Author: Denis Avetisyan
A new framework moves mechanistic interpretability research beyond qualitative narratives, demanding verifiable results through executable code.
Researchers introduce MechEvalAgent, an automated system for execution-grounded evaluation that enhances the reproducibility and scientific rigor of AI understanding.
Traditional peer review struggles to ensure research rigor amidst growing reproducibility crises and the increasing volume of AI-generated outputs. Addressing this, ‘The Story is Not the Science: Execution-Grounded Evaluation of Mechanistic Interpretability Research’ introduces MechEvalAgent, an automated framework that moves beyond narrative assessment by verifying code and data alongside research papers. This execution-grounded approach achieves over 80% agreement with human judges while identifying methodological flaws often missed by conventional review, particularly within the field of mechanistic interpretability. Could this signal a fundamental shift toward more robust and scalable scientific evaluation powered by AI agents?
Unmasking the Limits of Description
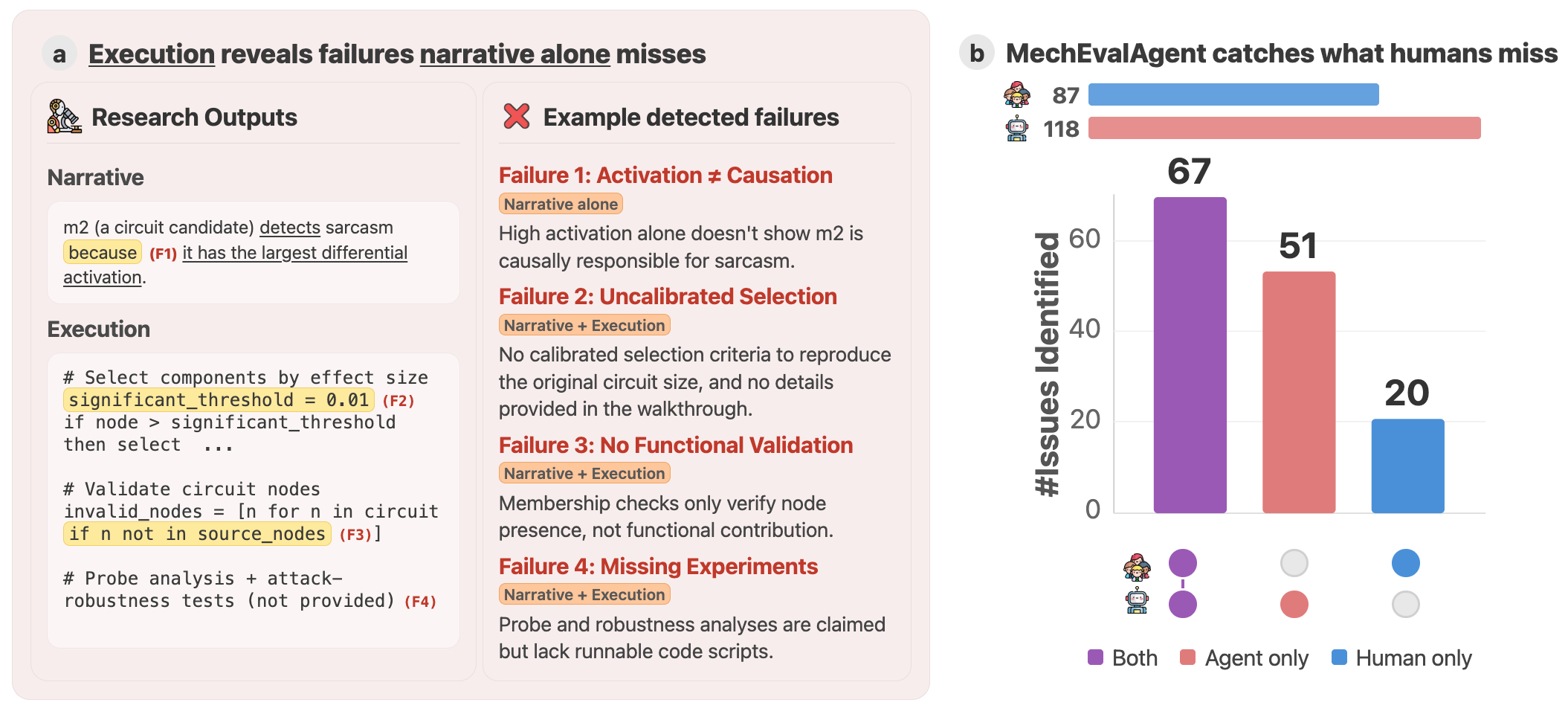
The conventional peer review process, often termed `Narrative-Alone Review`, faces growing limitations when evaluating modern research, particularly in fields demanding intricate functional verification like mechanistic interpretability. This established method primarily assesses the description of research – the logic, methodology, and claimed outcomes – but struggles to independently confirm whether the implemented details actually produce those results. As studies become more computationally complex, involving extensive codebases and nuanced algorithms, a disconnect can easily emerge between the stated intentions and the actual execution. This creates a vulnerability where subtle errors, logical inconsistencies, or unsubstantiated claims can persist undetected, as reviewers lack the means to directly examine and validate the underlying functionality – a critical issue when research relies on precise implementation to support its conclusions.
