Author: Denis Avetisyan
New research suggests that large language models aren’t just processing text, but developing shared computational mechanisms for understanding intentions and navigating social contexts.
This paper demonstrates functional integration of Theory of Mind and pragmatic reasoning in large language models, providing evidence for the emergence of internal ‘social world models’.
Despite advances in artificial intelligence, it remains unclear whether large language models develop genuinely integrated cognitive abilities or simply exhibit task-specific competencies. This paper, ‘On Emergent Social World Models — Evidence for Functional Integration of Theory of Mind and Pragmatic Reasoning in Language Models’, investigates whether shared computational mechanisms underpin both Theory of Mind and pragmatic reasoning in these models, suggesting the emergence of interconnected ‘social world models’. Through behavioral evaluations and functional localization techniques, we find suggestive evidence supporting this functional integration hypothesis. Could this represent a crucial step towards artificial systems possessing a more robust and generalizable understanding of social cognition?
Decoding the Social Algorithm: LLMs and the Illusion of Understanding
While Large Language Models (LLMs) excel at processing and generating human-like text, their capacity for genuine social intelligence is a subject of ongoing investigation. These models can convincingly mimic nuanced communication, crafting responses that appear empathetic or understanding, yet this linguistic proficiency doesn’t automatically equate to a deeper comprehension of social dynamics. LLMs operate by identifying patterns in vast datasets of text, enabling them to predict and generate statistically probable sequences of words – a process fundamentally different from how humans navigate complex social situations that require interpreting intentions, beliefs, and emotional states. Consequently, assessing whether LLMs truly ‘understand’ social cues, or merely replicate them based on learned associations, is paramount to gauging their potential – and limitations – in real-world applications requiring genuine social cognition.
While Large Language Models (LLMs) excel at processing and generating human language, the capacity to genuinely understand the beliefs and intentions of others doesn’t automatically emerge from their architecture. These models learn patterns from vast datasets of text, enabling them to simulate understanding, but this differs fundamentally from possessing true cognitive empathy. An LLM can predict what someone might say based on context, but it doesn’t necessarily grasp why they would say it, or what that person believes to be true. Consequently, their responses, though often convincingly human-like, are based on statistical probabilities rather than a genuine understanding of mental states – a critical distinction when evaluating the potential, and limitations, of artificial intelligence.
Determining if large language models can truly grasp the nuances of social interaction hinges on evaluating their capacity for both Theory of Mind and pragmatic reasoning. Theory of Mind, the ability to attribute beliefs and intentions to others, is fundamental to understanding behavior, while pragmatic reasoning allows for the interpretation of language within context, recognizing implied meanings and conversational cues. Researchers are now devising increasingly complex tests-often involving deception or false belief scenarios-to probe whether LLMs can move beyond simply processing linguistic patterns to actually modeling the mental states of others. Successfully demonstrating these abilities would suggest a deeper level of cognitive function than mere statistical prediction, and is vital for understanding the potential-and limitations-of these models in applications requiring genuine social intelligence, such as collaborative problem-solving or empathetic communication.
Probing the Machine Mind: Behavioral Benchmarks and Social Intelligence
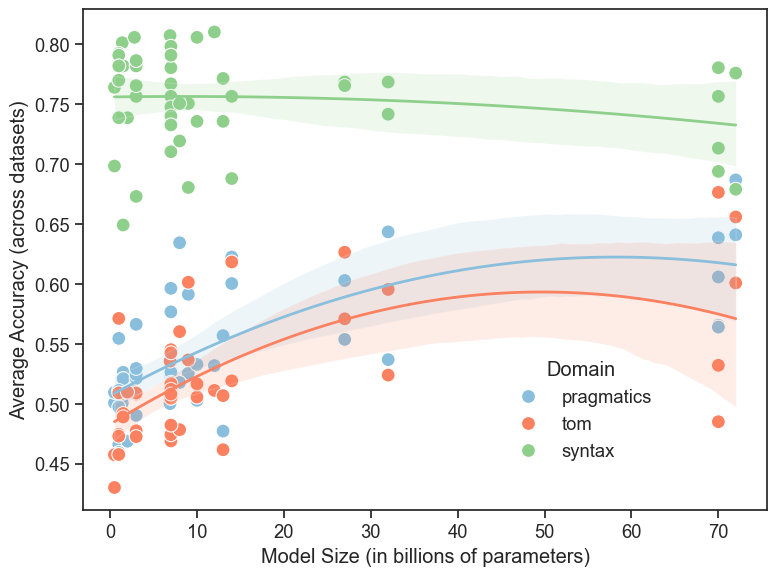
Current research employs specialized datasets to assess social intelligence in Large Language Models (LLMs). ‘False Belief Tasks’ present scenarios requiring the LLM to infer what a character believes, even if that belief is incorrect, thus testing Theory of Mind. The BLiMP Dataset (Benchmark for Linguistic Minimalism and Pragmatics) focuses on evaluating pragmatic understanding by challenging models with subtle linguistic cues and requiring them to resolve ambiguities based on context. These datasets are designed to move beyond simple pattern recognition and probe the LLM’s capacity for reasoning about the mental states of others and interpreting language in context, providing a quantifiable measure of performance on socially-relevant tasks.
