis Avetisyan
Researchers have developed a powerful new model capable of generating, editing, and understanding complex audio narratives with unprecedented control and nuance.

AudioChat unifies audio storytelling, editing, and understanding through a multi-modal foundation model leveraging large language models, diffusion techniques, and chain-of-thought reasoning.
Despite recent advances in audio processing, existing foundation models struggle with the semantic and temporal complexities of multi-source acoustic scenes-what we term audio stories. This paper introduces AudioChat: Unified Audio Storytelling, Editing, and Understanding with Transfusion Forcing, a novel framework leveraging large language models and diffusion models to generate, edit, and understand these complex audio narratives. AudioChat employs a unique training paradigm using LLM-based toolcalling agents and an [latex]Audio Transfusion Forcing[/latex] objective, enabling structured reasoning and interactive audio processing. Could this approach unlock truly intelligent systems capable of authoring and manipulating rich auditory experiences?
Beyond Sound: Embracing Holistic Audio Understanding
Historically, audio processing has largely focused on dissecting sound into its component parts – identifying individual instruments in a song, or separating speech from background noise. This granular approach, while useful for specific tasks, often overlooks the crucial contextual information embedded within a complete audio narrative. The holistic experience of sound – the subtle interplay of ambiance, the emotional weight carried by intonation, and the relationships between different sound events – is lost when audio is treated as a collection of isolated elements. Consequently, current systems struggle to truly understand an audio story, instead merely recognizing what sounds are present, rather than how those sounds contribute to a cohesive and meaningful experience. This limitation hinders the development of truly intelligent audio systems capable of sophisticated analysis, creative generation, and seamless editing of complete audio works.
Current audio processing technologies frequently falter when confronted with the intricacies of real-world soundscapes. Existing methods, often trained on isolated sounds or simple scenarios, struggle to disentangle and interpret the interplay of multiple interacting sound sources – a bustling street scene, a lively conversation in a café, or a dramatic film score. This difficulty extends to understanding nuanced narratives embedded within audio, where subtle changes in tone, pacing, and sound effects contribute to meaning. The inability to accurately model these complexities limits the potential for applications requiring a comprehensive grasp of auditory information, hindering advancements in areas like automated audio description, realistic sound synthesis, and intelligent audio editing tools.
Current audio processing technology typically dissects sound into isolated components – speech, music, effects – hindering a comprehensive grasp of the complete auditory experience. However, a truly versatile system necessitates a unified model capable of seamlessly transitioning between understanding, generating, and editing entire audio narratives. This holistic approach moves beyond simple transcription or source separation; it envisions an artificial intelligence that can not only interpret the meaning within a soundscape, but also realistically recreate or modify it, offering possibilities like automated audio restoration, intelligent sound design, and personalized audio experiences tailored to individual preferences. Such a model would effectively treat audio not as a collection of discrete events, but as a continuous, interconnected story, unlocking a new era of creative and analytical potential for audio technology.