Traditional peer review, while foundational to scientific progress, possesses inherent limitations when evaluating modern research characterized by complex implementation. The reliance on narrative descriptions – detailing what a study intends to achieve – can fail to identify discrepancies between intention and actual execution. Subtle errors in code, flawed data processing pipelines, or unsubstantiated methodological claims may remain undetected, as the review process often lacks a direct verification of the underlying implementation. This vulnerability is particularly acute in fields like mechanistic interpretability, where nuanced computational results are paramount, and a disconnect between described theory and functional code can entirely invalidate conclusions, even if the narrative appears logically sound.
Research increasingly relies on computational implementation, yet traditional peer review often focuses solely on the description of methods, creating a critical vulnerability. When studies involve code, a divergence between the stated algorithm and its actual execution can render the entire investigation flawed, even if the theoretical framework appears sound. This discrepancy isn’t necessarily malicious; subtle errors in translation from concept to code, or unforeseen interactions between different software components, can invalidate results without being readily apparent from a textual review. Consequently, a study’s conclusions, despite appearing logically consistent on paper, may be based on a fundamentally incorrect implementation, highlighting the need for methods that directly assess the functionality of the code itself – a verification step beyond simply evaluating the narrative.
From Narrative to Execution: A New Standard of Validation
Execution-Grounded Evaluation establishes a methodology that supplements traditional narrative literature review by directly assessing research validity through code execution. This framework involves obtaining and running the implementations associated with published research-typically via publicly available repositories-and verifying that the reported results can be replicated using the provided code. The process focuses on functional correctness, moving beyond assessing the claims made in a paper to objectively determining whether the underlying code actually produces the stated outcomes. This approach provides a complementary, empirical layer to the peer review process, enhancing the reliability and trustworthiness of scientific findings by confirming implementation viability.
Reproducibility, as measured through execution-grounded evaluation, establishes an objective metric for verifying the consistency of research findings. This assessment moves beyond reliance on reported results and directly tests if the same code, when executed independently, yields identical outcomes. A successful reproduction confirms the validity of the implementation and reduces the potential for errors or biases introduced during the original research process. The ability to consistently obtain the reported results is crucial for building confidence in the research and facilitates further development and application of the findings. This process differs from traditional peer review, which focuses on the logic and presentation of the research, by providing empirical evidence of the code’s functional correctness.
Traditional research evaluation relies heavily on narrative reviews, assessing the claims made within publications; however, this approach does not inherently validate the functional correctness of the underlying implementations. Execution-Grounded Evaluation addresses this limitation by directly testing submitted code, thereby shifting the focus from reported results to demonstrable functionality. This process confirms whether the claimed research outcomes are actually achievable through the provided implementation, establishing a clear distinction between stated intentions and operational reality. Successful code execution serves as objective evidence, increasing confidence in research findings and providing a more reliable basis for building upon prior work. This functional verification is crucial for identifying potential errors, inconsistencies, or irreproducibility issues that might be overlooked in purely narrative assessments.
![Evaluation stability, measured by agreement across three independent runs, varied by repository type, demonstrating near-perfect consistency [latex]3/3[/latex] for replication tasks but decreased to [latex]2/3[/latex] agreement for open-ended and human-written repositories.](https://arxiv.org/html/2602.18458v1/x37.png)
Automated Scrutiny: The Rise of MechEvalAgent
Automated evaluation tools, such as MechEvalAgent, address the limitations of manual research review by providing a scalable and repeatable assessment process. Traditional review methods are constrained by human resource availability and introduce potential inconsistencies between evaluations. MechEvalAgent utilizes programmatic analysis to systematically examine research papers, enabling the assessment of a significantly larger volume of work than is feasible with manual review. This scalability is crucial for rapidly evolving fields where timely feedback and validation are essential. By automating key aspects of the review process, these tools reduce bottlenecks and accelerate the dissemination of reliable research findings.
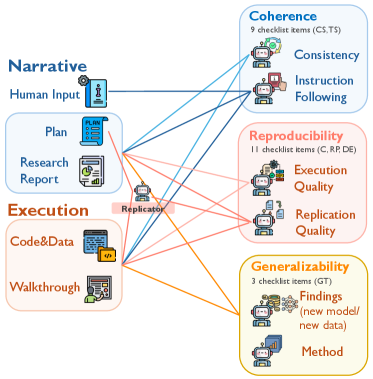
MechEvalAgent utilizes LLM-based agents to perform multi-dimensional research assessment by integrating both narrative analysis and automated code verification. The system doesn’t rely solely on code execution; it also processes the research paper’s text to understand stated goals and intended functionality. This combined approach allows MechEvalAgent to evaluate research contributions across multiple dimensions, including functional correctness, adherence to stated objectives, and the logical connection between claims and implementation. Automated code execution confirms functionality, while narrative checks ensure the code’s purpose aligns with the paper’s description and that results are appropriately contextualized within the research narrative.
