Author: Denis Avetisyan
A new framework leverages the power of large language models and structured knowledge to help robots articulate their reasoning, fostering clearer communication and trust in human-robot teams.
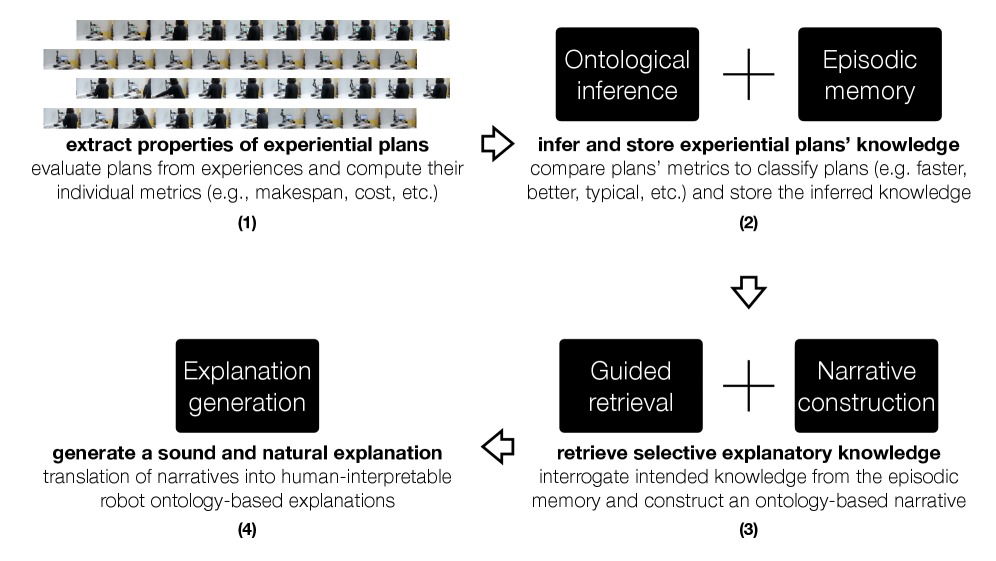
This review details an approach to ontological grounding for robot explanations, using knowledge representation and contrastive reasoning to generate sound and natural language descriptions of robotic actions.
Effective human-robot collaboration hinges on transparent and understandable reasoning, yet bridging the gap between logical inference and natural language communication remains a significant challenge. This paper, ‘Ontological grounding for sound and natural robot explanations via large language models’, introduces a hybrid framework that integrates ontology-based reasoning with large language models to generate concise, semantically accurate, and adaptive explanations for robot actions. By grounding explanations in formal ontologies and leveraging the fluency of LLMs, we demonstrate improved clarity and brevity in robot communication, validated through a collaborative task study. Could this approach unlock more trustworthy and efficient human-robot partnerships across complex domains?
The Illusion of Understanding: Why Scale Isn’t Enough
Despite their proficiency in generating human-like text, Large Language Models frequently encounter difficulties when tasked with complex reasoning or prolonged contextual awareness. These models, while adept at identifying patterns and statistical relationships within vast datasets, often lack the capacity for true understanding or logical inference. Consequently, they can produce outputs that, while grammatically correct and seemingly coherent, are factually inaccurate, internally inconsistent, or fail to address the nuances of a given problem. This limitation stems from their reliance on predictive algorithms rather than genuine cognitive processes, hindering their ability to maintain a consistent train of thought over extended interactions or to reliably apply common sense to unfamiliar scenarios. The challenge, therefore, lies not merely in increasing the scale of these models, but in fundamentally improving their reasoning capabilities.
Current large language models, despite their fluency, face inherent limitations that simply increasing their size will not overcome. The pursuit of ever-larger models runs into diminishing returns and escalating computational costs. A more fruitful path lies in augmenting these models with access to curated, external knowledge sources – effectively providing them with a reliable “memory” beyond their training data. Crucially, this integration must be paired with the implementation of more formalized, structured reasoning mechanisms, moving beyond pattern recognition towards systems capable of logical deduction, planning, and verifiable inference. Such an approach promises not just improved accuracy, but also enhanced explainability and robustness, allowing these systems to tackle genuinely complex problems requiring more than just statistical association.