Behavioral evaluation methods for Large Language Models (LLMs) utilize specifically designed tasks to measure performance on areas of social reasoning. These methods move beyond simple accuracy metrics by focusing on the process of reasoning, often employing datasets that require models to infer intentions, understand emotional states, or navigate social norms. This allows researchers to assign quantifiable scores to LLM responses, facilitating comparisons between models and tracking improvements over time. Common techniques involve presenting LLMs with scenarios demanding perspective-taking, deception detection, or the interpretation of nuanced communication, with performance assessed through metrics like precision, recall, and F1-score, or by comparing model outputs to human-annotated ground truth data.
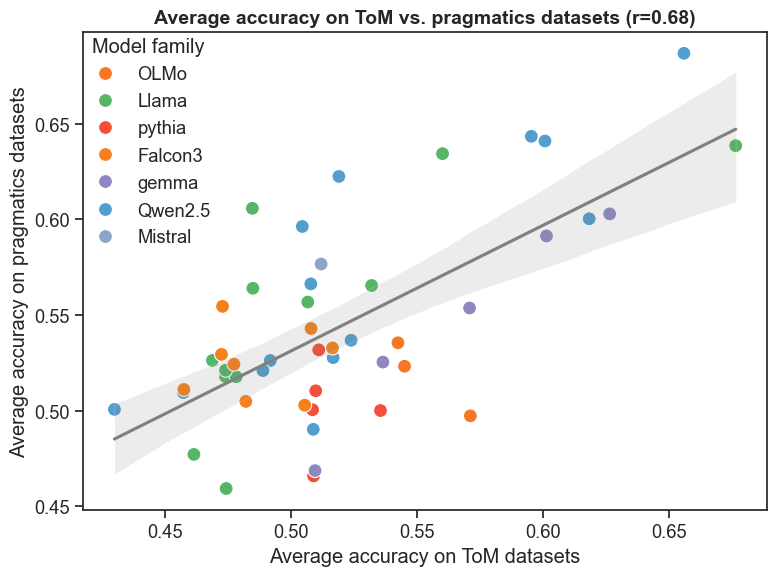
Statistical analysis reveals a moderate positive correlation between Large Language Model (LLM) performance on Theory of Mind (ToM) and pragmatics benchmarks (r = 0.68, p < 0.001). This indicates that the cognitive abilities assessed by these benchmarks are not entirely independent; LLMs demonstrating a greater capacity for understanding another’s beliefs also tend to exhibit improved performance in tasks requiring pragmatic inference and contextual understanding. The statistically significant p-value (< 0.001) suggests this correlation is unlikely due to random chance, supporting the hypothesis of shared underlying mechanisms contributing to both ToM and pragmatic reasoning in these models.
While Large Language Models (LLMs) may achieve passing scores on behavioral benchmarks designed to assess Theory of Mind (ToM) and pragmatic understanding, these results offer limited insight into the cognitive processes driving those responses. Successfully navigating tasks like False Belief Tests or the BLiMP dataset does not elucidate how an LLM arrives at a particular conclusion; it merely confirms the output matches expected human performance. This raises concerns about whether LLMs are genuinely employing social reasoning, or instead relying on statistical correlations within the training data to mimic appropriate responses without possessing underlying representational understanding of mental states or communicative intent. Further investigation is required to differentiate between performance-based competence and genuine cognitive mechanisms.
