Author: Denis Avetisyan
Researchers have created a unique dataset revealing that AI agents approach information retrieval in fundamentally different ways than humans, challenging long-held assumptions in the field.
A new dataset, ASQ, captures the query reformulation behaviors of AI agents, demonstrating key distinctions from human search patterns and prompting a re-evaluation of core information retrieval principles.
The increasing prevalence of automated agents issuing search queries challenges core assumptions within Information Retrieval (IR), a field historically centered on human information-seeking behaviour. This necessitates a re-evaluation of established practices as agentic search patterns diverge from those of human users, potentially impacting system performance and optimisation strategies. In ‘A Picture of Agentic Search’, we address this gap by introducing the Agentic Search Queryset (ASQ), a novel dataset capturing the query behaviours of AI agents across diverse tasks and retrieval pipelines. Will this detailed look into agentic search behaviours allow for the development of IR systems truly optimised for a future of collaborative human-agent information seeking?
The Illusion of Search: Keyword Matching and Its Failures
Historically, the foundation of information retrieval has rested on the principle of keyword matching – a system designed to identify documents containing specific terms entered by a user. However, this approach frequently overlooks the subtle layers of meaning and the intricate relationships that exist within text. Consequently, searches can fail to capture the true intent behind a query, particularly when dealing with concepts expressed using synonyms, implied meanings, or complex contextual dependencies. The limitations of keyword matching become especially apparent when seeking answers that require synthesizing information from multiple sources or understanding nuanced arguments, leading to results that, while containing the requested keywords, lack the comprehensive understanding necessary to address the underlying information need.
Despite their remarkable abilities in processing and generating human-like text, Large Language Models frequently encounter difficulties when tasked with multi-hop reasoning – the process of synthesizing information from multiple sources to arrive at an answer. Complex queries often demand more than simple keyword recognition; they require the model to identify relevant facts across several documents, establish logical connections between them, and then infer the final solution. This presents a significant hurdle, as LLMs, while adept at pattern recognition within a single text, can struggle to maintain coherence and accuracy when navigating and integrating information dispersed across multiple sources. Consequently, the effectiveness of these models in answering intricate questions hinges on overcoming this limitation, demanding innovative approaches to enhance their reasoning capabilities and ensure reliable performance on complex tasks.
The promise of Retrieval-Augmented Generation (RAG) – combining the strengths of pre-trained language models with external knowledge – is significantly curtailed when search inadequacies persist. While LLMs excel at generating coherent and contextually relevant text, their performance relies heavily on the quality of information initially retrieved. Insufficient reasoning depth in the search phase means crucial connections between facts, or the subtle nuances needed to answer complex questions, are often missed. Consequently, even the most powerful language model can produce inaccurate or incomplete responses if the foundational knowledge provided by the retrieval component is lacking. This necessitates the development of more robust search methodologies – those capable of discerning relationships, understanding intent, and delivering precisely the information needed to unlock the full potential of RAG systems.
Agentic Search: Modeling Intelligent Query Refinement
The Agentic Search Query (ASQ) dataset is constructed to model iterative query refinement as performed by autonomous agents. It comprises a substantial volume of search interactions, facilitating statistically robust evaluation of agentic search strategies. This dataset differs from typical search logs by explicitly capturing the full query reformulation process, including intermediate queries generated during complex task completion. The scale of ASQ enables researchers to move beyond qualitative analysis and conduct quantitative assessments of different agentic search algorithms and their impact on information retrieval performance, providing a benchmark for comparing and improving agentic systems.
Agentic search utilizes Large Language Models (LLMs) to address complex information needs through a process of query decomposition and iterative refinement. Rather than formulating a single query, the LLM breaks down the initial request into a series of sub-queries. These individual queries are then executed, and the results are analyzed to inform subsequent query formulations. This iterative cycle-of querying, analyzing, and reformulating-continues until the LLM determines that sufficient information has been gathered to satisfy the original complex request. The strategy allows for a more nuanced and adaptable search process compared to traditional methods, effectively simulating a human’s exploratory information-seeking behavior.
