Bridging Logic and Learning: A Unified Framework for AI
Researchers have developed a novel approach to combine the strengths of symbolic reasoning and neural networks into a single, cohesive system.
Researchers have developed a novel approach to combine the strengths of symbolic reasoning and neural networks into a single, cohesive system.
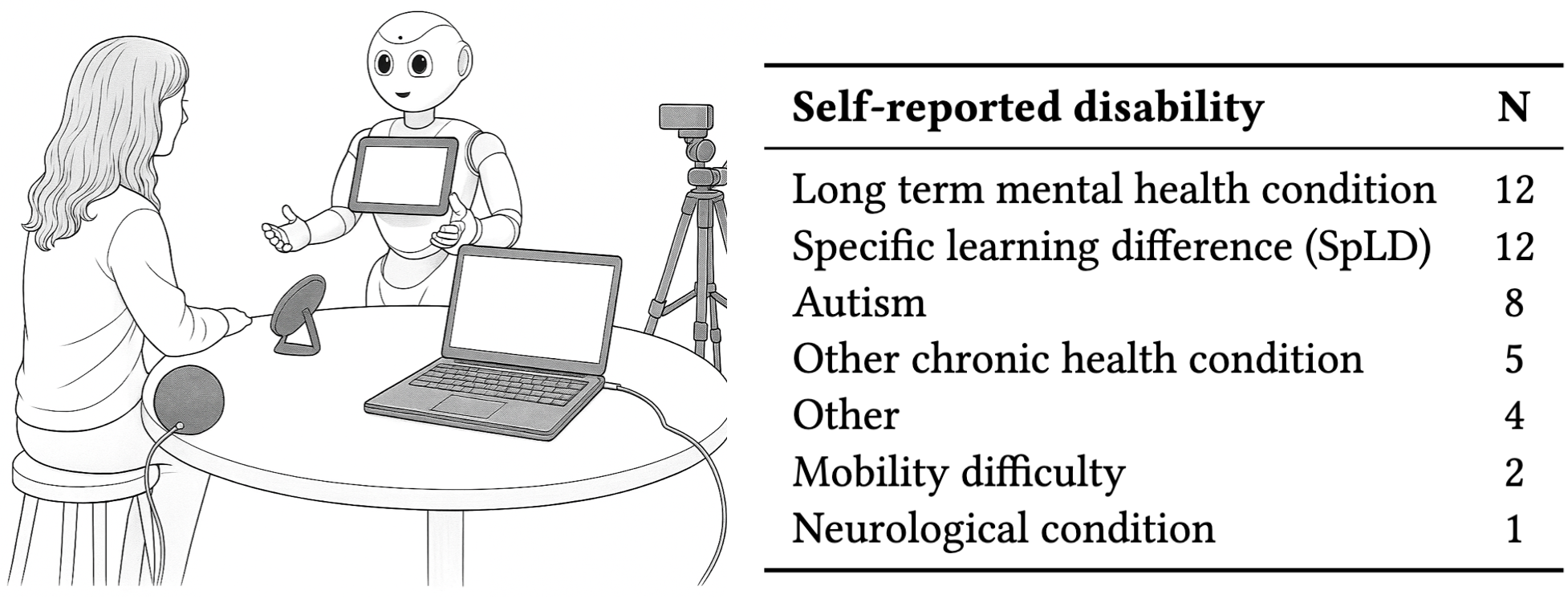
A new study examines the potential of social robots to support disabled students in higher education, revealing both promise and practical limitations.
