Author: Denis Avetisyan
As conversational AI systems become increasingly complex, ensuring their reliability requires a shift towards systematic and automated quality assurance.
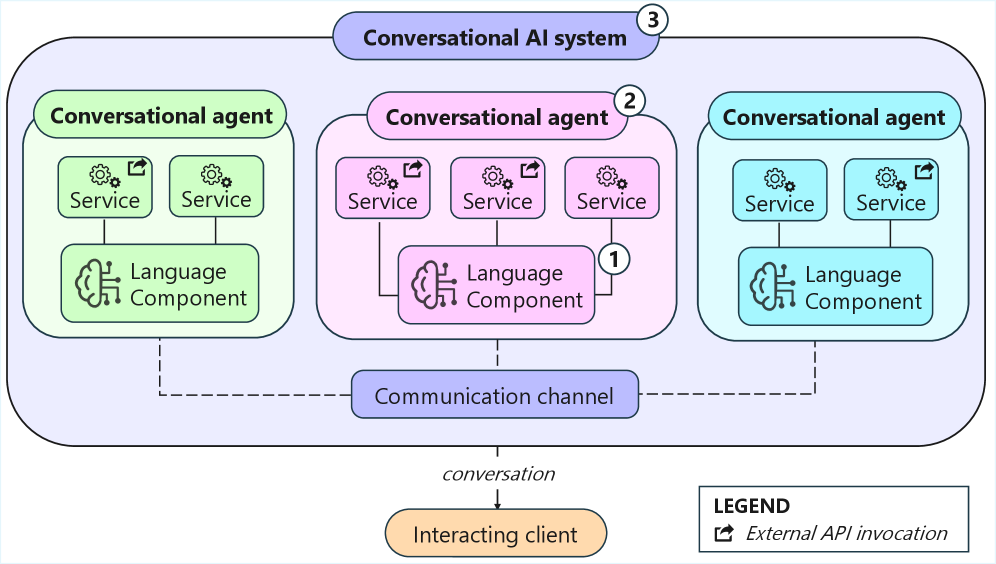
This review proposes a multi-level testing framework spanning service interaction, individual agents, and complete multi-agent systems to improve the trustworthiness of conversational AI.
Despite the increasing sophistication of conversational AI, robust testing methodologies have struggled to keep pace with the unique challenges of interactive, AI-driven dialogues. This Ph.D. thesis, ‘Multi-Level Testing of Conversational AI Systems’, addresses this gap by proposing a novel testing framework focused on validating conversational AI components at varying levels of granularity-from service interactions to multi-agent implementations. The core contribution lies in automated strategies designed to improve the trustworthiness and reliability of these complex systems through multi-level assessment. Will these approaches pave the way for more dependable and scalable conversational AI deployments in real-world applications?
The Inevitable Expansion of Conversation
Conversational artificial intelligence is rapidly transitioning from automating basic queries to facilitating nuanced, multi-turn interactions. Initially confined to tasks like setting alarms or providing weather updates, these systems now power increasingly sophisticated applications-from virtual assistants handling complex travel arrangements to AI-driven tutors adapting to individual student needs. This expansion isn’t merely about handling more tasks, but about managing interactions that require contextual understanding, reasoning, and even emotional intelligence. The deployment of these complex conversational systems is being driven by advances in natural language processing and machine learning, coupled with a growing demand for personalized and efficient user experiences across various sectors, including customer service, healthcare, and education.
Modern conversational AI doesn’t simply understand language; it orchestrates a complex dance between linguistic interpretation and practical action. A core architecture relies on a ‘Language Component’ – the system’s ability to parse, interpret, and generate human language – working in tandem with ‘backend Services’ that perform the actual tasks requested by a user. When a user asks a question or makes a request, the Language Component translates it into a structured format understandable by these Services – which might include databases, APIs, or other software systems. The Services then execute the request, and the Language Component transforms the resulting data back into a natural language response. This interplay is fundamental; without a seamless connection between linguistic understanding and functional execution, even the most sophisticated language models remain incapable of truly helpful interaction.
As conversational AI evolves from basic chatbots to sophisticated interactive systems, ensuring their dependability and positive user experience necessitates advanced testing procedures. Current methods often struggle to keep pace with the intricate interplay between language understanding, backend services, and multi-agent collaboration. This research addresses this challenge by proposing a novel framework for automated testing, specifically designed for complex conversational systems. The core of this work focuses on defining strategies at three crucial levels: the individual service interaction, the agent’s overall behavior, and the coordination between multiple agents. By systematically evaluating performance at each of these levels, the thesis aims to establish a robust and scalable approach to quality assurance, ultimately fostering greater trust and broader adoption of these increasingly prevalent technologies.