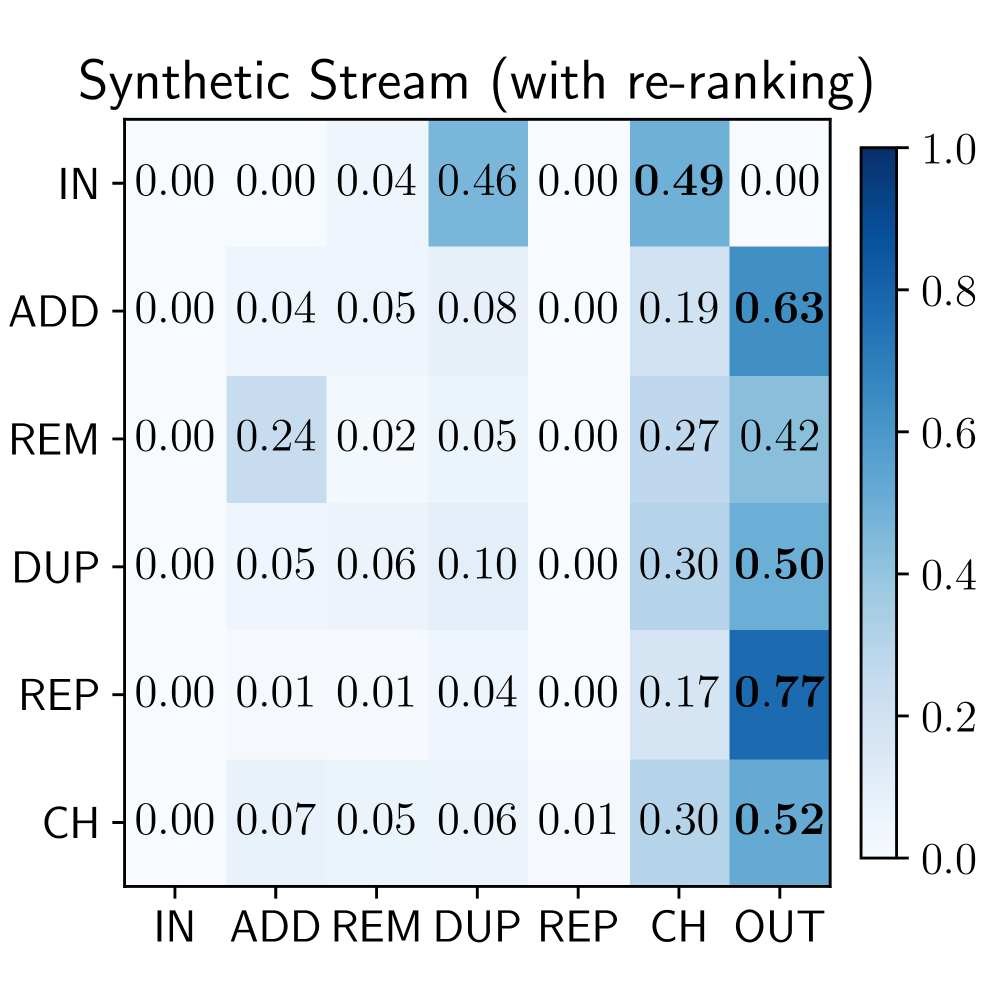
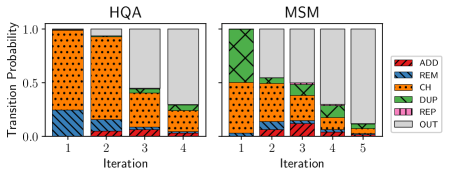
Query reformulation is a core component of agentic search, driving iterative improvements in information retrieval. Analysis of the ASQ dataset reveals a significant difference in lexical diversity between queries generated by agents and those originating from human users; synthetic queries exhibit hapax legomena ratios ranging from 21% to 43%. This contrasts sharply with organic, human-generated queries, which demonstrate hapax ratios between 62% and 78%. A lower hapax ratio in synthetic queries suggests a tendency towards reusing terms, potentially indicating a narrower exploration of the search space compared to human search behavior, but also offering opportunities for optimization through focused refinement strategies.
