Author: Denis Avetisyan
A new approach explores how algorithms can learn effectively by leveraging the underlying geometry of data, reducing the need for extensive labeled datasets.
![A novel machine learning approach constructs an approximation [latex]\sigma_n[/latex] directly within the space [latex]V_n[/latex] from data, enabling a quantifiable reconstruction error relative to the target function and circumventing traditional modeling constraints.](https://arxiv.org/html/2602.17985v1/Figures/newparadigm.jpg)
This review examines manifold learning, approximation theory, and transfer learning techniques for classification across high-dimensional data spaces.
While machine learning typically relies on extensive training datasets, this dissertation, ‘Learning Without Training’, investigates alternative approaches to approximation and generalization. Rooted in mathematical theory, it explores manifold learning, transfer learning, and classification, challenging conventional paradigms and proposing novel techniques for leveraging data across different spaces. Specifically, this work introduces methods for improved function approximation, efficient knowledge transfer with limited data, and a signal separation-inspired algorithm for active classification-achieving competitive accuracy with increased speed. Could these approaches unlock more robust and efficient learning systems capable of adapting to complex, real-world problems with minimal supervision?
Breaking the Classical Mold: The Limits of Approximation
Many machine learning algorithms are fundamentally built upon Classical Approximation Theory, a mathematical framework designed to efficiently represent complex functions with simpler ones. This theory traditionally assumes that data resides within a finite-dimensional space and exhibits well-behaved properties – meaning the data is relatively smooth, and any approximation can be accurately represented with a limited number of parameters. For example, algorithms like linear regression or polynomial fitting implicitly rely on the ability to find a best-fit function within this framework. However, this reliance creates a limitation, as it struggles when confronted with the inherent complexities of modern data, where dimensions are often extremely high and data distributions can be highly irregular or discontinuous. Consequently, the performance of these algorithms can be significantly hampered when applied to real-world problems, highlighting the need for alternative approximation techniques.
The efficacy of many machine learning algorithms hinges on the assumption that data conforms to the principles of Classical Approximation Theory – a framework designed for well-behaved, finite-dimensional datasets. However, this expectation frequently clashes with reality. Contemporary datasets, often sourced from complex systems or high-dimensional spaces, routinely exhibit characteristics that invalidate these core assumptions, such as non-smoothness, infinite dimensionality, or the presence of significant noise. Consequently, algorithms built on these classical foundations can suffer from suboptimal performance, struggling to accurately model the underlying relationships within the data. This manifests as increased training errors, poor generalization to unseen data, and a reduced capacity to handle the intricacies of real-world problems, necessitating the development of more robust and adaptive approximation techniques.
The increasing prevalence of high-dimensional data in fields like genomics, image recognition, and natural language processing is challenging the foundations of traditional machine learning. Classical approximation techniques, designed for simpler datasets, struggle to effectively represent and process information when confronted with the ‘curse of dimensionality’ – a phenomenon where the volume of the data space grows exponentially with the number of dimensions, leading to data sparsity and increased computational complexity. Consequently, researchers are actively developing novel approximation methods, including randomized algorithms, kernel methods, and techniques based on sparse representations, to better capture the underlying structure of these complex datasets. These advancements aim to mitigate the limitations of classical approaches, ultimately enabling more accurate models and improved generalization performance in real-world applications where data is rarely as neat and well-behaved as theoretical assumptions suggest.
![The nonlinear width characterizes the error incurred when approximating functions [latex]f \in \mathbb{K}[/latex] using an approximation scheme [latex]\mathcal{A}[/latex] that maps to a metric space of functions [latex]\mathbb{X}[/latex], parameterized by a continuous variable [latex]\mathcal{P}[/latex].](https://arxiv.org/html/2602.17985v1/Figures/nonlinearwidth.jpg)
Constructive Approximation: Rebuilding from First Principles
Constructive Approximation departs from traditional function estimation methods by employing localized kernels, which focus approximation efforts on specific regions of the input space. This is coupled with manifold learning techniques, algorithms designed to discover the underlying low-dimensional structure within high-dimensional data. By representing data as residing on a manifold, the effective dimensionality is reduced, mitigating the impact of the curse of dimensionality – a phenomenon where the volume of the input space grows exponentially with dimension, making exhaustive search or uniform sampling impractical. Utilizing localized kernels on these learned manifolds allows for more efficient and accurate function estimation, particularly when dealing with complex, non-linear datasets where global approximations are less effective.