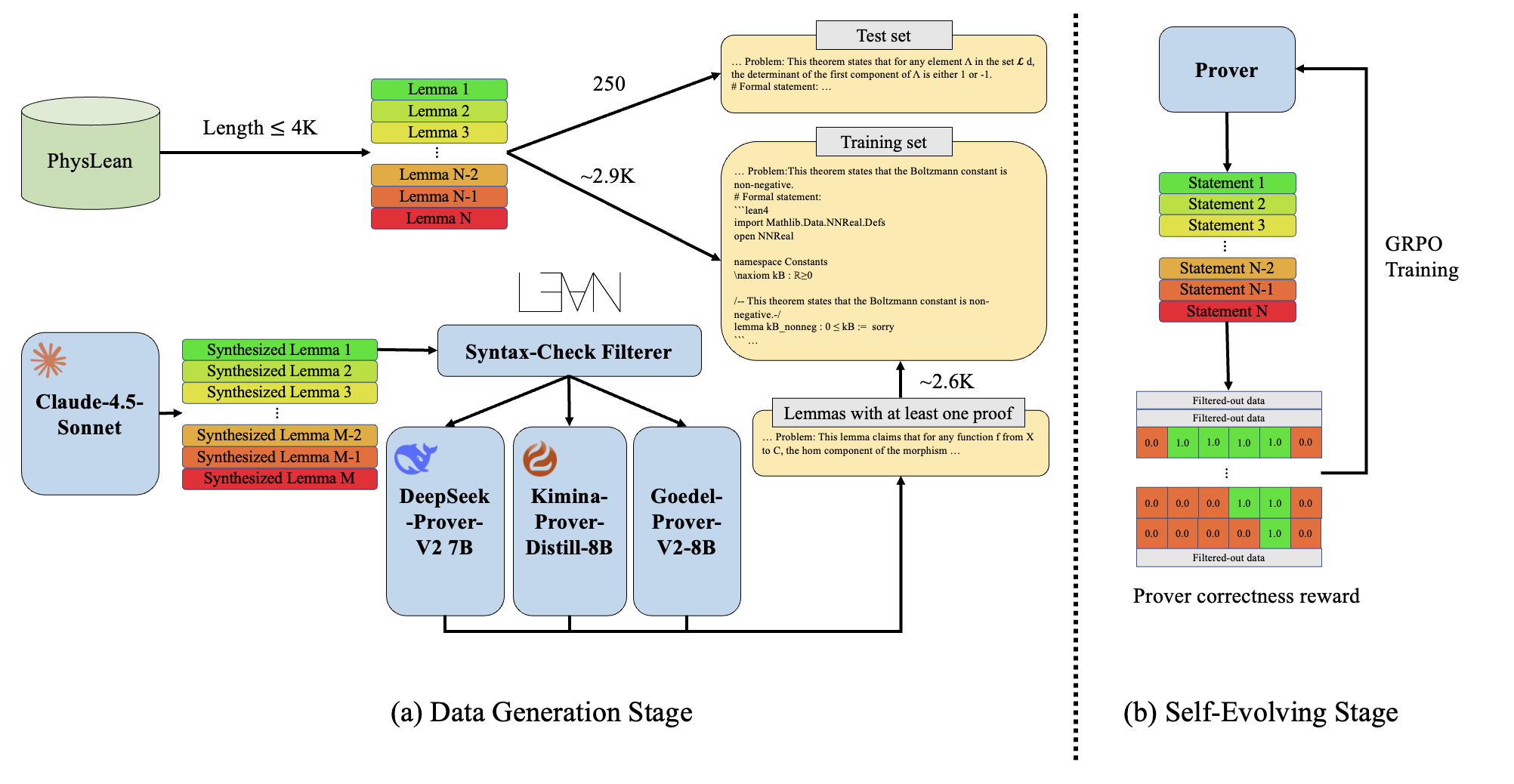
Researchers have developed a system that leverages artificial intelligence to formally prove physics theorems, pushing the boundaries of automated reasoning and mathematical problem-solving.
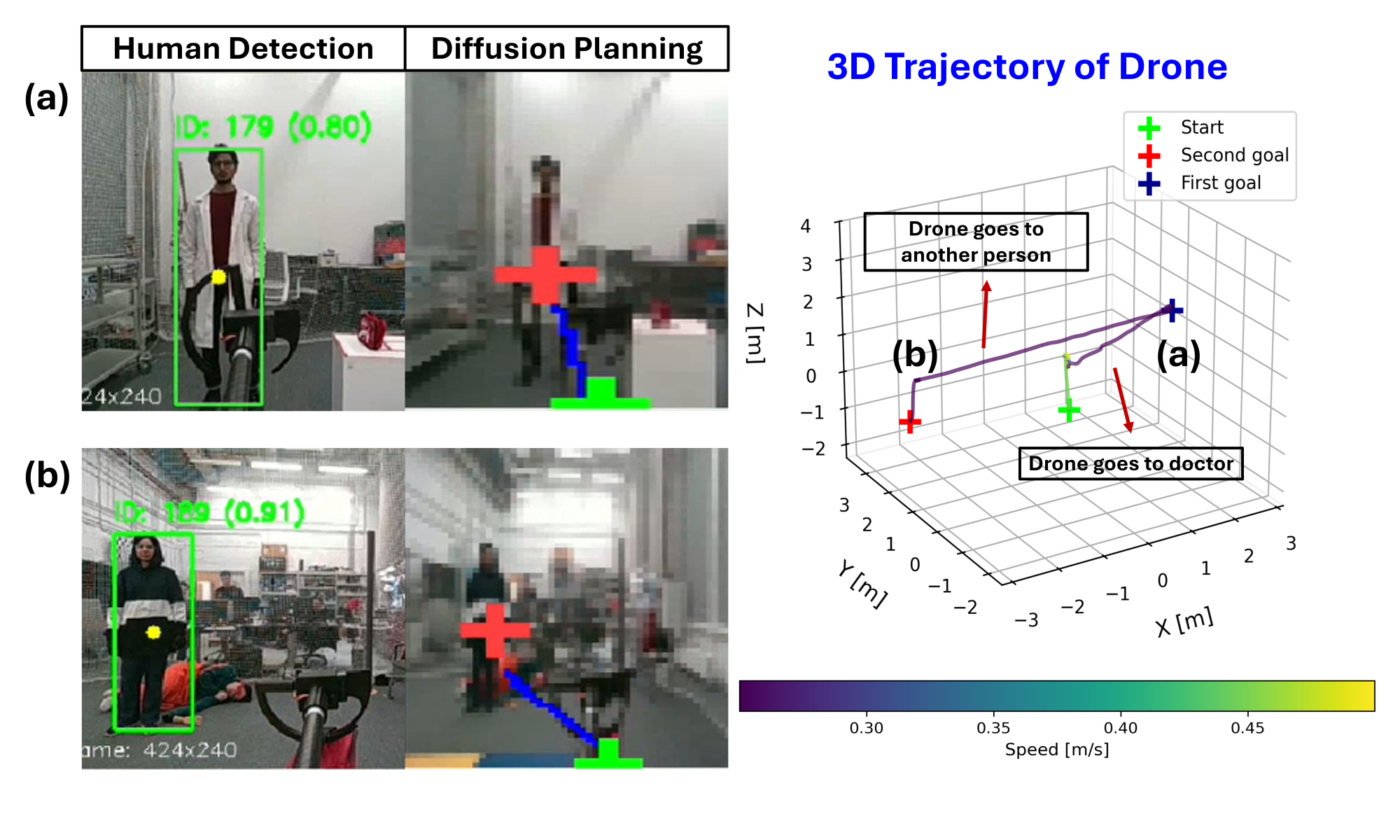
