Author: Denis Avetisyan
A new platform leverages the power of large language models and multi-agent systems to automate complex linguistic tasks, offering a transparent and reproducible approach to annotation.
![The LinguistAgent architecture establishes a framework for reasoning about language through the formalization of linguistic structures, enabling the agent to decompose complex sentences into their constituent parts and derive meaning based on underlying grammatical relationships - a process fundamentally rooted in the principles of compositional semantics, akin to evaluating [latex] f(g(x)) [/latex] where <i>f</i> represents semantic interpretation and <i>g</i> syntactic parsing.](https://arxiv.org/html/2602.05493v1/x1.png)
LinguistAgent is a no-code, multi-agent platform designed for automated linguistic annotation, with a focus on metaphor identification using LLMs and Retrieval-Augmented Generation.
Despite the theoretical promise of Large Language Models (LLMs), applying them to complex, nuanced tasks in the Humanities and Social Sciences-such as linguistic annotation-remains challenging. This paper introduces LinguistAgent: A Reflective Multi-Model Platform for Automated Linguistic Annotation, a novel, no-code platform employing a dual-agent workflow to simulate peer review and enhance the reliability of automated annotation, demonstrated here with the task of metaphor identification. By supporting comparative experimentation across prompting strategies-including prompt engineering, retrieval-augmented generation, and fine-tuning-LinguistAgent achieves real-time, token-level evaluation against human gold standards. Will this reflective, multi-model approach unlock new avenues for scalable and transparent linguistic analysis?
The Annotation Bottleneck: A Challenge to Linguistic Precision
The pursuit of increasingly sophisticated natural language processing (NLP) models fundamentally relies on vast quantities of meticulously labeled linguistic data, yet acquiring this data presents a significant hurdle. Traditional annotation methods, requiring human experts to painstakingly categorize and interpret text, are inherently slow and resource-intensive, creating a bottleneck in model development. The cost isn’t merely financial; the time required to annotate datasets large enough to train robust models delays progress across numerous NLP applications. This limitation particularly impacts projects demanding specialized knowledge, such as sentiment analysis in nuanced contexts or the identification of figurative language, where the expertise required further constrains scalability and drives up expenses. Consequently, researchers are actively exploring strategies to alleviate this annotation bottleneck, seeking a balance between data volume, annotation quality, and economic feasibility.
The pursuit of accurately labeled linguistic data frequently encounters a fundamental trade-off between human precision and computational scalability. While manual annotation offers a degree of subtlety crucial for discerning complex linguistic phenomena – such as the non-literal meaning inherent in metaphor – it is inherently susceptible to inconsistencies stemming from individual annotator biases and interpretations. Conversely, automated annotation techniques, though significantly faster and more cost-effective, often struggle to capture the nuanced contextual understanding required for tasks demanding subjective judgment. These systems may misinterpret figurative language or fail to recognize the subtle cues that signal underlying meaning, leading to errors that propagate through subsequent analyses and model training. Consequently, achieving reliable large-scale linguistic analysis necessitates innovative approaches that bridge this gap, potentially through methods that combine the strengths of both human insight and machine efficiency.
Current linguistic annotation techniques face a fundamental trade-off between efficiency and comprehensive understanding. While rapid, automated methods can process vast datasets, they frequently sacrifice the subtle contextual awareness necessary for tasks demanding nuanced interpretation – such as identifying figurative language or resolving ambiguity. Conversely, meticulous manual annotation, though yielding high accuracy and detailed rationales, is inherently slow and costly, limiting the scale of analysis. This creates a critical bottleneck: achieving both speed and precision requires capturing not just what is annotated, but why – a layer of reasoning that existing systems often struggle to integrate without significantly increasing processing time and resource demands. Consequently, the field seeks innovative approaches that can effectively balance these competing priorities, enabling large-scale linguistic analysis without compromising the depth of insight.
