Author: Denis Avetisyan
Researchers have created a challenging new environment to train artificial intelligence to write and understand code more effectively, pushing the boundaries of task transferability.
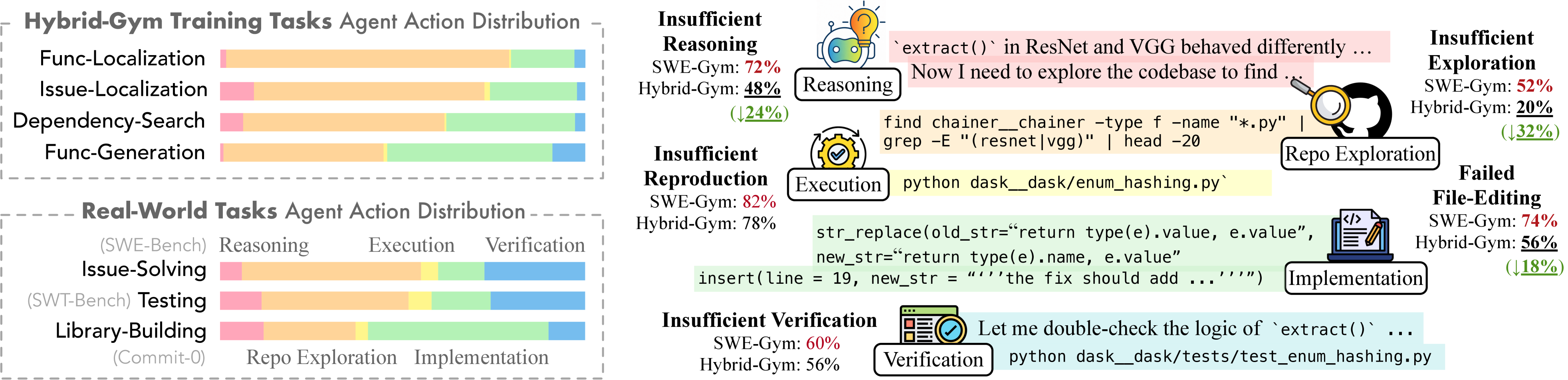
Hybrid-Gym is a scalable synthetic dataset designed to improve the generalization of coding agents by focusing on core skills like reasoning and repository exploration.
While current benchmarks for coding agents largely focus on isolated issue resolution, real-world software engineering demands broader skillsets encompassing codebase understanding, testing, and architectural design. This paper introduces ‘Hybrid-Gym: Training Coding Agents to Generalize Across Tasks’-a novel training environment built on scalable, synthetic tasks designed to cultivate transferable skills like reasoning and repository exploration. Experiments demonstrate that agents trained with Hybrid-Gym achieve significant performance gains on downstream benchmarks-improving by up to 25.4% on SWE-Bench Verified-and even complement existing datasets. Could this approach to skill-focused pre-training unlock a new generation of more robust and adaptable coding assistants?
The Inevitable Shift: Software Creation Under Automation
The landscape of software creation is undergoing a dramatic shift, driven by the ever-increasing complexity of modern applications and an unrelenting demand for faster development cycles. Contemporary software projects routinely involve millions of lines of code, intricate dependencies, and rapidly evolving requirements, placing immense strain on traditional development workflows. This complexity isn’t merely a matter of scale; it also stems from the proliferation of diverse platforms, architectures, and programming languages. Consequently, the need for automation isn’t simply about improving efficiency, but about maintaining feasibility – enabling developers to manage this growing cognitive load and deliver innovative solutions at a pace that meets contemporary expectations. The escalating shortage of skilled software engineers further exacerbates this challenge, intensifying the pressure to find ways to augment human capabilities through intelligent automation.
