Author: Denis Avetisyan
A new approach harnesses the power of artificial intelligence to identify causal relationships within data, moving beyond simple correlations.
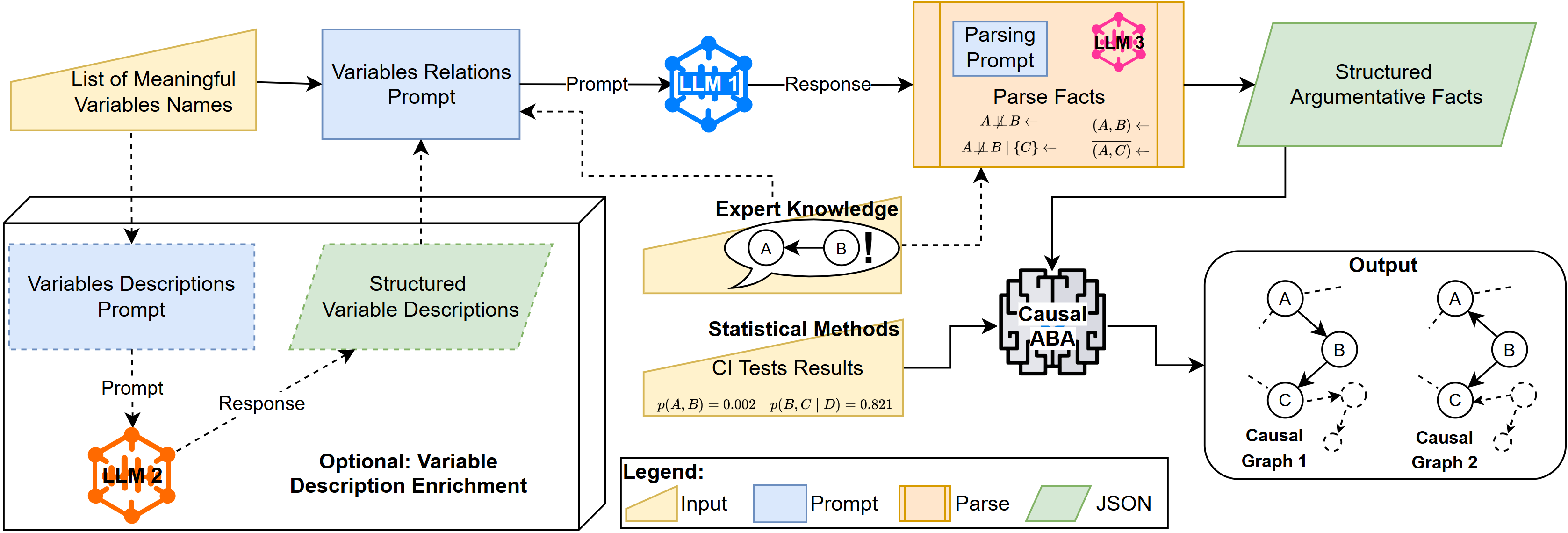
This review details a constraint-based argumentation framework leveraging large language models for improved causal discovery and interpretability.
Establishing reliable causal relationships from observational data remains a fundamental challenge, often requiring substantial expert knowledge to guide the process. This paper, ‘Leveraging Large Language Models for Causal Discovery: a Constraint-based, Argumentation-driven Approach’, introduces a novel framework that integrates the semantic understanding of large language models with a constraint-based argumentation approach-Causal ABA-to enhance causal discovery and improve the interpretability of resulting causal graphs. By eliciting structural priors from variable descriptions and combining them with statistical evidence, our method achieves state-of-the-art performance on standard benchmarks and synthetically generated data, alongside a new protocol to evaluate LLM performance while mitigating memorisation bias. Could this approach unlock more robust and transparent causal reasoning in complex systems, bridging the gap between data-driven discovery and domain expertise?
The Illusion of Discovery: Navigating High-Dimensional Systems
The pursuit of uncovering causal relationships from data is frequently hampered when dealing with datasets boasting a large number of variables – a scenario known as high dimensionality. Traditional causal discovery algorithms, reliant on assessing statistical dependencies, become increasingly prone to identifying spurious relationships in such complex systems. This occurs because the sheer volume of potential connections inflates the likelihood of observing correlations purely by chance, rather than reflecting genuine causal links. As the number of variables grows, these algorithms struggle to distinguish between true dependencies and noise, leading to inaccurate causal graphs and potentially flawed conclusions. The problem is exacerbated by the fact that these methods often fail to account for the multiple comparison problem – the increased probability of finding a statistically significant result simply due to the large number of tests performed. Consequently, researchers must exercise caution when interpreting results from traditional causal discovery in high-dimensional settings, recognizing the potential for false positives and the need for robust validation techniques.
