Author: Denis Avetisyan
A new framework empowers robots to dynamically adapt to assembly tasks, learning from human operators and visual cues to build customized products.

This work introduces CoViLLM, an adaptive human-robot collaboration framework leveraging large language models for runtime perception and reasoning in manufacturing assembly.
Traditional manufacturing robots struggle with the flexibility required for increasingly customized product lines, yet fully autonomous systems lack the adaptability of human workers. This paper introduces ‘CoViLLM: An Adaptive Human-Robot Collaborative Assembly Framework Using Large Language Models for Manufacturing’-a novel approach that integrates vision-based perception, human activity classification, and large language models to enable dynamic task planning for collaborative assembly. Experimental validation demonstrates that CoViLLM successfully extends human-robot collaboration beyond predefined scenarios, enabling the assembly of both customized and previously unseen products. Could this framework pave the way for truly adaptable and intelligent manufacturing systems capable of responding to rapidly changing demands?
The Challenge of Adaptable Assembly
Conventional robotic assembly systems, while renowned for their speed and repeatability, often falter when confronted with the unpredictable nature of real-world manufacturing. Unlike the controlled environments for which they are typically programmed, production lines are frequently subject to subtle variations in parts – slight differences in dimensions, orientation, or even the presence of minor defects. These inconsistencies, almost imperceptible to a human assembler, can disrupt the precise sequences a robot expects, leading to errors, stalled production, and the need for manual intervention. The rigid programming that underpins these systems struggles to accommodate such variability, highlighting a fundamental disconnect between the idealized precision of robotics and the inherent messiness of physical production. This limitation significantly hinders the adoption of fully automated assembly lines in industries demanding frequent product changes or handling a diverse range of components.
Conventional robotic assembly systems, while excelling in repetitive tasks, often falter when confronted with even minor deviations from their pre-programmed routines. These systems are typically designed for a specific product and a highly controlled environment; any alteration to the product’s design, the order of assembly, or even slight changes in part positioning can disrupt the process. Unlike human workers who readily adapt through visual feedback and learned dexterity, pre-programmed robots struggle with such unforeseen circumstances, requiring costly and time-consuming reprogramming or manual intervention. This inflexibility poses a significant hurdle to modern manufacturing, particularly in industries demanding frequent product updates, customized designs, or the ability to handle unpredictable variations in supplied components.
The rigidity of conventional robotic assembly lines frequently translates to significant financial burdens for manufacturers. When faced with even minor product alterations or unforeseen disruptions – a slightly different component, a shifted production target, or an unexpected tooling issue – pre-programmed robots often require complete shutdowns for reprogramming and recalibration. This downtime accumulates rapidly, impacting production schedules and increasing operational costs. More critically, this inflexibility severely restricts a company’s ability to implement agile manufacturing practices, hindering its responsiveness to market demands and limiting opportunities for rapid innovation and customized product offerings. The inability to quickly adapt to change ultimately diminishes competitiveness in an increasingly dynamic global landscape.
Current manufacturing increasingly demands systems capable of seamlessly integrating the strengths of both robotic automation and human cognition. The limitations of rigidly programmed robots in dynamic environments necessitate a shift towards more versatile assembly strategies. Researchers are actively exploring paradigms that leverage advancements in artificial intelligence, particularly machine learning and computer vision, to imbue robots with the capacity for real-time adaptation. This involves developing systems that can perceive variations in parts, adjust assembly sequences on the fly, and even learn from unexpected events – mirroring the intuitive problem-solving skills characteristic of human workers. Ultimately, the goal is to create a collaborative robotic ecosystem where precision and adaptability coexist, unlocking unprecedented levels of efficiency and responsiveness in manufacturing processes.

CoViLLM: A Framework for Collaborative Assembly
CoViLLM is a Human-Robot Collaboration (HRC) framework engineered to facilitate adaptable assembly processes. The system’s core functionality centers on enabling robotic manipulation within dynamic environments, specifically targeting scenarios requiring flexibility in response to changes in task parameters or component presentation. This is achieved through a unified architecture that moves beyond pre-programmed routines, allowing for on-the-fly adjustment of assembly sequences. The framework is designed to improve efficiency and reduce the need for extensive re-programming when faced with variations in assembly tasks, making it suitable for high-mix, low-volume production settings and other applications demanding robotic adaptability.
CoViLLM achieves integration of Large Language Models (LLM) and vision-perception systems through a multi-modal architecture. Specifically, visual input from cameras and sensors is processed by a perception module to extract relevant features and object information. These features are then encoded into a format compatible with the LLM, allowing the model to reason about the visual scene. The LLM processes both the visual encoding and natural language instructions from the human operator, generating control signals for the robot. This allows the system to interpret commands like “pick up the red component” by identifying the red component in the visual input and planning the appropriate robotic manipulation.
