Author: Denis Avetisyan
New research explores how abductive reasoning can bridge the gap between artificial intelligence and human clinical expertise in identifying critical symptoms.
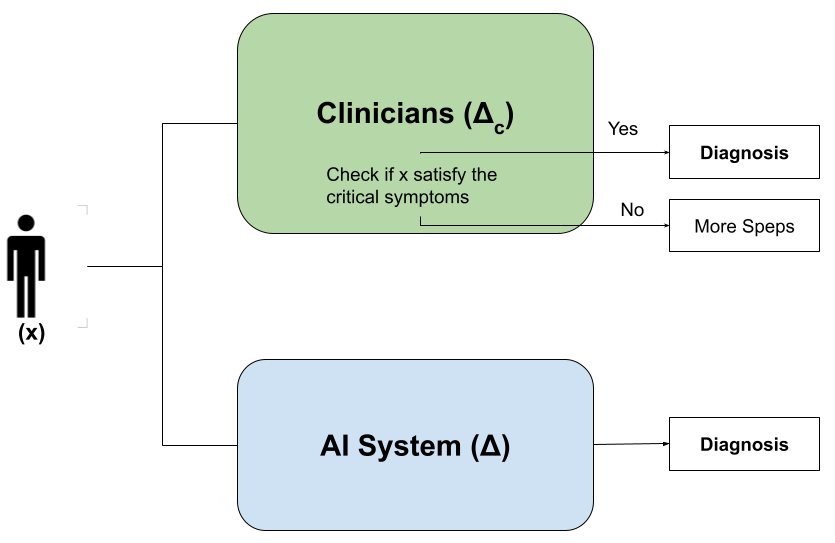
This review proposes a methodology using abductive explanations and critical symptom analysis to improve AI alignment in medical diagnosis and enhance trustworthiness through feature importance.
While artificial intelligence increasingly matches-and sometimes exceeds-human accuracy in clinical diagnostics, a critical gap remains between how these systems arrive at conclusions and the structured reasoning of clinicians. This disconnect hinders trust and adoption, particularly when AI overlooks pivotal ‘critical symptoms’ even with correct predictions. In the paper ‘Bridging AI and Clinical Reasoning: Abductive Explanations for Alignment on Critical Symptoms’, we introduce a methodology leveraging formal abductive explanations to ensure AI reasoning is grounded in clinically relevant feature sets, preserving predictive power while enhancing transparency. Could this approach unlock a new era of trustworthy AI in medical diagnosis, fostering genuine collaboration between humans and machines?
The Diagnostic Horizon: Unveiling the Disconnect Between Algorithm and Assessment
The increasing integration of artificial intelligence into diagnostic medicine reveals a notable disconnect between algorithmic predictions and the nuanced processes of clinical reasoning. While AI excels at identifying patterns within data, it often lacks the ability to articulate the why behind a diagnosis – a cornerstone of how physicians approach patient care. This isn’t simply a matter of accuracy; even when AI arrives at a correct conclusion, the absence of a transparent rationale can impede clinician trust and hinder effective treatment planning. The human diagnostic process involves synthesizing patient history, physical examination findings, and contextual factors – a holistic approach that current AI systems struggle to replicate, creating a critical gap in fully realizing the potential of machine learning within healthcare settings.
A significant disconnect exists between the predictive outputs of artificial intelligence and the established logic of clinical reasoning, largely due to the ‘black box’ functionality inherent in many AI models. This opacity doesn’t simply impede understanding; quantitative analysis demonstrates a tangible misalignment, with studies revealing approximately 14% divergence between diagnoses generated by a neural network and those derived from conventional clinical assessment within a breast cancer dataset. This discrepancy hinders clinician trust and complicates seamless integration into existing workflows, as healthcare professionals require comprehensible rationales behind AI-driven suggestions to confidently incorporate them into patient care. Consequently, the lack of transparency doesn’t just represent a theoretical limitation but a measurable obstacle to the effective implementation of AI in medical diagnosis.
The opacity of many artificial intelligence systems presents substantial hurdles for both medical professionals and those receiving care. Unlike traditional diagnostic methods where reasoning is often explicitly articulated, AI frequently arrives at conclusions through complex algorithms that are difficult to interpret – a phenomenon often termed the ‘black box’ problem. This lack of transparency erodes clinician trust, making it challenging to validate AI-driven insights and integrate them seamlessly into established workflows. For patients, the inability to understand how a diagnosis was reached can fuel anxiety and hinder informed consent, impacting the crucial doctor-patient relationship and potentially leading to treatment hesitancy. Ultimately, bridging this explanatory gap is not simply a matter of technical refinement, but a fundamental requirement for the ethical and effective implementation of AI in healthcare.
