Author: Denis Avetisyan
Researchers have developed a new framework that enables robots to generate realistic and efficient hand-object interactions by learning from sequences of fluid movements.
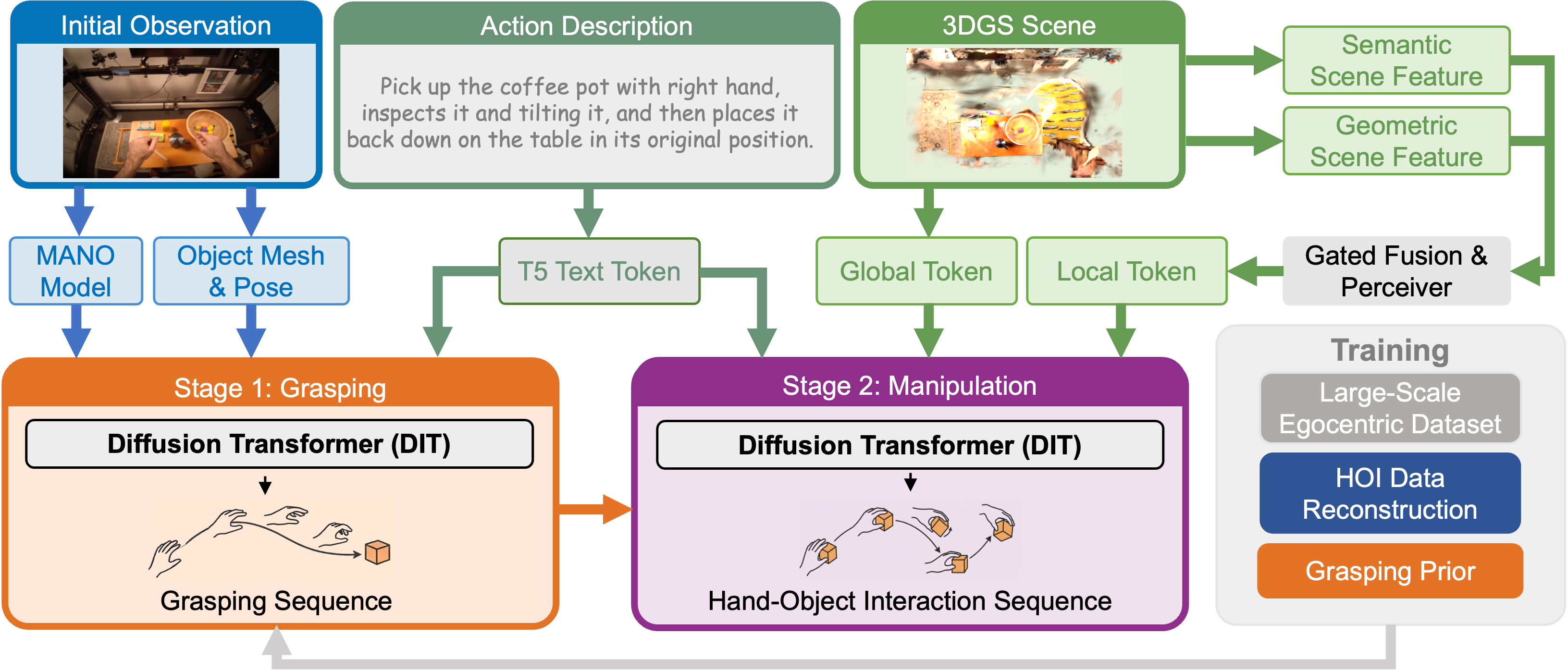
FlowHOI leverages flow matching to generate semantically grounded hand-object interaction sequences for improved robot manipulation and scene understanding.
