Author: Denis Avetisyan
A new multi-agent system combines the power of large language models and systematic search to autonomously explore and validate algorithms for complex problems.
This paper introduces OR-Agent, a system leveraging LLMs and tree search for automated experimentation and reflection in operations research.
Iterative program mutation alone proves insufficient for robust scientific discovery in complex domains, demanding more structured exploration and principled reflection. This paper introduces ‘OR-Agent: Bridging Evolutionary Search and Structured Research for Automated Algorithm Discovery’, a multi-agent framework that unifies evolutionary search with tree-based hypothesis management and a hierarchical reflection system. OR-Agent systematically explores research spaces, conducts experiments, and learns from results, outperforming strong evolutionary baselines across combinatorial optimization and cooperative driving tasks. Could this approach pave the way for truly autonomous AI scientists capable of tackling previously intractable problems in operations research and beyond?
Deconstructing the Scientific Bottleneck
Conventional scientific inquiry, while foundational to progress, frequently encounters limitations in both speed and efficiency. The process often demands substantial financial investment, extensive laboratory time, and considerable manpower, creating bottlenecks in the pursuit of knowledge. Moreover, inherent human biases – stemming from preconceived notions, selective data analysis, or interpretation influenced by prevailing paradigms – can inadvertently skew results and impede objective discovery. These biases, though not always intentional, represent a significant challenge to the reliability and reproducibility of scientific findings, prompting exploration into methods that minimize subjective influence and accelerate the pace of innovation.
The exponential growth of data across all scientific disciplines, coupled with increasingly intricate research questions, demands a paradigm shift in how discovery is approached. Modern problems, from predicting protein folding to designing novel materials, involve variables and interactions far exceeding the capacity of traditional, manual analysis. Researchers are now confronted with solution spaces so vast that exhaustive exploration is simply impractical. This necessitates the development of automated, data-driven methods – leveraging techniques like machine learning and artificial intelligence – to efficiently navigate complexity, identify promising avenues of inquiry, and ultimately accelerate the pace of scientific advancement. These new approaches don’t aim to replace human researchers, but rather to augment their capabilities, allowing them to focus on higher-level interpretation and innovation.
The limitations of contemporary scientific inquiry often stem from an inability to effectively navigate the immense ‘solution spaces’ presented by intricate problems. Traditional research, while rigorous, typically focuses on predefined hypotheses, systematically