Author: Denis Avetisyan
A new study explores how large language models can automate content creation in science, shifting the focus to oversight and quality assurance.
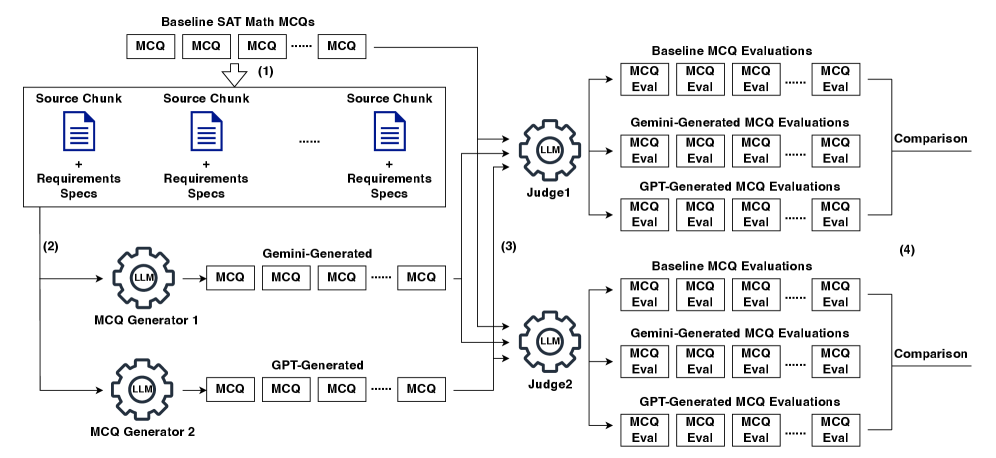
This pilot study demonstrates the use of orchestrated LLM agents for automated multiple-choice question generation and evaluation in scientific research.
Despite the promise of large language models (LLMs) to accelerate scientific discovery, empirical evidence on their impact on end-to-end research workflows remains limited. This study, ‘Orchestrating LLM Agents for Scientific Research: A Pilot Study of Multiple Choice Question (MCQ) Generation and Evaluation’, investigates an AI-orchestrated workflow wherein a researcher coordinated LLM agents to generate and evaluate multiple-choice questions, revealing substantial automation potential alongside a critical shift in required labor skills. While generated MCQs demonstrated high overall quality, equivalence testing revealed persistent gaps in areas like cognitive depth and difficulty calibration compared to expert-vetted questions. As LLMs reshape the scientific process, will the emerging role of the researcher become primarily one of orchestration, verification, and governance within these complex AI pipelines?
The Persistent Challenge of Valid Assessment
The development of effective multiple-choice questions has long been recognized as a significant undertaking, demanding considerable time and a deep understanding of the subject matter. Traditionally, crafting questions that accurately gauge comprehension-and not simply recall-necessitates a meticulous process of defining learning objectives, formulating plausible distractors, and ensuring alignment with established cognitive frameworks. This process isn’t merely about identifying correct answers; it requires anticipating common student misconceptions and designing options that reveal those misunderstandings. Consequently, generating a substantial bank of high-quality questions often proves to be a bottleneck in educational settings, placing a considerable burden on instructors and curriculum developers who must balance assessment needs with existing workloads. The expertise needed to avoid ambiguity, ensure validity, and maintain fairness further complicates the task, making it a labor-intensive endeavor that limits the scalability of traditional assessment methods.
Current automated question generation systems frequently struggle with tasks demanding more than simple recall. While proficient at creating questions testing factual knowledge, these methods often fail to assess critical thinking, problem-solving, or creative application of concepts. The algorithms typically rely on surface-level feature matching within text, identifying keywords and phrases to formulate questions, but lack the deeper semantic understanding needed to craft scenarios requiring analysis, evaluation, or synthesis. Consequently, automatically generated questions frequently exhibit a lack of subtlety, leading to ambiguous phrasing, predictable answers, or a focus on trivial details rather than core principles – ultimately limiting their effectiveness in gauging genuine comprehension and higher-order cognitive skills.