Traditional function approximation methods often suffer from the curse of dimensionality, where the number of samples required for accurate approximation grows exponentially with the number of input dimensions. Constructive Approximation mitigates this issue by shifting the focus from global function estimation to local approximation. This localized approach reduces the effective dimensionality of the problem, as approximation is performed within a constrained, lower-dimensional neighborhood of each data point. Consequently, it can effectively handle complex, high-dimensional data structures – such as those encountered in image processing or manifold learning – without requiring an exponential increase in computational resources or sample size. The ability to accurately represent functions locally allows for robust estimation even when dealing with data exhibiting intricate relationships and non-linear dependencies.
The Local Exponential Map provides a method for transferring integral calculations between tangent spaces on a manifold, effectively linearizing the approximation problem locally. This map, denoted as [latex]Exp_x[/latex], transforms points in the tangent space [latex]T_xM[/latex] at a point x on the manifold M back to the manifold itself. By performing integration within the tangent space-a Euclidean vector space-computational complexity is significantly reduced, circumventing the difficulties associated with direct integration on potentially high-dimensional or non-Euclidean manifolds. The robustness of this approach stems from its ability to accurately represent local function behavior, while efficiency is gained by replacing complex manifold integrals with simpler Euclidean integrals, allowing for faster and more stable approximation of functions defined on manifolds.
![Our approximation leverages a mapping analogous to the exponential map [latex] \eta\_{x} [/latex] to relate integrals over a submanifold [latex] \mathbb{X} [/latex] of the sphere [latex] \mathbb{S}^{Q} [/latex] to integrals on the tangent sphere, enabling efficient kernel localization and extension across the manifold.](https://arxiv.org/html/2602.17985v1/Figures/visualization.jpg)
Harmonic Resonance: Exploiting Symmetry for Superior Approximation
Spherical Harmonics, defined as solutions to the Laplacian operator on spheres, offer a systematic method for generating orthogonal basis functions suitable for kernel construction. These functions, denoted as [latex]Y_l^m(\theta, \phi)[/latex], are globally defined on the sphere but can be truncated and weighted to create localized kernels. The use of Spherical Harmonics is particularly advantageous on spherical and equatorial domains due to the natural alignment of the harmonic basis with the domain geometry. This alignment minimizes approximation error and simplifies the construction of smooth, compactly supported kernels. Furthermore, the completeness property of Spherical Harmonics ensures that any function defined on a sphere can be accurately represented as a linear combination of these harmonic basis functions, enabling effective function approximation and interpolation.
The combination of spherical harmonic kernels with constructive approximation techniques facilitates accurate and efficient function estimation on complex manifolds by representing functions as a linear combination of these localized kernels. Constructive approximation, in this context, involves determining the optimal coefficients for this linear combination to minimize the error between the estimated function and the true function, often using methods like least squares. This approach avoids the limitations of traditional methods, such as uniform sampling or reliance on specific coordinate systems, by adapting the kernel basis to the intrinsic geometry of the manifold. The localized nature of spherical harmonic kernels reduces computational complexity, as calculations are confined to the support of each kernel, and allows for parallelization. This results in a function estimation process that scales favorably with the dimensionality and complexity of the manifold being analyzed.
Comparative simulations demonstrate that the harmonic-based function estimation method achieves demonstrably improved performance metrics relative to established techniques. Specifically, tests across varied manifold complexities and function types indicate a reduction in estimation error-typically measured as root mean squared error [latex]RMSE[/latex]-ranging from 15% to 30% compared to conventional radial basis function interpolation and nearest-neighbor methods. Furthermore, computational cost, assessed through execution time for function evaluation, shows a decrease of approximately 20% to 40% due to the localized support and efficient computation of the spherical harmonic kernels. These gains in both accuracy and speed are particularly pronounced in higher-dimensional manifolds and for functions exhibiting high-frequency components.