Despite advances in vision-language-action models, generating realistic and reliable long-horizon robotic manipulation remains challenging due to a lack of explicit hand-object interaction (HOI) representation. This work introduces FlowHOI: Flow-based Semantics-Grounded Generation of Hand-Object Interactions for Dexterous Robot Manipulation, a novel framework leveraging flow matching to generate temporally coherent HOI sequences-including hand and object poses and contact states-conditioned on visual and linguistic inputs. By decoupling grasping geometry from manipulation semantics and utilizing a reconstruction pipeline for HOI supervision, FlowHOI achieves state-of-the-art performance on benchmarks like GRAB and HOT3D, and demonstrates successful real-robot execution. Could this approach unlock more adaptable and robust robotic systems capable of complex, real-world tasks?
The Inherent Disorder of Reality: Bridging the Gap in Hand-Object Interaction
Current methods for modeling hand-object interaction frequently falter when confronted with the inherent messiness of real-world environments. Robotic systems, for instance, often train on simplified datasets or in controlled laboratory settings, creating a significant disconnect when deployed amongst the unpredictable variables of everyday life. These approaches struggle to account for variations in object shape, size, texture, and pose, as well as the dynamic interplay of forces and constraints that characterize grasping and manipulation. The resulting models frequently exhibit brittle behavior, failing to generalize to even slight deviations from the training conditions. Consequently, a robotic hand proficient in a sterile environment may prove surprisingly clumsy when tasked with, for example, sorting laundry or preparing a meal, highlighting the critical need for more robust and adaptable HOI frameworks.
Current robotic systems frequently exhibit a rigidity in manipulation, stemming from an inability to predict and execute the subtle variations inherent in human hand-object interaction. Existing methods often produce repetitive or unnatural movements because they struggle to generate a diverse range of plausible interaction sequences – a critical limitation when faced with the unpredictable nature of real-world objects and environments. This lack of adaptability hinders the development of truly dexterous robots capable of performing complex tasks requiring nuanced manipulation, such as assembling intricate components or assisting in delicate procedures. The inability to foresee and smoothly transition between different grasping strategies, force applications, and object re-orientations significantly restricts a robot’s functional capacity and ultimately limits its potential for widespread application in dynamic and unstructured settings.
The limitations of current hand-object interaction (HOI) models stem from a fundamental difficulty in transferring learned behaviors to unfamiliar environments and tasks. Existing systems, often trained on specific datasets, struggle with the inherent variability of the real world – new objects, lighting conditions, or even slight alterations in task requirements can significantly degrade performance. This necessitates the development of a novel framework capable of robust generalization, one that moves beyond memorization of training examples to an understanding of the underlying physical principles and semantic relationships governing interaction. Such a framework would not merely recognize known scenarios, but proactively anticipate and adapt to the infinite possibilities presented by novel scenes, ultimately unlocking a new level of dexterity and adaptability in robotic systems.
Creating truly versatile robotic manipulation demands more than simply recognizing objects; it necessitates the generation of hand-object interaction sequences that convincingly mimic human dexterity. A robust framework must ensure these interactions are physically grounded, meaning they adhere to the laws of physics – accounting for gravity, friction, and collision dynamics. Equally crucial is semantic accuracy, where the actions performed logically align with the object’s function and the intended task. However, even physically plausible and semantically correct actions will appear unnatural if they aren’t temporally coherent – exhibiting smooth transitions and appropriate timing. The ability to synthesize these three elements – physical realism, functional relevance, and temporal consistency – represents a significant step toward bridging the reality gap in robotic manipulation, allowing robots to seamlessly interact with the world in a manner that is both effective and believable.

FlowHOI: A Two-Stage Generative Framework for Orderly Interaction
FlowHOI utilizes a two-stage generative framework for creating sequences of Human-Object Interaction (HOI) actions. This framework leverages flow matching, a probabilistic generative modeling technique, to produce realistic and semantically coherent interactions. The system doesn’t simply generate motions; it aims to create actions grounded in an understanding of the objects and the intended interaction. This is achieved by decomposing the HOI generation process into distinct stages, allowing for focused control over the generated sequences and improved fidelity of the resulting human-object interactions. The framework is designed to move beyond purely kinematic solutions by incorporating semantic understanding into the generation process.
