Author: Denis Avetisyan
Researchers have developed a new framework allowing humanoids to autonomously navigate complex parkour courses by intelligently chaining together learned human movements.
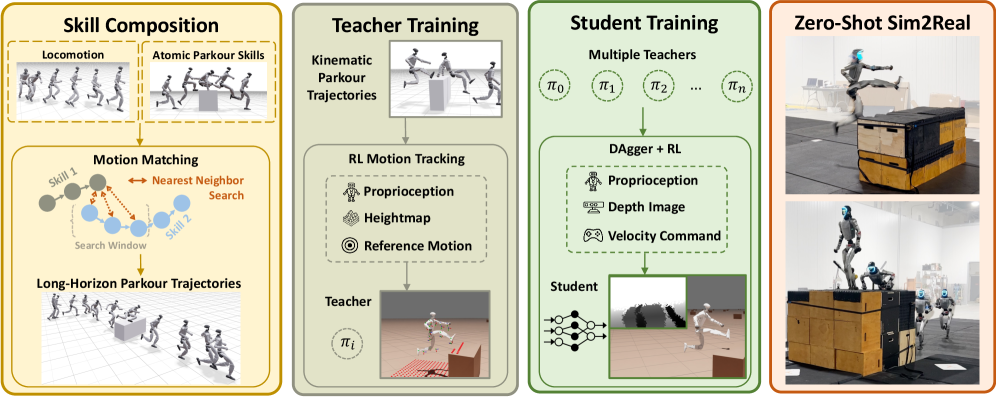
This work combines motion matching with a teacher-student deep reinforcement learning approach to enable robust skill composition and adaptive visuomotor policy in humanoid robots.
Achieving truly agile and adaptive locomotion remains a key challenge for humanoid robots despite advances in stable walking. This paper introduces ‘Perceptive Humanoid Parkour: Chaining Dynamic Human Skills via Motion Matching’, a framework enabling robots to autonomously navigate complex obstacle courses by composing human-inspired parkour skills. By leveraging motion matching and a teacher-student deep reinforcement learning approach, we demonstrate robust, vision-based traversal of challenging environments with dynamic adaptation to real-time perturbations. Could this approach unlock a new era of versatile and responsive humanoid robots capable of operating effectively in unstructured, real-world settings?
The Inevitable Dance: Replicating Dynamic Movement
The pursuit of truly agile humanoid robots hinges on overcoming substantial hurdles in replicating complex, dynamic whole-body skills. Unlike industrial robots performing repetitive motions, mimicking human capabilities-such as running, climbing, or even maintaining balance on uneven terrain-demands an extraordinary level of coordination and control. Current robotic systems often struggle with the interplay of multiple degrees of freedom, the rapid adjustments needed for unpredictable environments, and the sheer computational power required to process sensory input and plan movements in real-time. Achieving this level of dexterity isn’t merely a matter of building stronger actuators or more sophisticated sensors; it necessitates fundamentally new approaches to robotic control, allowing these machines to move not just as if they understand physics, but to actively leverage and respond to it.
Conventional robotics strategies, reliant on pre-programmed sequences and precise environmental mapping, falter when confronted with the unpredictable nature of dynamic activities like parkour. These methods struggle to reconcile the necessary instantaneous adjustments to maintain balance and momentum with the complex, full-body coordination required for vaulting, rolling, and navigating obstacles. The inherent rigidity of these systems limits their ability to react to unforeseen changes – a slightly uneven landing, an unexpected gust of wind, or a subtly altered course – leading to instability and failure. Consequently, a shift toward novel paradigms is crucial; these new approaches must prioritize real-time sensory integration, adaptive control algorithms, and a greater capacity for embodied intelligence, allowing robots to not simply execute movements, but to fluidly respond to the ever-changing demands of a dynamic environment.
Truly mirroring human locomotion demands more than just precise motor control; robots must possess an understanding of their environment and the capacity to dynamically adjust to unforeseen changes. Current robotics often relies on pre-programmed sequences, proving brittle when confronted with real-world variability like uneven terrain or unexpected obstacles. Researchers are now focusing on equipping robots with perception systems – vision, tactile sensing, and inertial measurement units – coupled with sophisticated algorithms that allow for real-time interpretation of sensory data. This enables a form of ‘situated intelligence’ where movements aren’t simply executed, but are continuously refined based on the robot’s evolving understanding of its surroundings, much like a human instinctively adjusts their gait to maintain balance on a slippery surface. The ultimate goal is to move beyond rote execution towards a system where the robot anticipates, reacts, and learns from its interactions with the physical world, unlocking a new era of adaptable and resilient robotic movement.
