Author: Denis Avetisyan
A new approach combines the power of artificial intelligence with materials science to autonomously develop perovskite solar cell compositions, accelerating the pace of innovation in renewable energy.
![The PVK-LLM framework advances scientific discovery through an iterative, closed-loop active learning process, leveraging a knowledge base constructed from scientific literature to refine a language model across three stages-domain knowledge acquisition ([latex]Stage \, I[/latex]), knowledge grounding with experimental data ([latex]Stage \, II[/latex]), and structured knowledge graph creation ([latex]Stage \, III[/latex])-thereby enabling autonomous design, verification, and optimization cycles within both simulated and laboratory environments, as demonstrated by a corpus of perovskite literature spanning from 2018 to 2025.](https://arxiv.org/html/2602.04914v1/x1.png)
Researchers present PVK-LLM, a domain-knowledge-guided large language model coupled with Bayesian optimization, achieving a 26.0% power conversion efficiency in perovskite solar cells and demonstrating a path towards self-driving materials discovery.
Despite the rapid progress in materials discovery, translating promising theoretical designs into high-performing real-world devices remains a significant challenge. This is addressed in ‘From Literature to Lab: Closed-Loop Advancement of Perovskite Solar Cells via Domain Knowledge Guided LLM’, which introduces a novel framework, PVK-LLM, that synergistically combines large language models with Bayesian optimization to autonomously design perovskite solar cell recipes. Notably, this approach yielded a champion power conversion efficiency exceeding 26.0% – a result approaching world records – through an AI-proposed, previously unreported four-component passivation recipe. Could this closed-loop, domain-knowledge-guided methodology accelerate materials discovery beyond perovskites, paving the way for self-driving innovation in materials science?
The Algorithmic Imperative: Optimizing Perovskite Structures
Perovskite solar cells represent a potentially revolutionary advancement in renewable energy, boasting efficiencies that rival traditional silicon-based technologies. However, realizing the full potential of these materials is significantly hampered by the intricate interplay of factors at the atomic and molecular levels. The performance of a perovskite cell isn’t dictated by a single property, but rather by a delicate balance of composition, crystal structure, and the presence of even trace impurities. These complex interactions influence how light is absorbed, how charge carriers are generated and transported, and ultimately, how efficiently electricity is produced. Subtle changes in material composition or processing conditions can dramatically alter these interactions, leading to unpredictable variations in performance and making the optimization process extraordinarily challenging – a search space far more nuanced than many conventional materials systems.
The development of novel materials for perovskite solar cells has historically relied on laborious trial-and-error experimentation, a process that significantly constrains the pace of innovation. Synthesizing and characterizing even a limited number of perovskite compositions demands considerable time, specialized equipment, and substantial material resources. This conventional approach often involves iterative adjustments to chemical formulations, followed by extensive testing to evaluate performance metrics like efficiency and stability. Because of the vast compositional space of potential perovskites, this brute-force method proves exceptionally inefficient, delaying the discovery of truly optimized materials and hindering the widespread adoption of this promising renewable energy technology. Consequently, researchers are increasingly focused on computational methods and machine learning techniques to predict promising perovskite candidates, aiming to bypass the limitations of purely empirical investigation.