The effectiveness of causal discovery hinges heavily on assessing statistical independence, yet this approach proves inadequate when hidden variables, known as latent confounders, are present. These unobserved factors can create spurious correlations between variables, leading algorithms to incorrectly infer direct causal links where none exist. Furthermore, systems exhibiting feedback loops – where a variable’s effect eventually influences itself – present a significant challenge; traditional independence tests struggle to disentangle the direction of influence within these cycles. Consequently, algorithms relying solely on identifying statistical independence often fail to accurately reconstruct the underlying causal structure, particularly in complex systems where latent variables and cyclical relationships are commonplace. Addressing these limitations necessitates incorporating techniques that account for unobserved confounders or explicitly model feedback mechanisms to improve the reliability of causal inferences.
Current causal discovery techniques frequently operate as “black boxes,” analyzing data without leveraging existing understanding of the system under investigation. This limitation proves particularly problematic in fields like biology or economics, where substantial prior knowledge often exists regarding potential causal relationships and underlying mechanisms. Without a means to integrate this domain expertise – whether through pre-defined causal constraints, known functional forms, or established hierarchies – algorithms can generate implausible or misleading causal graphs. The inability to encode such information not only reduces the accuracy of discovered relationships, but also severely hampers interpretability; a causal model devoid of contextual meaning remains difficult for experts to validate or utilize for prediction and intervention, ultimately diminishing the practical value of the analysis.
![The heatmap demonstrates that both LLM-derived and data-derived constraints positively correlate with improved graph reconstruction accuracy [latex]\Delta\Delta F1[/latex], with the number of constraints influencing the magnitude of this improvement.](https://arxiv.org/html/2602.16481v1/figures/interaction_heatmap.png)
Seeding Insight: Integrating Language Models into Causal Pathways
A novel pipeline has been developed to incorporate Large Language Models (LLMs) directly into the process of causal discovery. This pipeline leverages the LLM’s capacity for pattern recognition and relational understanding to generate potential causal constraints between variables. The process begins with the definition of variables and their relationships, which are then presented to the LLM as prompts. The LLM subsequently outputs proposed causal constraints, which are then evaluated and refined. This integration allows for the elicitation of high-precision constraints, effectively utilizing LLMs not as standalone causal engines, but as components within a larger, more rigorous causal discovery framework.
Detailed variable descriptions are integral to the process of eliciting causal constraints from Large Language Models (LLMs). By providing comprehensive information about each variable – including its definition, units, and potential relationships – LLM performance in identifying valid causal links is significantly improved. This approach, coupled with a consensus mechanism to reduce stochasticity, has demonstrated a precision of up to 1.0 in constraint generation, indicating near-perfect accuracy in identifying valid causal assertions based on the provided variable descriptions and the implemented stabilization process.
To address the inherent stochasticity of Large Language Models (LLMs) when generating causal constraints, a consensus mechanism was implemented. This process involves prompting the LLM multiple times with the same input and aggregating the resulting constraints. Discrepancies are identified, and constraints are only accepted if a pre-defined threshold of agreement is met amongst the LLM’s generated responses. This stabilizes outputs and significantly improves the reliability of the elicited constraints, effectively reducing the impact of random variation in the LLM’s generative process and ensuring consistency in the derived causal relationships.
![Heatmaps reveal the interaction between [latex]F_1[/latex] scores from language model and data-driven constraints, demonstrating how this relationship varies with network size.](https://arxiv.org/html/2602.16481v1/figures/heatmap_per_nodesize.png)
CausalABA: An Argumentation Framework for Inferring Systemic Logic
CausalABA functions as an argumentation framework designed to identify causal relationships by integrating logical inference with constraint-based reasoning. This approach utilizes a formal argumentation system where potential causal links are treated as claims, and evidence for or against these links is evaluated through logical deduction. Constraint-based reasoning supplements this by incorporating prior knowledge, expressed as constraints on permissible causal directions, to guide the inference process and reduce the search space for potential causal structures. The system evaluates the strength of arguments supporting or refuting each potential causal relationship, ultimately determining the most plausible causal model given the available data and constraints.