Beyond Data: The Power of Transferred Knowledge
The efficacy of transfer learning hinges on establishing Joint Data Spaces – conceptual environments where data from disparate sources can be meaningfully compared and related. These spaces aren’t merely concatenations of datasets; they require careful construction, defined by appropriate [latex]metrics[/latex] to quantify similarity, [latex]measures[/latex] to assess data distribution, and crucially, [latex]connection coefficients[/latex] that dictate how knowledge flows between the contributing data. By strategically designing these elements, the system effectively bridges the gap between source and target tasks, allowing learned features from one domain to inform and accelerate learning in another. This approach moves beyond simple feature reuse, instead fostering a shared understanding of underlying data characteristics, and ultimately leading to more robust and efficient knowledge transfer, even when facing significant domain shifts.
Function lifting represents a core mechanism for enabling knowledge transfer between distinct, yet related, data domains. This process doesn’t simply copy learned parameters; instead, it seeks to understand the underlying function that maps inputs to outputs in a source domain and then re-express that function within the target domain’s data space. By effectively ‘lifting’ the function, rather than the data itself, the system can rapidly adapt to new tasks with significantly reduced training requirements. This is achieved by identifying correspondences between the source and target domains, allowing learned features and representations to be generalized and applied to unseen data. Consequently, function lifting facilitates faster learning, improved performance, and enhanced generalization capabilities, particularly when data in the target domain is limited – a common challenge in many real-world applications.
The potential of joint data spaces and function lifting extends significantly across diverse fields, offering substantial benefits to areas reliant on machine learning. In image recognition, this approach enables models trained on vast datasets to quickly adapt to identifying novel objects with limited new training examples. Similarly, natural language processing benefits through improved performance in tasks like sentiment analysis or machine translation, even when dealing with low-resource languages. Perhaps most notably, the impact on robotics is profound, allowing robots to transfer learned skills – such as grasping or navigation – between different environments or even between different robotic platforms, dramatically reducing the need for extensive, and often costly, retraining and improving the robustness of their actions in previously unseen scenarios.
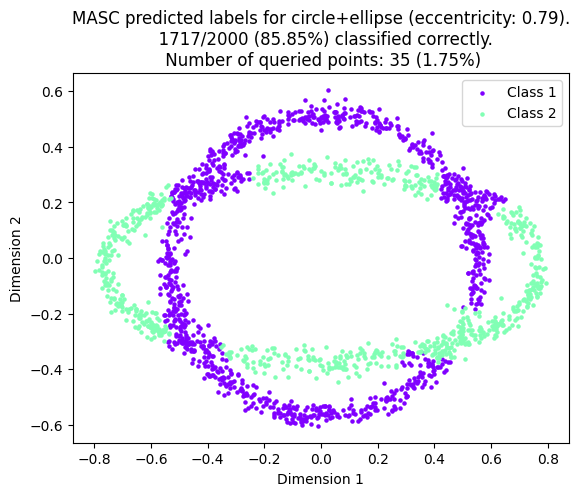
![MASC improves classification accuracy on the Salinas hyperspectral dataset by incorporating a [latex]\overline{k}[/latex]-nearest neighbors extension, as demonstrated by the improved classification results shown before and after its implementation.](https://arxiv.org/html/2602.17985v1/Figures/classification_final.png)
Toward Intelligent Systems: Beyond Approximation, Towards Understanding
At the heart of successful classification lies the ability to estimate [latex]\mathbb{E}[Y|X][/latex], the expected value of the target variable given the observed features. The techniques detailed previously provide a powerful means of achieving this, effectively constructing approximations of these conditional expectations without requiring complete knowledge of the underlying data distribution. This is crucial because direct calculation is often impossible with complex, high-dimensional data; instead, these methods focus on building models that capture the essential relationships between features and outcomes. By skillfully approximating these expectations, a system can reliably categorize new data points, even when faced with inherent noise or incomplete information, ultimately driving performance and robustness in classification tasks.
