Author: Denis Avetisyan
A new framework uses intelligent software to automatically build comprehensive databases from scientific papers, accelerating materials science research.
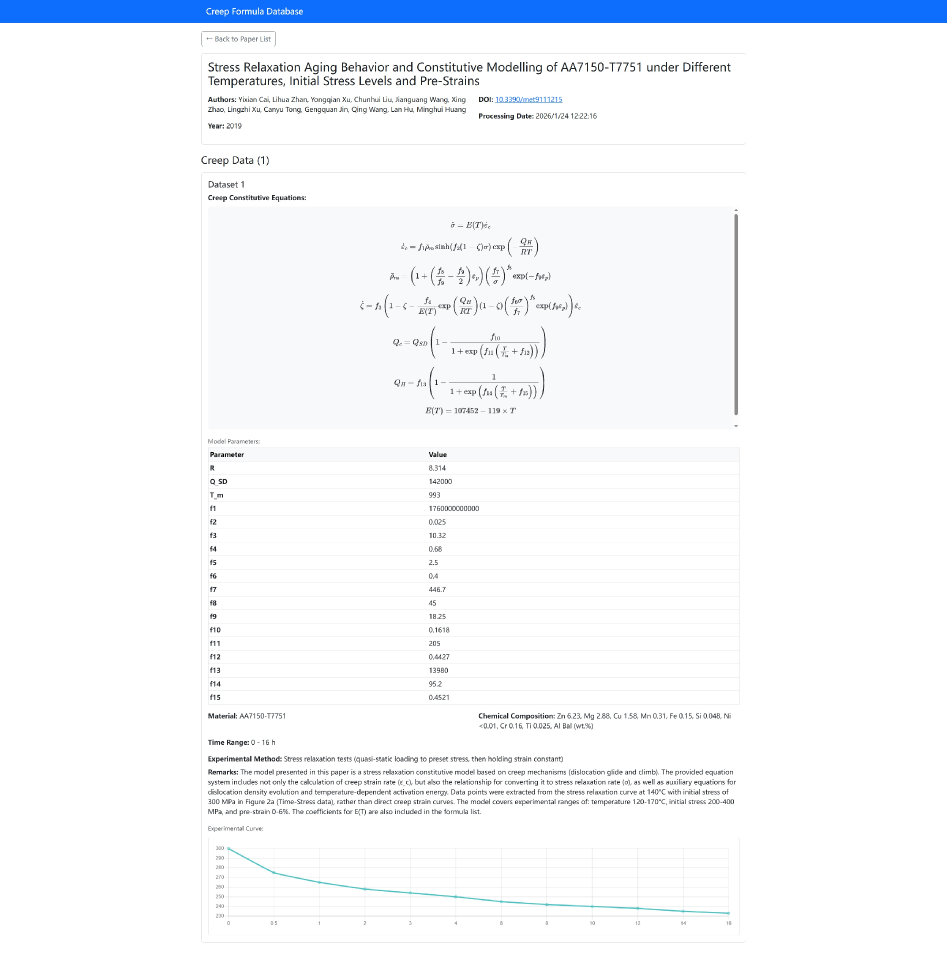
This work demonstrates a skill-based autonomous agent system for extracting creep mechanics data from literature, constructing a high-fidelity database and addressing a long-standing challenge in materials science.
Despite advances in data-driven materials science, a significant bottleneck persists due to the vast amount of valuable data locked within unstructured legacy literature. This work, ‘Skill-Based Autonomous Agents for Material Creep Database Construction’, introduces an autonomous, agent-based framework powered by Large Language Models to overcome this challenge by excavating high-fidelity datasets from scientific PDFs without human intervention. The framework achieves a verified extraction success rate exceeding 90% for creep mechanics data, autonomously aligning visually extracted data with textual parameters-demonstrating physical self-consistency [latex]R^2 > 0.99[/latex]. Could this scalable paradigm for automated knowledge acquisition unlock a new era of self-driving laboratories and accelerate materials discovery?