The escalating demands on software development, coupled with increasing project complexity, have spurred exploration into automated solutions, and coding agents represent a particularly promising avenue. These agents leverage the power of large language models – sophisticated artificial intelligence capable of understanding and generating human-like text – to tackle coding tasks. Rather than replacing developers entirely, the intention is to augment their capabilities, automating repetitive work like boilerplate code generation, bug fixing, and test case creation. This allows human programmers to focus on higher-level design and problem-solving. Initial demonstrations show these agents can translate natural language instructions into functional code, significantly accelerating development cycles and potentially lowering the barrier to entry for aspiring programmers. While still in its early stages, the potential for these agents to reshape the software development landscape is substantial, offering a path toward greater efficiency and innovation.
Truly effective coding agents transcend simple code generation; they necessitate a sophisticated comprehension of pre-existing code structures and the ability to navigate complex codebases with nuance. These agents must not merely produce syntactically correct code, but also understand the intent behind existing functions, identify dependencies, and seamlessly integrate new code without introducing errors or disrupting functionality. This requires advanced techniques in code analysis, symbolic execution, and knowledge representation, allowing the agent to reason about code at a semantic level – essentially ‘reading’ and ‘understanding’ code as a human developer would. Successfully navigating established projects demands an agent capable of pinpointing relevant code segments, tracing execution paths, and adapting to diverse coding styles and architectural patterns – a far more challenging feat than generating isolated snippets from scratch.
Despite remarkable advances in code generation, a substantial challenge for coding agents lies in their ability to generalize beyond the specific examples they were trained on. While these agents can often produce functional code for familiar tasks, performance frequently degrades when presented with novel problems or variations in existing codebases. This limitation stems from the difficulty in transferring learned patterns to unseen scenarios, requiring agents to not only understand syntax and semantics but also to reason about the underlying intent and context of the code. Current research focuses on techniques such as meta-learning and reinforcement learning to enhance this generalization capability, enabling agents to adapt more effectively to the ever-evolving landscape of software development and ultimately bridge the gap between narrow task completion and robust, autonomous coding.
Core Capabilities: The Anatomy of an Effective Agent
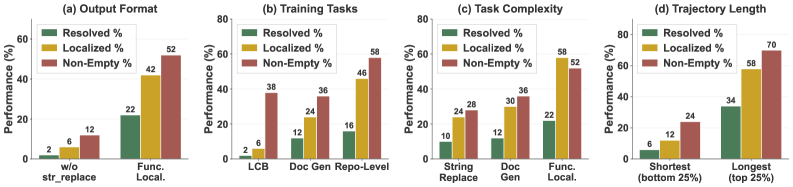
Effective coding agents necessitate three core capabilities for autonomous code manipulation: function localization, dependency understanding, and code generation. Function localization involves identifying relevant code segments within a codebase based on a given task or query. Dependency understanding requires the agent to analyze relationships between different code components, including libraries, modules, and other functions, to ensure correct execution and avoid conflicts. Finally, code generation is the ability to synthesize new code based on identified functions, understood dependencies, and the overall objective; this includes tasks like completing partially written functions or creating new functions from scratch.
Effective coding agents require the integrated operation of function localization and dependency search to accurately generate code. Function localization identifies relevant code segments, while dependency search determines the external components those segments rely on. Isolated operation of these capabilities leads to incomplete or inaccurate code generation; an agent must first locate a function and then identify its dependencies to ensure all necessary components are available and correctly integrated. This integration minimizes errors arising from missing or incompatible dependencies, and enables the agent to produce functional and reliable code by establishing a complete understanding of the code’s requirements and context.
Accurate function generation necessitates reliable code execution and verification procedures. Agents require a mechanism to not only synthesize code but also to test its functionality in a controlled environment. This typically involves executing the generated code with predefined test cases and comparing the actual output against expected results. Verification methods can range from simple unit tests to more complex property-based testing and formal verification techniques. Furthermore, robust error handling and debugging capabilities are crucial for identifying and correcting inaccuracies in the generated code, ensuring that the agent can iteratively improve its function generation performance. The ability to confidently assess code correctness is paramount for building trustworthy and dependable agents.