CausalABA utilizes D-separation – a graphical criterion for determining conditional independence in Bayesian networks – to assess the relationships between variables. Specifically, given a set of variables [latex]X[/latex], [latex]Y[/latex], and [latex]Z[/latex], D-separation determines if [latex]X[/latex] and [latex]Y[/latex] are independent given [latex]Z[/latex] based on the graphical structure of the network. In CausalABA, this process is guided by constraints provided by a Large Language Model (LLM), which specifies permissible or forbidden causal links. The LLM’s constraints effectively modify the graphical structure considered during D-separation testing, focusing the analysis on plausible causal pathways and excluding those deemed invalid by the prior knowledge encoded within the LLM.
CausalABA allows users to integrate domain expertise through the specification of both ‘required’ and ‘forbidden’ causal directions between variables. Required directions explicitly assert a known causal link – for example, stating that variable A directly causes variable B – and the framework will prioritize solutions consistent with this assertion. Conversely, forbidden directions preclude specific causal relationships – indicating that a link between variable A and variable B is known to be absent. These constraints function as hard boundaries during the causal discovery process, guiding the search space and ensuring the resulting causal graph aligns with pre-existing knowledge, thereby enhancing the reliability and interpretability of the discovered relationships.
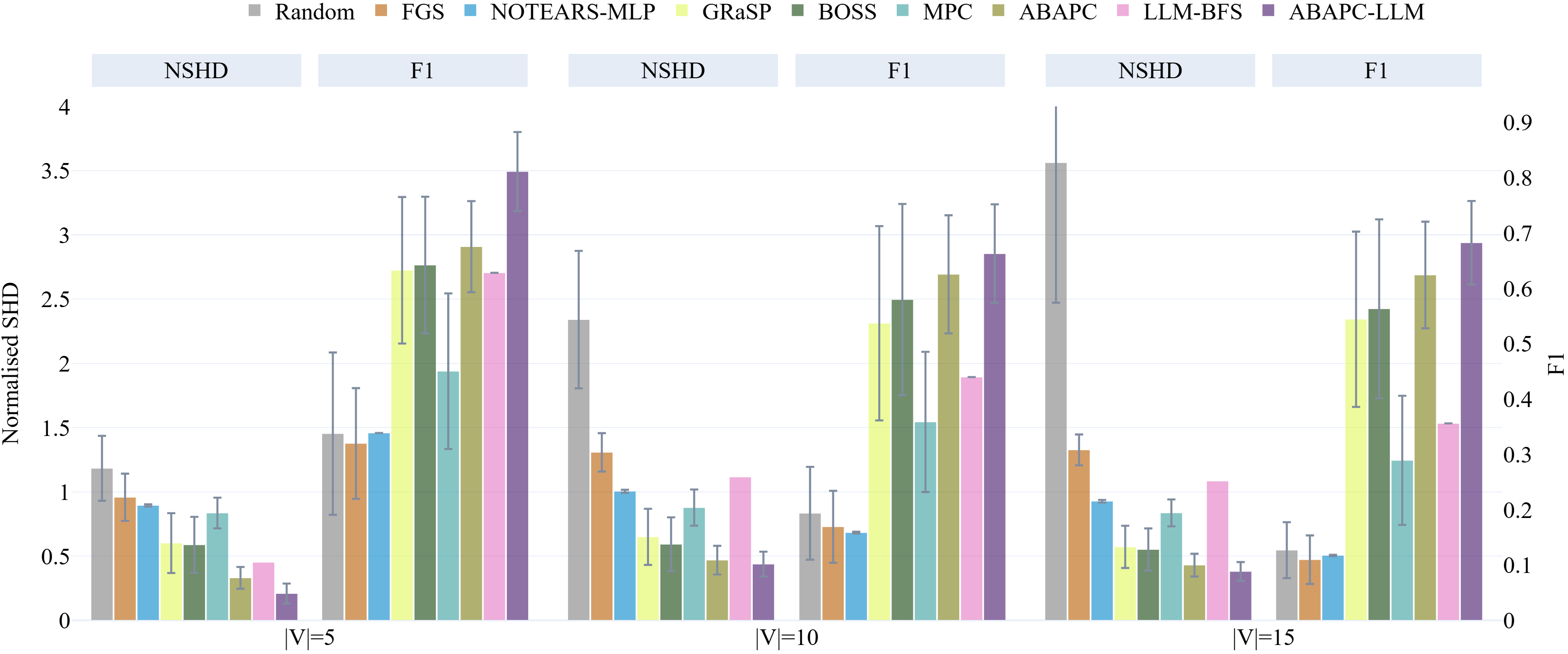
Validating the Ecosystem: Measuring Performance in Controlled Environments
To rigorously assess performance and mitigate the influence of uncontrolled variables, researchers leveraged ‘Synthetic CauseNet Data’ for evaluation. This approach involved generating datasets with precisely defined causal relationships, allowing for systematic control over potential confounding factors that often plague real-world observational data. By constructing these synthetic environments, the study ensured that observed performance differences weren’t attributable to spurious correlations or hidden biases, but rather reflected the true efficacy of the proposed method in discerning genuine causal effects. This level of control is crucial for establishing a reliable benchmark and demonstrating the robustness of the causal discovery algorithm across a spectrum of complex scenarios, providing confidence in its applicability to more ambiguous, real-world problems.