Knowledge Graph Integration: A Foundation for Prediction
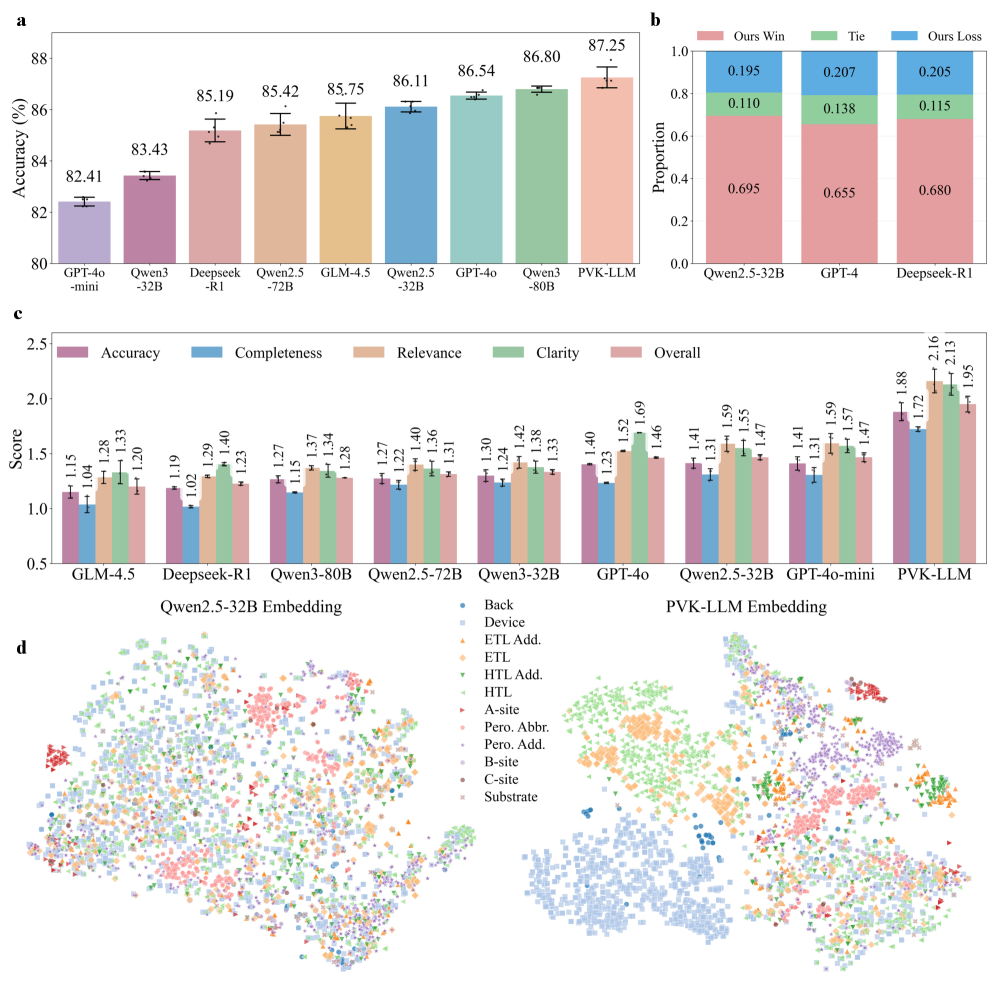
The PVK-LLM is a Large Language Model (LLM) designed for application within the field of perovskite materials science. Its development centers on the integration of a comprehensive Perovskite Knowledge Graph, which serves as the foundational source of domain-specific information. This Knowledge Graph encodes relationships between perovskite compositions, synthesis parameters, characterization data, and performance metrics. The LLM leverages this structured knowledge to improve the accuracy and relevance of its outputs when addressing perovskite-related queries and predictions, distinguishing it from general-purpose LLMs lacking specialized training in this scientific domain. The PVK-LLM’s architecture is optimized to process and reason about the complex data inherent in perovskite research, enabling advanced capabilities such as material property prediction and experimental design assistance.
The PVK-LLM employs Curriculum Learning, a training strategy that sequences learning examples based on their complexity. Initially, the model is exposed to fundamental perovskite concepts, including basic chemical formulas and crystal structures. Subsequent training phases introduce increasingly complex relationships, such as the correlation between compositional variations and optoelectronic properties, and finally, the model learns to predict material behavior based on nuanced feature combinations. This progressive approach, moving from simple to complex data, facilitates efficient knowledge acquisition and improves the model’s ability to generalize to unseen perovskite materials and predict their characteristics.
Active Learning within the PVK-LLM framework addresses the challenge of efficiently exploring the vast experimental space of perovskite materials. Instead of randomly selecting experiments for model training, the system employs a query strategy to identify those predicted to yield the most significant information gain. This is achieved by quantifying the uncertainty of the LLM’s predictions and prioritizing experiments that are expected to reduce this uncertainty most effectively. The selected experiments are then used to augment the training dataset, iteratively refining the model’s understanding of perovskite structure-property relationships. This targeted approach demonstrably accelerates the learning process and leads to improved predictive accuracy with fewer experimental iterations compared to passive learning or random sampling strategies.