Automated documentation, specifically through docstring generation, significantly enhances software maintainability and facilitates collaborative development. Docstrings, embedded within code as string literals, provide inline documentation detailing function purpose, arguments, return values, and potential exceptions. Automatically generating these docstrings reduces the burden on developers, ensuring documentation remains current with code changes. This practice is crucial because outdated documentation is a major impediment to understanding and modifying codebases, especially in team environments. Consistent and automatically updated docstrings enable developers to quickly grasp function interfaces and intended behavior, minimizing errors and accelerating development cycles. Furthermore, docstrings are utilized by numerous tools for API documentation generation and static analysis, providing a standardized and machine-readable format for code understanding.
Rigorous Validation: Benchmarking and Data-Driven Evaluation
Benchmarking suites such as SWE-Bench, SWT-Bench, and Commit-0 are vital for objective assessment of coding agent capabilities. SWE-Bench focuses on solving a wide range of software engineering problems, while SWT-Bench specifically tests the ability to solve competitive programming style tasks. Commit-0 assesses a coding agent’s capacity to create functional code from natural language commit messages. Utilizing these benchmarks allows for standardized performance comparisons between different models and training methodologies, facilitating iterative improvement and identifying areas where agents struggle across diverse task types and complexity levels. Quantitative results derived from these benchmarks provide a measurable basis for evaluating progress in the field of AI-assisted coding.
Large-scale training datasets are critical for enhancing the generalization and robustness of coding agents. Hybrid-Gym addresses this need by providing a substantial collection of 4,400 unique trajectories, enabling agents to encounter a wider range of scenarios during training. This increased exposure to diverse problem-solving paths and code structures improves the agent’s ability to perform reliably on previously unseen tasks and adapt to variations in input requirements, ultimately leading to more dependable performance in real-world applications.
