Author: Denis Avetisyan
A new benchmark dataset and simulation environment aims to accelerate the development of more adaptable and reliable mobile robots capable of complex physical tasks.
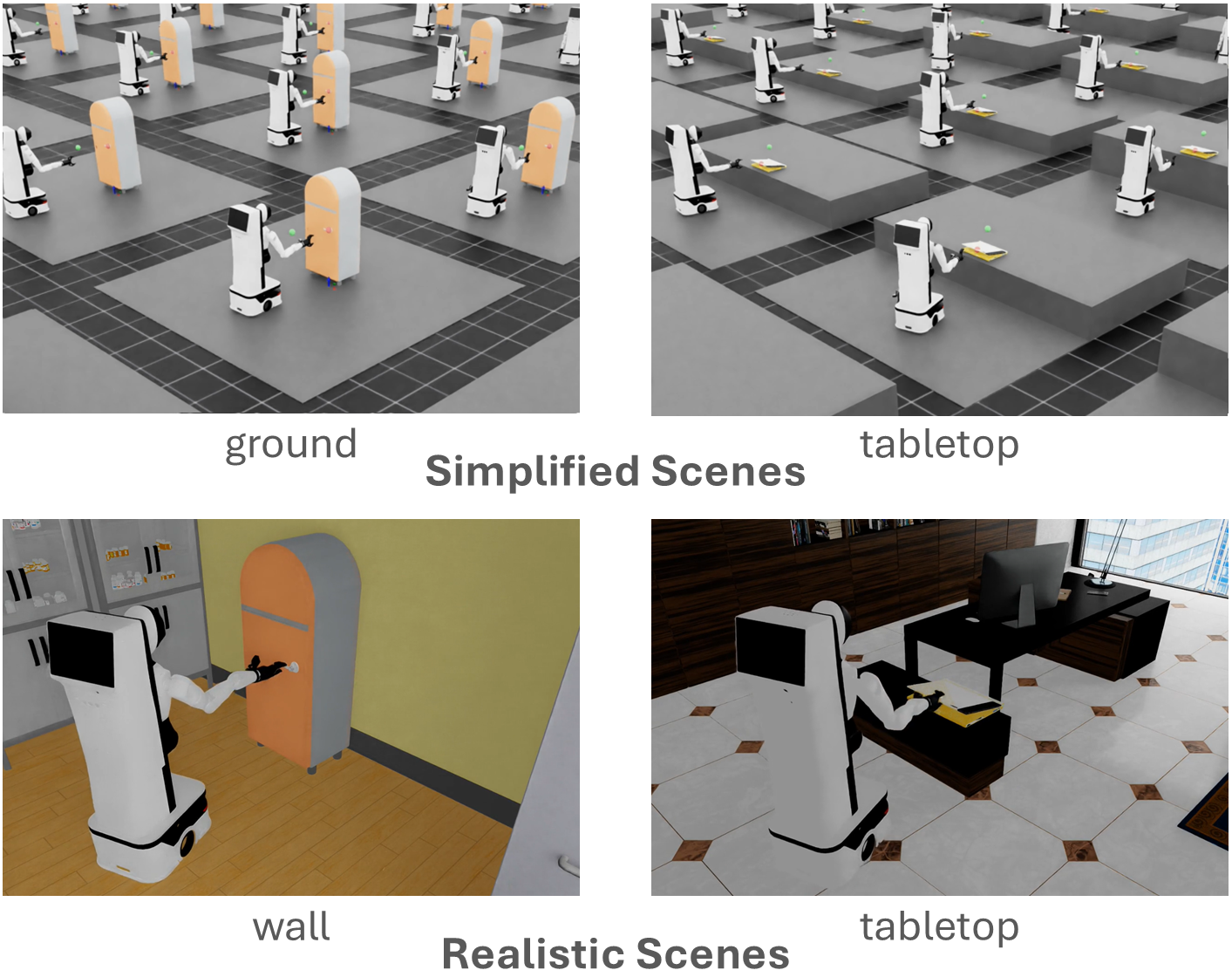
MobileManiBench provides a large-scale platform for training and evaluating vision-language-action models in robotic manipulation, addressing the challenges of simulation-to-real transfer.
Despite advances in vision-language-action models for robotic manipulation, reliance on limited, static datasets hinders real-world deployment. To address this, we introduce MobileManiBench: Simplifying Model Verification for Mobile Manipulation, a large-scale, simulation-driven benchmark built on NVIDIA Isaac Sim and powered by reinforcement learning to generate diverse, annotated manipulation trajectories. This framework yields over 300K trajectories featuring two mobile platforms, 630 objects, and five core manipulation skills, enabling controlled studies of embodiment, sensing, and policy design. Will this scalable platform accelerate the development of more robust and generalizable robotic systems capable of complex, real-world tasks?