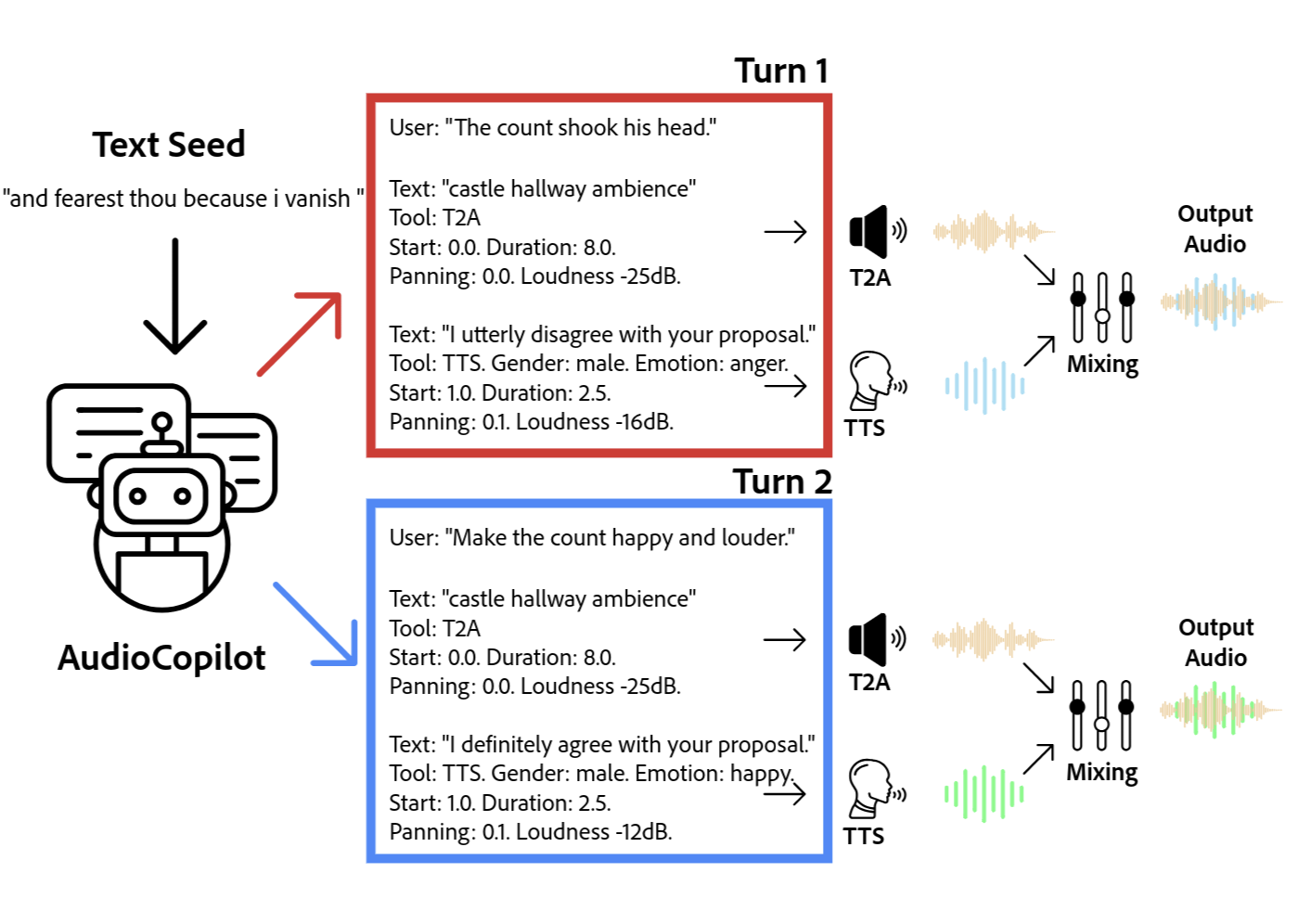
Introducing AudioChat: A Foundation for Narrative Sound
AudioChat is a multi-modal artificial intelligence model designed for the creation and manipulation of complete audio narratives. It accepts multiple input modalities – including text prompts, audio recordings, and structural cues – and processes them to generate new audio content, modify existing recordings, or interpret the semantic content of audio stories. This functionality extends beyond simple speech synthesis or audio editing; AudioChat aims to understand the narrative structure and contextual elements within audio, enabling it to perform tasks such as character development, scene setting, and plot progression through audio means. The model’s capabilities encompass both the generation of entirely new audio stories and the editing of existing ones, including alterations to pacing, mood, and character voice.
The Self-Cascaded Transformer is a core architectural element enabling AudioChat’s audio processing capabilities. This transformer-based model operates by sequentially analyzing audio data in multiple stages, allowing it to build a hierarchical understanding of the content. Each cascade layer receives the output of the previous layer as input, refining the audio representation and capturing increasingly complex relationships within the waveform. This sequential processing facilitates the model’s ability to understand not only the immediate acoustic features, but also the temporal dependencies and broader context of the audio story, resulting in a more complete and nuanced comprehension of the input.
