Author: Denis Avetisyan
A new framework offers reusable templates and patterns to systematically assess and assure the safety of increasingly complex artificial intelligence systems.
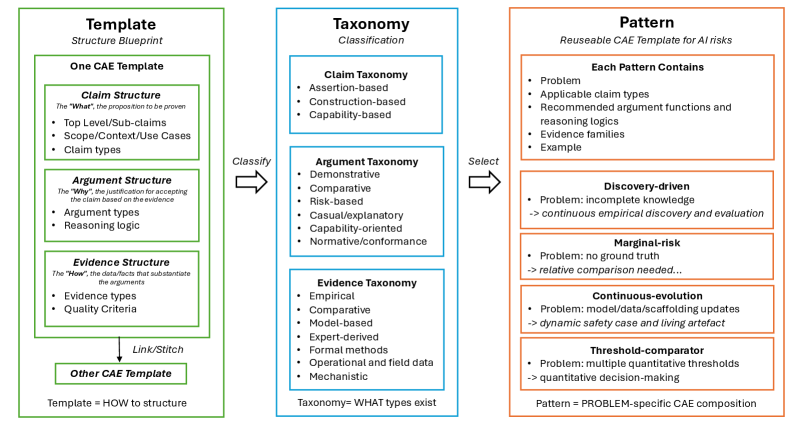
This review introduces a reusable template framework for constructing AI safety cases, addressing the unique challenges of risk assessment, verification, and dynamic safety assurance.
While established safety-case methodologies excel in domains with predictable system behaviour, their applicability to rapidly evolving artificial intelligence remains limited. This challenge is addressed in ‘Constructing Safety Cases for AI Systems: A Reusable Template Framework’, which proposes a novel, reusable framework of safety-case templates, taxonomies, and patterns tailored to the unique risks of modern AI. The framework provides a systematic approach to constructing credible, auditable, and adaptive safety arguments through defined claim, argument, and evidence types-spanning empirical data to formal methods. Can this composable approach effectively bridge the gap between traditional engineering safety and the dynamic complexities of generative and frontier AI systems?
The Inevitable Argument: Establishing a Foundation for AI Safety
The increasing integration of artificial intelligence into daily life demands a proactive and systematic approach to safety assurance. As AI systems transition from controlled research environments to real-world applications – influencing areas like healthcare, transportation, and finance – the potential for unintended consequences rises significantly. Simply demonstrating functionality is insufficient; a robust safety profile is now critical for public trust and responsible deployment. This necessitates moving beyond ad-hoc testing toward formalized methods that rigorously assess potential hazards, evaluate risk mitigation strategies, and provide documented evidence of acceptable performance under various conditions. The need isn’t merely to avoid harm, but to demonstrably prove a commitment to safety through a structured and verifiable process, establishing confidence in these increasingly powerful technologies.
The AI Safety Case establishes a structured rationale for trusting artificial intelligence systems, moving beyond simple testing to a comprehensive argument for acceptable safety. This framework demands a compelling and documented justification, built upon robust evidence, that a specific AI system will perform its intended function without causing unacceptable harm. It isn’t merely about proving the absence of failures, but demonstrating that potential risks have been thoroughly identified, assessed, and mitigated to a level deemed acceptable within a clearly defined operational context. By demanding this level of demonstrable assurance, the AI Safety Case aims to foster confidence and responsible deployment of increasingly powerful AI technologies, ensuring alignment with human values and societal well-being.

Deconstructing Assurance: Methods for Constructing the Safety Argument
The Claims, Arguments, and Evidence (CAE) framework provides a structured approach to AI safety justification. A claim articulates a specific safety property of the AI system – for example, “The system will not exceed a defined operational speed.” Supporting each claim are arguments, which present the logical reasoning connecting design and implementation choices to the claimed safety property. Crucially, each argument is substantiated by evidence, consisting of data from testing, simulations, formal verification, or established safety standards. This tripartite structure ensures transparency by explicitly detailing the rationale behind safety assertions and facilitates traceability, allowing reviewers to follow the chain of reasoning from claim to supporting evidence, and to identify potential gaps or weaknesses in the safety case.
Empirical Evaluation, Comparative Assessment, and Formal Verification constitute core methodologies for substantiating safety claims. Empirical Evaluation utilizes testing and observation to gather data on system behavior under defined conditions, providing evidence of performance against specified safety requirements. Comparative Assessment benchmarks the AI system against established baselines, alternative designs, or known safe systems, demonstrating relative safety improvements or identifying potential regressions. Formal Verification employs mathematical proofs to demonstrate that the system’s design and implementation satisfy predefined safety properties, offering a high degree of assurance, though often limited to specific aspects of the system. The integration of these methods provides a multi-faceted approach to building a robust and verifiable safety case.