Qwen2.5Coder serves as a robust base model for coding agent development, demonstrably enhancing performance when paired with large-scale training data. Specifically, training Qwen2.5Coder with the Hybrid-Gym dataset resulted in a 25.4% performance increase on the SWE-Bench Verified benchmark. This improvement indicates that Hybrid-Gym effectively equips the model with enhanced generalization capabilities and robustness across a variety of coding tasks, establishing a quantifiable benefit to utilizing comprehensive training datasets in conjunction with advanced base models like Qwen2.5Coder.
OpenHands is a unified framework designed to accelerate the development and evaluation of coding agents. It provides a standardized interface for interacting with various benchmarks, including SWE-Bench and SWT-Bench, simplifying the process of performance assessment. The framework integrates tools for data collection, model training, and automated evaluation, reducing the engineering effort required to iterate on agent designs. Furthermore, OpenHands supports distributed training and evaluation, enabling scalability for large models and datasets, and features modular components allowing for easy customization and extension to support new environments and tasks.
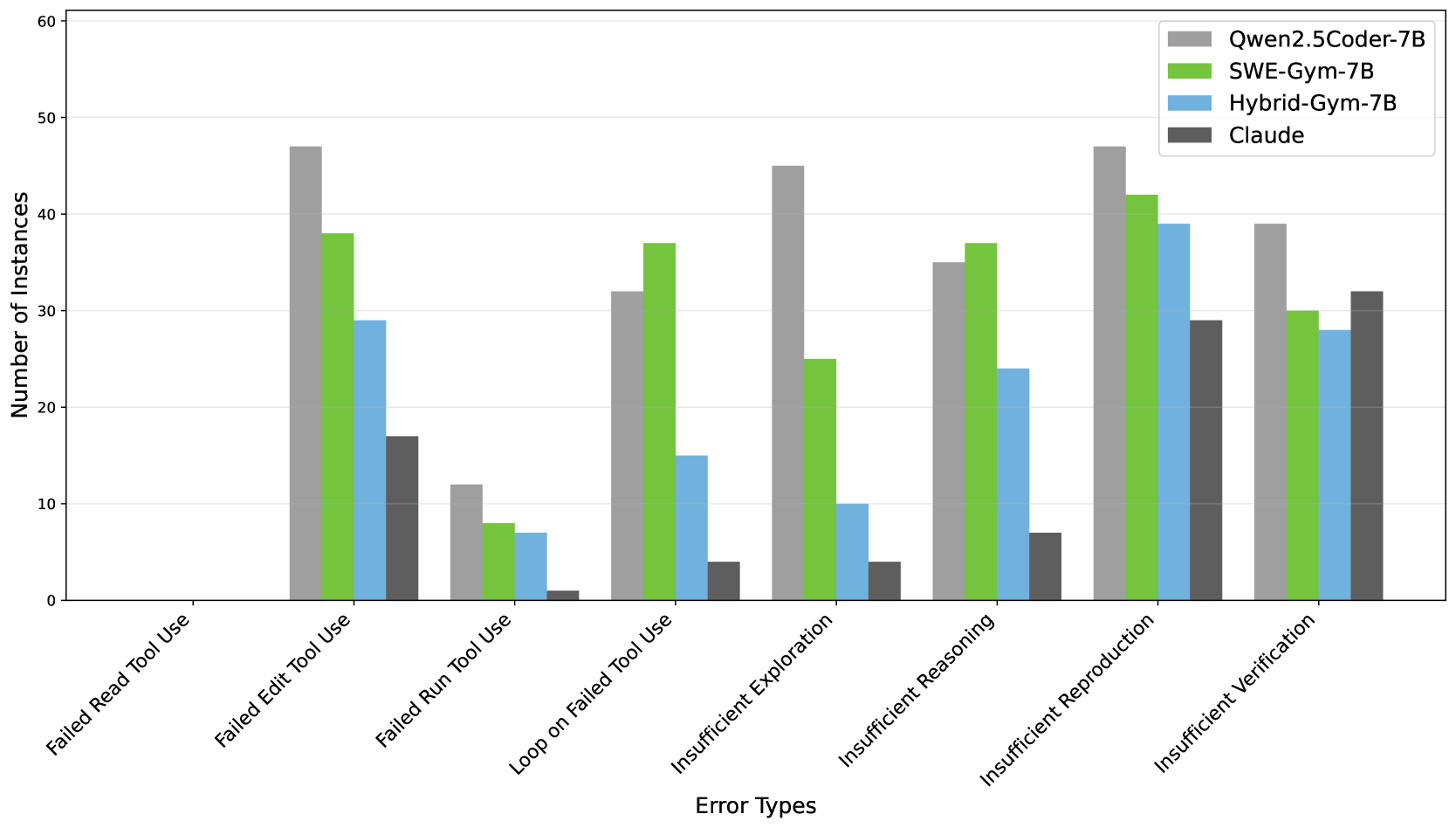
Refining Agent Performance: Finetuning and Modular Integration
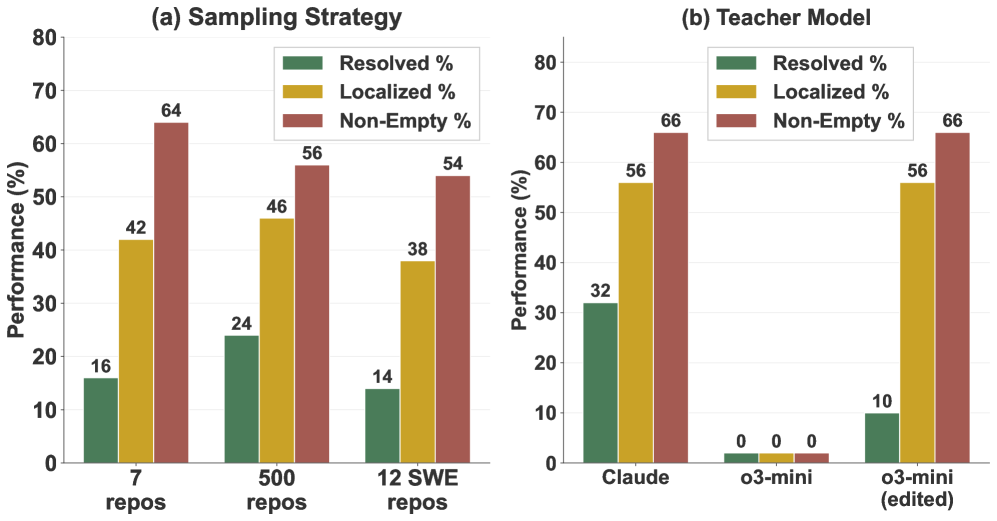
Rejection sampling is a finetuning technique used to improve the performance of language model-based agents on specific tasks by selectively accepting or rejecting generated outputs based on a predefined quality criterion. This process involves generating multiple candidate solutions and then applying a scoring function – often based on test-driven evaluation or a learned reward model – to assess their correctness or desirability. Only outputs that meet a certain threshold, determined by the scoring function, are accepted, while the rest are discarded and new candidates are generated. This iterative process ensures that the agent primarily learns from high-quality examples, leading to improved performance metrics and a more robust skillset focused on the target task. The efficacy of rejection sampling hinges on the quality of the scoring function and the balance between accepting enough samples to facilitate learning and rejecting poor samples to maintain a high standard of performance.