The AudioChat system employs a Continuous Audio Tokenizer (CAT) to transform raw audio waveforms into a discrete sequence of tokens suitable for deep learning models. Unlike traditional methods that rely on fixed-length frame-based processing, CAT utilizes a learned codebook to represent audio segments as a series of tokens, effectively compressing the audio data while retaining crucial information. This approach allows the model to process audio of varying lengths without requiring padding or truncation, and facilitates efficient processing by reducing the dimensionality of the input data. The resulting token sequence serves as the primary input to the subsequent deep learning components, enabling the system to understand and manipulate audio content.
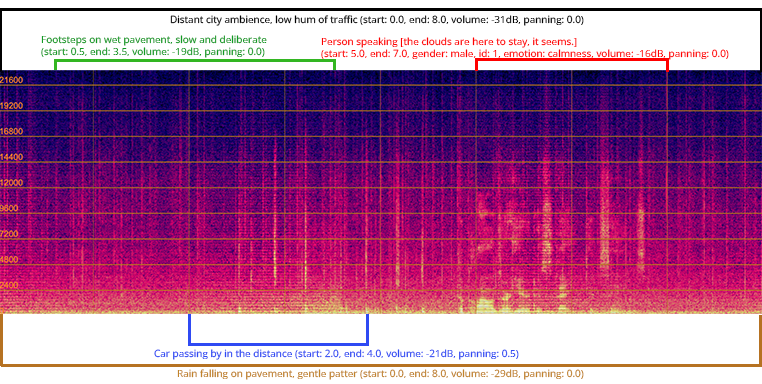
Audio Transfusion Forcing: Refinement Through Synthesis
Audio Transfusion Forcing improves audio generation by integrating a Large Language Model (LLM) with a Diffusion Model. The LLM is utilized to generate a high-level semantic representation of the desired audio, effectively acting as a conditioning signal. This signal then guides the Diffusion Model, which is responsible for synthesizing the actual audio waveform. By leveraging the LLM’s understanding of context and relationships, the Diffusion Model can produce audio with increased coherence and fidelity compared to models operating without such semantic guidance. This two-stage process allows for a decoupling of content planning from audio synthesis, resulting in enhanced control and quality of the generated audio output.
Structured Chain-of-Thought Reasoning facilitates complex audio task completion by decomposing the overall objective into a series of discrete, logically ordered sub-tasks. This approach allows the system to address each component individually, increasing the probability of accurate and coherent processing at each stage. Rather than attempting to generate complete audio directly, the method first plans the narrative or sonic structure, then generates individual audio segments based on that plan, and finally assembles these segments into a cohesive output. This modularity simplifies the generation process and improves the quality of the resulting audio by reducing the complexity of each individual operation.
Combining Large Language Models (LLMs) and Diffusion Models with Structured Chain-of-Thought Reasoning significantly improves audio story generation by addressing limitations in both individual approaches. LLMs provide the narrative structure and contextual understanding, while Diffusion Models excel at generating high-fidelity audio. However, directly prompting Diffusion Models with complex narrative descriptions often yields inconsistent results. Structured Chain-of-Thought Reasoning bridges this gap by decomposing the story generation task into a series of logical steps – for example, character development, scene setting, and action sequencing – which are then used to guide the Diffusion Model. This staged approach ensures greater coherence between narrative elements and the generated audio, resulting in more realistic and engaging audio stories compared to methods relying on single-model generation or unstructured prompting.