The Combinatorial Shadow of Multi-Agent Systems
Multi-Agent Conversational AI systems present escalated testing difficulties compared to single-agent systems due to the combinatorial explosion of possible interaction states. Each agent introduces its own behavioral possibilities, and the interdependence between agents creates a vastly larger solution space to validate. Testing must account for not only individual agent performance but also emergent behaviors arising from agent-to-agent communication and coordination. Factors such as turn-taking, negotiation, conflict resolution, and shared knowledge representation all contribute to this increased complexity, requiring test cases that thoroughly explore these inter-agent dynamics and potential failure modes. The non-deterministic nature of these interactions also demands a higher volume of test runs to achieve statistically significant results and ensure system robustness.
Evaluating conversational AI systems comprised of multiple interacting agents necessitates a shift away from isolated, single-agent testing. Traditional methods, which assess individual agent performance via metrics like intent recognition or response accuracy, fail to capture emergent behaviors arising from agent coordination and communication. System-level testing focuses on holistic performance, measuring factors such as task completion rate, dialogue efficiency, and the avoidance of conflicting information across agents. This requires defining test cases that simulate multi-agent interactions and developing metrics to quantify the system’s ability to function cohesively as a unified conversational entity, rather than a collection of independent components.
Multi-Agent System Testing (MAST) moves beyond evaluating individual conversational AI agents in isolation to assess the emergent behaviors resulting from their interactions. This methodology focuses on verifying the system’s ability to achieve defined goals through coordinated action, examining factors like task completion rates, efficiency of communication, and resolution of conflicts between agents. MAST requires the definition of system-level Key Performance Indicators (KPIs) that measure collective performance, and often involves simulating diverse interaction scenarios with varying agent configurations and environmental conditions. Evaluation metrics extend beyond individual agent accuracy to include measures of coherence, consistency, and the overall quality of the multi-agent dialogue or task execution.
Comprehensive testing of multi-agent conversational AI systems necessitates robust orchestration and AI planning capabilities to manage the expanded state space and interaction complexity. Traditional testing methods are inadequate for evaluating system-level behaviors arising from agent coordination; therefore, automated test workflow definition and execution are critical. This work addresses the need for testing improvements across all layers of conversational AI, including natural language understanding, dialogue management, and response generation, by focusing on techniques that enable the creation of scalable and verifiable test suites. These techniques aim to move beyond isolated agent validation towards holistic system assessment, encompassing inter-agent communication, task completion, and overall system stability.
Probing for Failure: Diverse Techniques for Robustness
Service-interaction testing focuses on validating the data exchange between language models and external services, such as databases, APIs, and other backend systems. This testing is critical because language components rarely operate in isolation; they frequently require data retrieval, processing, or storage through these services. Thorough service-interaction tests confirm that the language model correctly formats requests, handles responses (including errors and edge cases), and maintains data integrity throughout the interaction. Failures in this area can manifest as incorrect information presented to the user, service outages, or security vulnerabilities, making it a core component of overall system reliability and functionality.
API coverage and parameter coverage are key metrics used to quantify the extent to which service testing exercises the available functionality. API coverage measures the percentage of accessible API endpoints that are invoked during testing, indicating how much of the service’s public interface is being validated. Parameter coverage, a more granular metric, assesses the range of input values-including valid and invalid inputs-used to test each API parameter. A high parameter coverage score demonstrates a more thorough evaluation of how the service handles diverse input conditions and edge cases, providing greater confidence in its robustness. These metrics are typically expressed as percentages and are valuable for identifying gaps in test suites and guiding the creation of more comprehensive tests.
Techniques such as Charm and BoTest improve the robustness of language model testing by automatically generating variations of existing test cases. These methods operate by substituting words and phrases with paraphrases and synonyms, effectively increasing lexical diversity without altering the core intent of the test. LLM-based test generation further expands on this principle, leveraging large language models to create novel test inputs that express the same meaning using different wording. This approach helps to identify vulnerabilities arising from sensitivity to specific phrasing and ensures the system responds consistently to semantically equivalent inputs, thereby improving overall system resilience.
Mutation testing systematically introduces small, syntactically valid faults – or “mutations” – into the source code to assess the quality of existing test suites. These mutations represent common programming errors. A test suite is considered effective if it can “kill” these mutants – meaning, the tests fail when executed against the mutated code, demonstrating that the tests can detect the introduced faults. The percentage of killed mutants, known as the mutation score, serves as a quantifiable metric for test suite effectiveness. In this work, mutation testing is employed as a primary comparative metric to evaluate the robustness of different testing techniques and their ability to identify vulnerabilities.