Perceiving the Path: Navigating Real-World Terrain
Robust robot locomotion in real-world environments is fundamentally dependent on perceptive terrain traversal, which necessitates the effective utilization of exteroception. Exteroceptive sensors, including cameras, LiDAR, and depth sensors, provide robots with information about the external environment, enabling them to perceive obstacles, surface characteristics, and navigable space. This externally-sourced data is then processed to create an environmental understanding which directly informs the robot’s path planning and control systems, allowing for dynamic adjustments based on perceived conditions. Without accurate and reliable exteroceptive input, a robot is limited to pre-programmed routes or random exploration, hindering its ability to operate autonomously in complex or changing environments.
Depth-conditioned policies utilize depth data – typically obtained from stereo vision, RGB-D cameras, or LiDAR – as input to a robot’s control system, enabling it to directly correlate visual perceptions with actionable movement parameters. This contrasts with policies relying solely on RGB images, which require additional processing to infer depth. By incorporating depth information, the policy can learn a mapping between observed terrain geometry and appropriate motor commands, improving the robot’s ability to estimate distances to obstacles, assess surface traversability, and plan collision-free trajectories. The resulting control signals are thus informed by a more complete understanding of the surrounding environment, leading to more robust and adaptable locomotion behaviors, especially in unstructured or dynamic settings.
Employing perception-driven locomotion enables robots to operate dynamically in unstructured environments by deviating from strictly pre-defined trajectories. Traditional robotic navigation often relies on detailed maps and pre-programmed paths, limiting adaptability. However, systems utilizing real-time sensory input – such as visual or depth data – allow for immediate adjustments to movement plans. This reactive capability facilitates navigation around previously unknown obstacles, response to unexpected terrain variations, and overall improved robustness in dynamic and unpredictable real-world scenarios. The robot effectively assesses its surroundings and modifies its path in real-time, rather than adhering rigidly to a static plan.

The Echo of Expertise: Learning from Demonstration and Refinement
The Teacher-Student pipeline utilizes a two-stage approach to policy development, beginning with imitation learning via the DAgger algorithm. DAgger collects data by querying an expert for actions in various states, allowing the robot to learn a diverse dataset and mitigate distribution shift. This initial policy is then further refined using reinforcement learning, specifically the Proximal Policy Optimization (PPO) algorithm, which optimizes the policy based on a reward function. By combining the benefits of both imitation and reinforcement learning, this pipeline achieves improved sample efficiency and robustness compared to relying on either technique in isolation, resulting in a powerful framework for complex skill acquisition.
Robotic acquisition of complex skills is facilitated through a two-stage process: initial learning from expert human motion data and subsequent refinement via interaction and reward shaping. The initial stage utilizes demonstrations to establish a foundational visuomotor policy, providing a starting point for skill execution. This policy is then iteratively improved through interaction with the environment, where a reward function guides the robot towards optimal behavior. The reward signal reinforces successful actions and penalizes failures, enabling the robot to adapt and refine its policy beyond the limitations of the initial demonstration data. This combination of imitation and reinforcement learning allows robots to generalize learned skills to novel situations and achieve higher levels of performance.
The integrated learning process, combining imitation and reinforcement learning, yields a demonstrably improved visuomotor policy compared to DAgger (Dataset Aggregation). Quantitative results indicate a statistically significant increase in skill mastery and a reduction in error rates when utilizing the full pipeline. Specifically, the reinforcement learning stage, employing Proximal Policy Optimization (PPO), effectively addresses the distribution shift inherent in DAgger, allowing the robot to generalize beyond the provided demonstration data and adapt to novel situations. This refinement stage optimizes the policy based on reward signals, leading to enhanced performance and robustness in executing the desired skill.
Bolstering Resilience: Enhancing Robustness and Adaptability Through Training
Domain randomization is a training paradigm essential for developing visuomotor policies capable of generalizing to previously unseen environments. This technique involves systematically varying simulation parameters – including lighting, textures, friction, and object geometry – during training. By exposing the learning agent to a wide distribution of randomized conditions, the policy learns to be invariant to these changes and performs reliably when deployed in the real world, where precise knowledge of environmental parameters is unavailable. This approach effectively bridges the “reality gap” between simulation and real-world execution, improving the robustness and adaptability of robotic systems.