Illuminating the Inner Workings: Approaches to Explainable AI
Post-hoc explanation techniques, such as SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations), are employed to enhance the transparency of complex machine learning models after they have been trained. These methods operate by approximating the model’s behavior locally, around a specific prediction, to identify the features that most significantly contribute to that outcome. SHAP utilizes principles from game theory to assign each feature a value representing its contribution to the prediction, while LIME builds a simpler, interpretable model locally to approximate the black box model’s behavior. The resulting explanations typically provide feature importance scores or identify the features with the greatest influence on the predicted result, allowing stakeholders to understand the reasoning behind individual predictions without needing access to the model’s internal workings.
Abductive explanation techniques operate on the principle of finding the smallest set of features that, when considered together, are sufficient to justify a model’s prediction for a specific instance. Unlike post-hoc methods which approximate feature importance, abductive approaches employ a formal search to identify a minimal sufficient feature set – a subset where removing any feature would alter the prediction. This is achieved through algorithms that evaluate feature combinations based on the model’s internal logic, effectively determining which features are necessary for the outcome, rather than simply influential. The resulting set provides a concise and logically grounded justification, offering a higher degree of confidence in the explanation’s fidelity to the model’s decision-making process.
The reliability of explainable AI (XAI) techniques – including SHAP, LIME, and abductive explanation – is not inherent and requires thorough validation. Testing must assess whether the generated explanations accurately represent the model’s decision-making process and are not simply spurious correlations or artifacts of the explanation method itself. Common validation strategies include comparing explanation stability under small input perturbations, evaluating explanation fidelity by measuring the extent to which explanations predict model outputs on held-out data, and conducting human-in-the-loop evaluations to gauge the comprehensibility and trustworthiness of explanations for domain experts. Failure to rigorously validate XAI methods can lead to misinterpretations of model behavior, potentially resulting in flawed decision-making or a false sense of trust in the AI system.
The Foundations of Assessment: Datasets and Models in Diagnostic AI
The Cleveland Heart Disease Dataset, Wisconsin Diagnostic Breast Cancer Dataset, and Mental Health in Tech Survey Dataset are utilized as standardized benchmarks for assessing the performance of artificial intelligence models in diagnostic applications. The Cleveland dataset comprises 303 instances with 75 attributes, focusing on the prediction of heart disease presence. The Wisconsin dataset contains data from 569 patients, detailing characteristics of breast masses for diagnostic classification. The Mental Health in Tech Survey Dataset provides self-reported data from individuals in the technology sector regarding their mental health, offering a benchmark for models focused on psychological well-being. These datasets allow for comparative analysis of model accuracy, precision, recall, and other key metrics, facilitating objective evaluation of AI diagnostic capabilities across diverse medical and psychological domains.
Logistic Regression and Neural Networks are frequently employed as comparative baselines in the evaluation of explainable AI (XAI) techniques. These models, while differing in complexity and performance characteristics, provide established benchmarks against which the fidelity and interpretability of more advanced XAI methods can be measured. By comparing explanations generated for these simpler models to those produced by complex models, researchers can quantify the gains – or trade-offs – in explainability achieved through more sophisticated techniques. This comparative analysis allows for a data-driven assessment of whether increased model complexity translates to more understandable and trustworthy explanations, facilitating informed decisions regarding model deployment in critical applications.
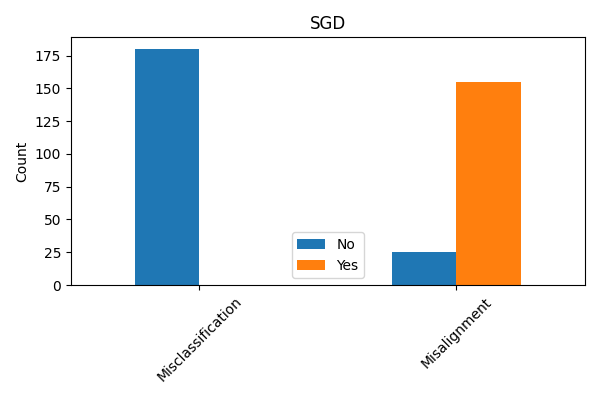
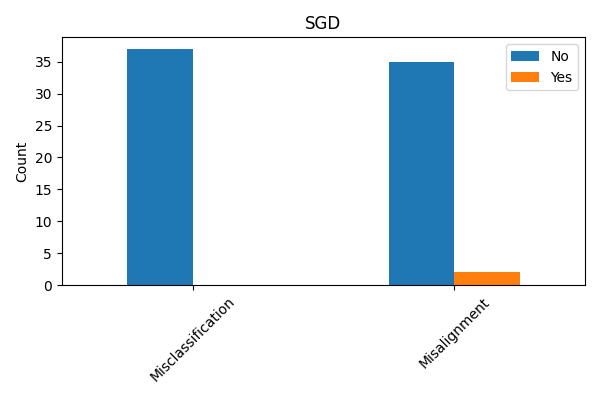
Evaluating explanation techniques requires metrics beyond overall accuracy to assess the faithfulness of explanations to the model’s decision-making process. Current research demonstrates that models can achieve high predictive accuracy while providing explanations that do not accurately reflect the features driving those predictions; for instance, quantitative analysis of the Cleveland Heart Disease dataset using a Stochastic Gradient Descent (SGD) model revealed a misalignment percentage of approximately 6% between the explanations and the model’s actual behavior. This misalignment indicates that approximately 6% of the time, the features identified as important by the explanation technique did not genuinely contribute to the model’s prediction, highlighting the need for rigorous fidelity metrics to quantify the trustworthiness of explanations.