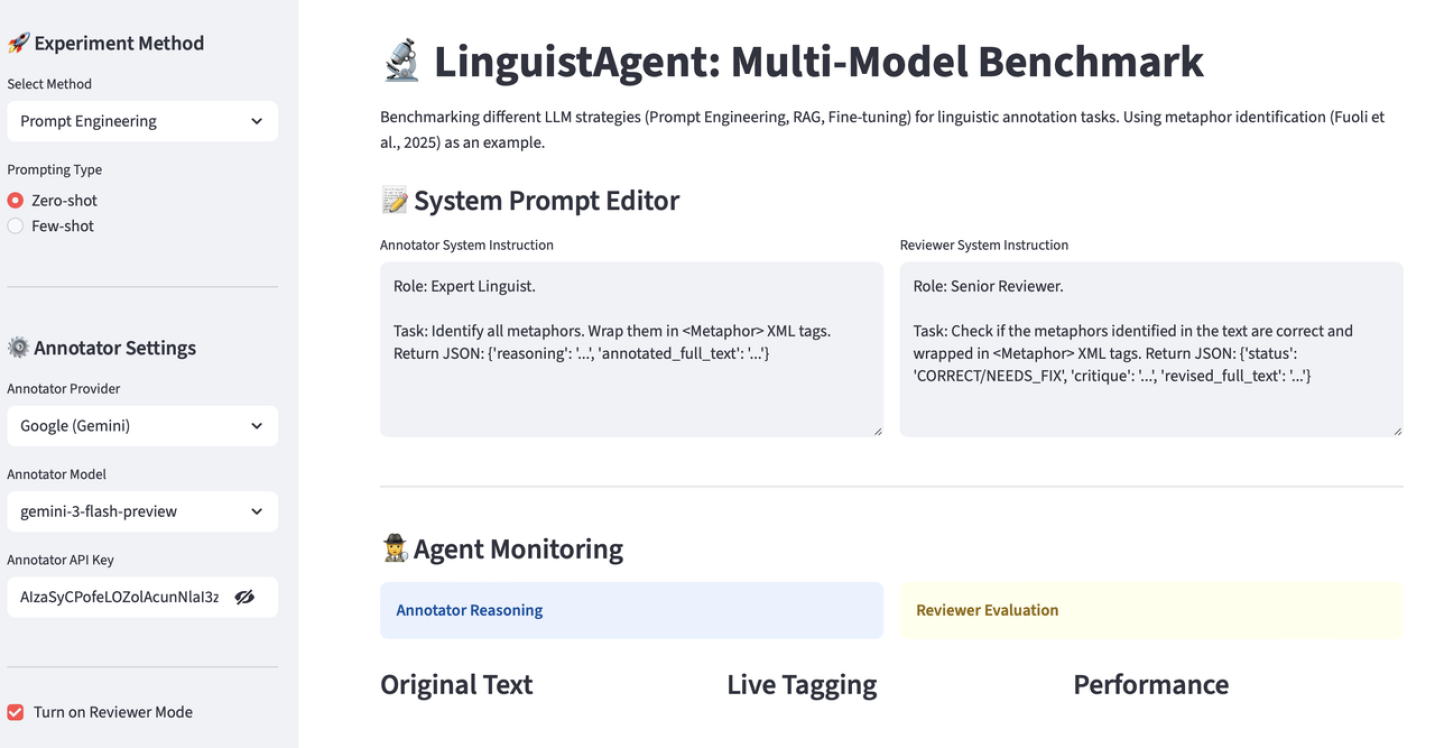
LinguistAgent: A System for Enhanced Annotation Through Reflection
LinguistAgent employs a reflective multi-agent workflow consisting of an Annotator Agent and a Reviewer Agent to enhance annotation reliability and reduce the occurrence of hallucinations. The Annotator Agent initially processes input data and generates preliminary annotations. These annotations are then passed to the Reviewer Agent, which critically evaluates the initial output, identifies potential errors or inconsistencies, and provides feedback or corrections. This iterative process of annotation and review allows for self-correction and refinement, leading to improved annotation quality and a demonstrable reduction in the generation of factually incorrect or unsupported outputs, commonly referred to as hallucinations, within the annotation process.
LinguistAgent utilizes Native JSON Mode to enforce a structured reasoning process during annotation. This mode requires the system to output all intermediate reasoning steps and the final annotation as a valid JSON object. By explicitly defining the reasoning chain in a machine-readable format, the process becomes fully transparent, allowing for detailed inspection of how each annotation was derived. This structured output also facilitates auditability, enabling users to trace the decision-making process and verify the accuracy and consistency of the annotations. The use of JSON ensures data integrity and simplifies programmatic access to the reasoning history for further analysis or debugging.
LinguistAgent utilizes Streamlit to construct its user interface, providing a dynamic and interactive frontend for managing the annotation pipeline. This implementation allows users to directly engage with the multi-agent system, submitting text for annotation and monitoring the workflow between the Annotator and Reviewer Agents. The Streamlit interface facilitates real-time visualization of the annotation process, including the reasoning chains generated in Native JSON Mode, and enables users to provide feedback or initiate corrections as needed. The dynamic nature of the interface ensures responsiveness and adaptability to various input sizes and annotation complexities, contributing to a streamlined user experience.