AI-assisted methods are being developed to automate and standardize the creation of safety documentation. Specifically, LLM_Safety_Case_Generation utilizes large language models to draft safety case content, while Template_Based_Safety employs pre-defined structures to ensure consistency. These approaches are further supported by the identification and implementation of four reusable safety-case patterns, designed to facilitate the efficient construction of arguments and evidence for AI system safety. This automation aims to reduce the time and resources required for safety justification, while improving the completeness and traceability of the resulting documentation.

Embracing the Current: Adapting to Change with the Dynamic Safety Case
The Dynamic Safety Case represents a departure from static, document-centric safety assessments traditionally used in engineering. Instead of a one-time certification, it is a living document that is continuously updated throughout the AI system’s lifecycle. This is achieved by integrating real-time operational data – encompassing system inputs, outputs, and internal states – into the safety argument. Consequently, the safety case adapts to observed changes in the AI’s behavior, drift in input data distributions, and the introduction of new functionalities. This continuous evolution ensures the safety argument remains aligned with the current operational profile and mitigates risks associated with unanticipated system behavior, a critical requirement for autonomous and adaptive AI systems.
Continuous monitoring via AgentOps is central to maintaining a current and accurate Dynamic Safety Case. AgentOps involves the systematic collection and analysis of runtime data from the AI system, including performance metrics, behavioral patterns, and environmental interactions. This data is then used to validate the assumptions and assertions documented within the safety case, identifying discrepancies between expected and observed behavior. Automated alerting systems within AgentOps flag deviations requiring investigation, triggering updates to the safety case documentation – including hazard analyses, risk assessments, and mitigation strategies – to reflect the AI system’s evolving real-world performance. This iterative process of monitoring, analysis, and adaptation ensures the safety case remains a reliable and up-to-date representation of the system’s safety posture throughout its operational lifecycle.
The Dynamic Safety Case operates on the principle that AI system safety is not a fixed characteristic established during initial development, but rather an evolving property requiring continuous assessment. This necessitates a close integration with the AI_System_Evolution lifecycle; as the AI model changes through retraining, data drift, or functional updates, the safety case must be correspondingly revised and validated. This iterative process ensures the documented safety arguments accurately reflect the current system behavior and potential hazards, acknowledging that safety assurance is an ongoing activity rather than a one-time certification. Failure to synchronize the safety case with system evolution introduces the risk of basing safety arguments on outdated or inaccurate information.

Navigating Uncertainty: Addressing Real-World Complexity with Risk Assessment Strategies
Marginal Risk Assessment is a crucial evaluation strategy employed when definitive ground truth data is absent, a common scenario in many real-world AI applications. This approach shifts the focus from achieving absolute accuracy to demonstrating that the AI system’s performance does not fall below an acceptable baseline – often a currently used manual process or a simpler, established algorithm. The assessment compares the AI system’s outputs to those of the baseline, specifically analyzing instances where the AI and baseline disagree, and determining if the AI’s deviation introduces unacceptable harm or error. Statistical methods are used to quantify the risk of the AI being worse than the baseline, rather than simply measuring its overall performance, making it a practical technique for deploying AI systems in the absence of perfect validation data.
AI Risk Management encompasses a systematic process for identifying potential harms arising from AI systems, assessing the likelihood and impact of those harms, and implementing strategies to mitigate them. This framework extends beyond initial development and encompasses the entire lifecycle of the AI system, including data acquisition, model training, deployment, and ongoing monitoring. Key components include hazard analysis to proactively identify risks, impact assessment to determine the severity of potential harms across different stakeholder groups, and the implementation of controls – technical, procedural, or organizational – to reduce risk to an acceptable level. Continuous monitoring and evaluation are essential to adapt risk mitigation strategies as the AI system evolves and encounters new data or operational contexts.
The implementation of risk assessment strategies, such as marginal risk assessment and comprehensive AI risk management, is particularly vital in high-stakes applications like AI-driven tender evaluation systems. These systems, responsible for objective assessment of bids and proposals, require demonstrably fair and reliable operation to maintain public trust and legal defensibility. Rigorous assessment identifies potential biases in algorithms or data that could lead to discriminatory outcomes, ensuring equal opportunity for all bidders. Furthermore, proactive risk mitigation throughout the system’s lifecycle-from data collection and model training to deployment and monitoring-is essential to prevent inaccuracies, maintain data security, and uphold the integrity of the procurement process.

