Author: Denis Avetisyan
New research reveals that human ratings of conversational recommender systems are surprisingly susceptible to bias, casting doubt on their use as reliable benchmarks.
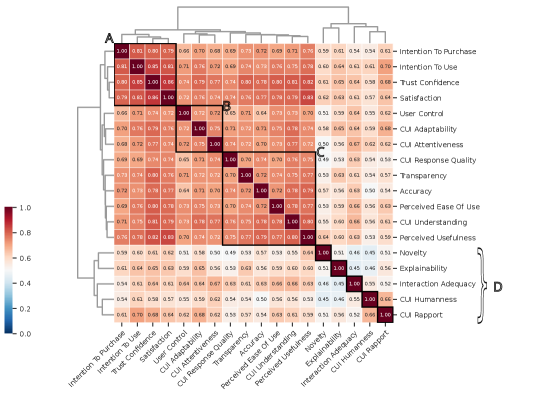
Crowdsourced evaluations of conversational recommender systems often collapse into a single quality signal, necessitating careful aggregation and raising concerns about using them as ground truth for large language model evaluation.
Despite the increasing reliance on user-centric metrics for evaluating Conversational Recommender Systems (CRS), the validity of assessing these subjective qualities-such as satisfaction and rapport-through third-party annotations remains largely unexamined. This work, ‘On the Reliability of User-Centric Evaluation of Conversational Recommender Systems’, presents a large-scale empirical study revealing that crowdsourced evaluations of CRS dialogues exhibit moderate reliability for utilitarian dimensions but struggle with socially grounded constructs, often collapsing into a single, generalized quality signal. These findings challenge the use of single annotators or LLM-based approaches as reliable proxies for genuine user experience. How can we develop more robust and nuanced evaluation protocols that accurately capture the complex interplay of factors influencing user perception in conversational recommendation?
The Illusion of Conversation: Why Metrics Fail Us
Truly effective conversational recommender systems demand more than simply finding relevant items; they necessitate an assessment of subjective qualities like empathy and adaptability, characteristics proving difficult to quantify with traditional metrics. Current evaluation techniques often prioritize easily measurable aspects – click-through rates or task completion – while overlooking the crucial nuances of human interaction. A system capable of genuinely understanding a user’s emotional state and flexibly adjusting its recommendations accordingly requires evaluation methods that move beyond these simplistic proxies, probing for qualities like sensitivity to user needs and the ability to navigate complex or ambiguous requests. This shift necessitates exploring novel approaches, potentially incorporating qualitative analyses and user studies focused on perceived empathy and conversational flow, to accurately gauge a system’s ability to build rapport and deliver a truly personalized experience.
The pursuit of truly intelligent conversational recommender systems is hampered by a fundamental limitation: the inability of current evaluation methods to fully represent the richness of human interaction. While objective metrics like precision and recall offer quantifiable assessments, they fall short in capturing the subjective qualities – empathy, adaptability, and genuine understanding – that define a successful conversation. These metrics often treat dialogue as a transaction, overlooking the nuanced emotional states and evolving needs of the user. Consequently, systems optimized solely for objective scores may exhibit superficial fluency but lack the ability to build rapport or provide genuinely helpful recommendations, ultimately hindering progress towards creating AI that can truly engage with and assist humans in a meaningful way.
Current methods for judging conversational recommender systems frequently depend on easily measured, yet ultimately superficial, indicators of user satisfaction, such as the length of the conversation or the number of items ‘clicked’. While convenient, these proxies often fail to correlate with genuine user experience; a longer interaction doesn’t necessarily equate to a more helpful or enjoyable one, and clicking on a recommendation doesn’t guarantee actual satisfaction with the suggested item. Consequently, systems optimized for these simplistic metrics can exhibit misleading performance gains – appearing successful according to automated evaluations, while delivering suboptimal or even frustrating experiences for users. This disconnect between proxy metrics and true user satisfaction poses a significant challenge to the field, potentially hindering the development of truly empathetic and adaptable conversational agents.