testing a limited number of possibilities. However, many critical questions – from drug discovery to materials science – involve a combinatorial explosion of potential solutions, far exceeding the capacity of manual or even automated, yet narrowly focused, exploration. This challenge isn’t simply about computational power; it’s about intelligently searching a landscape where the most promising answers may lie in unexpected or counterintuitive regions. Consequently, current methods can become trapped in local optima, overlooking globally superior solutions hidden within the vastness of possible configurations, hindering progress and demanding innovative strategies for comprehensive exploration.
Orchestrating Autonomous Investigation: The OR-Agent
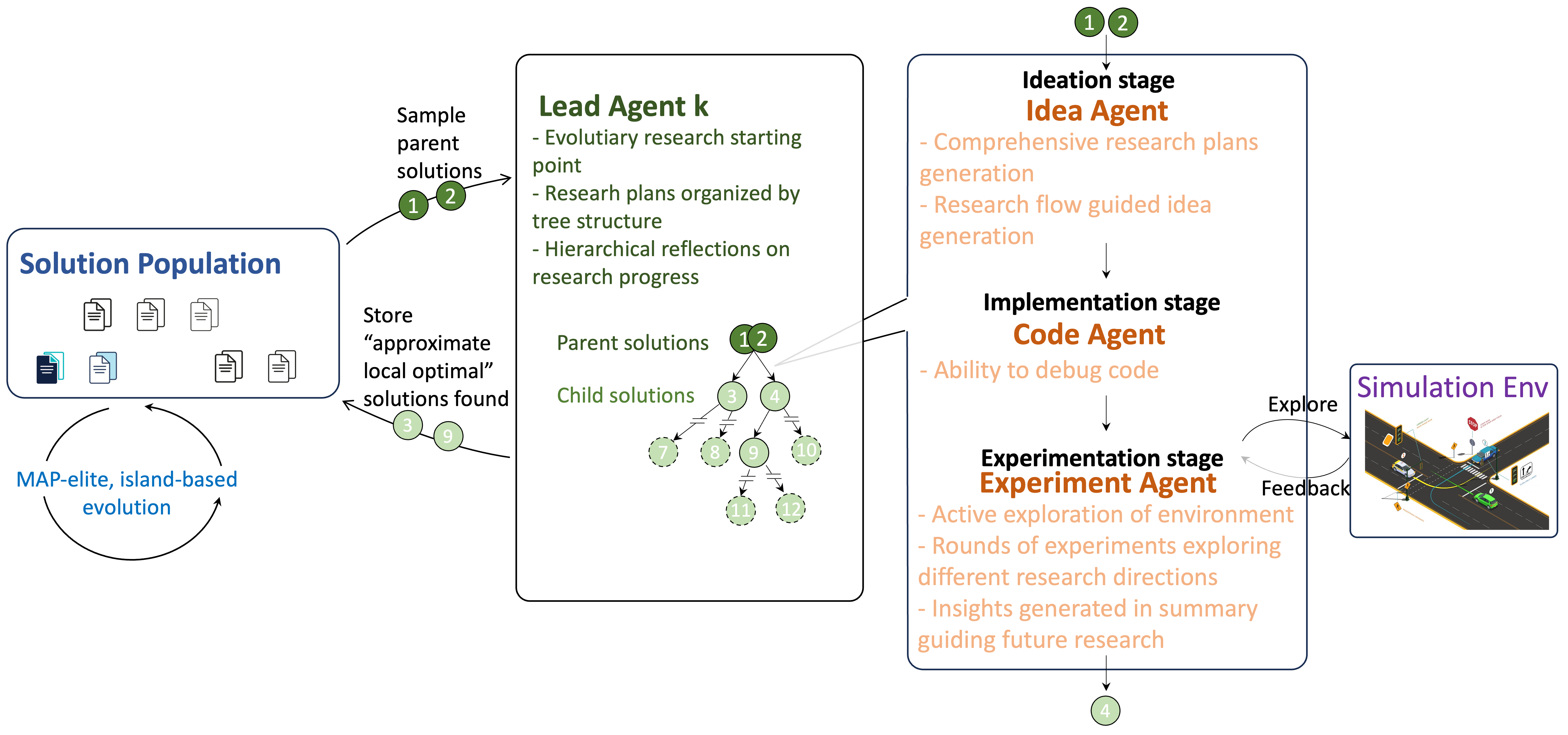
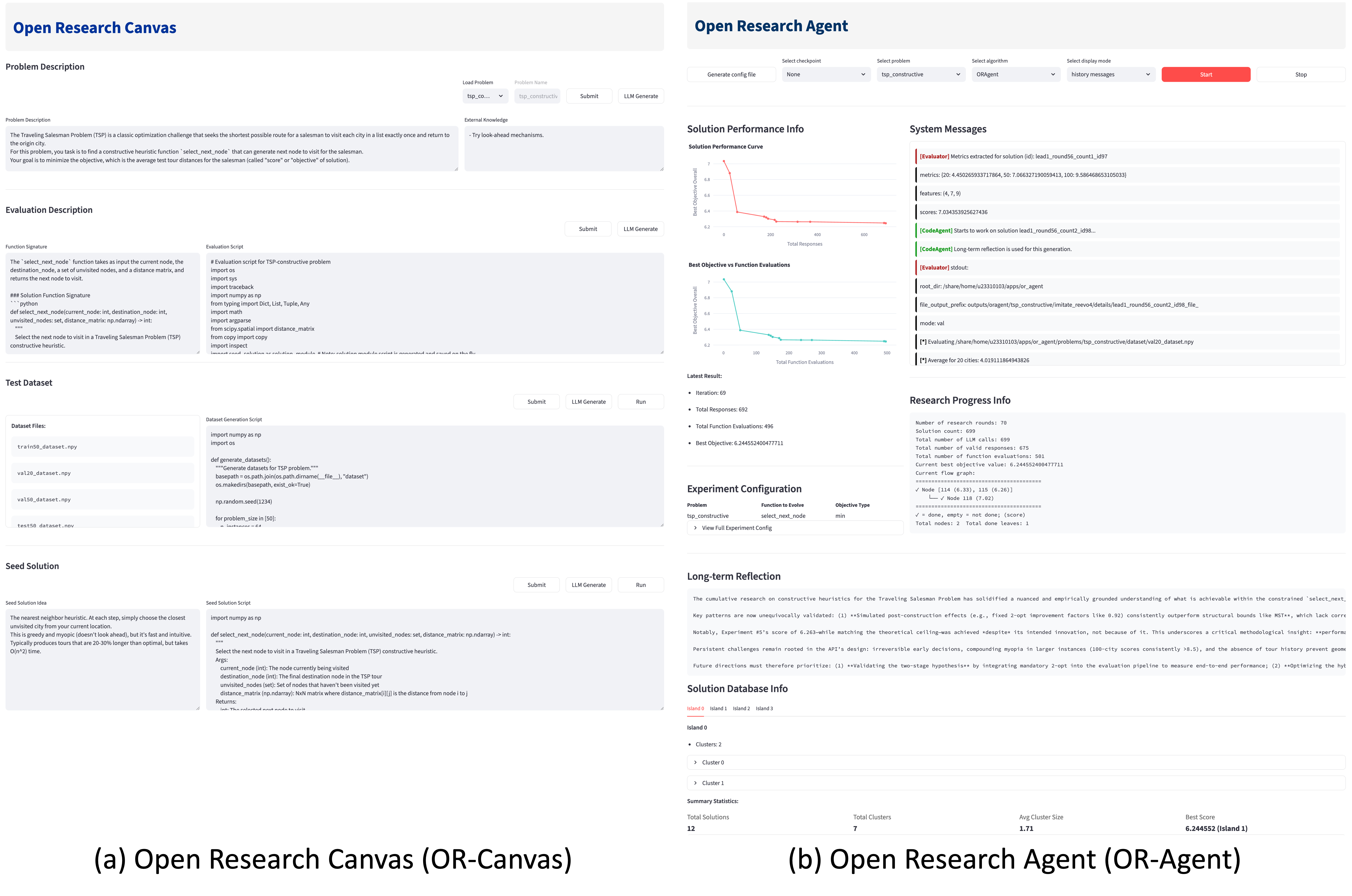
The OR-Agent is a multi-agent system constructed to automate procedures within the scientific research process. This is achieved by distributing research tasks across multiple independent agents, each responsible for a specific sub-problem or aspect of investigation. These agents operate collaboratively, communicating and coordinating their efforts to achieve a common research goal. The system’s architecture allows for parallel exploration of hypotheses and data analysis, increasing the efficiency of the research lifecycle and enabling the investigation of complex problems beyond the capacity of individual researchers. The design prioritizes modularity and scalability, allowing for the easy integration of new tools and the adaptation to a wide range of scientific disciplines.