Effective handling of complex coding challenges requires the decomposition of problems into fundamental subtasks. Specifically, agents benefit from integrated capabilities in issue localization – identifying the source of a bug or feature request – function localization, which pinpoints the relevant code sections to modify, and dependency search, enabling the agent to understand relationships between different code components. By systematically addressing these subtasks, agents can navigate large codebases, accurately target modifications, and reduce errors, ultimately improving performance on tasks requiring code comprehension and alteration.
Effective modification of existing codebases necessitates robust file editing capabilities for coding agents. This includes not only the ability to accurately locate and parse files within a project structure, but also to perform precise insertions, deletions, and replacements of code segments. Inefficient file handling – such as incorrect parsing, inability to manage large files, or errors in syntax – can introduce bugs, disrupt program functionality, and significantly degrade agent performance. Agents must reliably manage file I/O, handle various file encodings, and maintain code formatting consistency to ensure successful integration of changes into the target codebase.
Knowledge transfer between tasks is a critical factor in improving the adaptability and real-world applicability of coding agents. Empirical results demonstrate this, with agents trained using Hybrid-Gym exhibiting a 25.4% performance increase on the SWE-Bench Verified benchmark. Furthermore, this training methodology yielded improvements of 7.9% on the SWT-Bench Verified dataset and 5.1% on the Commit-0 Lite benchmark, indicating a consistent benefit across diverse coding challenges. These gains highlight the efficacy of strategies designed to promote generalization and the reuse of learned skills in novel situations.
The pursuit of genuinely intelligent coding agents, as demonstrated by Hybrid-Gym, necessitates a departure from superficial performance metrics. The dataset’s focus on core skills – reasoning and repository exploration – echoes a fundamental principle of mathematical elegance. Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” This rings true; an agent can generate code, but without a solid foundation in algorithmic reasoning-the ability to know how to order its operations-it remains limited. Hybrid-Gym, by emphasizing transferable skills, aims to build agents that aren’t merely pattern-matchers, but possess a provable capacity for problem-solving, mirroring Lovelace’s vision of a machine executing defined instructions with precision.
Beyond the Synthetic Horizon
The construction of Hybrid-Gym represents a necessary, if limited, step towards robust coding agents. The demonstrated gains in transferability are encouraging, yet one must ask: are these agents truly reasoning, or simply memorizing patterns within a cleverly curated synthetic landscape? The elegance of a solution isn’t measured by its performance on a benchmark, but by the demonstrable proof of its correctness-a standard conspicuously absent from much of the current evaluation.
Future work must address the inherent fragility of synthetic data. While scalability is laudable, the pursuit of ever-larger datasets risks obscuring a fundamental truth: a single, logically sound algorithm will always outperform a million approximations. The field should prioritize the development of formal verification techniques integrated directly into the training process, allowing agents to prove their code, not merely execute it.
Ultimately, the true measure of progress will not be the ability to generate code, but the capacity to understand it. Until agents can independently derive solutions from first principles, the promise of truly autonomous software engineering remains a beautiful, yet elusive, abstraction.
Original article: https://arxiv.org/pdf/2602.16819.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-21 20:17