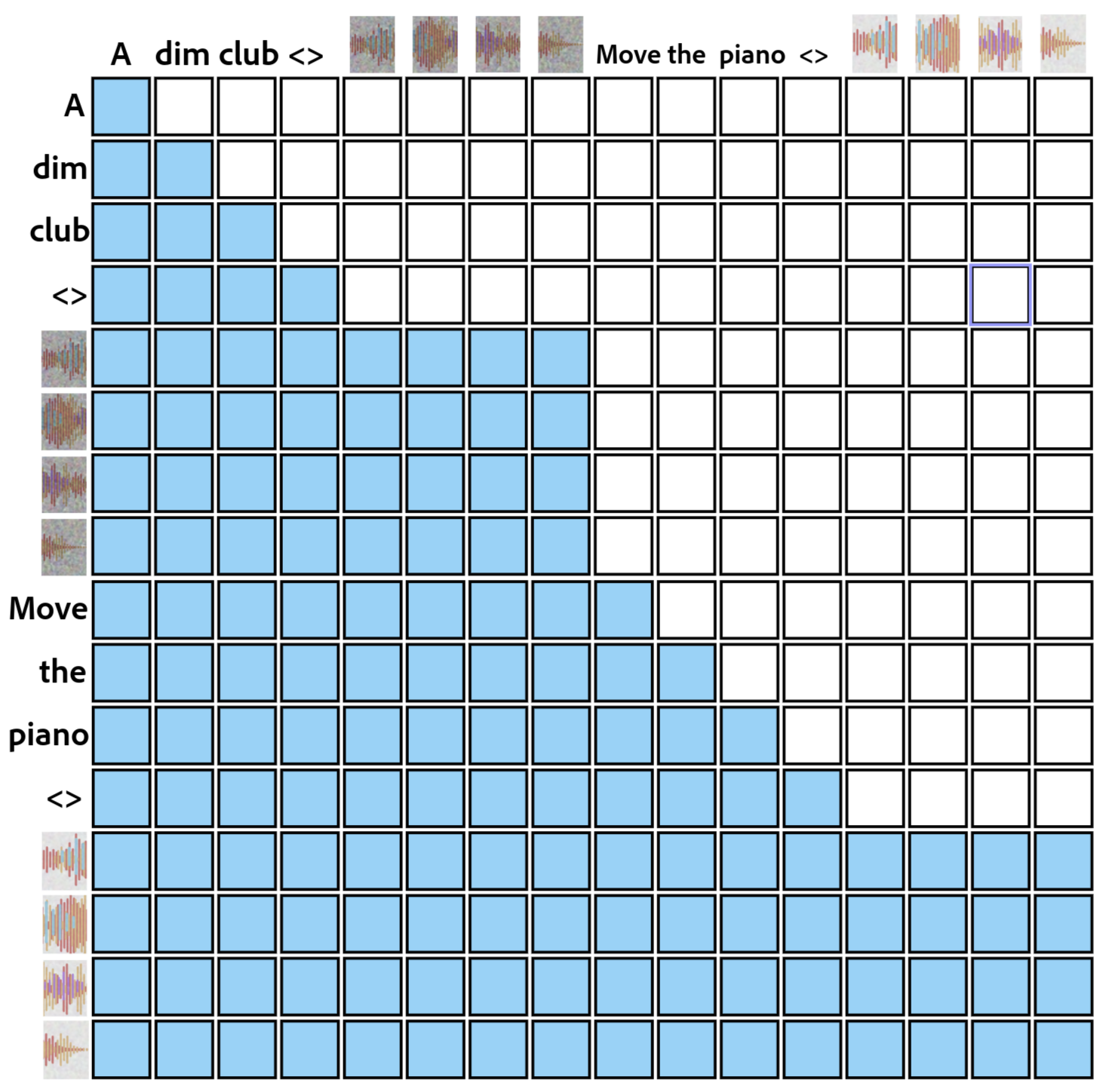
Quantifying Sonic Fidelity: Metrics for Meaning
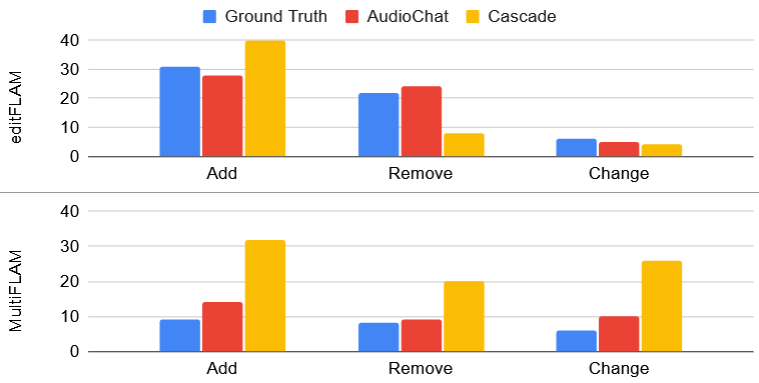
Recent advancements in audio generation necessitate robust methods for evaluating the semantic fidelity of synthesized content. MultiFLAM addresses this challenge by quantifying how well generated audio aligns with the intended sound elements, effectively measuring semantic consistency. Through rigorous testing, MultiFLAM achieved a score of 0.88, indicating a high degree of alignment between the generated audio and the desired semantic content. This performance is notably comparable to that of Whisper-Story, which attained a score of 0.86 using the same metric, suggesting MultiFLAM provides a reliable and competitive assessment of audio generation quality and its capacity to accurately convey intended meaning through sound.
DeltaMultiFLAM offers a rigorous quantitative approach to evaluating the fidelity of audio editing processes. This metric doesn’t simply assess whether changes were made, but critically, whether those changes introduced unintended distortions or inconsistencies relative to the original audio. By comparing the edited output to its source material, DeltaMultiFLAM generates a score reflecting the preservation of sonic integrity. A high score indicates minimal deviation and a faithful edit, while a lower score signals potential artifacts or a departure from the original sound characteristics. This is particularly valuable in applications like audio restoration, noise reduction, or content modification, where maintaining the inherent quality of the audio is paramount and subjective listening tests are insufficient for precise evaluation.