A thorough evaluation of the proposed method centers on three key metrics designed to capture distinct aspects of performance. The F1-score assesses the precision and recall of identified causal relationships, and results indicate this approach achieves the highest observed value across all tested datasets. Beyond simple accuracy, the Structural Hamming Distance measures the difference between the estimated and true causal graphs, offering insight into the overall structural correctness of the learned relationships. Complementing this, the Structural Intervention Distance evaluates the ability to accurately predict the effects of interventions on the system. The convergence of high scores across these metrics – particularly the leading F1-score – demonstrates a robust and comprehensive ability to both identify correct causal links and accurately model the system’s response to change.
Evaluations reveal that CausalABA consistently surpasses the performance of current state-of-the-art methods, particularly when analyzing datasets characterized by intricate causal relationships. This superiority is quantitatively demonstrated through the achievement of the lowest observed Normalized Structural Hamming Distance (NSHD) and Structural Intervention Distance (SID) scores across all tested datasets. These metrics rigorously assess the accuracy of discovered causal graphs, with lower values indicating greater fidelity to the true underlying causal structure. The consistent minimization of both NSHD and SID suggests that CausalABA not only identifies more accurate causal relationships but also exhibits a stronger capacity to predict the effects of interventions within complex systems – a critical advantage for applications requiring robust and reliable causal inference.
![LLM-augmented Causal ABA consistently achieves lower normalised Structural Intervention Distance (SID) than baseline methods across synthetic datasets with varying numbers of nodes ([latex]|\mathbf{V}|\in\{5,10,15\}[/latex]), as demonstrated by the error bars representing standard deviations over 50 repetitions.](https://arxiv.org/html/2602.16481v1/figures/DAG_results_SID.png)
The pursuit of causal structures, as outlined in this work, feels less like engineering and more like tending a garden. The framework doesn’t build a causal model so much as cultivate one from the noisy seeds of data, guided by constraints generated through Large Language Models. It’s a messy process, inherently prone to the propagation of error, yet the integration of argumentation – Causal ABA – attempts to introduce a form of selective pruning. As Claude Shannon observed, “The most important thing in communication is to reduce uncertainty.” This research embodies that principle; the framework isn’t about finding the truth, but about systematically reducing the space of plausible causal relationships, even if those reductions are ultimately temporary and subject to revision as new data emerges.
The Seeds of Future Reckoning
This work, in its attempt to coax causality from the pronouncements of large language models, does not so much solve a problem as relocate it. Every dependency is a promise made to the past – a reliance on the training data, the architecture, the very notion of ‘knowledge’ embedded within these systems. The precision of the generated constraints is, for a time, reassuring. But systems live in cycles; the elegance of the initial discovery will inevitably give way to the untangling of unforeseen consequences, the edge cases missed, the assumptions quietly broken. Control is an illusion that demands SLAs, and even the most rigorously validated constraint will eventually yield to the entropy of real-world complexity.
The true horizon lies not in perfecting the constraint generation, but in embracing the inevitable self-correction. The framework’s ability to synthesize data, while a useful scaffolding, hints at a deeper truth: everything built will one day start fixing itself. Future iterations will likely focus less on imposing causality and more on observing its emergence – treating the language model not as an oracle, but as a complex adaptive system, capable of evolving its own understanding of cause and effect.
This is not a path towards absolute certainty, but towards a more nuanced appreciation of the limits of knowledge. The goal isn’t to find the causal structure, but to build a system that can adapt to its absence – a framework that gracefully degrades in the face of uncertainty, and learns from its own failures. The constraints are not ends in themselves, but the seeds of future reckoning.
Original article: https://arxiv.org/pdf/2602.16481.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-19 09:35