Augmenting Annotation with RAG and Advanced Models
The annotation process is improved through the implementation of Retrieval-Augmented Generation (RAG). This technique allows both the Annotator and Reviewer Agents to dynamically access and incorporate information from external codebooks during operation. Rather than relying solely on pre-trained knowledge, the agents retrieve relevant data from these codebooks to inform their annotations and reviews, increasing the contextual accuracy and consistency of the labeling process. This external knowledge integration is performed on a per-task basis, enabling adaptation to specialized domains or evolving requirements defined within the codebooks.
LinguistAgent’s architecture is designed to integrate with large language models (LLMs) including Gemini 3 and Qwen3. This integration allows the agent to leverage the advanced reasoning and contextual understanding capabilities inherent in these models. Specifically, the LLMs facilitate improved interpretation of complex linguistic nuances within the annotation tasks, moving beyond simple keyword matching to grasp semantic meaning and intent. This capability is crucial for handling ambiguous or multifaceted data, leading to more accurate and consistent annotation results. The agent manages input and output to these LLMs, enabling a scalable solution for incorporating powerful AI into the annotation workflow.
Prompt engineering techniques are applied to maximize the in-context learning potential of large language models used within LinguistAgent. This involves carefully crafting input prompts to guide the model’s reasoning and ensure it effectively utilizes provided context from codebooks and the input data. Specifically, prompts are designed to elicit desired annotation behaviors, such as specifying the format of the output, providing examples of correct annotations, and explicitly instructing the model to prioritize certain aspects of the input. Optimization focuses on minimizing ambiguity and maximizing the signal-to-noise ratio within the prompt, leading to demonstrable improvements in annotation consistency and accuracy as measured against established quality metrics.
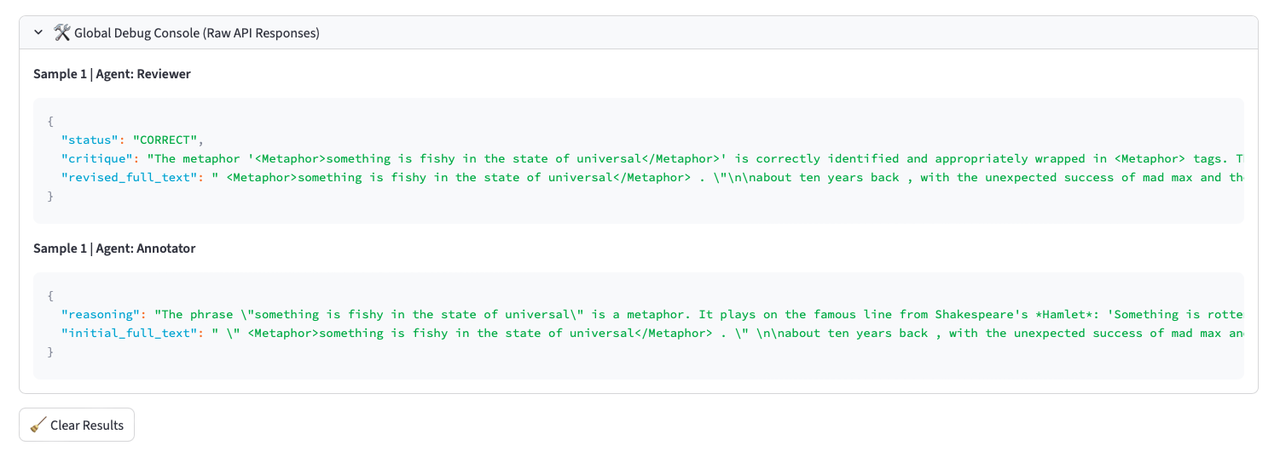
Rigorous Evaluation: Quantifying Annotation Performance
Token-level evaluation assesses annotation accuracy by comparing predicted tags to ground truth labels for each individual token. This granular approach enables the calculation of Precision, which represents the proportion of correctly identified positive instances among all instances predicted as positive. Recall, conversely, measures the proportion of correctly identified positive instances among all actual positive instances. The F1 Score is then calculated as the harmonic mean of Precision and Recall, providing a balanced measure of the system’s overall accuracy: [latex]F1 = 2 (Precision Recall) / (Precision + Recall)[/latex]. Utilizing these metrics at the token level allows for detailed error analysis and targeted improvements to the annotation process.
The token-level evaluation framework facilitates a detailed analysis of system performance beyond aggregate scores. By assessing annotation accuracy at the individual token level, the framework pinpoints specific linguistic patterns or contextual features where the system consistently succeeds or fails. This granular insight allows for targeted improvements; for example, consistently misidentified token types can inform retraining data selection or algorithm adjustments. Furthermore, the framework enables the identification of systemic biases or edge cases that might be masked by overall performance metrics, leading to a more robust and reliable system through iterative refinement of both the annotation guidelines and the underlying model.