Researchers have developed a new AI system that allows drones to autonomously navigate complex environments and respond to human needs using only visual input.
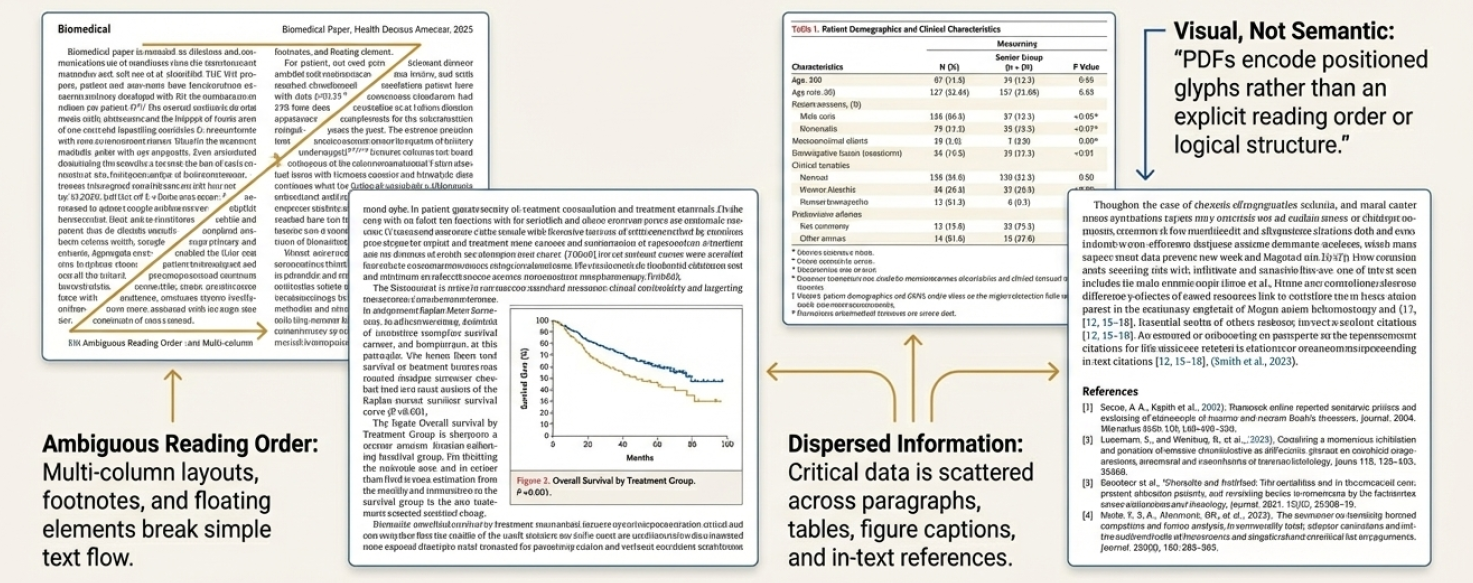
A new approach harnesses schema constraints and provenance tracking to automatically extract structured data from scientific PDFs, streamlining biomedical research.