The Grasping Stage of FlowHOI is dedicated to generating initial hand configurations that facilitate effective object acquisition. This stage focuses on producing hand poses that allow the hand to approach the target object and establish a stable grasp. The generated poses are not simply random configurations; they are designed to consider the object’s geometry and position within the reconstructed 3D scene, ensuring a feasible and successful initial interaction. Successful completion of the Grasping Stage sets the foundation for the subsequent Manipulation Stage by providing a secure starting point for more complex interactions.
The Manipulation Stage of FlowHOI builds upon the output of the Grasping Stage to generate a temporally coherent sequence of interaction motions. This stage utilizes flow matching to predict subsequent hand poses and object states, extending the initial grasp into a more complex interaction. The predicted motions are designed to maintain physical plausibility and ensure a smooth transition between actions, effectively simulating the manipulation of the object after it has been initially grasped. This allows for the generation of extended HOI sequences beyond a single grasping action, enabling the modeling of multi-step interactions.
The FlowHOI framework incorporates 3D Gaussian Splatting (3DGS) to establish a detailed, high-fidelity scene representation. 3DGS provides a differentiable volumetric scene reconstruction from multiple RGB images, enabling the system to accurately perceive object geometry and spatial relationships. This reconstructed scene serves as vital visual context for both the Grasping and Manipulation Stages, allowing the generative model to predict plausible and physically stable human-object interactions. The use of 3DGS facilitates the generation of realistic HOI sequences by grounding the actions in a geometrically accurate and visually consistent environment, improving the overall coherence and believability of the generated interactions.
Scene Understanding and Motion Generation: A Framework for Coherent Action
Scene Tokens within the Manipulation Stage function as a compressed, fixed-length vector representation of the 3D environment. These tokens are generated from a point cloud of the scene, encoding information about object positions, shapes, and relationships. By utilizing Scene Tokens, the system avoids processing the full, high-dimensional point cloud data directly during motion planning. This reduction in complexity enables real-time, context-aware trajectory generation, as the planner can efficiently access and interpret the surrounding environment without incurring substantial computational cost. The tokens effectively provide a semantic understanding of the scene layout, informing the robot’s actions and ensuring collision avoidance and physically plausible interactions.
Flow Matching is a probabilistic modeling technique utilized within the framework to learn and generate Human-Object Interaction (HOI) sequences. This approach defines a continuous-time diffusion process that transforms complex HOI data into noise, and then learns to reverse this process to generate new, plausible interaction sequences. By modeling the data distribution in this manner, Flow Matching enables efficient sampling of diverse HOI sequences, exceeding the performance of traditional generative models in terms of both speed and quality. The technique avoids the computational demands of iterative sampling methods, allowing for real-time generation of realistic and varied interactions between humans and objects.
The framework’s training and evaluation procedures utilize the EgoDex and HOT3D datasets. EgoDex provides a large-scale collection of human-object interaction (HOI) data captured in a simulated environment, offering precise ground truth for robotic manipulation tasks. Complementing this, the HOT3D dataset consists of real-world RGB-D video recordings of humans interacting with objects, introducing greater variability and realism to the evaluation process. Utilizing both datasets allows for a comprehensive assessment of the framework’s performance, bridging the gap between simulation and real-world applicability and facilitating robust generalization capabilities.