The Fragility of Conventional Robotics
Conventional robotic systems frequently operate on a foundation of meticulously pre-programmed instructions, dictating each movement and action in a predictable sequence. While effective in highly structured settings, this approach proves brittle when confronted with the inherent variability of real-world environments. A robot designed to assemble a product on a static conveyor belt may falter if an object is slightly misaligned, obstructed, or unexpectedly altered – scenarios commonplace outside of controlled laboratory conditions. This reliance on fixed sequences limits a robot’s ability to generalize its skills, requiring extensive re-programming for even minor deviations from the expected. Consequently, the pursuit of more adaptable robotic manipulation focuses on enabling systems to perceive their surroundings and dynamically adjust their actions, moving beyond the limitations of rigid, pre-defined routines.
The pursuit of genuinely intelligent robotics hinges on developing systems capable of not just executing commands, but truly understanding them within a complex, dynamic world. Current artificial intelligence methods struggle to bridge the gap between abstract language and concrete action, often faltering when faced with ambiguity or unexpected scenarios. A robot that can interpret natural language requires more than just speech recognition; it demands contextual awareness, the ability to parse intent, and the capacity to build a coherent representation of its surroundings through vision and other sensors. Achieving real-time reaction capabilities adds another layer of complexity, demanding computational efficiency alongside robust perception and reasoning – a significant hurdle for algorithms designed for static datasets rather than unpredictable, real-world interactions.
The pursuit of genuinely intelligent robotics hinges on the seamless convergence of perception, communication, and physical execution. Current artificial intelligence often excels in isolated tasks – identifying objects in images, understanding spoken commands, or controlling individual joints – but struggles when these capabilities must operate in concert. Achieving true integration demands learning approaches that are not merely accurate on training data, but generalizable to novel situations, unforeseen obstacles, and nuanced instructions. Researchers are actively exploring methods like reinforcement learning and large multimodal models to build systems capable of interpreting complex scenes, responding to natural language, and adapting actions in real-time – essentially, equipping robots with the capacity to ‘understand’ the world and interact with it in a flexible, human-like manner. This requires moving beyond specialized algorithms towards holistic systems where vision informs language understanding, which in turn guides purposeful action, creating a virtuous cycle of learning and adaptation.

Bridging Perception, Language, and Action
Vision-Language-Action (VLA) models establish a computational framework enabling robots to receive instructions expressed in natural language and subsequently execute corresponding physical actions. This is achieved by integrating three core modalities: visual perception from cameras or other sensors, natural language processing to decode the instruction’s semantic meaning, and robotic control to translate the interpreted instruction into a sequence of motor commands. The framework necessitates a mapping between linguistic descriptions of desired outcomes and the robot’s physical capabilities, allowing for task specification through human-understandable language rather than low-level programming. Successful implementation requires robust techniques for grounding language in perception and action, ensuring the robot correctly identifies relevant objects and understands the intended manipulation or navigation goals.
Effective action sequence formulation within Vision-Language-Action models necessitates a comprehensive understanding of both the environment and the robot itself. Object states – encompassing attributes like position, size, shape, and material properties of relevant items – provide the context for task execution. Simultaneously, robot states, which include joint angles, end-effector pose, velocity, and internal sensor readings, define the robot’s current configuration and capabilities. The intersection of these two state spaces allows the model to assess feasibility, predict outcomes, and generate actions that are both semantically correct, given the language instruction, and physically realizable by the robot. Accurate state estimation, therefore, is a critical component in ensuring successful task completion.
Vision-Language-Action models utilize state conditioning to incorporate current environmental and robot status into behavioral predictions. This involves feeding representations of both object states – such as position, size, and color – and robot states – including joint angles, velocities, and end-effector pose – as input to the model. Diffusion models are then employed to generate probable action sequences given this conditioned state information; these models operate by progressively refining a random initial action distribution into a coherent plan. The iterative refinement process, characteristic of diffusion models, allows for the generation of diverse and contextually appropriate behaviors, improving robustness and adaptability in complex environments.
MobileManiBench: A Standard for Rigorous Evaluation
MobileManiBench is designed as a standardized evaluation platform for mobile robotic manipulation policies, addressing the need for reproducible and comparable results in the field. The benchmark leverages the NVIDIA Isaac Sim simulation environment, enabling large-scale data generation and training. This simulated environment allows for systematic variation of task parameters and robot configurations, facilitating robust policy evaluation. By providing a consistent testing ground, MobileManiBench aims to accelerate progress in mobile manipulation research by allowing researchers to directly compare the performance of different algorithms and approaches across a defined set of tasks and scenarios.