Beyond Accuracy: User-Centric Evaluation Frameworks
User-Centric Evaluation (UCE) represents a shift in system assessment from objective, quantitative measures – such as precision, recall, or error rate – to incorporate qualitative aspects of the user experience. Traditional metrics often fail to capture crucial elements like user satisfaction, perceived usefulness, or ease of interaction. UCE frameworks address this limitation by focusing on subjective qualities through methodologies like questionnaires, interviews, and usability testing. These methods allow researchers and developers to gauge how users feel about an interaction, not just whether the system produced a technically correct output. By prioritizing the user’s perspective, UCE aims to create systems that are not only accurate but also enjoyable, efficient, and effective in meeting user needs.
The ResQue (Research Questionnaire for Evaluating Conversational Systems) instrument facilitates the conversion of subjective interaction qualities – such as helpfulness, understandability, and naturalness – into measurable data through a standardized questionnaire. It achieves this by defining specific, observable behaviors that exemplify each quality, then creating Likert-scale questions designed to assess the degree to which those behaviors were present during user interaction. This allows researchers to move beyond holistic, qualitative assessments and instead obtain quantifiable scores for each subjective quality, enabling statistically rigorous comparisons between different conversational systems or system iterations. The instrument’s modular design also permits customization, allowing researchers to prioritize and emphasize qualities most relevant to their specific evaluation goals.
CRS-Que builds upon the ResQue instrument by adapting its methodology to address the specific evaluation needs of conversational recommendation systems. Unlike traditional recommendation evaluation focusing on metrics like precision and recall, CRS-Que assesses subjective qualities – such as helpfulness, understandability, and naturalness – within the context of a dialogue. It achieves this through a questionnaire designed to capture user perceptions of the conversation, considering aspects unique to interactive recommendation, like the clarity of clarifying questions, the appropriateness of suggestions given the dialogue history, and the overall user experience during the conversational process. The resulting data provides a quantifiable assessment of these subjective qualities, enabling systematic comparison and improvement of conversational recommendation systems beyond purely accuracy-based measures.
The Illusion of Scale: Annotation and Analysis Methods
Third-party evaluation utilizes external resources – either human crowd workers or Large Language Models – to analyze static dialogue logs, offering a method for generating large datasets suitable for quantitative analysis. This approach circumvents the limitations of manual annotation by enabling the assessment of numerous dialogues at a reduced cost and within a shorter timeframe. Data generated through third-party evaluation can be applied to tasks such as identifying patterns in conversational behavior, evaluating the performance of dialogue systems, or training machine learning models. The resulting datasets are particularly valuable for research requiring statistically significant sample sizes that would be impractical to obtain through solely internal resources.
Crowdsourcing provides a scalable method for collecting annotations by distributing annotation tasks to a large, heterogeneous group of individuals. This approach allows for the efficient processing of substantial datasets, exceeding the capacity of a limited internal team. Utilizing a diverse pool of raters mitigates potential biases inherent in a smaller, more homogenous group and increases the generalizability of the resulting annotations. Data collected through crowdsourcing requires careful statistical validation to account for individual rater variability and ensure the reliability of aggregated results, but it remains a cost-effective solution for obtaining the large-scale human assessments needed for dialogue system evaluation and analysis.
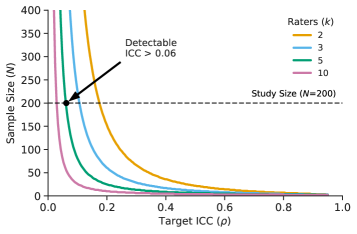
Ensuring annotation reliability necessitates the application of robust statistical methods. Random-Effects Modeling accounts for variation between raters, while Correlation Analysis assesses the relationships between their judgments. Inter-rater agreement is quantified using metrics such as Krippendorff’s Alpha and the Intraclass Correlation Coefficient (ICC). Our research indicates that, with a minimum of k=5 raters evaluating N=200 dialogues, there is 80% statistical power to detect an ICC as low as approximately 0.06, establishing a threshold for identifying potentially unreliable annotations and informing necessary adjustments to the annotation process or rater training.
Analysis of crowd-sourced dialogue evaluations indicated susceptibility to rater bias; however, aggregation of ratings yielded reliable signals, particularly when assessing task- and outcome-oriented constructs. Empirical results from our study demonstrated a reliability score of 0.6, as measured by the Reldial(k) metric, for these specific construct types. This suggests that while individual raters may exhibit bias, the collective judgment provides a valid and dependable assessment when focused on measurable task completion and outcomes.
