Author: Denis Avetisyan
Researchers have demonstrated that a surprisingly simple vision-language-action model can achieve state-of-the-art performance in robotic manipulation tasks.
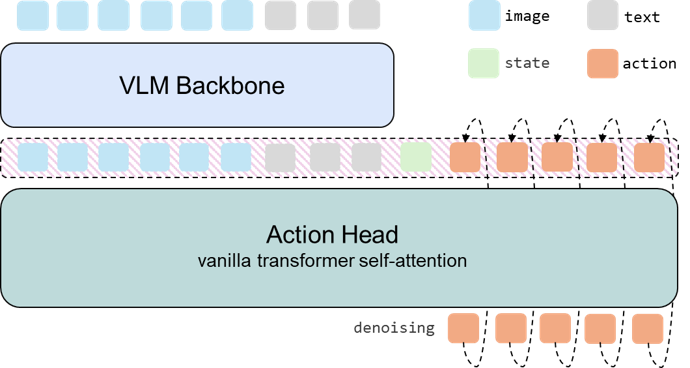
SimVLA, a standardized and modular VLA baseline leveraging flow matching, proves that well-tuned simplicity can outperform larger, more complex robotic learning systems.
Recent advances in vision-language-action (VLA) models for robotic manipulation have been hampered by inconsistent implementation details, obscuring the true source of performance gains. To address this, we introduce SimVLA: A Simple VLA Baseline for Robotic Manipulation, a streamlined and standardized framework designed as a transparent reference point for the field. Remarkably, this minimalist design-featuring only 0.5B parameters-achieves state-of-the-art simulation results and competitive real-robot performance compared to significantly larger models, demonstrating that careful tuning and modularity can outweigh architectural complexity. Does SimVLA represent a viable path toward more interpretable and reproducible progress in general-purpose robotic learning?
The Inevitable Gap: Perception, Language, and Embodied Action
While artificial intelligence has demonstrated remarkable capabilities in areas like image recognition and natural language processing, a significant challenge remains in translating this ‘intelligence’ into physical action within the real world. Traditional AI systems frequently operate on abstract data, excelling at identifying objects or understanding commands, but lacking the crucial ability to ground these perceptions in effective, embodied behavior. This disconnect stems from a reliance on static datasets and a limited capacity to adapt to the unpredictable complexities of a dynamic environment. Consequently, even sophisticated AI can falter when tasked with performing simple, everyday actions – a clear indication that true intelligence requires a seamless integration of perception, language, and, critically, the capacity for robust, grounded action.
The development of Vision-Language-Action (VLA) learning represents a significant advancement in artificial intelligence, striving to equip robotic systems with the capacity to not only perceive the world through vision and comprehend instructions via language, but also to effectively act within it. This interdisciplinary field moves beyond isolated capabilities, fostering a holistic approach where visual input and linguistic commands are seamlessly integrated to guide physical actions. By training algorithms to associate what is seen and said with appropriate motor responses, VLA learning enables robots to perform complex tasks in dynamic environments, ranging from manipulating objects based on verbal requests to navigating unfamiliar spaces guided by textual descriptions. Ultimately, this convergence of perception, language, and action is essential for creating truly intelligent and versatile robotic agents capable of meaningful interaction with the physical world.
Despite advancements in vision-language-action (VLA) models, a significant challenge remains in achieving reliable performance during extended, intricate tasks. Current systems frequently exhibit fragility when confronted with unexpected environmental changes, subtle variations in object appearance, or the cumulative effects of errors over time. This lack of robustness stems, in part, from limitations in efficiently planning and executing sequences of actions that require anticipating future states and recovering from inevitable disruptions. While VLA models can often succeed in simple, well-defined scenarios, scaling to complex, long-horizon tasks – such as autonomously navigating a cluttered room to fetch a specific item – demands substantial improvements in both algorithmic efficiency and the ability to generalize learned behaviors to novel situations. The pursuit of more resilient and adaptable VLA systems is therefore critical for realizing the full potential of embodied artificial intelligence.

SimVLA: A Baseline Built on Inevitable Compromises
SimVLA is designed as a foundational model for Visual-Language Agent (VLA) research, explicitly prioritizing both transparency and rigorous performance evaluation. Unlike many existing VLAs which are complex and often lack detailed documentation, SimVLA adopts a modular architecture with clearly defined components. This allows for easier inspection, modification, and analysis of the model’s behavior. The streamlined design isn’t intended to represent the highest possible performance ceiling, but rather to provide a well-understood and reproducible baseline against which more complex VLA architectures can be compared and benchmarked. The focus on reproducibility facilitates wider adoption and accelerates progress in the field by providing a common reference point for researchers.
SimVLA’s foundational component is a pretrained Vision-Language Model (VLM) backbone, responsible for processing both visual and textual inputs. This VLM encodes perceptual information derived from visual observations and simultaneously interprets language instructions provided as input. The encoded representations, a combined embedding of visual and linguistic data, serve as a unified feature space for subsequent action planning. Utilizing a pretrained VLM leverages existing knowledge acquired from large-scale datasets, reducing the need for extensive task-specific training and improving generalization capabilities. The VLM backbone effectively bridges the gap between visual perception and language understanding, allowing SimVLA to reason about the environment based on both modalities.