MobileManiBench is designed to accommodate a range of robotic hardware, specifically supporting both parallel grippers, exemplified by the G1 Robot, and more complex dexterous hands such as the XHand Robot. This multi-platform compatibility enables the evaluation of manipulation policies across different actuator configurations and kinematic designs. The inclusion of both robotic types facilitates comparative analysis of algorithm performance and scalability, and allows researchers to test the transferability of learned policies between robots with varying degrees of freedom and manipulation capabilities. This diversity is critical for developing broadly applicable robotic manipulation systems.
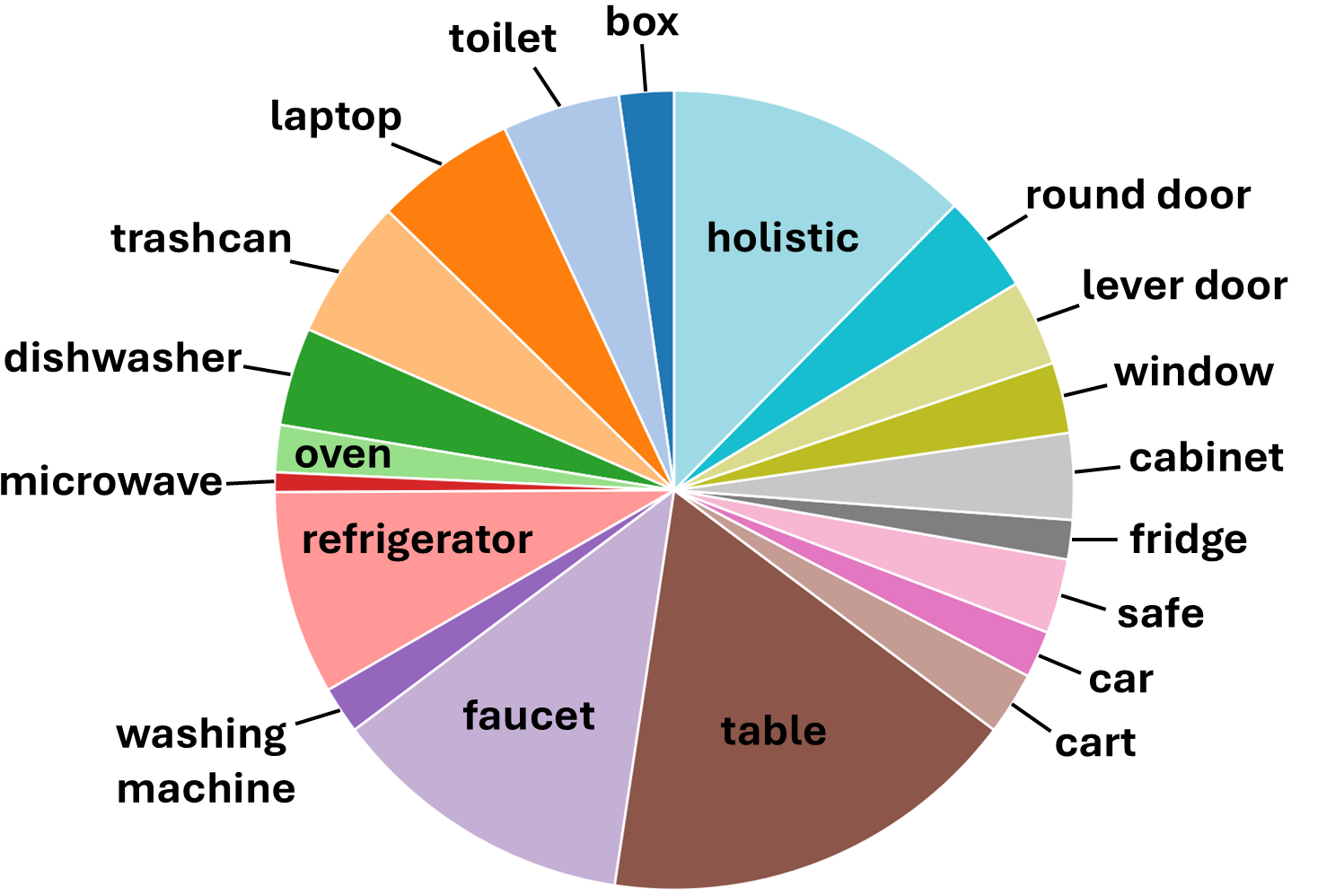
MobileManiRL employs reinforcement learning techniques, specifically Proximal Policy Optimization (PPO), to facilitate efficient training of robotic manipulation policies within the MobileManiBench framework. The training dataset is composed of 630 unique objects distributed across 20 distinct categories, enabling generalization across a wide range of manipulable items. This dataset is further expanded by utilizing 1182 unique combinations of robot configuration, object instance, and required manipulation skill, providing a comprehensive and diverse training environment for the policy.