The Inevitable Data Constriction
The progression of materials science has long been stifled by a critical impediment: a severe lack of readily accessible, curated data. Historically, materials discovery relied heavily on iterative experimentation and the painstaking manual extraction of insights from published research. This process is not only time-consuming and expensive, but also creates a substantial ‘data bottleneck’ – a situation where the rate of knowledge generation is limited not by the ability to analyze information, but by the sheer difficulty of obtaining it in a format suitable for computational analysis. While a wealth of materials data exists within scientific literature – encompassing synthesis parameters, characterization results, and performance metrics – this information is often locked away in unstructured formats like text-heavy papers, images, and tables, making it exceptionally challenging for algorithms and artificial intelligence to efficiently process and learn from it. Consequently, the field’s potential to leverage the power of data-driven discovery remains significantly restricted, hindering the rapid development of novel materials with tailored properties.
The sheer volume of materials science literature presents a significant challenge to rapid innovation, as conventional knowledge extraction techniques struggle to keep pace with the exponential growth of research. While millions of publications detail material properties and synthesis methods, the data within remains largely trapped in unstructured formats – often residing in figures, tables, and qualitative descriptions rather than readily accessible databases. Current natural language processing methods, though improving, frequently misinterpret scientific nuance, fail to accurately identify key data points, or lack the domain-specific knowledge necessary to discern meaningful relationships. This necessitates substantial manual curation – a time-consuming and expensive process – limiting the ability of researchers to leverage the collective knowledge embedded within the scientific record and effectively apply machine learning for accelerated materials discovery.
The promise of artificial intelligence to revolutionize materials science remains largely unrealized due to a critical impediment: a scarcity of readily usable data. While AI algorithms excel at identifying patterns and predicting outcomes, their efficacy is directly proportional to the quality and quantity of information they receive. Currently, much of the valuable knowledge concerning material properties and compositions resides