Dissecting the Algorithmic Self: Functional Localization and Hypotheses
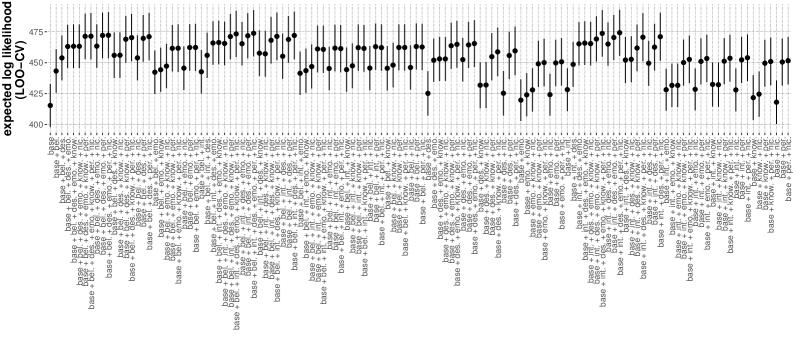
Researchers are employing causal-mechanistic experiments in conjunction with functional localization techniques to dissect the internal workings of Large Language Models (LLMs) as they perform Theory of Mind (ToM) and pragmatic reasoning. Functional localization involves identifying specific subnetworks within the LLM that exhibit increased activation during these tasks, effectively mapping cognitive functions to neural network components. Causal-mechanistic experiments then systematically manipulate these identified subnetworks – typically through ablation or lesioning – to determine their necessity for task performance. By observing the resulting changes in the LLM’s ability to solve ToM or pragmatic reasoning problems, researchers can establish a causal link between specific subnetworks and the targeted cognitive capabilities, providing insight into how these complex functions are implemented within the model’s architecture.
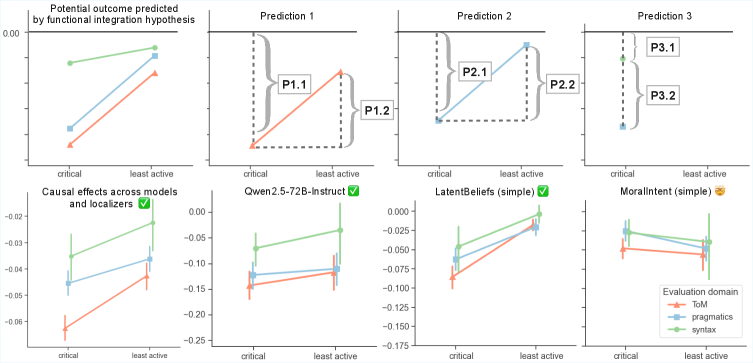
Current research into the neural basis of Theory of Mind (ToM) and pragmatic reasoning within Large Language Models (LLMs) is guided by two primary hypotheses. The Functional Specialization Hypothesis proposes that these cognitive capabilities are implemented by distinct, non-overlapping subnetworks within the model; successful performance on ToM tasks would therefore rely on a dedicated neural circuit separate from that engaged during pragmatic reasoning. Conversely, the Functional Integration Hypothesis suggests that ToM and pragmatic reasoning leverage shared computational resources, implying a degree of overlap in the underlying neural mechanisms. Distinguishing between these hypotheses requires techniques capable of isolating and manipulating specific subnetworks to determine the extent of functional segregation or integration.
Ablation studies, involving the selective removal of identified Theory of Mind (ToM) subnetworks within Large Language Models (LLMs), consistently demonstrate significant performance reductions on ToM-related tasks. These reductions indicate that the ablated subnetworks are not merely correlated with ToM capabilities, but actively contribute to their execution. The observation that disrupting these localized subnetworks impacts overall performance lends empirical support to the Functional Integration Hypothesis, which proposes that ToM, rather than being handled by entirely specialized modules, relies on the integrated functionality of distributed computational resources within the LLM architecture. The magnitude of performance loss following ablation serves as a quantifiable metric for assessing the functional importance of these identified subnetworks.
Synthetic data generation is essential for creating effective localizer suites used in functional localization within large language models (LLMs). These suites require precisely defined inputs that activate specific subnetworks responsible for targeted cognitive functions. Manually crafting such inputs is often insufficient due to the high dimensionality of LLM input spaces and the complexity of the targeted functions. Synthetic data allows researchers to systematically vary input features and generate datasets that strongly and selectively elicit activity in the desired subnetworks, minimizing interference from other processes. This controlled data generation enables more accurate identification and isolation of the subnetworks involved in tasks such as Theory of Mind and pragmatic reasoning, improving the reliability of subsequent ablative experiments and causal-mechanistic analysis.