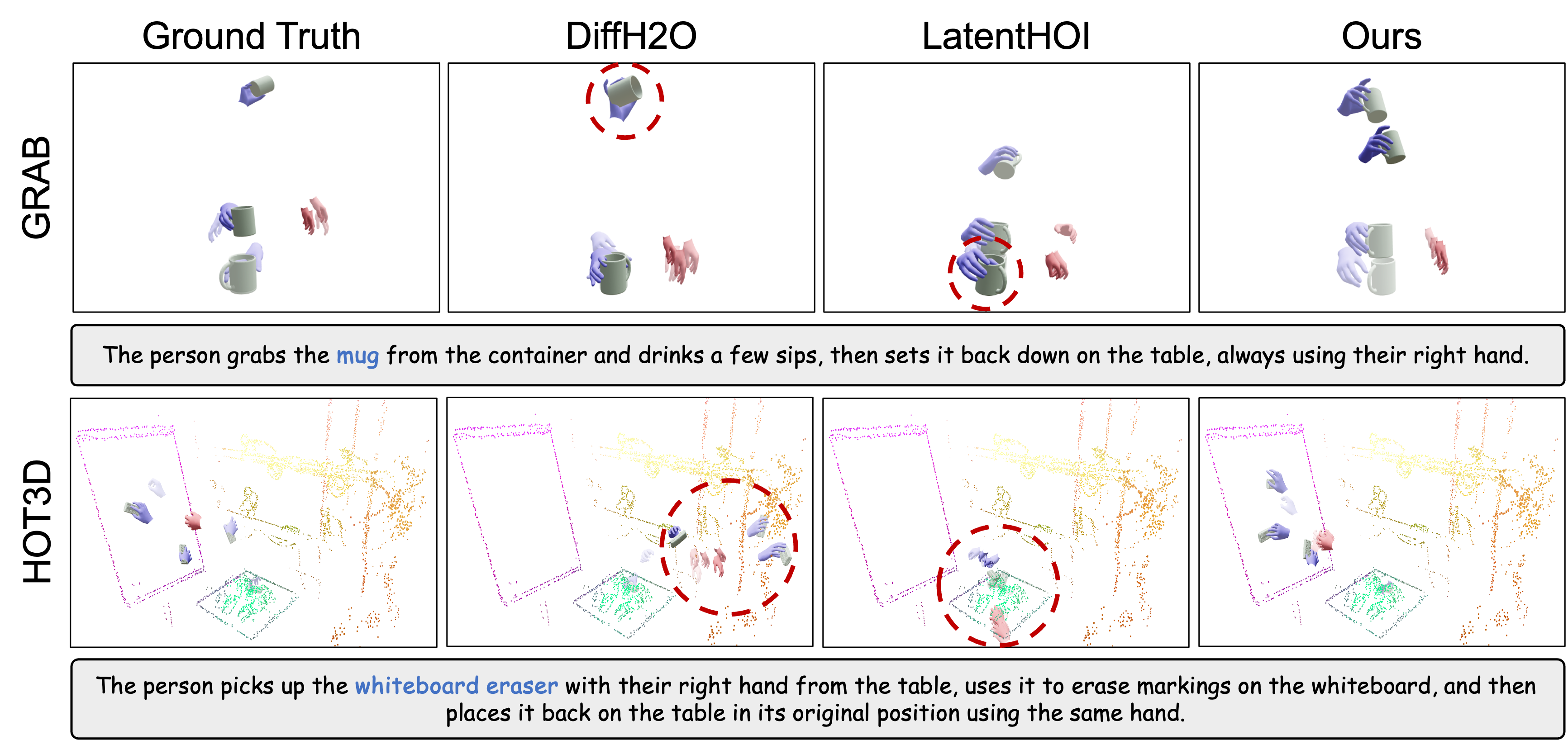
Evaluation of generated motions incorporates two key metrics: semantic correctness and physical feasibility. Semantic correctness is quantified using Action Recognition Accuracy, which measures the ability to correctly identify the performed action; our framework achieves state-of-the-art results on this metric when compared to DiffH2O and LatentHOI. Physical feasibility is assessed through Physics Simulation, verifying that generated trajectories adhere to realistic physical constraints and preventing implausible movements. This dual evaluation ensures both the logical and practical validity of the generated human-object interactions.