The Inevitable Ecosystem: Beyond Isolated Tests
The creation of effective conversational AI relies on a diverse toolkit, and platforms like Botium, RASA, and Dialogflow are central to this process. These resources don’t simply build chatbots; they provide comprehensive environments for developing, training, and – crucially – rigorously testing each component. Botium, for example, specializes in automated testing, ensuring conversations flow as intended across various channels, while RASA and Dialogflow offer frameworks for building the core conversational logic and natural language understanding. By leveraging these tools, developers can move beyond basic functionality tests to simulate realistic user interactions, identify potential failure points, and refine the AI’s ability to handle nuanced requests – ultimately leading to more reliable and engaging conversational experiences.
The creation of a dependable conversational AI experience demands more than simply assembling components; it requires a strategically integrated testing framework. Developers are increasingly combining tools like Botium – designed for end-to-end chatbot testing – with the underlying frameworks that power these interactions, such as RASA and Dialogflow. This synergy isn’t merely about checking for functional errors, but about employing advanced techniques that probe the system’s resilience and adaptability. Through techniques like metamorphic testing, which verifies relationships between inputs and outputs even without a complete specification, developers can build confidence in an AI’s ability to handle unexpected or nuanced user queries. The resulting ecosystem prioritizes reliability, ensuring consistent and positive interactions, ultimately fostering greater user trust and accelerating the broader adoption of conversational AI technologies.
A comprehensive testing strategy is demonstrably linked to enhanced conversational AI performance and user satisfaction. By prioritizing not only functional correctness but also the overall conversational flow, developers cultivate systems that feel more natural and intuitive to interact with. This, in turn, fosters increased user trust-a critical factor for the widespread adoption of AI-driven interfaces. The efficacy of this holistic approach is rigorously assessed through metrics like Code Coverage, which measures the extent of code exercised during testing, and, crucially, Conversational Coverage, which evaluates the breadth of dialogue scenarios validated. High scores in both areas signify a robust and reliable system, primed for positive user engagement and broader implementation across diverse applications.
When defining comprehensive tests for conversational AI proves challenging due to incomplete or ambiguous specifications, Metamorphic Testing offers a valuable alternative. This technique doesn’t attempt to verify against a definitive ‘correct’ answer, but instead focuses on relationships between different inputs and their corresponding outputs. By identifying ‘metamorphic relations’ – rules stating how changes in input should predictably alter the output – the system’s behavior is assessed for consistency. For example, if a chatbot provides a weather forecast for London, a metamorphic relation dictates it should also respond to a query for the weather in the same city phrased differently. This approach is particularly powerful for complex AI systems where exhaustive testing is impractical, complementing traditional methods by uncovering discrepancies that might otherwise go undetected and increasing confidence in the AI’s robustness even with limited specification.
The pursuit of robust conversational AI, as detailed in this exploration of multi-level testing, isn’t about achieving perfect stasis; it’s about anticipating inevitable divergence. The system won’t remain neatly defined; its interactions will breed unforeseen behaviors. As G. H. Hardy observed, “The essence of mathematics lies in its freedom.” This freedom translates directly to the dynamism of these complex systems. Automated testing, spanning service interactions to multi-agent dynamics, doesn’t prevent failure-it illuminates the pathways of evolution, revealing how the system will reshape itself under stress. Long stability isn’t the goal; understanding the nature of the coming transformation is.
What’s Next?
The pursuit of automated testing for conversational AI, as outlined in this work, reveals less a path to flawless systems and more a carefully charted route toward predictable failure. The tiered approach-service interaction, agent behavior, multi-agent dynamics-does not solve the problem of trust; it merely localizes the inevitable points of collapse. A system that passes every test is, by definition, a system that has not encountered sufficient complexity to reveal its inherent brittleness.
Future work will undoubtedly refine test generation, expand metamorphic relations, and explore more sophisticated adversarial techniques. Yet, such improvements are palliative, not curative. The true challenge lies in acknowledging that conversational AI, as a complex adaptive system, is fundamentally resistant to complete verification. The focus should shift from proving correctness to understanding the contours of failure, embracing graceful degradation as a design principle.
Perfection, in this domain, leaves no room for people-for the nuanced interpretation, the contextual awareness, the charitable misinterpretation that defines genuine conversation. The next generation of testing frameworks should not aim to eliminate error, but to surface it, to make it legible, and to empower human operators to navigate the inevitable imperfections with skill and empathy.
Original article: https://arxiv.org/pdf/2602.03311.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- All Mobile Games (Android and iOS) releasing in April 2026
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- Limbus Company 2026 Roadmap Revealed
2026-02-04 18:00