AutoRefine: Generating Synthetic Query Streams at Scale
AutoRefine functions as an agentic Retrieval-Augmented Generation (RAG) system specifically designed for the automated creation of Synthetic Query Streams. These streams constitute a scalable dataset of search behaviors, offering a significant advantage over reliance on manually collected user data or limited existing query logs. By employing an agentic approach, AutoRefine can iteratively refine its query generation process, producing a diverse and extensive collection of search queries suitable for evaluating and improving information retrieval systems. The resulting data can be used for tasks such as stress-testing search engines, benchmarking RAG pipelines, and analyzing user search patterns at scale, all without requiring direct user interaction.
The synthetic query stream generation process utilizes the Qwen2.5 large language model to formulate search queries. This model was selected for its capacity to produce diverse queries while maintaining relevance to the defined task. Qwen2.5’s architecture enables the system to move beyond simple keyword variations and generate queries reflecting a range of information needs and phrasing styles. This capability is crucial for creating a synthetic stream that accurately represents real user search behavior and facilitates robust evaluation of retrieval-augmented generation (RAG) systems.
AutoRefine generates a detailed execution history, termed a “Trace”, with each iteration of synthetic query stream generation. A Trace comprises a sequential record of “frames”, documenting the agent’s specific actions and the reasoning behind those actions at each step. Analysis of these Traces indicates a query repetition rate (RQ) of 5% for the AutoRefine agent, a statistically significant reduction compared to the 12% query repetition rate observed in human user search behavior. This lower repetition rate suggests the agent effectively diversifies its queries during the synthetic data generation process.
The Limits of Ranking: Evaluating Performance with ASQ
The Air Quality Search (ASQ) dataset has become a crucial resource for advancing the field of information retrieval, providing a standardized benchmark for evaluating and comparing different search methodologies. Researchers utilize ASQ to rigorously test algorithms like BM25, a widely-used ranking function based on term frequency and inverse document frequency, and more contemporary models such as MonoElectra, a powerful language model adapted for search tasks. This dataset allows for quantifiable comparisons of retrieval performance, measuring metrics like precision, recall, and normalized discounted cumulative gain (NDCG) to determine which approaches most effectively identify relevant documents in response to user queries. By offering a consistent and challenging testbed, ASQ accelerates innovation and drives improvements in the accuracy and efficiency of search systems.
Information retrieval systems often benefit from strategies that move beyond simple keyword matching. Techniques like query expansion aim to improve recall by reformulating the initial search terms with synonyms or related concepts, effectively broadening the net to capture more relevant documents. Complementing this, semantic caching leverages the understanding of query meaning to store and reuse previously computed results for similar, but not identical, searches. This avoids redundant computations and accelerates retrieval, particularly for conversational search scenarios where follow-up queries are common. By intelligently expanding the search space and reusing semantic information, these methods demonstrably enhance both the accuracy – ensuring retrieved results are relevant – and the recall – maximizing the capture of all relevant documents – within a system.
At the heart of modern information retrieval lies the Probability Ranking Principle, a foundational concept asserting that documents should be ranked according to the probability of their relevance to a given query. Recent studies demonstrate that the application of this principle is significantly impacted by model scale; larger language models, such as Qwen-7B, exhibit a substantially broader search space compared to their smaller counterparts. Specifically, Qwen-7B generates up to 265% more search calls during retrieval, indicating a more exhaustive exploration of potential relevant documents. This increased computational effort suggests that larger models aren’t simply refining existing rankings, but actively expanding the scope of their search, potentially uncovering more nuanced or less obvious connections between queries and information – a critical advancement in achieving comprehensive and accurate results.
Analysis of user search behavior reveals a significant degree of relatedness between seemingly distinct queries originating from the same underlying information need. Studies indicate that queries sharing a common root exhibit a Jaccard Similarity – a measure of overlap – ranging from 35% to 83%. This suggests that users often rephrase their questions or explore related facets of a topic, leading to multiple queries that, while not identical, are substantially similar in intent. Understanding this phenomenon is crucial for optimizing information retrieval systems; techniques that recognize and leverage these connections can significantly improve the recall of relevant documents by effectively broadening the search scope beyond the initially submitted query.