CoViLLM utilizes natural language communication as the primary interface for human-robot interaction, eliminating the need for traditional robot programming methods such as scripting or graphical block programming. Human operators can issue high-level assembly instructions – for example, “Attach the red connector to the base” – which are then interpreted by the integrated Large Language Model. This model translates the natural language input into actionable robot commands, controlling the robot’s movements and actions. The system supports iterative refinement; operators can provide corrective feedback or further instructions in natural language, allowing for real-time adaptation and correction of the assembly process without requiring any specialized robotics expertise or reprogramming.
The CoViLLM framework enables robotic adaptation to variations in assembly tasks through the combined functionality of its Large Language Model and vision system. When presented with altered requirements or previously unencountered components, the system leverages the LLM’s reasoning capabilities to interpret the new context communicated by the human operator. Simultaneously, the vision system provides real-time perceptual data regarding the changes. This data is then processed by the LLM, allowing the robot to modify its assembly plan and execution without requiring explicit reprogramming. The system achieves this dynamic adaptation by re-interpreting task instructions and generating revised action sequences based on the current visual input and linguistic guidance.

Perception and Planning: The Core Mechanisms of CoViLLM
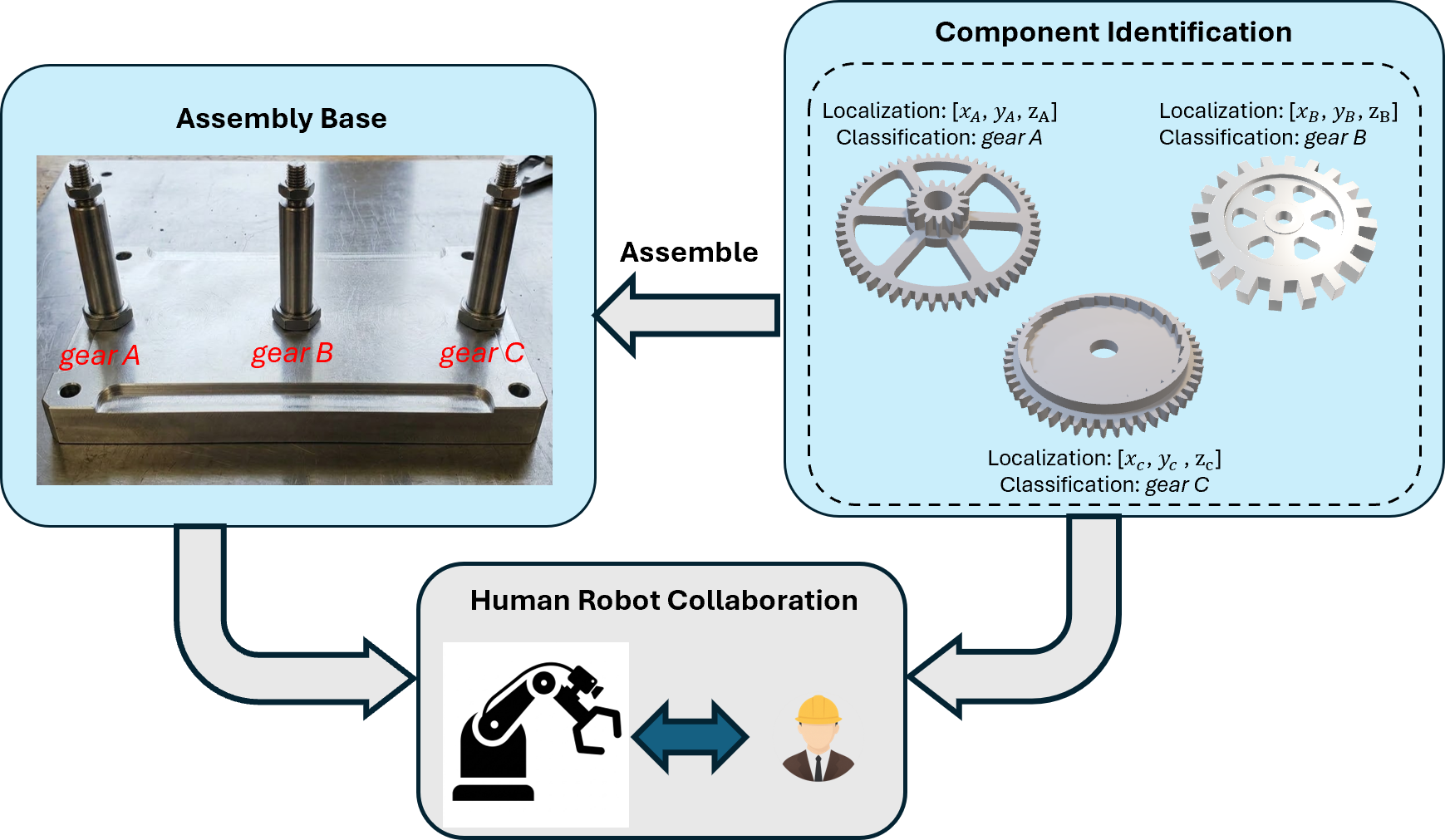
CoViLLM utilizes depth-based localization to establish accurate spatial awareness of objects within its operating environment. This is achieved through the integration of depth sensors, such as time-of-flight or stereo cameras, which provide 3D point cloud data representing the scene geometry. Processing this data allows the system to identify object positions and orientations relative to the robot base frame. The resulting 3D object maps are used for collision avoidance, grasp planning, and to inform the LLM’s task planning process, enabling CoViLLM to accurately perceive and interact with objects in a dynamic workspace. Localization accuracy is maintained through continuous data acquisition and refinement of the 3D object maps.