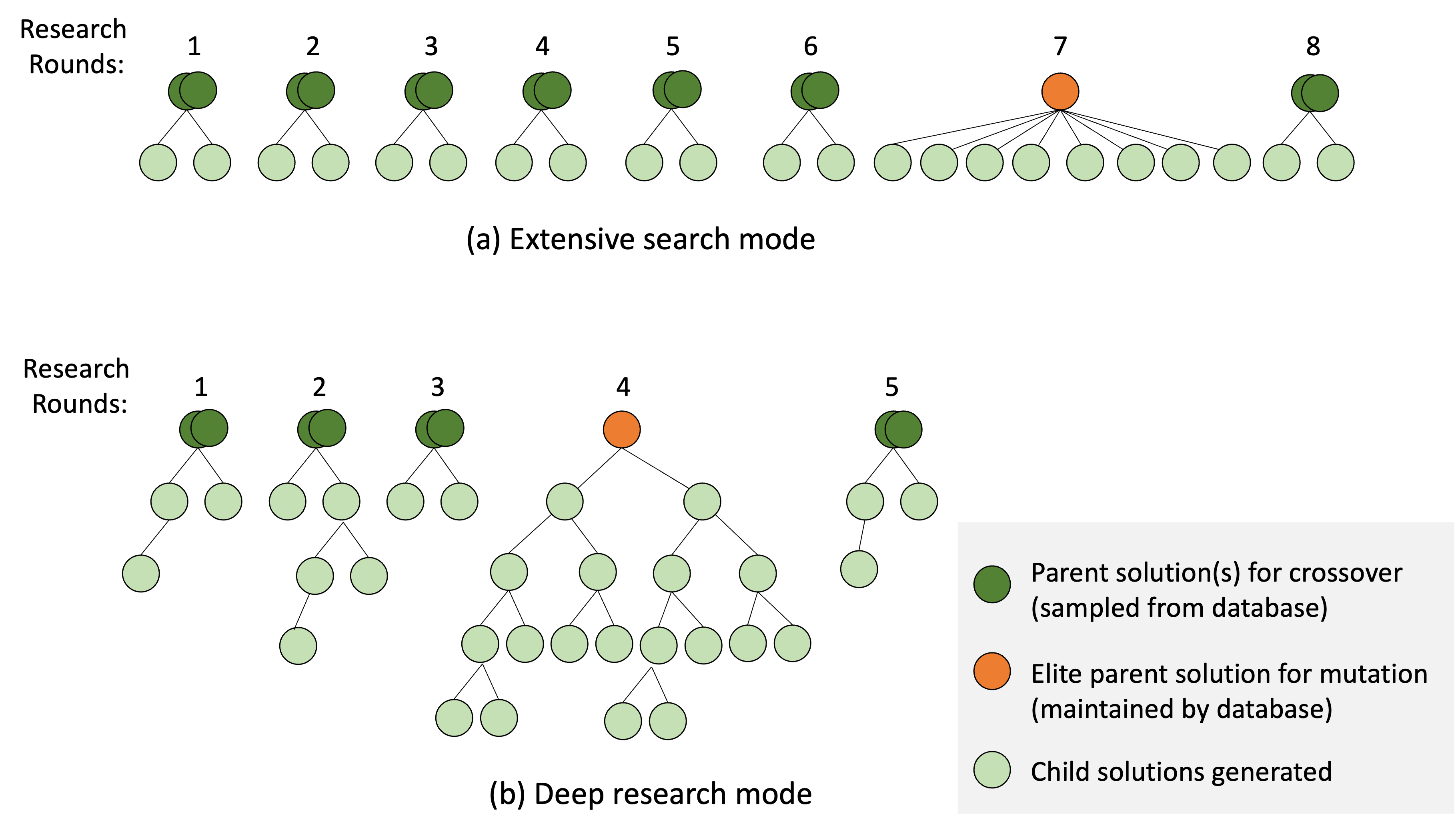
The OR-Agent employs a hierarchical research process initiated by a ‘Tree-Structured Research Workflow’. This workflow systematically generates and evaluates research directions, branching out from initial hypotheses to explore a wide range of possibilities. Following initial exploration, the system utilizes ‘Deep Local Investigation’ – a focused refinement process applied to the most promising branches of the research tree. This involves iteratively testing variations and extensions of these hypotheses with increased precision, allowing the OR-Agent to thoroughly investigate specific areas of the solution space and identify optimal solutions or insights.
Evolutionary Initialization within the OR-Agent utilizes a population-based approach to generate a diverse set of initial hypotheses for research exploration. This process involves randomly creating multiple starting points, then iteratively applying variation operators – including mutation and crossover – to these points. The resulting population is evaluated against predefined criteria, and the fittest individuals are selected for reproduction, driving the population towards increasingly promising research directions. This method ensures broad coverage of the solution space, mitigating the risk of premature convergence on suboptimal solutions and ultimately contributing to the system’s state-of-the-art performance across a range of problem domains.