Dataset analysis identified a critical property present in 180 cases of the Wisconsin Diagnostic Breast Cancer Dataset and 37 cases within the Cleveland Heart Disease Dataset. This disparity indicates a significant difference in the prevalence of this property across the two datasets. The observed variation suggests that explanation techniques, and their resulting alignment with human understanding, may perform differently depending on the specific dataset used for evaluation, requiring tailored assessment strategies and potentially limiting the generalizability of results. Further investigation is needed to understand the root causes of these differing alignments.
Toward Harmonious Systems: Impact and Future Directions in Diagnostic AI
The successful integration of artificial intelligence into healthcare hinges significantly on establishing trust with clinicians, and improved transparency is paramount to achieving this. When AI systems reveal how they arrive at a diagnosis or prediction – rather than simply presenting an output – healthcare professionals gain a crucial understanding of the underlying reasoning. This allows clinicians to assess the validity of the AI’s conclusions, identify potential biases, and, critically, reconcile the AI’s insights with their own clinical expertise. Consequently, transparency doesn’t aim to replace human judgment, but to augment it, fostering a collaborative relationship where AI serves as a supportive tool, confidently incorporated into established workflows and ultimately improving patient care.
The capacity of modern artificial intelligence to predict patient outcomes hinges not only on accuracy, but also on interpretability. Recent advances demonstrate that AI systems can pinpoint the critical symptoms – the specific clinical indicators – that most heavily influence their predictions. This isn’t about replacing clinical judgment, but rather about powerfully augmenting it; clinicians can now review the AI’s reasoning, assessing whether the identified symptoms align with their own expertise and patient understanding. This synergy between artificial and human intelligence fosters a more holistic diagnostic approach, enabling clinicians to confidently validate, refine, or even challenge AI-driven insights. Ultimately, by illuminating the ‘why’ behind a prediction, these methods transform AI from a ‘black box’ into a collaborative tool that supports and enhances the complex process of clinical reasoning.
Continued innovation in explainable AI (XAI) necessitates the development of techniques that are not only readily interpretable but also capable of handling the complexity and scale of real-world clinical datasets. Future studies are poised to investigate methods that move beyond simply highlighting feature importance to providing deeper, more nuanced explanations of why an AI system arrived at a particular prediction. This includes exploring the potential of these explanations to tailor treatment strategies to individual patient characteristics, paving the way for personalized medicine approaches. Robustness will be key – ensuring explanations remain consistent and reliable even with variations in data or model updates – while scalability will enable the application of XAI to larger patient populations and more complex medical challenges. Ultimately, these advancements aim to transform AI from a “black box” into a collaborative tool that empowers clinicians and enhances patient care.
The pursuit of aligning artificial intelligence with established clinical reasoning, as detailed in this work, echoes a fundamental truth about all complex systems. Just as architectures inevitably evolve and age, so too must AI models be continuously evaluated and refined to maintain relevance and trustworthiness. Grace Hopper aptly stated, “It’s easier to ask forgiveness than it is to get permission.” This resonates with the methodology proposed – a willingness to explore abductive explanations and critical symptom analysis, even if it necessitates challenging existing diagnostic approaches. The paper’s focus on transparency and feature importance isn’t merely about building better AI; it’s acknowledging that all systems, including medical diagnosis, operate within a timeframe where continuous adaptation is essential for graceful aging and sustained efficacy.
What’s Next?
The pursuit of alignment, as demonstrated by this work, isn’t a destination but a continuous recalibration. This methodology, focusing on abductive explanations and critical symptoms, highlights a predictable truth: systems will diverge from intended function. The question isn’t preventing that divergence-it’s understanding the shape of the decay. Future iterations must move beyond symptom identification, and address the fundamental instability inherent in complex models. Feature importance, while crucial, is merely a snapshot – a static representation of a dynamic process.
A compelling direction lies in modeling not just what an AI concludes, but how its confidence evolves. The system’s internal friction-the points of contention between data, model, and clinical knowledge-will inevitably manifest as errors. These ‘incidents’ aren’t failures, but rather diagnostic steps toward maturity. Tracking these internal conflicts offers a more nuanced understanding of model fragility than any post-hoc explanation can provide.
Ultimately, the longevity of any AI-assisted diagnostic system depends not on achieving perfect alignment-an asymptotic ideal-but on building mechanisms for graceful degradation. Time, after all, isn’t a metric to be optimized, but the medium in which all systems ultimately succumb to entropy. The goal, therefore, is not immortality, but a predictable and manageable decline.
Original article: https://arxiv.org/pdf/2602.13985.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-17 10:29