Human Operator Classification within CoViLLM facilitates the identification and categorization of novel components during assembly tasks through operator feedback. When presented with an unrecognized part, the system prompts the human operator for a descriptive label or category. This operator-provided information is then used to update the system’s knowledge base, effectively expanding its object recognition capabilities without requiring pre-programmed definitions for every possible component. The LLM processes this feedback, associating the new label with the visual characteristics of the object, and subsequently integrates this knowledge into its perception and planning modules for future use. This allows CoViLLM to dynamically adapt to varying assembly scenarios and accommodate components not present in its initial training data.
CoViLLM’s dynamic task planning utilizes a large language model to generate assembly sequences in real-time. This process integrates two primary data sources: operator instructions, provided through natural language, and environmental perceptions obtained via depth-based localization. The LLM interprets these inputs to construct a feasible sequence of actions for the robot, adapting the plan as new information becomes available from either the operator or the perceived workspace. This allows the system to handle variations in component placement, unexpected obstacles, and modifications to the desired assembly process without requiring pre-programmed responses or manual intervention.
Robot forward kinematics is implemented to translate high-level assembly plans into precise robot joint commands. This process calculates the position and orientation of the robot’s end-effector based on defined joint angles, enabling accurate trajectory planning and execution. By utilizing forward kinematics, CoViLLM ensures that the robot’s movements are coordinated and avoid collisions with both the assembly and the surrounding workspace. The calculations account for the robot’s mechanical structure – link lengths and joint types – to determine the end-effector’s pose in Cartesian space, facilitating precise component placement and manipulation during assembly tasks.

The Power of Prompting: Unlocking LLM Potential
Vision-Language Models (VLMs) represent a pivotal advancement in artificial intelligence, enabling machines to interpret and connect the visual world with natural language. These models aren’t simply combining image recognition with text processing; rather, they’re built on deep neural networks trained on massive datasets of paired images and text descriptions. This allows the LLM to move beyond processing solely textual inputs and to ground its understanding in visual reality. By learning the correlations between visual features and linguistic concepts, VLMs facilitate tasks requiring both visual perception and language comprehension-from generating descriptive captions for images to answering questions about visual content and, crucially, guiding robotic actions based on visual instructions. The architecture effectively bridges the gap between sight and language, offering a pathway toward more intuitive and versatile interactions between humans and machines.
Prompt engineering is increasingly recognized as a pivotal technique for maximizing the effectiveness of large language models. It involves carefully designing the input text – the “prompt” – to elicit desired responses and steer the model towards accurate and reliable outputs. Rather than simply asking a question, effective prompt engineering structures the request with specific instructions, contextual information, and even examples of the desired format or reasoning process. This nuanced approach circumvents the inherent ambiguity in natural language, providing the LLM with a clearer understanding of the task at hand. Consequently, even relatively simple models can exhibit significantly improved performance on complex tasks through strategically crafted prompts, minimizing errors and enhancing the consistency of results.
The capacity of large language models to perform intricate reasoning and planning hinges significantly on the quality of the prompts they receive. Rather than simply requesting a direct answer, thoughtfully designed prompts can guide the model through a structured thought process, encouraging it to break down complex problems into manageable steps. This involves providing context, specifying desired output formats, and even incorporating examples of successful reasoning – techniques that effectively ‘prime’ the model for more sophisticated tasks. Such precise prompting allows the LLM to move beyond pattern recognition and demonstrate genuine problem-solving abilities, unlocking its potential for applications requiring nuanced judgment and strategic foresight. The result is a substantial increase in performance, transforming the LLM from a powerful text generator into a versatile cognitive tool.