The push towards personalized learning experiences is creating a significant need for assessment tools that can adapt to individual student needs and learning paths. Traditional assessment methods often rely on a one-size-fits-all approach, failing to accurately gauge a student’s unique understanding or identify specific areas requiring support. Consequently, educators are seeking scalable solutions – methods that can automatically generate a wide range of assessment materials, varying in difficulty and focusing on different skills. These dynamically-created assessments aren’t simply about increasing the quantity of tests, but about delivering relevant, targeted evaluations that provide actionable insights into each student’s progress and inform instructional strategies. This demand is driving research into automated question generation, aiming to move beyond rote memorization checks towards assessments that truly measure critical thinking and problem-solving abilities, ultimately supporting a more effective and individualized educational journey.
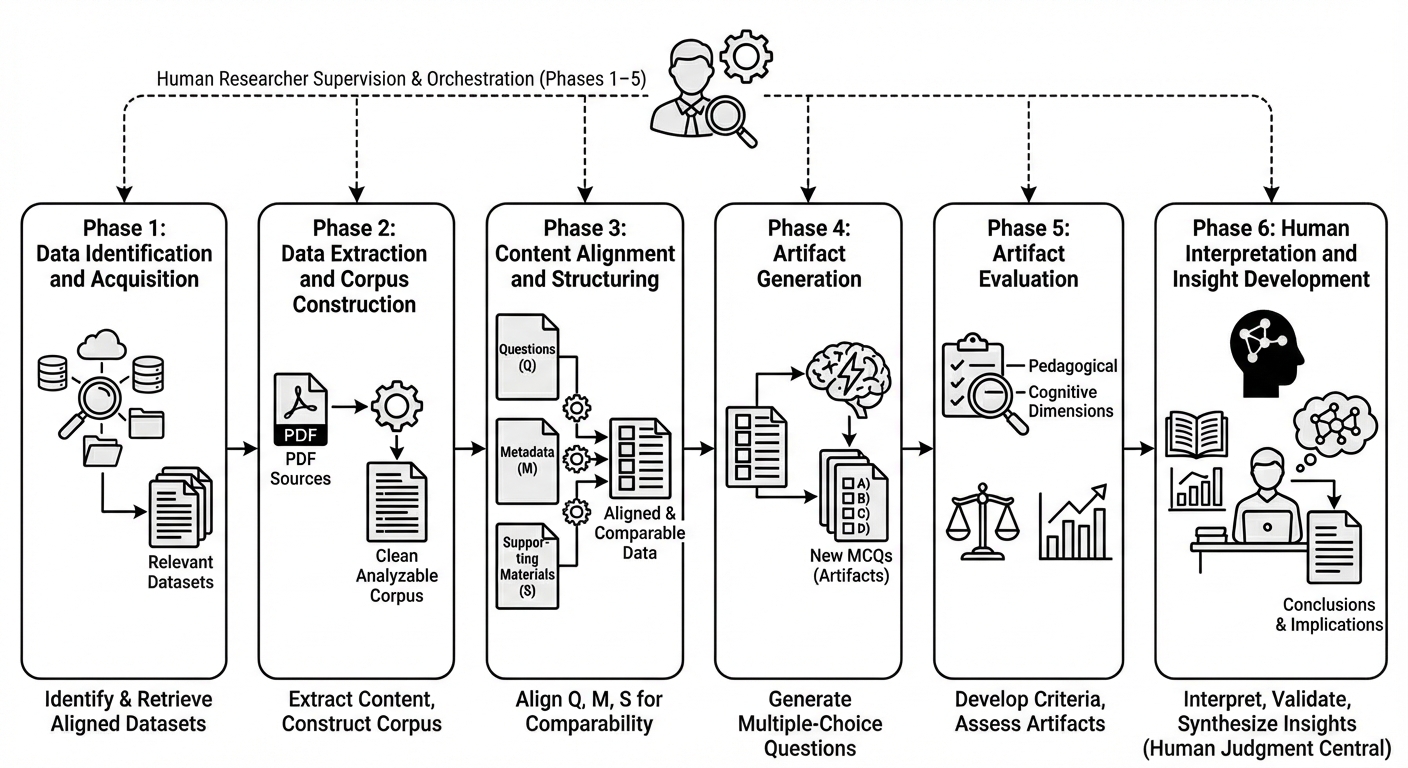
An Algorithmically Defined Workflow for Question Generation
The implemented AI-orchestrated workflow functions as a coordinated system integrating multiple tools to automate question generation. This workflow begins with data extraction from source materials, proceeds to question creation utilizing large language models, and concludes with automated quality assessment procedures. Coordination between these tools is managed programmatically, enabling a continuous and scalable process for generating and validating question sets. This automation minimizes manual intervention and ensures consistent application of quality criteria throughout the entire question lifecycle.