Reflecting on Experience: The Power of Iterative Learning
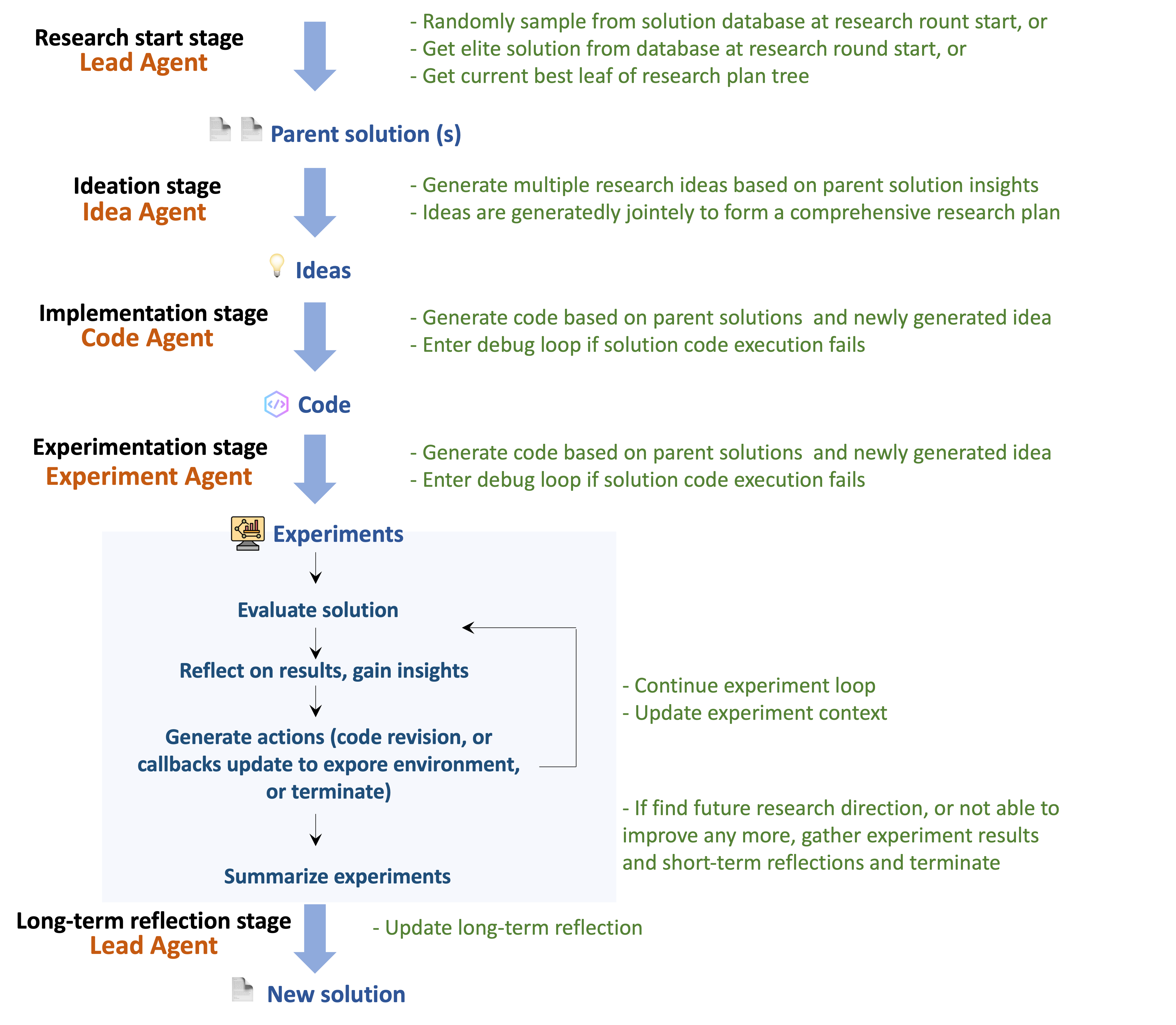
Memory-Based Reflection within the OR-Agent functions by storing data from completed experiments, including the specific configurations, resulting outcomes, and associated performance metrics. This historical data is then analyzed to identify patterns and relationships between experimental parameters and success rates. During subsequent research efforts, the system retrieves relevant past experiments based on the similarity of current conditions to those previously recorded. This allows the OR-Agent to prioritize promising configurations and avoid repeating unsuccessful approaches, effectively leveraging prior experience to accelerate the discovery of optimal solutions.
The OR-Agent’s capacity to accumulate knowledge is realized through the construction of a ‘Solution Database’. This database functions as a repository of previously successful strategies identified during experimentation. As the agent conducts research, effective approaches – defined by their contribution to positive outcomes on benchmark problems – are stored with associated parameters and contextual information. Subsequently, when encountering similar research challenges, the agent first consults this database to determine if a pre-existing solution can be adapted, thereby actively avoiding redundant exploration of already-tested strategies and accelerating the discovery of novel solutions. This process is crucial for efficiency, particularly when addressing complex optimization tasks.