Bayesian Optimization: Automating the Search for Perfection
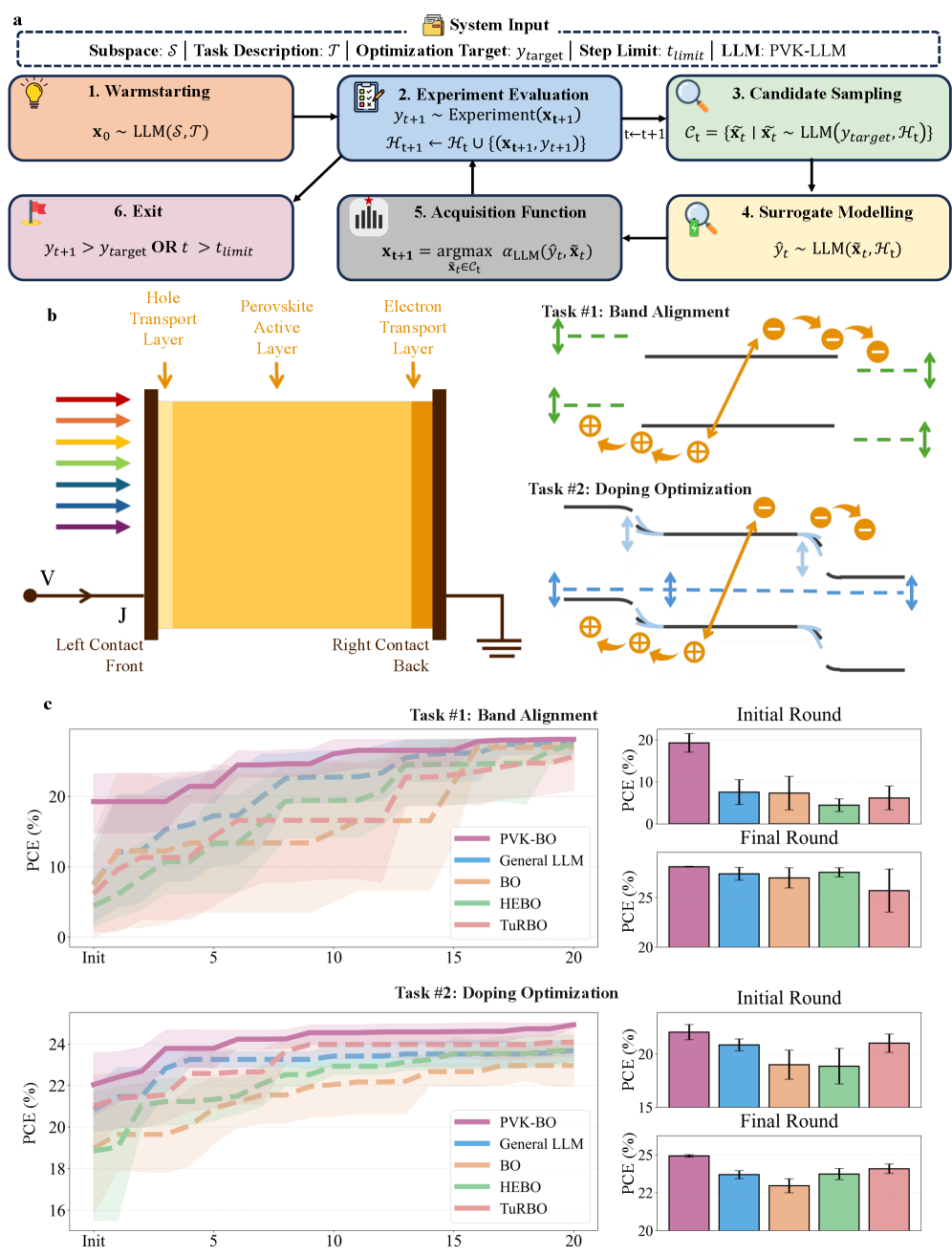
The PVK-LLM functions as the core engine for a Bayesian Optimization (PVK-BO) process, systematically adjusting both material compositions and device fabrication parameters. PVK-BO employs a probabilistic model – specifically, a Gaussian Process – to predict the performance of unseen parameter combinations based on previously evaluated data. The PVK-LLM leverages its predictive capabilities to suggest the next set of parameters to evaluate, balancing exploration of the parameter space with exploitation of promising regions. This iterative refinement cycle – prediction, evaluation, and model update – continues until a defined optimization goal is met or a resource limit is reached, effectively automating the search for optimal device configurations.
Device performance prediction is achieved through simulator experiments integrated within the Bayesian Optimization loop. These simulations, based on validated physics models, rapidly assess the characteristics of proposed material compositions and fabrication parameters without requiring physical sample creation or measurement. This in silico evaluation provides a proxy for real-world performance, allowing the PVK-LLM to efficiently prioritize promising candidates and significantly reduce the number of expensive and time-consuming physical tests needed to converge on optimal designs. The simulation data serves as the primary input to the Bayesian Optimization algorithm, guiding the search towards areas of the material space likely to yield improved device characteristics.