MobileManiVLA, a policy trained and evaluated within the MobileManiBench framework, demonstrates a 40% success rate when performing the open laptop task in real-world robotic inference. This performance metric was achieved through transfer learning from the simulated environment to a physical robotic system. The 40% success rate indicates the policy’s ability to generalize learned manipulation skills to unseen instances of the task and to overcome the sim-to-real gap, though further improvements are still being investigated to increase robustness and reliability in real-world deployments.

The Power of Simulation and Accelerated Learning
The foundation of MobileManiRL’s learning process lies in the generation of extensive trajectories – sequences of states, actions, and rewards – which serve as the crucial training data for its reinforcement learning algorithms. A substantial 150,000 trajectories were created during the training phase, providing the system with a diverse dataset encompassing a wide range of robotic behaviors and environmental interactions. This data-driven approach allows the robot to learn complex manipulation skills by identifying patterns and optimizing its actions to maximize rewards. The sheer volume of trajectories is critical, enabling the system to generalize effectively and perform reliably across varying conditions and tasks within the MobileManiBench environment.
MobileManiBench addresses the significant challenges of robotic training by prioritizing simulation as a core component of its methodology. Real-world robotic data collection is often hampered by time constraints, safety concerns, and the costs associated with physical hardware and environments. Simulation bypasses these limitations, enabling the generation of vast datasets at a dramatically accelerated pace. This allows for more frequent experimentation with different algorithms and parameters, leading to quicker iteration cycles and ultimately, more refined robotic policies. Furthermore, simulation facilitates the exploration of a broader range of scenarios – including those that are difficult or dangerous to replicate in the physical world – resulting in more comprehensive training and the development of robots capable of adapting to diverse and unpredictable conditions.
The cornerstone of creating resilient robotic systems lies in the capacity to swiftly train and assess policies within a simulated environment. This accelerated development cycle allows for exhaustive testing across a vast range of scenarios – far exceeding the practical limitations of real-world experimentation. By rapidly iterating through countless simulations, researchers can identify and address potential weaknesses in a robot’s control system, leading to policies that exhibit greater stability and adaptability when confronted with unexpected disturbances or novel situations. Consequently, simulation-driven training isn’t simply about speed; it’s about fostering a level of robustness that would be unattainable through conventional methods, ultimately paving the way for robotic systems capable of reliable performance in complex and unpredictable environments.
The introduction of MobileManiBench exemplifies a commitment to systemic design in robotics. The benchmark isn’t merely a collection of tasks, but a carefully constructed ecosystem for evaluating vision-language-action models. This holistic approach acknowledges that true scalability arises not from brute computational force, but from clear, well-defined ideas-a principle echoed by G.H. Hardy who once stated, “A mathematician, like a painter or a poet, is a maker of patterns.” The pattern here is a benchmark designed to reveal the underlying structure of robotic manipulation, allowing for the creation of systems where each component’s behavior contributes to the overall robustness and generalizability-a living organism of code and simulation.
Beyond the Bench
The creation of MobileManiBench addresses a crucial bottleneck – the lack of comprehensive, simulated environments for mobile manipulation. Yet, a meticulously crafted benchmark is merely a refined mirror, not a telescope. It accurately reflects current capabilities, and highlights the persistent challenge: transferring learned policies from simulation to the unpredictable reality of the physical world. One cannot simply replace the robotic hand; one must understand the entire kinematic chain, the subtle interplay of friction, and the inevitable imprecision of sensors.
Future work must move beyond increasingly realistic simulations. The focus should shift to methodologies that actively embrace the discrepancy between simulation and reality – techniques for continual adaptation, robust error recovery, and perhaps, most importantly, a more nuanced understanding of what constitutes successful manipulation. A robot that flawlessly executes a pre-programmed sequence is impressive, but one that gracefully recovers from an unexpected obstruction demonstrates true intelligence.
Ultimately, the field requires a move away from task-specific benchmarks towards more generalizable, compositional skills. The goal isn’t simply to train a robot to perform this manipulation, but to equip it with the foundational abilities from which any manipulation can emerge. It is a question of building a nervous system, not a pre-defined routine.
Original article: https://arxiv.org/pdf/2602.05233.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- All Mobile Games (Android and iOS) releasing in April 2026
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- Limbus Company 2026 Roadmap Revealed
2026-02-08 02:22