The SimVLA architecture employs a lightweight Action Head to convert the encoded perceptual and linguistic information from the VLM Backbone into continuous action outputs. This head utilizes Flow Matching, a probabilistic modeling technique, to learn a continuous trajectory from the encoded state to the desired action. By framing the action prediction as a continuous process, Flow Matching facilitates stable and efficient learning, particularly when dealing with complex, high-dimensional action spaces. This approach contrasts with discrete action selection methods and allows for finer-grained control and more naturalistic robot behaviors, while minimizing computational overhead due to the head’s streamlined design.
SimVLA’s architecture is designed for computational efficiency, enabling both rapid training and evaluation. Utilizing a pretrained Vision-Language Model as its foundation and a lightweight Action Head, the model achieves state-of-the-art performance on relevant benchmarks with a significantly reduced memory footprint compared to existing approaches. This is achieved through the streamlined design, minimizing parameter count and computational complexity without sacrificing performance. Evaluations demonstrate that SimVLA can be trained and deployed on hardware with limited resources, facilitating broader accessibility and scalability for VLA research.
The Devil is in the Details: Data, Conditioning, and Normalization
Data shuffling is a critical component of SimVLA training to mitigate overfitting and enhance generalization performance. During each epoch, the training dataset is randomly reordered before being presented to the model. This process prevents the model from learning spurious correlations present in the original data ordering, which can lead to biased predictions and poor performance on unseen data. By exposing the model to a diverse range of data samples in each batch, shuffling promotes more robust feature learning and reduces the risk of memorizing the training set. The implementation ensures complete randomization of the data sequence, preventing any systematic bias introduced by the initial data arrangement and contributing to improved model stability and accuracy.
The SimVLA Action Head utilizes conditional AdaLN (Adaptive Layer Normalization) and Token Concatenation to integrate visual and linguistic information during action generation. Specifically, visual and linguistic inputs are first encoded into feature vectors. These vectors are then used to modulate the layer normalization parameters within the Action Head, allowing the network to dynamically adjust its behavior based on the input context. Token Concatenation further refines this conditioning by directly appending linguistic tokens to the visual feature representation, providing a more granular and informative signal for action prediction. This combined approach enables the Action Head to generate actions that are both visually grounded and linguistically informed, improving task performance and generalization.
Action Normalization is implemented within the SimVLA framework to address potential instability during training and to maintain appropriate action magnitudes. This process involves normalizing the output of the action head, specifically scaling and shifting the action vectors to a consistent range. By applying normalization, the training process becomes less sensitive to the initial distribution of actions, preventing excessively large or small action values that can hinder learning and reduce generalization. This standardization contributes to improved robustness by ensuring consistent action scaling across diverse environmental conditions and task variations, leading to more reliable performance in both simulation and real-world applications.
SimVLA achieves a 96.4% average success rate on the LIBERO Long suite and 95.8% on the WidowX benchmark, demonstrating performance exceeding that of many larger models. These results were obtained through the combined implementation of data shuffling for overfitting prevention, conditional AdaLN and token concatenation within the Action Head for improved action generation, and Action Normalization to stabilize training and maintain appropriate action scaling. Performance was evaluated using standard success rate metrics for these robotic manipulation benchmarks, indicating a robust and efficient system despite a comparatively smaller model size.
The Inevitable Limits: Towards More Resilient Agents
The SimVLA model underwent rigorous testing using the LIBERO benchmark, a challenging platform designed to evaluate performance on extended, multi-step tasks and consistency in execution. Results demonstrate SimVLA’s capacity to not only complete these long-horizon objectives, but to do so with remarkable semantic robustness, achieving scores between 98% and 100% on the particularly demanding LIBERO-PRO subset. This high level of performance suggests the model effectively understands and maintains task goals even when presented with subtle variations in instructions or environmental conditions, representing a significant step towards reliable and adaptable robotic agents capable of functioning in complex real-world scenarios.