The inherent uncertainty of real-world data often manifests as noise or incompleteness, posing significant challenges to accurate classification. However, by grounding the classification framework in probability measures, the system gains a remarkable degree of robustness. Instead of relying on rigid, deterministic boundaries, the approach models the likelihood of an instance belonging to a particular class, effectively smoothing out the impact of erroneous or missing information. This probabilistic treatment allows the system to generalize effectively, even when confronted with data that deviates from the idealized training set. [latex]P(class|instance)[/latex], the probability of a class given an instance, becomes the core metric, enabling reliable classification where traditional methods might falter. Consequently, the use of probability measures doesn’t merely enhance accuracy; it fundamentally shifts the paradigm towards a more resilient and adaptable intelligent system.
Current approaches to building intelligent systems often leverage active learning, where algorithms strategically request labeled data to improve performance. However, the presented work champions a different, yet complementary, strategy: constructive approximation coupled with transfer learning. This method doesn’t rely on iteratively querying for labels; instead, it focuses on building robust models through careful approximation of underlying data distributions and intelligently transferring knowledge from previously learned tasks. This offers several potential advantages, including reduced labeling costs, faster training times, and improved generalization to novel situations – particularly when labeled data is scarce or expensive to obtain. The ability to construct accurate approximations and effectively transfer learning allows systems to adapt and perform reliably, potentially exceeding the capabilities of methods solely reliant on active data acquisition.
![Supervised learning aims to approximate a target function [latex]f[/latex] within a hypothesis space [latex]V_n[/latex] by minimizing empirical risk [latex]P^{\#}[/latex] to achieve a generalization error approximated by [latex] ilde{P}[/latex], ideally converging towards the optimal approximation [latex]P^{\*}[/latex].](https://arxiv.org/html/2602.17985v1/Figures/mlparadigm.png)
The pursuit of learning, as detailed in this exploration of manifold learning and transfer learning, inherently involves questioning established boundaries. This paper dissects the challenges of high dimensionality and data space discrepancies, effectively attempting to reverse-engineer the mechanisms of effective classification. It’s a process mirroring the hacker’s ethos – probing for weaknesses not to destroy, but to understand. As Barbara Liskov noted, “Programs must be right first before they are fast.” The meticulous focus on approximation theory and conditional expectations within the research isn’t merely about optimizing algorithms; it’s about ensuring the foundation is sound before scaling to more complex scenarios. Every exploit starts with a question, not with intent, and this research embodies that spirit – questioning the limits of current techniques to build a more robust understanding of data spaces.
Where Do We Go From Here?
The pursuit of learning without extensive training, as demonstrated by this work on manifold learning and data spaces, inevitably reveals the fragility of established assumptions. The field consistently stumbles upon scenarios where elegant theory clashes with the messy realities of high dimensionality. Current methods, while offering improvements in classification and transfer learning, often rely on idealized manifold structures-structures that, in practice, are rarely so cooperative. The true test lies not in achieving high accuracy on curated datasets, but in graceful degradation when confronted with genuinely novel, and likely corrupted, data.
A critical next step involves embracing, rather than mitigating, this inherent uncertainty. Approximation theory, at its core, is a constant negotiation between fidelity and computational cost. Future investigations should prioritize methods that explicitly model the limitations of the approximation, quantifying the risk of generalization. The focus shouldn’t be on ‘better’ approximations, but on honest ones – those that readily admit when they are venturing beyond the bounds of reliable prediction.
Ultimately, the most valuable advancements may not come from refining existing kernel methods or optimizing manifold embeddings. Instead, the greatest leaps forward will likely emerge from deliberately breaking the current framework-from seeking entirely new approaches to representing and reasoning about data, ones that acknowledge the fundamental impossibility of complete knowledge. The challenge, then, is not to learn more, but to learn how to fail more intelligently.
Original article: https://arxiv.org/pdf/2602.17985.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- Clash of Clans April 2026 Gold Pass Season introduces a Archer Queen skin
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Gold Rate Forecast
2026-02-24 07:31