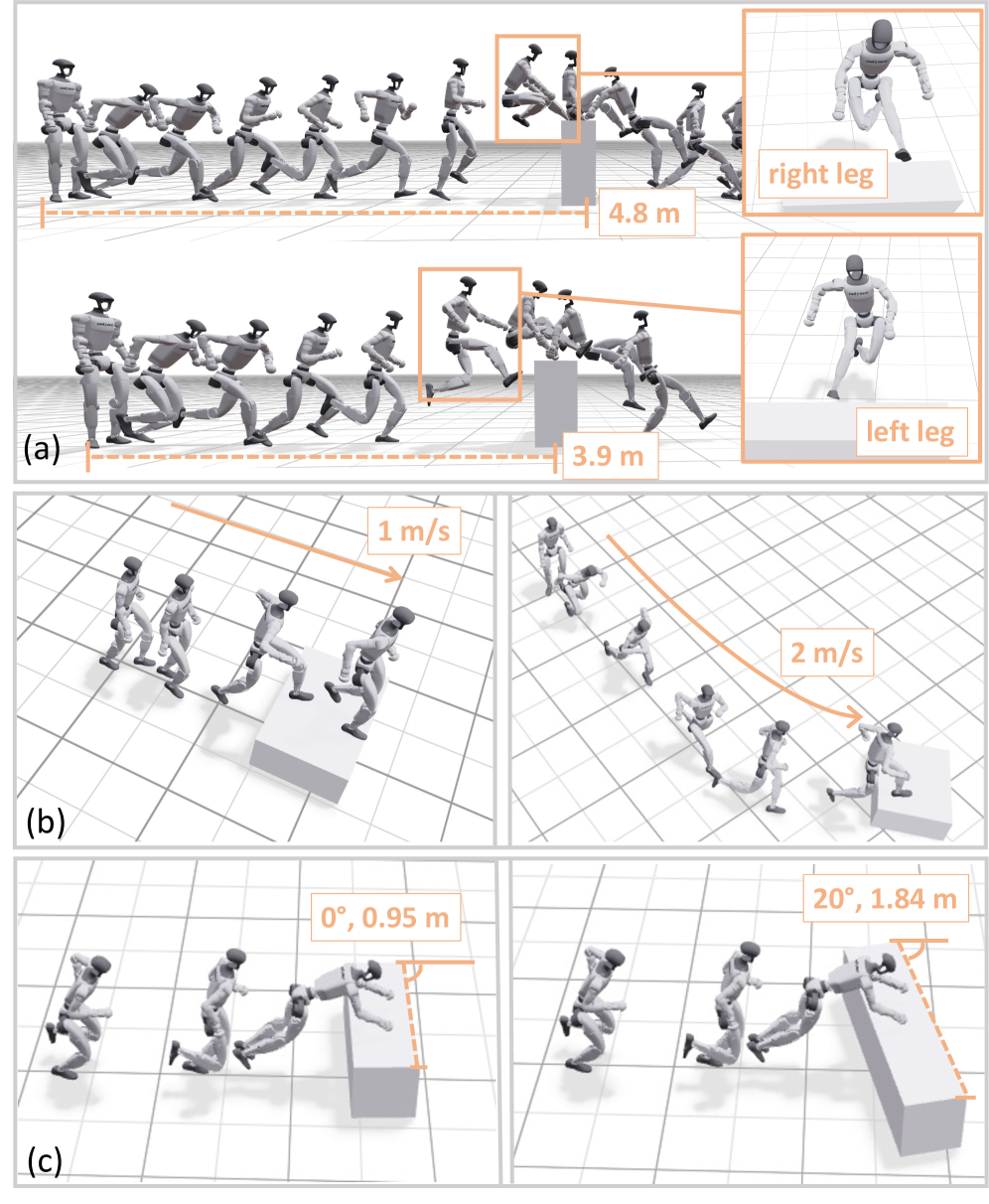
Motion matching improves locomotion quality by utilizing a pre-built database of realistic motion fragments. These fragments are indexed within a feature space defined by parameters such as foot position, orientation, and velocity. During policy execution, the current state of the robot is projected into this feature space, and the closest matching motion fragment is retrieved and blended seamlessly into the ongoing trajectory. This approach bypasses the need for explicitly calculating low-level motor commands, resulting in more natural, dynamically stable, and energy-efficient movements compared to traditional control or reinforcement learning methods that directly output motor torques or positions.