within unstructured scientific literature – research papers, patents, and technical reports – inaccessible to automated analysis. This data bottleneck prevents AI from efficiently sifting through existing knowledge to suggest novel material combinations or predict the performance of existing ones, thereby slowing the pace of innovation. Consequently, the development of advanced materials with tailored properties-essential for progress in areas like energy storage, aerospace, and medicine-is significantly constrained, highlighting the urgent need for strategies to unlock and curate this wealth of hidden information.
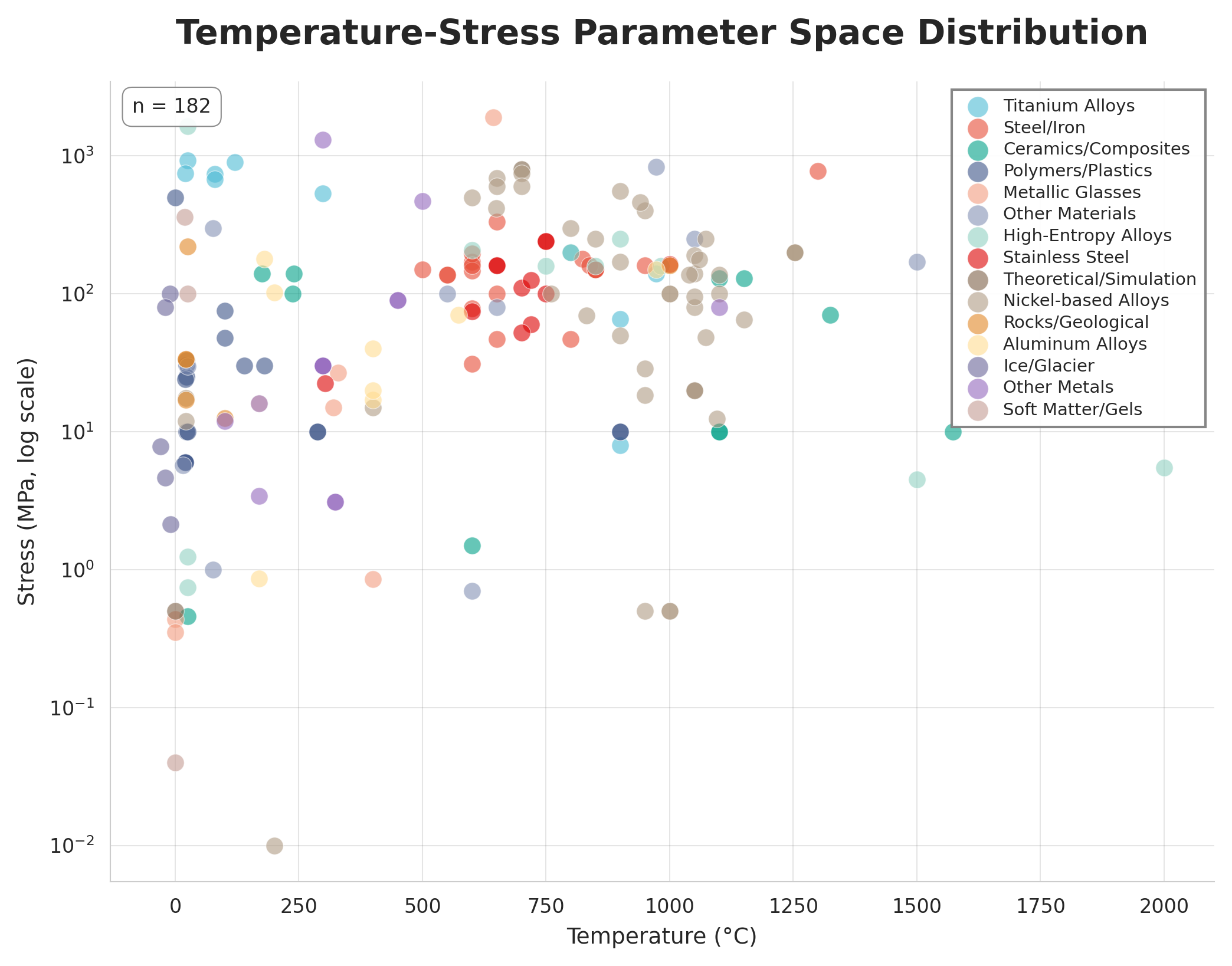
![The constructed creep database exhibits broad material diversity, including significant representation of critical industrial materials like nickel-based alloys ([latex]19.0%[/latex]) and steel/iron ([latex]12.5%[/latex]), alongside non-metallic systems such as polymers ([latex]8.5%[/latex]) and ice/glaciers ([latex]4.0%[/latex]), demonstrating the agent's ability to identify creep behavior across varied material science domains.](https://arxiv.org/html/2602.03069v1/figure_2a_material_distribution_nature.png)
Autonomous Agents: A Shift in Scientific Workflow
The proposed framework utilizes autonomous agents to automate data extraction from scientific literature. These agents are powered by large language models, specifically the Qwen3-235B-A22B model, chosen for its capacity to process and interpret complex textual data. The architecture allows for automated identification and extraction of key data points without manual intervention, increasing efficiency in scientific data processing. This approach shifts data acquisition from a human-driven process to one executed by software agents capable of continuous operation and scalability, thereby enabling faster analysis of large datasets.
The ReAct paradigm, utilized in these intelligent agents, functions by interleaving ‘Reason’ and ‘Act’ steps to navigate complex scientific texts. Initially, the agent reasons about the information needed to fulfill a given task. It then acts by utilizing external tools – such as literature search engines or data analysis software – to gather relevant information. The results of these actions are observed, and this observation feeds back into the reasoning process, allowing the agent to iteratively refine its understanding and adjust subsequent actions. This cycle continues until the agent confidently achieves the desired outcome, effectively enabling it to handle nuanced information and overcome the limitations of static knowledge bases.