Evaluation of LinguistAgent’s metaphor identification capabilities, conducted through an ‘Annotate-Review-Evaluate’ cycle, indicates substantial performance gains with the inclusion of a review stage. Quantitative results demonstrate that the ‘Reviewer Mode’, which incorporates human-in-the-loop validation of initial annotations, consistently achieves higher Precision, Recall, and F1 scores compared to a baseline ‘Annotator-only’ mode. This improvement highlights the efficacy of incorporating a review process to refine annotations and reduce errors in metaphor identification, suggesting a measurable benefit from the combined human and AI approach.

Future Directions: Toward Adaptable and Intelligent Annotation
LinguistAgent distinguishes itself through a deliberately modular architecture, facilitating the incorporation of diverse fine-tuning paradigms directly into the annotation process. This design choice empowers users to move beyond the system’s pre-trained capabilities and tailor it precisely to the nuances of specialized domains – be it legal text, biomedical literature, or social media analysis. By seamlessly integrating techniques like LoRA or adapter modules, the agent’s annotation behavior can be refined with limited computational resources and data, effectively addressing domain-specific terminology, stylistic conventions, and annotation guidelines. The result is a highly adaptable system capable of delivering consistently accurate and relevant annotations across a broad spectrum of linguistic applications, moving beyond a one-size-fits-all approach to natural language processing.
LinguistAgent’s core architecture isn’t limited to discerning metaphorical language; its flexible design readily accommodates a diverse range of natural language processing challenges. The system’s modularity allows for adaptation to tasks such as sentiment analysis, named entity recognition, and relation extraction with minimal modification. This broad applicability stems from the agent’s ability to be re-configured for different annotation schemes and data types, effectively transforming it into a versatile tool for any NLP pipeline. Consequently, LinguistAgent represents a significant step toward a unified framework capable of streamlining annotation processes across multiple linguistic domains, potentially reducing the need for task-specific tools and fostering greater consistency in NLP research.
Ongoing development prioritizes a substantial broadening of the agent’s functional skillset, moving beyond current capabilities to encompass more nuanced linguistic analyses and annotation tasks. Researchers are actively investigating innovative methods for integrating diverse knowledge sources – including external databases and pre-trained language models – directly into the annotation pipeline. This pursuit aims to enhance the agent’s reasoning abilities, enabling it to not merely identify linguistic features, but to understand their contextual significance and make more informed annotation decisions, ultimately fostering a more robust and intelligent system for complex NLP challenges.
The development of LinguistAgent underscores a principle echoed by Henri Poincaré: “Mathematics is the art of giving reasons.” This platform isn’t merely about achieving functional metaphor identification; it’s about establishing a provable workflow. The system’s reflective architecture, enabling iterative refinement of prompts and agents, directly embodies this mathematical rigor. By prioritizing transparency and replicability, LinguistAgent moves beyond empirical success – ‘it works on these tests’ – toward a demonstrably correct solution. The multi-agent system, therefore, isn’t simply automating a task, but formalizing the reasoning behind linguistic annotation, aligning with Poincaré’s view of mathematics as the bedrock of true understanding.
The Horizon of Automated Linguistics
The pursuit of automated linguistic annotation, as exemplified by platforms such as LinguistAgent, reveals a fundamental tension. While scaling annotation is achievable through multi-agent systems and large language models, the elegance of a solution cannot be judged solely on throughput. The current reliance on prompt engineering, however sophisticated, remains a pragmatic workaround, not a principled foundation. A truly robust system demands a move beyond empirical success to provable correctness – a demonstration that the identified metaphors, or any linguistic feature, are identified because of inherent structural properties, not simply because a model was trained to mimic human labeling.
The transparency afforded by a reflective workflow is valuable, yet insufficient. Reproducibility, while necessary, addresses only the symptom of opacity, not the disease. Future work must focus on formalizing the rules governing linguistic interpretation – a difficult task, certainly, but one that would elevate this field from applied empiricism to a genuine mathematical science. The current emphasis on Retrieval-Augmented Generation (RAG) feels suspiciously like externalizing intelligence, a delegation of reasoning rather than an internalization of linguistic principles.
Ultimately, the true measure of progress will not be the quantity of annotated data, but the quality of the underlying theory. A system that can explain why a phrase is metaphorical, grounded in demonstrable linguistic axioms, would represent a genuine leap forward – a harmony of symmetry and necessity, where every operation serves a logically defensible purpose.
Original article: https://arxiv.org/pdf/2602.05493.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Gold Rate Forecast
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- ‘Project Hail Mary’s Soundtrack: Every Song & When It Plays
- All Mobile Games (Android and iOS) releasing in April 2026
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- Top 5 Best New Mobile Games to play in April 2026
2026-02-08 10:48