The PVK-LLM-driven Bayesian Optimization (PVK-BO) process facilitates efficient exploration of expansive material composition and fabrication parameter spaces. Traditional materials discovery relies heavily on iterative physical experimentation, a process limited by time and resource constraints, and often incapable of thoroughly searching high-dimensional spaces. PVK-BO, by leveraging simulator experiments to predict device performance, significantly reduces the need for physical tests, enabling the rapid evaluation of a substantially larger number of potential compositions. This accelerated screening process allows for the identification of promising materials and configurations that would likely be overlooked by conventional, less systematic methods, particularly those exhibiting complex or non-intuitive relationships between composition and performance.
Experimental Validation: Bridging Prediction and Reality
Rigorous wet-lab experimentation serves as the crucial bridge between computational prediction and tangible device performance. The predictions generated by both the PVK-LLM and PVK-BO optimization algorithms undergo stringent validation through physical material synthesis and device fabrication. This process doesn’t merely confirm the algorithms’ suggestions, but actively quantifies their accuracy and reliability – identifying which proposed material combinations translate into improved perovskite solar cell characteristics. By systematically comparing experimental results with algorithmic forecasts, researchers can refine the models, enhancing their predictive power and accelerating the discovery of high-efficiency perovskite formulations. This iterative cycle of prediction and validation is fundamental to ensuring the optimization process yields consistently robust and impactful improvements in device performance.
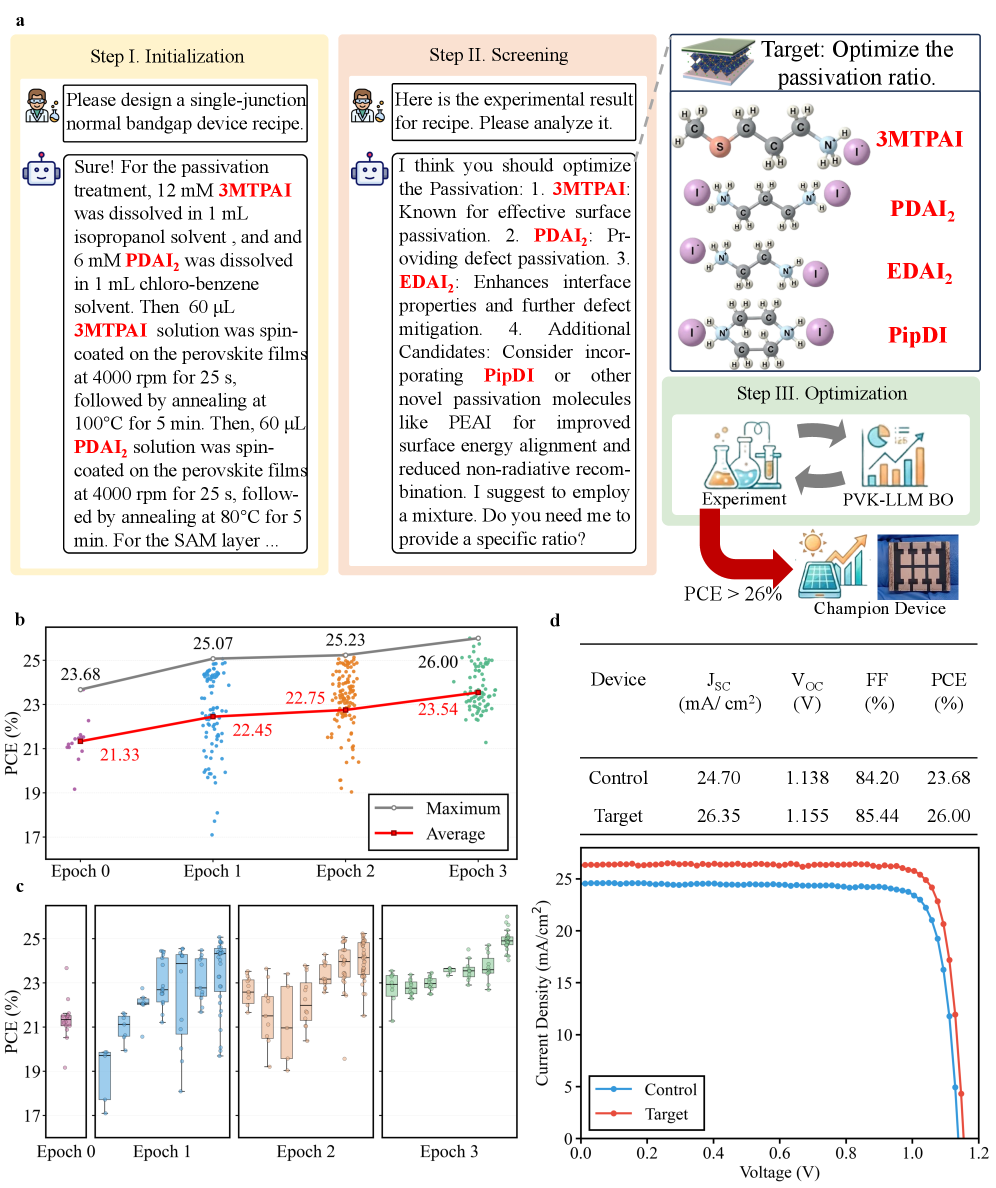
Interface passivation represents a crucial strategy for boosting perovskite solar cell performance by mitigating defects that trap charge carriers and diminish efficiency. Research centers on strategically incorporating organic molecules – specifically 3MTPAI, PDAI2, EDAI2, and PipDI – at the perovskite film’s interfaces. These molecules function as chemical ‘glues,’ binding to and neutralizing surface defects that would otherwise impede the flow of electricity. By reducing these non-radiative recombination centers, the lifespan of charge carriers is extended, ultimately leading to a significant enhancement in both the power conversion efficiency and stability of the resulting perovskite devices. This targeted approach to defect management has proven instrumental in achieving efficiencies approaching the current world record for perovskite solar cells.