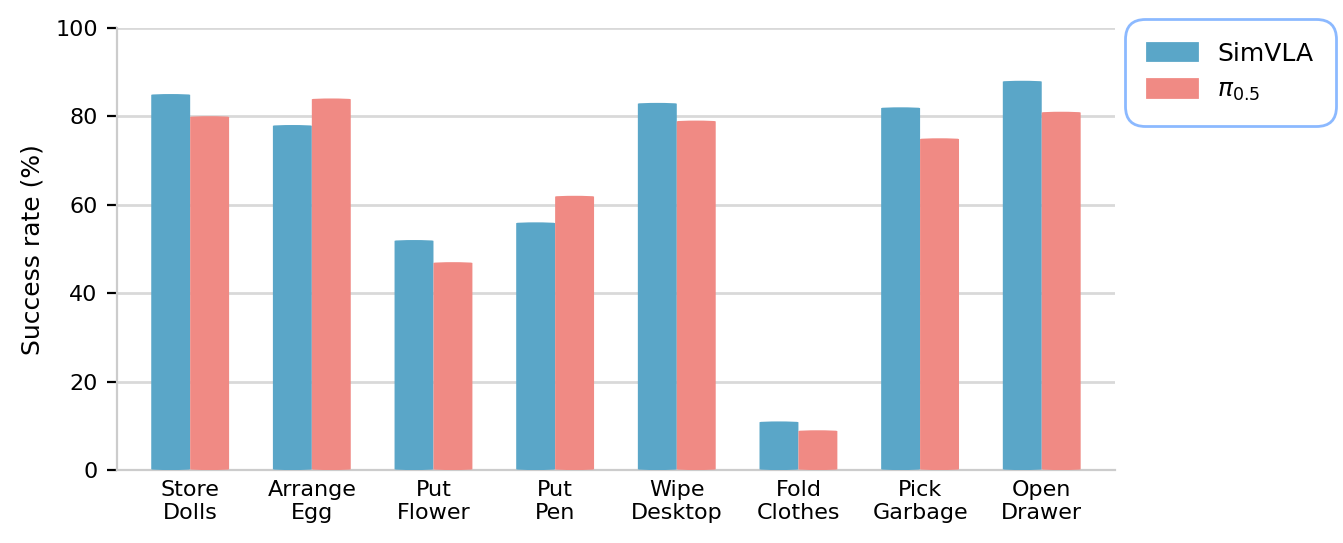
Recent validation efforts demonstrate the practical applicability of the SimVLA model through deployment on a Galaxea R1 Lite robotic platform. Remarkably, the system achieved success rates comparable to those of the established π0.5 model, despite being trained entirely from scratch – crucially, without any prior robotic pre-training. This finding highlights SimVLA’s capacity for rapid adaptation and effective generalization to real-world scenarios, suggesting a viable pathway towards creating robust robotic agents capable of performing complex tasks with minimal reliance on extensive, specialized datasets or pre-existing robotic knowledge. The ability to bypass robotic pre-training represents a significant advancement, lowering the barrier to entry for developing intelligent robotic systems and enabling broader accessibility to advanced automation technologies.
Integrating three-dimensional spatial awareness into Vision-Language Action (VLA) models represents a significant step towards more effective robotic agents. Current VLA models often struggle with nuanced environmental understanding, limiting their ability to perform complex tasks requiring precise object manipulation and navigation. By equipping these models with the capacity to interpret depth information and construct a comprehensive 3D representation of their surroundings, researchers aim to enhance their ability to reason about spatial relationships, predict object trajectories, and plan collision-free paths. This enhanced spatial reasoning not only improves task execution accuracy but also fosters greater robustness in dynamic and unstructured environments, allowing robotic agents to adapt more readily to unforeseen circumstances and achieve a more human-like level of environmental mastery.
Continued development of SimVLA centers on broadening its operational scope and refining the granularity of its control mechanisms. Researchers aim to move beyond current capabilities by investigating more intricate action distributions, allowing for nuanced and adaptable robotic behaviors. This involves exploring methods to represent and implement a wider range of possible actions, moving from simple, discrete commands to continuous, parameterized control signals. Such advancements promise to unlock more sophisticated task execution, enabling robotic agents to handle complex scenarios with greater precision and efficiency, ultimately leading to more robust and versatile performance in real-world applications.
The pursuit of robotic manipulation, as demonstrated by SimVLA, isn’t about erecting monolithic structures of complexity. It’s about fostering an ecosystem where simplicity, carefully nurtured, yields unexpected robustness. The paper’s success with a minimalist design echoes a fundamental truth: over-engineering invites future fragility. As Vinton Cerf observed, “The Internet treats everyone the same.” This echoes in SimVLA’s approach – a standardized baseline that levels the playing field, allowing for focused refinement rather than architectural bloat. The system doesn’t solve manipulation; it provides fertile ground for growth, acknowledging that the true work lies not in building, but in attentive tending.
The Turning of the Wheel
SimVLA, in its deliberate simplicity, offers not a destination, but a re-calibration. Every dependency is a promise made to the past, and this work suggests that the future of robotic manipulation may lie not in amassing complexity, but in refining the echoes of what already works. The pursuit of ever-larger models feels increasingly like building a taller tower on shifting sands; this baseline, however, begins to resemble a foundation-though every foundation, inevitably, will require repair.
The standardization achieved here is a fragile thing. Systems aren’t tools; they’re ecosystems. A standardized training regime will, by its very nature, select for certain solutions, inevitably obscuring others. The real challenge isn’t achieving transfer to a single real-world robot, but anticipating the myriad failures that will arise as these systems proliferate into increasingly unpredictable environments. Control is an illusion that demands SLAs.
It is a curious observation that the most successful systems often begin fixing themselves. The cycle will turn again: limitations will be revealed, new abstractions will emerge, and the next baseline will appear. This isn’t progress, precisely-merely the continued unfolding of inherent constraints. The question isn’t whether these systems will fail, but how they will reveal the limits of their design.
Original article: https://arxiv.org/pdf/2602.18224.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-23 18:13