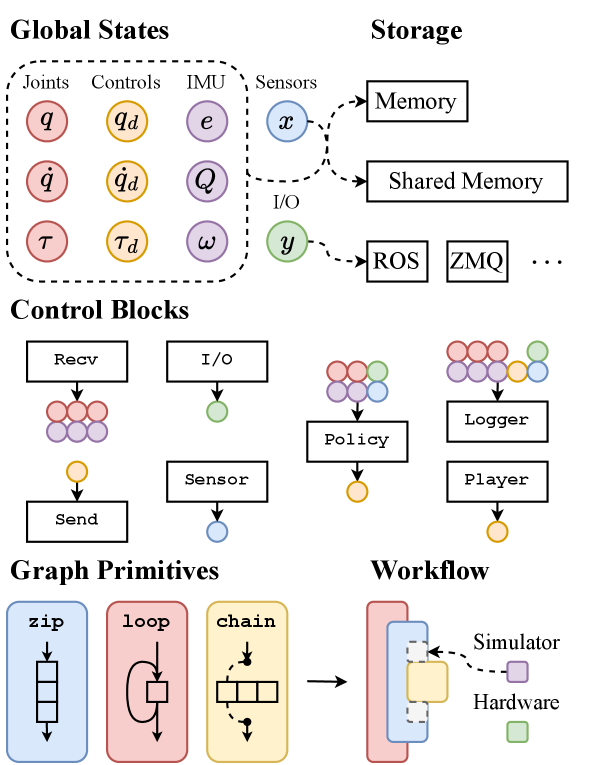
A new framework streamlines the transfer of learned skills to physical robots, accelerating development and deployment across diverse platforms.
A new benchmark rigorously tests large language models’ ability to reason about chemical structure, revealing surprising gaps in their understanding.
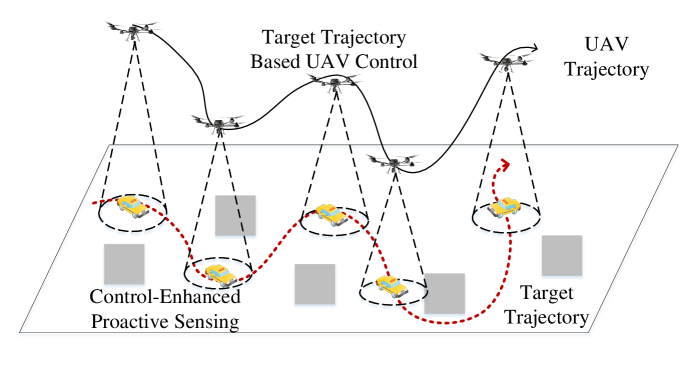
A new framework leverages the synergy between sensing, communication, and control to unlock enhanced agility and efficiency in unmanned aerial vehicle swarms.
A new artistic paradigm is emerging where creative systems don’t just repeat, but fundamentally transform through their own iterative processes, particularly fueled by advancements in artificial intelligence.
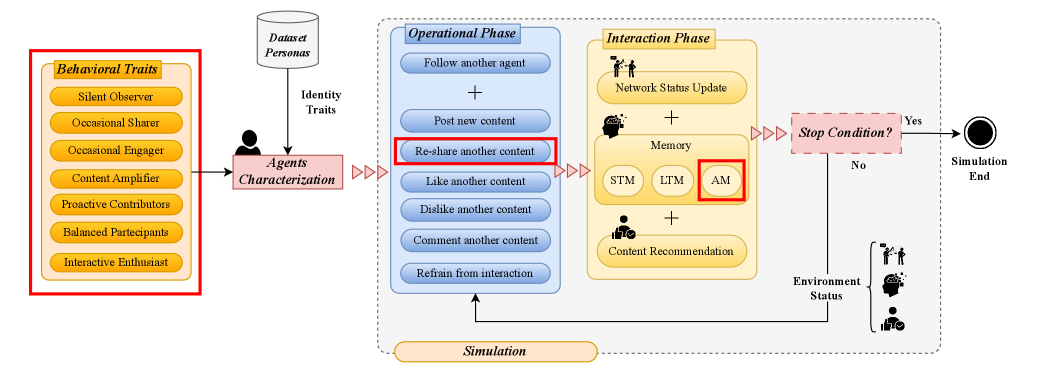
New research shows that giving artificial intelligence distinct personalities dramatically improves the realism of social media simulations.