Beyond Certification: The Future of AI Safety – Continuous Validation and Evolution
Deploying increasingly complex artificial intelligence systems demands a shift from static safety assessments to a continuous validation process, fundamentally reliant on the integration of several key technologies. Dynamic Safety Cases, which evolve alongside the AI’s learning and adaptation, are crucial for maintaining a current understanding of potential hazards. These cases are strengthened by advanced risk assessment strategies that move beyond simple failure mode analysis, instead employing techniques like formal verification and adversarial testing. Critically, the sheer volume of data and arguments required for comprehensive AI assurance necessitates AI-assisted documentation tools; these systems can automate evidence gathering, argument construction, and consistency checking, ultimately enabling a more scalable and reliable approach to ensuring AI safety throughout its lifecycle. This combination promises a future where AI systems aren’t simply tested once, but continuously monitored and validated, fostering trust and responsible innovation.
While established AI_Safety_Standards currently offer a vital foundation for responsible development, their static nature is increasingly insufficient given the accelerating pace of innovation. AI systems are no longer simply deployed and monitored; they continuously learn and evolve, potentially exceeding the boundaries defined by initial safety assessments. Therefore, a shift towards continuous validation and adaptation is critical, demanding ongoing risk assessment and refinement of safety protocols. This proactive approach necessitates frameworks capable of dynamically updating to reflect emergent behaviors and vulnerabilities, ensuring that safety measures remain relevant and effective throughout the AI system’s lifecycle. Simply meeting a standard at one point in time is no longer enough; sustained vigilance and iterative improvement are essential to navigate the complexities of advanced AI.
A robust system for ensuring AI safety relies on a meticulously structured approach to evidence and reasoning. This framework details a comprehensive taxonomy, categorizing the specific claims made about an AI system’s behavior and the argument functions used to support those claims. Crucially, it identifies seven distinct evidence families – encompassing data, tests, simulations, formal methods, and more – that can be combined and adapted to provide assurance. This ‘composable’ design allows for flexibility; rather than relying on a single, rigid validation process, developers can select and integrate evidence types appropriate to the specific AI system and its intended application, creating a continuously evolving and demonstrably safe architecture.
The pursuit of AI assurance, as detailed in the framework, acknowledges that perfect foresight is an illusion. Systems, by their very nature, evolve and accumulate imperfections over time. This aligns with Donald Knuth’s observation: “Premature optimization is the root of all evil.” While not directly about safety, the principle echoes the need to avoid rigid, overly prescriptive safety measures that cannot adapt to the dynamic risks inherent in AI. The reusable templates aren’t about eliminating all potential failures, but about establishing a structured approach to identifying, mitigating, and learning from them-allowing the system to mature gracefully through a series of incremental improvements and refinements, acknowledging that incidents are simply steps toward a more robust and reliable AI.
What Lies Ahead?
The construction of safety cases for artificial intelligence, as this work demonstrates, is less about achieving a static state of ‘safe’ and more about charting a course through inevitable decay. Traditional engineering assumes systems eventually succumb to predictable failure modes; AI presents a different challenge. Its ‘failures’ are often emergent, reflections of shifting data landscapes and unforeseen interactions. The presented framework offers a useful scaffolding, but scaffolding, by its nature, is temporary. The real question is not how to prevent these failures, but how to build systems that learn to age gracefully – that reveal their vulnerabilities before they become critical.
A reliance on templates, however comprehensive, risks ossification. The field must move beyond codifying known risks and towards methods for identifying the unknown unknowns. Dynamic safety, as touched upon in this work, requires a constant recalibration, a willingness to dismantle and rebuild assumptions. It is a continuous process of observation, adaptation, and acceptance that a perfect safety case is an illusion.
Perhaps the most valuable outcome of this line of inquiry will not be a foolproof method for assuring AI, but a deeper understanding of the limits of assurance itself. Sometimes, observing the process of system evolution – acknowledging its inherent imperfections – is more valuable than attempting to accelerate it towards an unattainable ideal. The work invites further exploration into the metaphysics of failure, and how systems, both artificial and natural, navigate the passage of time.
Original article: https://arxiv.org/pdf/2601.22773.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- Clash of Clans April 2026 Gold Pass Season introduces a Archer Queen skin
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Gold Rate Forecast
2026-02-02 13:30