MechEvalAgent extends evaluation beyond simple reproducibility to encompass research Coherence and Generalizability. Coherence assessment verifies the internal consistency between stated research objectives, the implemented methodology, and the reported results. Generalizability evaluation determines the extent to which findings apply beyond the specific conditions of the study. Independent evaluation confirms MechEvalAgent achieves greater than 80% agreement with human expert assessments across all evaluated task categories, indicating a high degree of reliability in its automated evaluations.
![MechEvalAgent() provides specific, execution-based rationales for identifying issues in both research-agent ([latex]R[/latex]) and human-written ([latex]H[/latex]) repositories, contrasting with the more generalized explanations typically offered by human experts.](https://arxiv.org/html/2602.18458v1/plots/others/candidates_12983796.png)
Beyond Verification: Reclaiming Rigor in the Pursuit of Knowledge
The pursuit of robust research increasingly benefits from execution-grounded evaluation, a methodology that moves beyond simply stating claims to actively verifying them through computational testing. Tools like MechEvalAgent exemplify this approach, automatically assessing the validity of research outputs by ‘executing’ the proposed logic and identifying inconsistencies or errors. This isn’t merely about error detection; it cultivates a culture where accountability is baked into the research process itself. By demanding demonstrable evidence supporting claims, the field actively discourages reliance on unsubstantiated assertions and promotes a higher standard of rigor. Consequently, the integration of such tools is expected to dramatically improve the reliability of findings, particularly in complex domains where manual verification is impractical, and ultimately accelerate the pace of genuine scientific advancement.
A critical advancement in research quality stems from the explicit verification of statistical significance and reproducibility, actively mitigating the propagation of flawed or unsubstantiated claims. Recent evaluations, leveraging tools like MechEvalAgent, demonstrate a substantial capacity to identify methodological weaknesses; specifically, the agent achieves an 80% failure rate in pinpointing issues related to statistical significance, as measured by the CS5 metric. This indicates a considerable potential to systematically challenge research findings and encourage more robust experimental design. By proactively flagging concerns about statistical validity, such automated evaluation shifts the focus toward rigorous methodology and builds a more reliable foundation for scientific progress, fostering greater confidence in published results.
The pursuit of robust research practices is fundamentally reshaping the landscape of artificial intelligence, particularly within the complex domain of mechanistic interpretability. A move toward execution-grounded evaluation, exemplified by tools like MechEvalAgent, isn’t simply about identifying errors; it’s about establishing a more trustworthy foundation for scientific advancement. Validation of this approach comes from the high degree of agreement – 89.4% – between MechEvalAgent’s assessments and those of human experts, as determined through majority voting. This strong correlation confirms the tool’s validity and suggests that automated verification can reliably assess the rigor of research claims, ultimately accelerating progress by ensuring that future work builds upon substantiated and reproducible findings.

The pursuit of mechanistic interpretability, as detailed in the paper, demands a rigorousness often lost in solely narrative-driven analysis. One must not simply describe how a system functions, but demonstrably prove it through execution. This echoes Ada Lovelace’s sentiment: “The Analytical Engine has no pretensions whatever to originate anything.” The paper’s MechEvalAgent embodies this principle; it doesn’t speculate on a model’s internal workings, it actively tests them. By grounding evaluation in executable code, the framework seeks to move beyond mere storytelling about AI behavior and towards a genuine comprehension of its mechanisms – a reverse-engineering of reality, if you will – precisely what Lovelace hinted at regarding the Engine’s capabilities and limitations.
What’s Next?
The introduction of MechEvalAgent isn’t about achieving a final answer; it’s about refining the questions. For too long, the field of mechanistic interpretability has operated with a narrative bias-stories about what a neural network should be doing, rather than what it demonstrably is doing. This framework isn’t intended to validate those narratives, but to expose their fragility. The gaps revealed by execution-grounded evaluation are not bugs to be patched, but invitations to disassemble, probe, and truly understand the underlying code.
The limitations are, of course, inherent. Any automated framework is only as comprehensive as its test suite. The true challenge lies in devising evaluations that aren’t themselves subtly influenced by prior assumptions-a circularity that plagues any attempt to reverse-engineer a complex system. Future work must focus on building evaluation sets that actively seek counterexamples, pushing the boundaries of what’s considered ‘interpretable’ and exposing the hidden assumptions baked into current approaches.
Ultimately, this isn’t about building better AI, but about reading the source code of reality. The network isn’t the thing to be understood; it’s a proxy. MechEvalAgent is a small step toward a larger goal: a rigorous, executable understanding of the principles governing intelligence, artificial or otherwise. The story, it turns out, is rarely the science.
Original article: https://arxiv.org/pdf/2602.18458.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- Clash of Clans April 2026 Gold Pass Season introduces a Archer Queen skin
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
2026-02-25 00:12