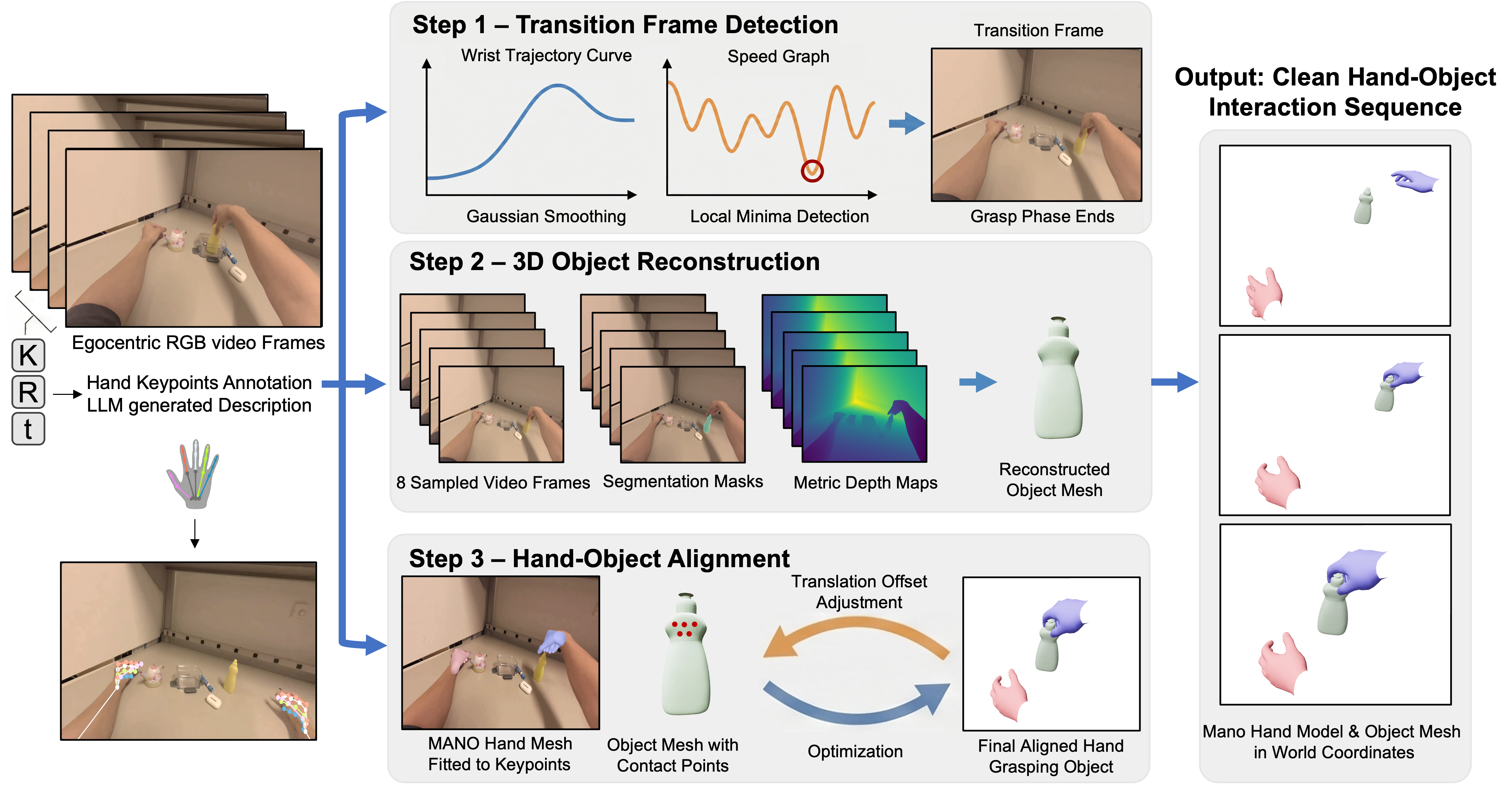
![An egocentric vision pipeline reconstructs 3D hand-object interactions by detecting manipulation transitions, segmenting and estimating depth for object reconstruction, and aligning a [latex] ext{MANO}[/latex] hand mesh with the object while enforcing non-penetration constraints.](https://arxiv.org/html/2602.13444v1/figures/3_reconstruction_v3.png)
Validation and Robustness Through Simulation: Establishing a Foundation for Reliability
Physics simulation serves as a critical evaluation component for generated Hand-Object Interaction (HOI) sequences by verifying the physical feasibility and stability of the simulated actions. This process involves subjecting the generated HOI data to a physics engine, which calculates the expected physical response of the hand and object based on applied forces and constraints. Successful simulation-defined as the absence of immediate physical collapse or unrealistic behavior-indicates that the generated interaction is plausible. Conversely, failures in simulation, such as objects falling through each other or the hand losing stability, highlight deficiencies in the generated sequence and necessitate refinement of the generation model. This rigorous testing ensures the generated HOIs are not merely visually coherent but also adhere to the laws of physics, increasing the reliability and applicability of the generated data for downstream tasks like robotics and animation.
The quality of physical interaction between the hand and object in generated Human-Object Interaction (HOI) sequences is quantified using metrics such as Contact Ratio and Interpenetration Volume. Contact Ratio measures the percentage of object surface area in contact with the hand, providing an indication of stable grasping. Interpenetration Volume calculates the amount of overlap between the hand and object meshes; lower values indicate more realistic and physically plausible interactions, minimizing instances of objects passing through each other. These metrics are computed within the physics simulation environment and used to assess the fidelity of generated HOI sequences, with lower interpenetration volume and higher contact ratios corresponding to improved simulation quality.