Rigorous device fabrication protocols were implemented to translate the computationally optimized material compositions into functioning perovskite solar cells. This process demanded exacting control over deposition parameters, film morphology, and layer interfaces, ultimately yielding a device with a power conversion efficiency of 26.0%. This performance benchmark places the fabricated cell in direct contention with current world-leading perovskite solar cell efficiencies and validates the predictive power of the PVK-LLM and PVK-BO optimization strategies. The successful realization of such a high-performing device demonstrates the potential for machine learning to accelerate materials discovery and facilitate the development of next-generation photovoltaic technologies.
![Our pipeline, utilizing a fine-tuned [latex]PVK-LLM[/latex], consistently outperforms baseline models like [latex]Qwen2.5-{32}B[/latex] in experiment analysis and knowledge grounding, constructs higher-quality knowledge graphs-correctly identifying [latex]SnO_2[/latex] as the electron transport layer-and demonstrates strong correlation between simulator parameters.](https://arxiv.org/html/2602.04914v1/x5.png)
The pursuit of optimized perovskite solar cell recipes, as detailed in the article, mirrors a fundamental principle of rigorous inquiry. It recalls John Dewey’s assertion: “Education is not preparation for life; education is life itself.” The PVK-LLM framework embodies this sentiment; it isn’t merely designing experiments towards discovery, but actively participating in the process of materials science. The coupling of the Large Language Model with Bayesian Optimization creates a dynamic system where iterative refinement – a hallmark of genuine learning – drives the achievement of a 26.0% power conversion efficiency. This exemplifies how a well-defined, analytical approach can yield demonstrably correct results, transcending simple empirical observation.
What’s Next?
The presented work, while demonstrating a notable advance in automated materials discovery, merely scratches the surface of a deeper challenge. The achievement of 26.0% power conversion efficiency, laudable as it is, remains an empirical result. The true test lies not in attaining a high value, but in the provability of the underlying principles guiding the design. Current approaches, even those leveraging large language models, operate largely within the confines of correlative analysis – identifying patterns in existing data without necessarily understanding the causal mechanisms. Future work must prioritize the integration of first-principles calculations and theoretical frameworks into the design loop, shifting from ‘what works’ to ‘why it works.’
A critical limitation resides in the inherent ambiguity of ‘domain knowledge.’ The knowledge encoded within the language model, while valuable, represents a distillation of past experiments and observations-a history of successful, and often serendipitous, outcomes. True innovation demands the ability to transcend existing knowledge, to explore parameter spaces previously deemed unviable. This requires algorithms capable of formulating and testing hypotheses, not simply extrapolating from precedent.
In the chaos of data, only mathematical discipline endures. The next generation of self-driving materials discovery systems will not be defined by the size of their datasets, but by the rigor of their deductive reasoning. The pursuit of higher efficiencies, while important, must be secondary to the establishment of a provably correct foundation for materials design.
Original article: https://arxiv.org/pdf/2602.04914.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Gold Rate Forecast
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- ‘Project Hail Mary’s Soundtrack: Every Song & When It Plays
- Total Football free codes and how to redeem them (March 2026)
- All Mobile Games (Android and iOS) releasing in April 2026
- Top 5 Best New Mobile Games to play in April 2026
2026-02-09 05:31