Autonomous execution of complex parkour behaviors was demonstrated through the training framework, with the robot achieving a cat vault completion time of 0.8 seconds and a high-wall climb completion time of 3.63 seconds. These performance metrics are directly comparable to those observed in human parkour practitioners performing the same maneuvers. The robot’s ability to successfully complete these tasks validates the effectiveness of the training methodology in transferring learned visuomotor policies to real-world, dynamic environments and achieving human-level agility.
The Expanding Horizon: Real-World Impact and Future Directions
The culmination of this research lies in the demonstrable ability of these visuomotor policies to facilitate robust robotic navigation in complex, real-world environments. Recent trials showcase successful autonomous traversal of multi-obstacle courses, proving the system’s capacity to react dynamically to unpredictable terrain and physical barriers. This isn’t merely simulated success; the robots consistently execute learned behaviors, integrating visual input with motor commands to maintain balance, adjust gait, and overcome challenges. Such proficiency marks a significant step towards deploying humanoid robots in practical applications, ranging from search and rescue operations to logistical support in unstructured environments, and underscores the potential for these robots to operate reliably beyond the confines of controlled laboratory settings.
The versatility of robotic skillsets is significantly enhanced through OmniRetarget, a technique allowing learned motor policies to generalize across robots with differing physical structures. Traditionally, a skill mastered by one robot could not be directly transferred to another with different limb lengths, joint configurations, or even numbers of degrees of freedom. OmniRetarget addresses this limitation by automatically adapting the control signals, effectively ‘retargeting’ the learned behavior to the new morphology. This adaptability avoids the need for costly and time-consuming re-training for each unique robot platform, opening possibilities for wider deployment of humanoid robots in diverse environments and applications. By decoupling skill learning from specific robot design, OmniRetarget promises a future where robots can readily share and reuse knowledge, accelerating progress in the field of robotics.
The trajectory of humanoid robotics is inextricably linked to advancements in both learning algorithms and perception systems. Current limitations in a robot’s ability to rapidly acquire new skills and reliably interpret complex environments necessitate ongoing investigation into more efficient methodologies. Researchers are actively exploring techniques such as reinforcement learning with improved sample efficiency and the integration of multi-modal sensory data – vision, tactile sensing, and proprioception – to create perception systems resilient to noise and uncertainty. Such progress promises to move beyond pre-programmed routines, enabling robots to dynamically adapt to unforeseen circumstances, generalize learned behaviors to novel situations, and ultimately achieve a level of autonomy crucial for widespread real-world deployment in fields like disaster response, healthcare, and manufacturing.
The pursuit of chaining dynamic human skills, as demonstrated in this work on perceptive humanoid parkour, inherently acknowledges the inevitable entropy of any complex system. Every successful skill composition, every robust adaptation achieved through teacher-student learning, is but a temporary stay against the decay. As Donald Davies observed, “The only constant is change.” This framework, leveraging motion matching and deep reinforcement learning, doesn’t prevent the system’s eventual degradation-it establishes a means of gracefully navigating it. Refactoring, in this context, isn’t merely about improving performance, but a continuous dialogue with the past, adapting learned skills to the present conditions and anticipating future challenges. The system’s longevity isn’t measured in absolute time, but in its capacity to respond and evolve.
What Lies Ahead?
The chaining of dynamic skills, as demonstrated by this work, merely postpones the inevitable cascade toward entropy. Uptime, in any complex system, is a temporary reprieve. The framework successfully grafts human intuition onto a mechanical substrate, yet the core challenge-generalization beyond the captured motions-remains. Latency is the tax every request must pay, and current approaches still struggle with unforeseen environmental perturbations or novel skill combinations that fall outside the training distribution. The illusion of stability is cached by time, but the dataset itself represents a frozen moment, a limited slice of potential action.
Future work will undoubtedly focus on refining the teacher-student paradigm. However, a more fundamental question lingers: can a truly robust visuomotor policy be constructed solely from imitation and reinforcement? Or will deeper integration with predictive models of physics and embodiment be necessary? The current reliance on pre-defined skill libraries, while pragmatic, introduces a fragility inherent in any modular design.
The true metric of success will not be the flawless execution of known parkour maneuvers, but the capacity to adapt, to improvise, and to recover gracefully from the inevitable failures that accompany any attempt to navigate a fundamentally unpredictable world. It is in those moments of breakdown, not in the perfected sequence, that the limitations of the system-and the true frontiers of research-will be revealed.
Original article: https://arxiv.org/pdf/2602.15827.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-18 14:55