Towards Robust RAG: The Future of Intelligent Search
Recent advancements in Retrieval-Augmented Generation (RAG) systems are being significantly propelled by the introduction of datasets like ASQ – a collection specifically designed to challenge and evaluate complex question answering. This dataset, featuring questions requiring multi-hop reasoning and nuanced understanding, is proving particularly effective when paired with agentic search methodologies. These methodologies empower the RAG system to dynamically formulate sub-questions, iteratively refine its search strategy, and ultimately retrieve more relevant information. This synergistic combination moves beyond simple keyword matching, allowing systems to tackle previously intractable queries and demonstrate a marked improvement in the quality and accuracy of generated responses. The result is a demonstrable push towards RAG systems capable of not just retrieving information, but of truly understanding and reasoning about it.
Advancing Retrieval-Augmented Generation (RAG) systems necessitates a shift towards more nuanced cognitive abilities; future investigations will likely center on integrating complex reasoning patterns beyond simple fact retrieval. This involves equipping these systems with the capacity for multi-hop reasoning, common sense inference, and the ability to synthesize information from disparate sources. Simultaneously, adaptive search strategies – those that dynamically refine search queries based on initial results and evolving contextual understanding – promise to overcome the limitations of static keyword-based approaches. Such strategies could involve reinforcement learning techniques, allowing the system to learn which search paths yield the most relevant and trustworthy information, ultimately leading to more robust and contextually aware responses. This convergence of sophisticated reasoning and intelligent search represents a crucial step towards creating RAG systems that truly mirror human information processing capabilities.
The pursuit of truly effective information retrieval hinges on replicating the nuanced reasoning processes of the human mind within automated search systems. Current methods often struggle with ambiguity, contextual understanding, and the ability to synthesize information from multiple sources – capabilities humans perform effortlessly. Bridging this gap requires moving beyond simple keyword matching towards systems that can interpret intent, evaluate source credibility, and draw inferences, much like a skilled researcher. Successfully merging human-like reasoning with automated search promises a paradigm shift, unlocking the full potential of information retrieval by delivering not just relevant documents, but also insightful, synthesized knowledge tailored to complex queries and evolving needs.
The pursuit of truly agentic search, as detailed in this work, feels less like innovation and more like rediscovering old limitations. It seems the more sophisticated the retrieval system, the more readily it exposes fundamental assumptions about how information should be sought. As Robert Tarjan once observed, “A good algorithm must be right before it’s fast.” This rings true; ASQ, by revealing the divergence between agent and human search, forces a reckoning with established Information Retrieval paradigms. The dataset isn’t just a benchmark; it’s a reminder that elegant theories often buckle under the weight of production realities-or, in this case, the surprisingly alien logic of an AI agent attempting to satisfy a synthetic query.
What’s Next?
The ASQ dataset, as a snapshot of agentic information seeking, merely clarifies what was already suspected: the tidy models of human search, built on decades of observation, are ill-suited to entities unburdened by cognitive biases or the need for narrative coherence. It’s not that the old assumptions were wrong, precisely; it’s that they were… anthropocentric. The bug tracker, one anticipates, will fill with edge cases arising from the agent’s relentless, goal-focused queries – a cascade of perfectly valid requests that nonetheless reveal the brittleness of existing retrieval systems.
Future work will undoubtedly focus on bridging this gap, attempting to ‘humanize’ agentic search with layers of behavioral mimicry. This feels… inefficient. A more honest approach might be to abandon the pretense of relevance as a human judgment, and instead define it as algorithmic efficiency – a measure of how quickly an agent achieves its stated goal, regardless of whether a human would have asked the same questions.
The data suggests that agents don’t refine queries; they re-architect them. They don’t iterate towards an answer; they explore a solution space. The illusion of smooth progression is just that – an illusion. It is not that agents will ‘fail’ to search like humans – they already don’t. The task now is to accept this divergence, and build systems that don’t expect them to. It isn’t deployment; it’s letting go.
Original article: https://arxiv.org/pdf/2602.17518.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-20 17:29