A skill-based architecture for autonomous agents utilizes a decomposition of complex tasks into discrete, specialized modules termed ‘Agent Skills’. Each skill encapsulates a specific functionality, such as text parsing, data validation, or API interaction, and operates independently. This modular design enhances both the maintainability and scalability of the agent system; new skills can be integrated without requiring modifications to existing code, and individual skills can be replicated or distributed across multiple processing units to handle increased workloads. Furthermore, this approach facilitates focused testing and debugging of individual components, improving the overall reliability of the automated scientific discovery process.
Extracting Insight: A Multi-Modal Pipeline
The initial phase of the automated data extraction pipeline centers on comprehensive literature collection and subsequent automated screening to identify pertinent scientific publications. This process leverages multiple digital libraries and databases, employing keyword searches and citation network analysis to maximize coverage. Automated screening filters publications based on pre-defined criteria – including title, abstract, and keywords – to reduce the volume of documents requiring manual review. This step utilizes algorithms designed to minimize false negatives while effectively removing irrelevant material, ensuring that downstream extraction processes focus on publications with a high probability of containing target data.
Data extraction from scientific literature is performed using a combination of tools specializing in text and image processing. MatScholar, a machine learning model, focuses on identifying and extracting materials data from the body text of publications. Complementing this, ChemDataExtractor is employed to specifically identify and parse chemical information, including reaction conditions and compound names, also from textual content. For data presented in figures and diagrams, Optical Character Recognition (OCR) technology converts image-based text into machine-readable format, enabling the extraction of data that is not directly available in textual form. This multi-faceted approach ensures comprehensive data capture from diverse publication formats.
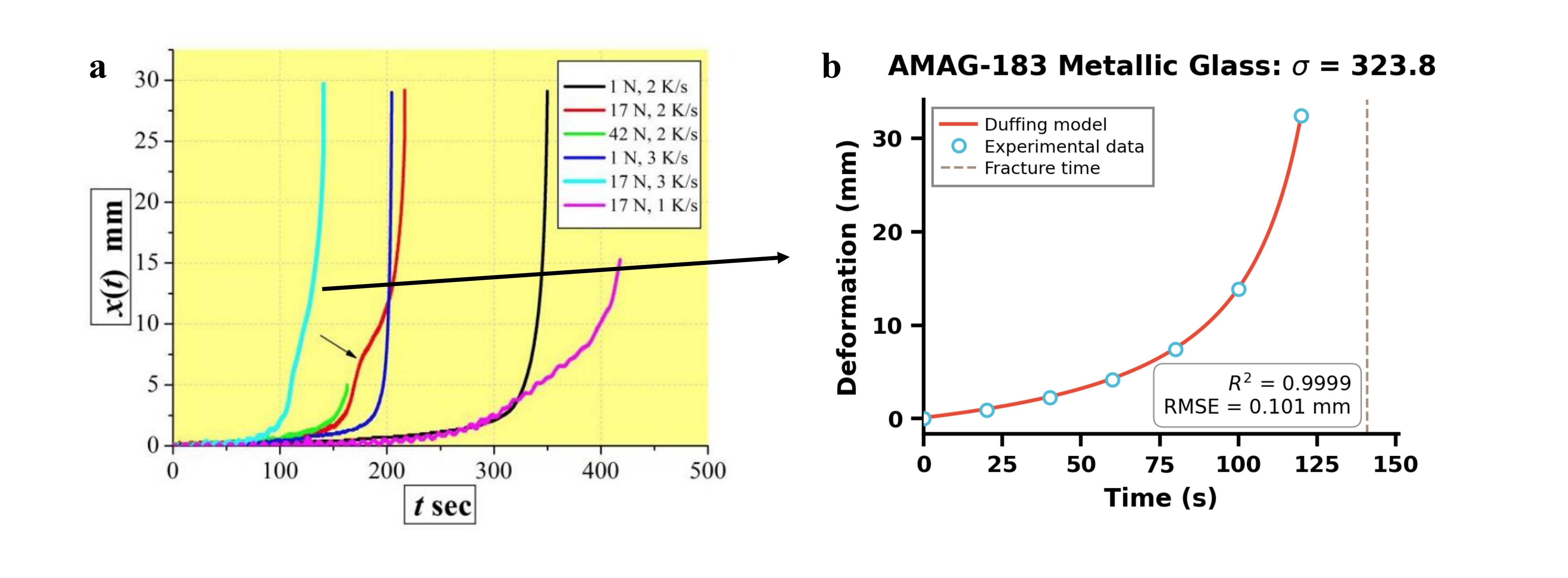
Following initial data extraction, a multi-modal information extraction process integrates data from text, images, and potentially other sources to create a consolidated dataset. This is then subjected to formula validation, which assesses the consistency and accuracy of extracted equations and numerical results. The Duffing Oscillator, a non-linear dynamical system, is employed as a benchmark for validating the behavior of extracted formulas under varying conditions. Evaluation of formula accuracy is quantified using the R-squared metric, which indicates the proportion of variance in the observed data explained by the extracted formula; values closer to 1 signify a stronger correlation and higher validation confidence. This process ensures data integrity and reliability for downstream analysis.
From Data to Design: A Structured Foundation