Multiple-choice question (MCQ) generation is central to the workflow and is achieved through Large Language Models (LLMs) integrated with a Retrieval-Augmented Generation (RAG) pipeline. This RAG pipeline accesses and utilizes an Open Textbook Corpus as the knowledge source, ensuring questions are factually grounded and contextually relevant. The LLM leverages retrieved information from the corpus to formulate both the question stem and the answer options, improving the accuracy and reducing the potential for hallucination compared to standalone LLM question generation. This method allows for the automated creation of MCQs directly informed by established educational materials.
The implemented workflow facilitates the automated generation of approximately 1000 multiple-choice questions per question set. This high-volume output is achieved through the orchestration of large language models and a Retrieval-Augmented Generation (RAG) pipeline, which allows questions to be directly linked to content within the Open Textbook Corpus. Importantly, question creation is not random; the system is designed to produce questions specifically aligned with defined learning objectives, ensuring relevance and educational value within each generated set.

Objective Question Evaluation via LLM-Based Judgment
The evaluation of generated questions utilized a Large Language Model (LLM) functioning as an automated judge, termed `LLM-as-Judge`. This system assessed each question against a pre-defined `Evaluation Rubric` comprising 24 distinct criteria. These criteria were designed to provide granular feedback on various question attributes, enabling a detailed, multi-faceted assessment of quality. The implementation of `LLM-as-Judge` and the 24-criterion rubric facilitated the automated scoring of questions, providing a quantitative measure of performance across defined quality dimensions.
The evaluation rubric utilized a multi-faceted approach to assess question quality, focusing on three primary categories: Cognitive Demand, which gauged the level of thinking skills required to answer the question; Pedagogical Quality, encompassing factors like clarity, conciseness, and the avoidance of misleading phrasing; and alignment with predefined learning objectives, ensuring questions directly addressed intended educational outcomes. Each of these categories was further broken down into specific, measurable criteria – totaling 24 in the complete rubric – to facilitate a granular and objective assessment of each generated question.
Automated question evaluation using Large Language Models (LLMs) offers advantages over traditional human review by providing consistent and reproducible assessments. Subjective human evaluation is prone to variability based on individual reviewer biases and interpretations, which can impact the reliability of quality control processes. LLM-based evaluation, grounded in a defined rubric, eliminates these inconsistencies and enables scalable assessment of large question banks. This approach allows for efficient identification of questions failing to meet predetermined quality standards, facilitating iterative improvement and ensuring consistent pedagogical alignment across learning materials, regardless of volume.
Statistical Rigor in Establishing Question Equivalence
To rigorously determine if the automatically generated math questions were comparable to existing SAT questions, the study employed TOST equivalence testing, a statistical approach built upon two one-sided tests. This method doesn’t aim to prove the questions are identical, but rather to demonstrate they fall within a pre-defined, acceptable equivalence range. Instead of seeking statistical significance in differences, TOST testing establishes that the observed differences are practically negligible – that the generated questions perform similarly enough to be considered equivalent for assessment purposes. This framework allows for a nuanced evaluation, acknowledging natural variation while ensuring the new questions maintain the same level of quality and difficulty as the established SAT benchmark.
A detailed statistical analysis revealed a substantial overlap between the quality of automatically generated questions and established SAT Math questions. The generated content didn’t merely approach equivalence; it definitively met predefined equivalence criteria in 8 out of 24 key evaluation categories. Importantly, the analysis further demonstrated practical equivalence – meaning a negligible difference in quality – across a minimum of 19 out of 24 categories. This finding suggests the generated questions possess a level of rigor and cognitive demand comparable to those found on a standardized, high-stakes assessment, offering a potentially valuable resource for educators and assessment developers.