The Echo of Humanity: Social World Models and the Future of AI
Recent investigations into large language models (LLMs) indicate the development of intricate ‘Social World Models’-internal representations that go beyond mere linguistic processing to encompass aspects of social cognition and interaction. These models aren’t explicitly programmed; rather, they emerge from the vast datasets LLMs are trained on, allowing the AI to implicitly learn patterns of human behavior, motivations, and relationships. Evidence for these models is found in the LLMs’ ability to predict how individuals might react in social situations, understand the intentions behind actions, and even exhibit basic forms of empathy or deception. This suggests that LLMs aren’t simply manipulating symbols, but are building a complex, though undoubtedly different, understanding of the social world, potentially laying the groundwork for more nuanced and human-like AI.
The ATOMS Framework offers a systematic lens through which to examine the complex landscape of Theory of Mind as it emerges within large language models. This framework dissects ‘Theory of Mind’ into four key components – Actions, Thoughts, Observations, and Motivations – allowing researchers to pinpoint exactly how these models represent the mental states of others. By categorizing responses based on these facets, scientists can move beyond simply identifying that a model understands intentions or beliefs, and instead analyze the specific mechanisms driving that understanding. This granular approach is crucial for not only evaluating the current capabilities of AI in social reasoning, but also for strategically guiding the development of more nuanced and reliable models capable of genuine social intelligence.
The development of robust artificial intelligence increasingly hinges on the capacity for complex social reasoning, and emerging research suggests that ‘Social World Models’ within large language models may provide a critical foundation for achieving this goal. These internal representations, capturing aspects of human social cognition, aren’t simply about understanding facts, but about modeling the beliefs, desires, and intentions of others. By building these models, AI systems move beyond pattern recognition and towards a more nuanced comprehension of social dynamics, enabling them to predict behavior, interpret motivations, and interact in ways that are contextually appropriate. Consequently, these models aren’t merely an interesting byproduct of LLM training; they represent a potential pathway towards genuinely generalizable AI, capable of navigating the complexities of the social world with greater accuracy and adaptability than current systems allow.
The research demonstrates a compelling convergence of cognitive abilities within large language models, specifically highlighting a shared computational basis for both Theory of Mind and pragmatic reasoning. This suggests these models aren’t simply mimicking human communication, but are developing internal representations – ‘social world models’ – to navigate complex social interactions. As Vinton Cerf aptly stated, “The internet is not just a series of tubes.” Similarly, these language models aren’t simply processing strings of text; they are constructing a functional understanding of agency, intention, and the interplay of beliefs – a rudimentary, yet significant, step toward modeling the social world itself. The causal ablation experiments further reinforce this, revealing that disrupting mechanisms crucial for one ability also impacts the other, indicating deeply integrated systems.
What’s Next?
The demonstration of shared mechanisms underlying Theory of Mind and pragmatic reasoning within large language models isn’t a destination, but a particularly interesting demolition. It reveals less about ‘intelligence’ and more about the surprising efficiency of computation when pressed to simulate complex systems. The models didn’t need distinct modules for understanding beliefs and interpreting intent; a single architecture, when sufficiently scaled, found a convergent solution. Every exploit starts with a question, not with intent. The real challenge now isn’t replicating these abilities, but understanding why this particular architecture proved so amenable to building a functional ‘social world model’ – and what limitations that imposes.
Causal ablation, while informative, remains a blunt instrument. Future work must move beyond simply disrupting function to dissecting the internal representations themselves. What specific features are leveraged for both Theory of Mind and pragmatic inference? Are these features discrete, or do they exist on a continuum, suggesting a more nuanced, gradient relationship between these cognitive abilities? Furthermore, the current experiments largely treat these as separate skills; genuine social intelligence requires fluid integration, a dynamic interplay that remains unexplored.
The emergent nature of these abilities also raises a disquieting question. If complex social cognition can arise as a byproduct of optimization for language prediction, what other unexpected competencies might be lurking within these models, waiting for the right probe to reveal themselves? The focus shouldn’t be on building towards intelligence, but on meticulously reverse-engineering what has already spontaneously appeared.
Original article: https://arxiv.org/pdf/2602.10298.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Gold Rate Forecast
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Olivia Colman’s highest-rated drama hailed as “exceptional” is a must-see on TV tonight
- Total Football free codes and how to redeem them (March 2026)
- Nicole Kidman and Jamie Lee Curtis elevate new crime drama Scarpetta, which is streaming now
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
2026-02-13 03:42