The foundation of accelerated materials design lies in meticulously organizing experimental and computational data within a ‘Structured Storage’ system-essentially a relational database. This approach transcends the limitations of conventional, unstructured data formats by enabling efficient querying and analysis of materials properties and processing parameters. Crucially, each data entry is linked to its origin via a ‘Digital Object Identifier’ (DOI), establishing a robust system for provenance tracking. This ensures reproducibility and allows researchers to confidently trace the lineage of any given material’s data, from initial synthesis to final characterization, fostering trust and accelerating the pace of scientific discovery.
The transition to structured data storage fundamentally alters the landscape of materials discovery by enabling efficient knowledge retrieval and analysis. Unlike traditional, unstructured datasets – often consisting of isolated reports and figures – a relational database organizes information into interconnected entities, facilitating complex queries and the identification of subtle relationships. This approach bypasses the limitations inherent in searching through vast quantities of text or manually extracting data from images, allowing researchers to rapidly pinpoint relevant materials, properties, and experimental conditions. Consequently, the ability to efficiently query and analyze accumulated knowledge not only accelerates the pace of materials design but also unlocks opportunities for data-driven insights that would remain hidden within less organized information stores.
The curated materials data, organized within the structured storage system, powerfully unlocks advanced machine learning techniques like Symbolic Regression and Physics-Informed Neural Networks (PINNs). Symbolic Regression algorithms can automatically discover underlying mathematical relationships governing material properties directly from the data, bypassing the need for pre-defined models. Simultaneously, PINNs integrate existing physical laws-expressed as differential equations-into the learning process, ensuring that predictions remain physically plausible and extrapolatable beyond the training dataset. This synergy between data-driven learning and fundamental physics dramatically accelerates materials discovery by efficiently navigating the vast chemical space and suggesting promising candidates with desired characteristics, ultimately reducing reliance on costly trial-and-error experimentation.
Towards a Self-Evolving Scientific Landscape
The current rate of scientific progress is often limited by the sheer volume of published research, creating a significant bottleneck in knowledge synthesis. Automating knowledge extraction offers a pathway to overcome this challenge by enabling machines to systematically analyze and distill insights from vast datasets of scientific literature. This process moves beyond simple keyword searches, employing techniques like natural language processing and machine learning to identify relationships, validate findings, and even formulate novel hypotheses. By freeing researchers from the time-consuming task of manual literature review, this automation allows them to focus on higher-level analysis, experimental design, and creative problem-solving, ultimately accelerating the pace of discovery across all scientific disciplines. The potential impact extends to identifying previously unseen connections between fields and facilitating the rapid translation of research into practical applications.