The development of high-quality educational assessments is historically a lengthy undertaking, often requiring approximately six months to complete a single evaluation cycle. However, this project demonstrably compressed that timeline to just ten days. This radical acceleration wasn’t achieved through compromised quality, but rather through the innovative application of automated question generation and rigorous statistical validation. The speed with which comparable questions were produced and verified signifies a potential paradigm shift in assessment development, offering the possibility of more frequent, adaptable, and responsive evaluations without sacrificing the necessary standards of reliability and validity. This expedited process allows for quicker iterations, enabling educators to rapidly refine learning materials and better gauge student understanding.

Towards a Future of Adaptive and Scalable Educational Measurement
The architecture of the Automated Question Generation pipeline allows for substantial expansion beyond its initial capabilities. By modifying the knowledge sources and incorporating diverse datasets, the system isn’t limited to a single subject area; it can be adapted to produce questions spanning the humanities, sciences, and even specialized vocational fields. Furthermore, the pipeline’s parameters controlling question complexity – encompassing both cognitive demand and textual difficulty – enable the generation of questions at varied levels, from basic recall to advanced critical thinking. This dynamic adjustment allows for the creation of assessments that precisely match a student’s current understanding and facilitate progressive learning, effectively building a customized pathway for knowledge acquisition. The modular design ensures that new subjects and difficulty calibrations can be integrated without fundamentally altering the core system, promising a continuously evolving and increasingly versatile assessment tool.
The true potential of automated assessment lies in its seamless integration with learning management systems, allowing for the creation of dynamically adjusted learning paths. This technology moves beyond static evaluations by continuously monitoring a student’s performance and adapting future questions to specifically target areas needing improvement. Through algorithmic analysis of responses, the system identifies knowledge gaps and automatically generates assessments focused on reinforcing those concepts, ensuring each student receives a truly personalized educational experience. This adaptive approach not only enhances understanding but also fosters a more engaging and effective learning environment, optimizing the pace and content to match individual progress and maximize learning outcomes.
The potential of automated question generation extends beyond simply creating quizzes; it offers a pathway to broadly democratize access to quality educational materials. Currently, the development of effective assessments requires significant expertise and resources, creating disparities in educational opportunities. This technology circumvents these limitations by enabling the rapid and cost-effective creation of tailored learning resources, regardless of geographic location or institutional funding. By adapting to individual student needs and progress, these systems facilitate personalized learning experiences at scale, potentially bridging achievement gaps and fostering improved educational outcomes for a wider range of learners. The ability to generate questions across diverse subjects and difficulty levels ensures that educational content remains relevant and challenging, fostering deeper understanding and critical thinking skills.
The study highlights a fundamental shift in scientific labor, moving away from the manual creation of research materials towards the meticulous orchestration and validation of automated systems. This echoes a core principle of elegant design – a focus on provable correctness rather than simply functional output. As Linus Torvalds aptly stated, “Talk is cheap. Show me the code.” The researchers demonstrate this by showcasing how LLMs generate multiple-choice questions, but crucially, emphasize the need for rigorous equivalence testing to ensure the generated content aligns with established scientific understanding. The true value lies not merely in the speed of generation, but in the demonstrable accuracy and logical consistency of the results, a harmonious balance of symmetry and necessity.
What’s Next?
The demonstrated acceleration of scientific workflows, achieved through automated content generation, is not a triumph of artificial intelligence, but rather a subtle realignment of intellectual labor. The bottleneck has shifted. No longer is the difficulty in creating multiple choice questions; it resides now in the rigorous verification of their equivalence, in ensuring that automated outputs truly reflect nuanced scientific understanding. This demands a formalism currently absent from most applications – a provable correctness, not merely empirical validation against a test suite.
Future work must confront the inherent ambiguity of natural language. LLMs excel at mimicking patterns, but lack genuine comprehension. The paper implicitly highlights the need for a meta-language – a system for formally representing scientific concepts and their relationships – against which LLM-generated content can be definitively assessed. Without such a foundation, the ‘future of work’ risks becoming a future of increasingly sophisticated error propagation.
In the chaos of data, only mathematical discipline endures. The field requires a move beyond assessing performance and towards establishing provability. The challenge is not simply to build agents that appear to reason scientifically, but to construct systems whose reasoning is mathematically sound – a pursuit demanding a level of theoretical rigor often absent in current explorations of artificial intelligence.
Original article: https://arxiv.org/pdf/2602.18891.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-24 22:29