The culmination of refined prompt engineering techniques manifests as a notable advancement in robotic assembly capabilities. Through precisely formulated prompts, robots powered by large language models demonstrate a heightened proficiency in tackling intricate and varied assembly tasks. This isn’t merely about executing pre-programmed motions; the system exhibits improved adaptability to unforeseen challenges, such as misaligned parts or unexpected obstacles. Consequently, the robot can not only complete assembly sequences with greater accuracy but also demonstrate a degree of problem-solving previously unattainable, suggesting a pathway toward more autonomous and resilient manufacturing processes. The improvement extends beyond simple repetition, enabling the robot to generalize learned skills to novel assembly configurations and environments.

Validation and Future Directions: Towards Collaborative Manufacturing
The CoViLLM framework underwent rigorous testing utilizing the NIST Assembly Task Board 1, a standardized and highly respected platform within the robotic manipulation research community. This benchmark presents a series of complex assembly challenges designed to evaluate a robot’s ability to perceive, plan, and execute intricate tasks – ranging from peg-in-hole insertions to multi-part constructions. By employing this widely recognized evaluation tool, researchers ensured the CoViLLM results are both reproducible and comparable to existing state-of-the-art robotic systems, providing a robust measure of the framework’s capabilities in a realistic and challenging assembly environment.
CoViLLM’s performance on the NIST Assembly Task Board 1 signifies a substantial advancement in robotic task planning. The framework consistently demonstrated the capacity to not only comprehend the intricacies of complex assembly procedures but also to formulate error-free plans for their execution. Achieving 100% task-planning accuracy across diverse assembly cases-ranging in part complexity and requiring precise manipulation-validates the robustness and reliability of the system. This capability moves beyond simple, pre-programmed routines, indicating a level of cognitive flexibility previously unseen in robotic assembly, and suggesting a potential for adaptation to unforeseen challenges during real-world implementation.
Ongoing development of the CoViLLM framework prioritizes tackling increasingly intricate and unpredictable assembly challenges. Researchers aim to move beyond static scenarios by incorporating real-time sensor data and adaptive planning algorithms, enabling the system to respond to unexpected changes during assembly-such as part variations or unforeseen obstacles. This expansion includes investigating methods for robust error recovery, allowing the robot to autonomously correct mistakes and continue the assembly process without human intervention. Ultimately, the goal is to create a system capable of handling highly variable and dynamic environments, paving the way for more flexible and resilient manufacturing processes and broadening the range of tasks suitable for robotic automation.
The trajectory of modern manufacturing is shifting towards collaborative robotics, and a future is anticipated where humans and robots work in seamless synergy. This vision entails a manufacturing ecosystem characterized by heightened agility and adaptability, responding dynamically to changing demands and unforeseen disruptions. Robots, powered by advanced frameworks like CoViLLM, will move beyond isolated automation, becoming integral partners in the production process – handling intricate tasks, optimizing workflows, and augmenting human capabilities. Such a collaborative environment promises not only increased efficiency and reduced costs, but also a more resilient and innovative manufacturing landscape, capable of rapidly prototyping, customizing products, and scaling production with unprecedented ease.
The CoViLLM framework, as detailed in the study, embodies a holistic approach to human-robot collaboration, prioritizing adaptability and runtime perception. This resonates with the sentiment expressed by David Hilbert: “We must be able to answer the question: What are the ultimate elementary particles of which everything is composed?” Just as Hilbert sought fundamental building blocks, CoViLLM aims to create a flexible assembly system where robots, guided by Large Language Models, can dynamically respond to new product variations. The system doesn’t demand complete overhauls for each new task; instead, it evolves, leveraging existing capabilities and integrating new information – a principle akin to evolving infrastructure without rebuilding the entire block. This echoes the study’s core idea of enabling robots to handle both customized and novel products without rigid pre-programming.
Beyond the Blueprint
The framework presented here, while a demonstrable step toward more flexible assembly systems, merely shifts the locus of the fundamental problem. The reliance on large language models, however effective at runtime reasoning, introduces a dependency on the quality and bias embedded within those models. It is not enough for a robot to do what is asked; the system must also guarantee that the asking is sensible, safe, and aligned with the true intent. The elegance of natural language interfaces belies the complexity of translating ambiguous human instruction into precise robotic action; an illusion that will inevitably fracture under real-world conditions.
Future work must address the inherent brittleness of these systems. True adaptability isn’t about responding to novel tasks, but about anticipating and mitigating unforeseen states. The current emphasis on vision-language models, while providing a useful scaffolding, skirts the deeper question of robust state estimation. Until systems can reliably distinguish between genuine novelty and mere sensor noise, the promise of flexible automation will remain perpetually out of reach. The architecture, at present, feels like a complex solution to a problem that will ultimately demand simplicity.
Ultimately, the true cost of freedom isn’t the complexity of the software, but the limits of perception. A system capable of assembling anything, on demand, must first understand what ‘anything’ truly means, and that requires more than just a larger vocabulary. It requires a model of the world, not just of words.
Original article: https://arxiv.org/pdf/2603.11461.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-03-13 10:12