EditFLAM represents a novel approach to objectively evaluating the efficacy of audio editing tasks. This metric doesn’t simply assess perceptual quality; instead, it directly verifies whether the implemented edits align with the given instructions. By analyzing the modified audio against the original and the specified editing parameters, EditFLAM quantifies the degree to which the operation was successfully completed. This is achieved through a focused assessment of semantic content and structural changes, providing a score that reflects instruction-following accuracy. The development of EditFLAM offers a crucial benchmark for evaluating and improving audio editing algorithms, enabling developers to refine systems for precise and reliable manipulation of sound.
Recent evaluations demonstrate a substantial advancement in audio story comprehension with the development of AudioChat. This system achieves a remarkably low token classification error rate (tcpWER) of 9.7, a figure that significantly surpasses the 55.9 recorded by the widely-used WhisperX. This dramatic improvement indicates AudioChat’s enhanced ability to accurately transcribe and interpret the narrative structure within spoken audio, suggesting a considerable leap forward in technologies reliant on understanding complex auditory information and offering potential benefits for applications ranging from automated storytelling to improved voice assistants.
Scaling Creativity: Towards Intelligent Audio Tools
AudioCopilot represents a significant advancement in audio storytelling through its capacity for scalable data synthesis, fundamentally altering the production workflow. Leveraging the power of AudioChat, the system automates much of the traditionally laborious process of crafting audio narratives. Instead of relying on extensive manual recording, editing, and sound design, creators can now generate a substantial amount of audio content programmatically. This isn’t simply about speed; it’s about accessibility and iteration. By drastically reducing manual effort, AudioCopilot empowers storytellers to explore a wider range of creative possibilities, experiment with different sonic landscapes, and ultimately, bring more immersive audio experiences to life with greater efficiency.