Evaluation of FlowHOI on the GRAB (Grasping and Retrieval of Articulated Bodies) dataset assesses its ability to generalize to a wide range of full-body human-object interaction scenarios. The GRAB dataset comprises diverse grasping and manipulation tasks performed by humans, providing a benchmark for evaluating the realism and adaptability of generated HOI sequences. Performance on this dataset demonstrates FlowHOI’s capacity to handle variations in object shape, size, pose, and human body configurations, extending beyond the constraints of training data and validating its practical applicability to real-world scenarios involving complex, full-body interactions.
Evaluation demonstrates that the generated Hand-Object Interaction (HOI) sequences exhibit improved realism and physical grounding when compared to existing methods. Specifically, the approach achieves a 1.7x increase in physics simulation success rate, measured at 55.96% versus 33.03% for baseline techniques. Furthermore, analysis of physical plausibility indicates a reduction in interpenetration volume – a key metric for assessing collision fidelity – of up to 21% compared to alternative HOI generation models. These quantitative results confirm the enhanced quality and stability of the generated interactions.
![Our method demonstrates superior physical plausibility and coordination in hand-object interactions across diverse actions compared to DiffH2O[18] and LatentHOI[54], yielding accurate grasping poses and smooth bimanual movements.](https://arxiv.org/html/2602.13444v1/supp_figures/supp_figure2.png)
Towards Intelligent and Adaptive Robotic Manipulation: A Vision for Seamless Interaction
FlowHOI marks a considerable advancement in the field of robotic manipulation, moving beyond pre-programmed sequences towards systems capable of dynamic adaptation. This framework achieves this by modeling manipulation not as isolated actions, but as continuous, physically plausible sequences of Human-Object Interactions (HOIs). By generating these HOI sequences, a robot can anticipate necessary actions and adjust its movements in real-time, improving robustness and reliability when faced with the inherent uncertainties of the physical world. Unlike traditional approaches that struggle with variations in object pose or environmental conditions, FlowHOI offers a more flexible and intelligent approach, paving the way for robots that can reliably perform complex tasks in unstructured environments and ultimately collaborate more effectively with humans.