The architecture underpinning this automated knowledge extraction isn’t limited to a single field of study; its modular design anticipates broad application across diverse scientific domains. By adapting the core agent and knowledge graph to accommodate the specific ontologies and data structures of fields like materials science, genomics, or astrophysics, a truly self-discovering scientific ecosystem becomes feasible. This expansion envisions a network where automated agents continuously analyze the latest research, identify emerging patterns, formulate novel hypotheses, and even suggest experiments-effectively accelerating discovery beyond the capacity of traditional, human-driven research. The potential lies in fostering a synergistic relationship between automated analysis and human intuition, ultimately leading to a more dynamic and rapidly evolving scientific landscape.
Continued development centers on enhancing the agent’s capacity for nuanced data interpretation and hypothesis generation. Researchers are actively working to fortify data validation techniques, addressing challenges posed by inconsistent or erroneous information commonly found in scientific literature. A crucial next step involves direct integration with real-time experimental data streams, allowing the system to move beyond passive analysis of existing publications and actively participate in the scientific method – formulating predictions, suggesting experiments, and iteratively refining its understanding based on observed results. This transition promises a dynamic feedback loop, ultimately accelerating discovery and fostering a truly self-evolving scientific ecosystem.
![An agent successfully extracted a specific creep curve ([latex]σ=31.6 MPa[/latex]) from a complex plot of creep trajectories for X46Cr13 material at [latex]600^\circ C[/latex], demonstrating its ability to isolate target data while disregarding irrelevant information and preserving the underlying trend.](https://arxiv.org/html/2602.03069v1/fig2_page-0001.jpg)
The pursuit of a comprehensive creep mechanics database, as detailed in this work, highlights the inevitable entropy inherent in knowledge systems. Data, like all structures, degrades over time – becoming fragmented, inaccessible, or simply lost to outdated formats. This research doesn’t halt that decay, but rather constructs a system designed to actively resist it through continuous, automated refinement. As John McCarthy observed, “The best way to predict the future is to invent it.” The framework presented here isn’t merely cataloging existing data; it’s inventing a future where materials science isn’t constrained by the ‘data bottleneck’, proactively building a resource that ages gracefully through the iterative actions of skilled agents. Versioning, in this context, isn’t just a technical necessity, but a form of memory, preserving the evolution of understanding.
What Lies Ahead?
The automation of knowledge extraction, as demonstrated by this work, doesn’t resolve the fundamental challenge of material degradation-it merely shifts the point of failure. The ‘data bottleneck’ may loosen, but a new constriction inevitably forms. The database will grow, undoubtedly, accumulating more instances of creeping failure. Yet, time remains the ultimate variable, and even the most comprehensive dataset cannot predict the precise moment a system yields to it. Stability, in this context, often appears less a testament to inherent resilience and more a prolonged deferral of inevitable decay.
Future efforts will likely center on refining the agent’s capacity for cross-modal reasoning – moving beyond simple data extraction to genuine synthesis and hypothesis generation. However, the true limitation isn’t computational; it’s conceptual. The agents can identify patterns, but interpreting those patterns requires an understanding of the underlying physics, an understanding that remains stubbornly resistant to algorithmic capture. The system ages not because of errors in the code, but because the very materials it studies are subject to the relentless march of entropy.
Perhaps the most intriguing direction lies not in building ever-more-complex agents, but in accepting the inherent incompleteness of any predictive model. Acknowledging the limits of knowledge might allow for the development of systems that are not merely resistant to creep, but adaptive to it – systems that anticipate their own failure and gracefully accommodate it. This is not a solution, of course, but a re-framing of the problem itself.
Original article: https://arxiv.org/pdf/2602.03069.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Limbus Company 2026 Roadmap Revealed
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Total Football free codes and how to redeem them (March 2026)
2026-02-04 12:23