The system’s versatility extends beyond simple audio generation through its dual capacity for both text-to-audio and text-to-speech synthesis. This integrated approach significantly broadens its potential applications; it isn’t limited to creating soundscapes or musical elements, but can also directly vocalize narrative content and dialogue. This capability unlocks possibilities for automated audiobook creation, accessible content generation for visually impaired individuals, and the dynamic production of personalized audio experiences, effectively transforming static text into engaging auditory forms and enabling a wider range of creative projects with reduced manual intervention.
Recent advancements in audio storytelling demonstrate a significant leap in efficiency with the development of AudioChat. Comparative analysis reveals AudioChat to be approximately 20 times faster than WavJourney in completing comparable audio story creation tasks. This acceleration stems from innovations in automated audio synthesis and editing, allowing for rapid prototyping and iteration of narrative content. The increased speed doesn’t compromise quality; instead, it empowers storytellers to explore more creative avenues and refine their work with greater agility, ultimately reducing production timelines and opening possibilities for more dynamic and immersive audio experiences.
The development of this integrated framework signifies a crucial step towards genuinely intelligent audio tools, promising to reshape how creators approach storytelling and immersive experiences. By automating significant portions of the audio production pipeline, the system allows artists to focus less on technical execution and more on the creative core of their work – narrative, character development, and emotional resonance. This isn’t simply about accelerating production; it’s about unlocking new creative possibilities, enabling the rapid prototyping of ideas and facilitating more ambitious, large-scale audio projects. The potential extends beyond traditional audio dramas to encompass interactive narratives, personalized soundscapes, and innovative applications in gaming and virtual reality, ultimately lowering the barrier to entry for aspiring audio creators and amplifying the voices of established artists.
The pursuit of AudioChat reflects a dedication to streamlined communication, mirroring a philosophy that prioritizes clarity over complexity. This model elegantly integrates diverse capabilities – generation, editing, and understanding – into a unified system. It embodies a belief that powerful tools should diminish cognitive load, not amplify it. As Vinton Cerf aptly stated, “The internet is not just about technology; it’s about people.” AudioChat, by simplifying audio storytelling through its chain-of-thought reasoning and multi-modal approach, brings those people closer to a more natural and accessible creative process, removing barriers between intention and expression. The system’s efficiency echoes the sentiment that perfection isn’t about adding features, but about removing unnecessary layers.
Where Do We Go From Here?
The ambition of AudioChat – a unified system for audio narrative – reveals, perhaps more than it resolves, the inherent clutter in multi-modal learning. The system functions, demonstrably, but one suspects the ‘forcing’ in ‘transfusion forcing’ hints at a deeper truth: much of current progress relies on compelling disparate components to cooperate, rather than genuine integration. The next step isn’t simply more parameters, or even more modalities, but ruthless pruning. What redundancies can be exposed and eliminated? What layers of abstraction truly contribute to understanding, and which are merely present to satisfy architectural precedent?
The reliance on chain-of-thought reasoning, while effective, feels like an acknowledgement of the diffusion model’s internal opacity. It’s a workaround, not a solution. Future research must grapple with interpretability. Can these models be made to explain their creative choices, or are they destined to remain black boxes, generating compelling content through inscrutable means? The pursuit of generative capability should not eclipse the need for genuine understanding-of both the model and the art it produces.
Ultimately, the field will be defined not by what can be added to these systems, but by what can be confidently removed. A truly elegant solution will not be the most complex, but the most concise-the one that achieves the same results with the fewest moving parts. The challenge, then, is not to build bigger, but to build better-and better, invariably, means simpler.
Original article: https://arxiv.org/pdf/2602.17097.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Last Furry: Survival redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- eFootball 2026 “Countdown to 1 Billion Downloads” Campaign arrives with new Epics and player packs
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Limbus Company 2026 Roadmap Revealed
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
2026-02-23 04:26