The core innovation lies in FlowHOI’s ability to construct sequences of Human-Object Interactions (HOIs) that are both physically plausible and semantically meaningful. Unlike prior approaches that often treat robotic actions as isolated events, this framework anticipates how forces and constraints will play out during a manipulation task, ensuring stability and preventing collisions. By accurately predicting the consequences of each action – grasping, lifting, placing, and so on – the system minimizes errors and increases the robot’s success rate when performing complex tasks. This focus on physically grounded reasoning, coupled with a deep understanding of the intended semantic goal, allows the robot to adapt to subtle variations in the environment and handle objects with a level of robustness previously unattainable, ultimately leading to more reliable performance in real-world scenarios.
The development of FlowHOI establishes a foundation for robotic systems poised to impact numerous sectors. In domestic environments, robots equipped with this framework could assist with daily tasks, offering support to the elderly or individuals with disabilities. Manufacturing processes stand to benefit from increased automation and adaptability, allowing robots to handle complex assembly procedures and respond dynamically to changing production needs. Perhaps most profoundly, healthcare could be revolutionized through robotic assistance with surgery, patient care, and rehabilitation, enabling greater precision, reduced recovery times, and improved patient outcomes. These applications represent just the beginning, as the capacity for robots to understand and interact with the physical world with greater intelligence promises to unlock further innovations across diverse fields.
Ongoing development of this robotic manipulation framework prioritizes augmenting its capabilities through observation and adaptation. Researchers aim to integrate learning from human demonstrations, allowing the system to acquire new skills and refine existing ones by mimicking expert performance. Simultaneously, efforts are directed towards enhancing the framework’s robustness in dynamic and unpredictable environments; this includes developing strategies for identifying and responding to unforeseen circumstances, such as unexpected object positions or disturbances during task execution. This dual focus on imitation and resilience promises to move robotic systems closer to achieving truly intelligent and adaptive manipulation, capable of operating effectively alongside humans in real-world settings.
The pursuit of robotic dexterity, as demonstrated by FlowHOI, necessitates a rigorous foundation in predictable, verifiable sequences. This aligns perfectly with Barbara Liskov’s assertion: “Programs must be correct.” FlowHOI’s emphasis on semantically grounded generation, utilizing flow matching to create plausible hand-object interactions, isn’t simply about achieving functional movement; it’s about establishing a provable link between intention and action. The framework’s success hinges on generating sequences that aren’t merely observed to work, but are inherently correct based on physical principles and semantic understanding. Such an approach moves robotic manipulation closer to the ideal of mathematically pure, verifiable algorithms.
Future Directions
The introduction of FlowHOI represents a step, albeit a predictably iterative one, towards generating robotic manipulation sequences possessing a semblance of physical realism. However, the pursuit of ‘plausibility’ remains largely heuristic. The true test lies not in visual fidelity, but in provable stability-a mathematically rigorous guarantee against catastrophic failure in the real world. Current generative models, even those employing flow matching, are fundamentally approximations; they generate likely interactions, not guaranteed ones.
A critical, and largely unaddressed, limitation is the inherent difficulty in scaling semantic grounding. While the framework demonstrates proficiency with a defined set of hand-object interactions, the combinatorial explosion of possible actions and objects presents an intractable challenge. Minimizing redundancy in the representation of these interactions-stripping away all but the essential geometric and physical constraints-is paramount. Every additional parameter introduces a potential source of error, an abstraction leak masquerading as robustness.
Future work should prioritize the development of formal verification techniques applied to generated manipulation sequences. The goal is not simply to create a robot that appears to manipulate objects skillfully, but one whose actions are demonstrably correct, adhering to the immutable laws of physics. Until then, the field remains mired in empirical observation, mistaking correlation for causation, and statistical likelihood for mathematical certainty.
Original article: https://arxiv.org/pdf/2602.13444.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-17 12:03