Long-Term Reflection within the OR-Agent system functions by analyzing data accumulated from numerous experimental runs to discern high-level patterns in problem characteristics and algorithmic performance. This analysis allows the system to move beyond simple storage of successful strategies – as implemented in the Solution Database – and instead optimize its overall research direction. Specifically, the implementation of Long-Term Reflection enabled the OR-Agent to achieve the highest average normalized score across 12 Operations Research benchmark problems when compared to current state-of-the-art methodologies, demonstrating its capacity for generalized learning and improved problem-solving efficacy.
A Symphony of Agents: Collaborative Discovery
The research workflow benefits from a distributed system managed by the OR-Agent, which functions as an orchestrator for a team of specialized agents. Each agent-the ‘Lead Agent’, ‘Idea Agent’, ‘Code Agent’, and ‘Experiment Agent’-contributes a unique skillset to the research process. The ‘Lead Agent’ guides the overall direction, while the ‘Idea Agent’ focuses on generating novel hypotheses. Crucially, the ‘Code Agent’ translates these hypotheses into executable code, and the ‘Experiment Agent’ rigorously tests them within a simulated environment. This collaborative architecture moves beyond traditional, monolithic research approaches, allowing for a dynamic and iterative process where each agent’s output informs the actions of others, ultimately accelerating discovery and improving the robustness of results.
The system’s exploratory process hinges on a dynamic interplay between information gathering and hypothesis creation. The ‘Experiment Agent’ actively probes the research environment, collecting granular data to build a comprehensive understanding of the problem space. This detailed environmental assessment then fuels the ‘Idea Agent’, which leverages the gathered insights to formulate novel hypotheses; crucially, this collaborative approach yields a significantly broader range of structural diversity in generated ideas compared to scenarios where the ‘Idea Agent’ operates in isolation. This increased diversity isn’t merely quantitative; it suggests a more thorough exploration of potential solutions, moving beyond conventional approaches and fostering genuinely innovative outcomes.
The system’s architecture fosters a remarkable synergy through parallel processing and optimized resource distribution, demonstrably elevating driving performance. By dividing the research workflow amongst specialized agents, the system achieves a cooperative driving score of 90.24 – a significant improvement over the baseline score of 85.25 established by the SUMO default driving model. This advancement isn’t simply incremental; the distributed approach allows for simultaneous exploration of multiple research avenues, effectively accelerating discovery and maximizing the utilization of computational resources. The result is a more robust and efficient system capable of navigating complex driving scenarios with increased proficiency and adaptability.
The OR-Agent, in its systematic exploration of operations research problems, embodies a principle akin to Dijkstra’s assertion: “It’s not enough to get it right; you’ve got to understand why it’s right.” The agent doesn’t merely stumble upon solutions through large language model prompting and tree search; it actively constructs and tests hypotheses, mirroring an ‘exploit of comprehension’ where the validity of each step is rigorously evaluated through experimentation. This reflects a commitment to not just finding a solution, but to fully dissecting the problem space, confirming the underlying logic, and ensuring the robustness of any discovered algorithm. The system’s reflective capacity isn’t post hoc justification, but a core component of its search, actively refining its understanding and guiding future explorations.
The Code Remains Unread
The OR-Agent represents a predictable, yet still noteworthy, step towards automating the scientific method. It’s a compelling demonstration that large language models, when chained to a structured search process, can do science, albeit within the narrowly defined boundaries of operations research. However, the system merely scratches the surface of what’s possible – and what’s necessary. The true limitation isn’t the agent’s ability to generate hypotheses or execute experiments; it’s the implicit assumption that a meaningful solution exists within the explored search space. Reality, as it were, isn’t a bug waiting to be fixed; it’s a sprawling, undocumented codebase.
Future work shouldn’t focus solely on refining the search algorithm or increasing the model’s reasoning capacity. The critical challenge lies in enabling the agent to redefine the problem. To ask not just “how can this be solved?” but “is this the right question?”. This necessitates a mechanism for genuinely novel hypothesis generation, extending beyond the recombination of existing knowledge. The system must learn to identify, and even construct, entirely new axiomatic frameworks.
Ultimately, the success of automated scientific discovery will depend not on building better tools, but on fostering a system capable of fundamental intellectual rebellion. A system that actively seeks to dismantle established paradigms, and rewrite the rules of the game. The code is there, waiting to be understood. The question is, can an agent be engineered to truly read it?
Original article: https://arxiv.org/pdf/2602.13769.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-17 08:48