The Bottom Line: Trust, Satisfaction, and the User’s Intent
Rigorous evaluation consistently demonstrates a significant link between how users feel about a conversational recommender system and fundamental aspects of its usability. Studies reveal strong correlations between subjective qualities – such as perceived helpfulness, naturalness of dialogue, and overall enjoyment – and core dimensions of user experience, including trust in the system’s suggestions, satisfaction with the interaction, and the user’s intent to continue using the system long-term. This isn’t merely about providing accurate recommendations; it highlights that positive emotional responses and a sense of rapport directly influence whether a user will adopt and rely on the technology, suggesting that prioritizing these factors is crucial for successful system design and implementation.
Conversational recommender systems stand to gain significantly from designs that prioritize both empathy and adaptability. Recognizing user needs isn’t simply about accurate prediction; it requires systems to demonstrate understanding of the user’s emotional state and adjust communication accordingly. A system capable of gauging user frustration, for example, can proactively offer assistance or rephrase recommendations, fostering a more positive interaction. Furthermore, adaptability allows the system to learn from each dialogue, refining its understanding of individual preferences and tailoring future recommendations with increasing precision. This dynamic responsiveness not only enhances user satisfaction but also builds trust, ultimately driving continued engagement and solidifying the system’s value as a personalized guide.
Developers building conversational recommender systems stand to gain significantly by centering design around key user experience drivers like trust, satisfaction, and intention to use. Beyond simply providing relevant recommendations, prioritizing these elements cultivates interactions that users find genuinely positive and compelling. This approach moves beyond functional utility, fostering a sense of connection and encouraging continued engagement with the system. By deliberately shaping these subjective qualities, developers can create not just effective tools, but experiences that users actively want to use, ultimately boosting long-term adoption and user loyalty. A focus on these drivers ensures the system is perceived as helpful, reliable, and even enjoyable, exceeding expectations beyond mere task completion.
The study demonstrated a robust ability to detect meaningful relationships between evaluation metrics and user experience factors. With a sample size of 200 conversational dialogues, researchers achieved 80% statistical power to identify correlations of at least medium strength (r=0.3). This indicates a high degree of confidence in the findings, as the methodology was sensitive enough to detect effects of this magnitude. Furthermore, the expected width of the 95% confidence interval for reliability was calculated at 0.12 (ρ=0.6), suggesting a relatively narrow range of uncertainty around the estimated correlation coefficients and bolstering the validity of the observed connections between system evaluation and user perceptions.
The pursuit of truly objective evaluation in conversational recommender systems feels increasingly Sisyphean. This paper confirms what experience suggests: human assessment, even crowdsourced, isn’t a path to neutral ground. The ‘halo effect’ described within, where initial impressions dominate subsequent ratings, merely underscores a fundamental truth. As John von Neumann observed, “The best way to predict the future is to invent it.” But inventing metrics doesn’t magically solve the problem of subjective judgment; it simply creates a new, often more opaque, layer of complexity. The reliance on single human annotations as ‘ground truth’ for evaluating LLMs feels particularly precarious, given the demonstrated biases. It’s a clean theoretical construct destined to be muddied by production realities.
The Road Ahead (and It’s Probably Paved with Good Intentions)
The demonstrated susceptibility of conversational recommender system (CRS) evaluation to the halo effect and inter-rater disagreement isn’t exactly news. Anyone who’s deployed a system at scale understands that production is, invariably, the best QA. But this work helpfully formalizes the observation that human judgment, even when crowdsourced, collapses into a frustratingly singular signal. The quest for ‘user-centric’ evaluation feels increasingly circular; it seems the signal isn’t about the system, but about the evaluator’s mood on Tuesday.
Future efforts will likely focus on increasingly elaborate attempts to disentangle these biases-more granular rating scales, carefully crafted prompts, perhaps even incentivizing disagreement. The field chases ever-refined metrics, but it’s worth remembering that everything new is old again, just renamed and still broken. The problem isn’t finding a signal; it’s accepting that the signal is inherently noisy and subjective.
The increasing reliance on large language models (LLMs) as evaluators adds another layer of complexity. If human annotations are unreliable ground truth, what does it mean to train an LLM on that data? It’s a sophisticated echo chamber, potentially amplifying existing biases. The truly interesting question isn’t whether LLMs can judge CRSs, but whether they can consistently judge them wrong in a predictable way.
Original article: https://arxiv.org/pdf/2602.17264.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-22 14:49