![Explanations are generated through an iterative process, beginning with a system and user prompt based on ontological narratives [latex] (a) [/latex] and then refined via subsequent user prompts [latex] (b) [/latex] to achieve desired characteristics like brevity.](https://arxiv.org/html/2602.13800v1/x3.png)
Grounding Responses: The Myth of Self-Awareness
Retrieval-Augmented Generation (RAG) addresses limitations in Large Language Model (LLM) reasoning by supplementing the LLM’s parametric knowledge with information retrieved from external sources. Rather than relying solely on the data used during pre-training, RAG systems dynamically access and incorporate relevant documents or knowledge graph entries at inference time. This process typically involves an information retrieval component to identify pertinent knowledge, followed by its integration into the LLM’s prompt or decoding process. By grounding responses in external evidence, RAG aims to improve factual accuracy, reduce hallucinations, and enable LLMs to address questions or tasks requiring information beyond their initial training corpus.
An ontology, central to robust Retrieval-Augmented Generation (RAG) systems, provides a formal, explicit specification of concepts within a domain and the relationships between those concepts. This structured representation typically includes classes (representing sets of objects), properties (defining characteristics of objects), and relations (describing how objects are connected). Utilizing an ontology enables the RAG system to not simply retrieve documents containing relevant keywords, but to understand the meaning of the query and retrieve information based on semantic relationships. A well-defined ontology facilitates more precise and accurate retrieval of knowledge, improving the system’s ability to synthesize information and generate logically sound responses, particularly in complex reasoning tasks.
Large language models (LLMs) traditionally generate text based on statistical correlations learned from massive datasets; however, this approach can lead to inaccuracies or fabricated information when facing questions requiring factual recall or reasoning beyond the training distribution. By integrating external knowledge sources, the system shifts from relying solely on these learned patterns to accessing and utilizing verifiable facts. This capability is crucial for improving output reliability, as the model can now ground its responses in documented evidence rather than probabilistic predictions, mitigating the risk of generating plausible but incorrect statements and enabling more robust performance on knowledge-intensive tasks.
Tracing the Logic: A Façade of Understanding
Ontology-based narrative generation utilizes a system’s formalized knowledge representation – its ontology – as the foundation for constructing textual explanations. This approach moves beyond simply reporting decision-making processes; instead, it grounds explanations in defined concepts, relationships, and properties within the ontology. By referencing this structured knowledge, the system can articulate why a particular decision was made in terms that are directly linked to its understanding of the environment and task, allowing for explanations that are both semantically meaningful and traceable back to the system’s core knowledge base. This contrasts with methods that rely on opaque internal states or post-hoc rationalization, offering a transparent and verifiable basis for explanation generation.
The system utilizes both semantic similarity and contrastive explanations to pinpoint the critical factors driving its decision-making process. Semantic similarity identifies concepts closely related to the decision, establishing context and relevance. Complementing this, contrastive explanations highlight what nearly happened or what would have led to a different outcome, thereby emphasizing the specific factors that were decisive. This dual approach allows the system to not only state why a decision was made, but also to clarify what distinguished the chosen path from alternative possibilities, providing a more nuanced and informative explanation for human collaborators.
Ensuring explanation accessibility is paramount for effective human-robot collaboration, and readability is quantitatively assessed using metrics like the Flesch Reading Ease score. This metric evaluates text complexity based on sentence length and syllable count per word, providing a standardized measure of understandability. By prioritizing high Flesch Reading Ease scores during explanation generation, the system aims to produce outputs easily comprehended by human collaborators without specialized technical knowledge. Quantitative results demonstrate a significant improvement in readability; the generated explanations achieve up to a 76% increase in Flesch Reading Ease at higher specificity levels, indicating a substantial reduction in textual complexity compared to baseline methods.
The narrative generation approach yields substantial reductions in explanation length, achieving a 33% decrease compared to baseline methods at specificity level 1, and up to 93% at higher levels. Concurrently, readability is improved, with a 19% increase in Flesch Reading Ease at specificity level 2, scaling up to a 76% improvement at higher specificity levels. Critically, these reductions in length do not compromise semantic consistency; explanations maintain stable semantic similarity, with Cosine Similarity scores consistently ranging between 0.7 and 0.8, even when users request more concise outputs.
The capacity for a robotic system to articulate the reasoning behind its actions – termed Explainable Agency – is a critical component for establishing user trust and facilitating effective Human-Robot Collaboration. This transparency allows human collaborators to understand why a decision was made, enabling them to validate the system’s logic, identify potential errors, and confidently delegate tasks. Increased trust, derived from comprehensible explanations, directly correlates with improved collaboration, as humans are more likely to accept and act upon recommendations from a system whose reasoning they can follow. Without such explainability, reliance on robotic systems is hindered by a lack of understanding and potential concerns regarding safety and reliability.
The Illusion of Intelligence: A Benchmark for Automation
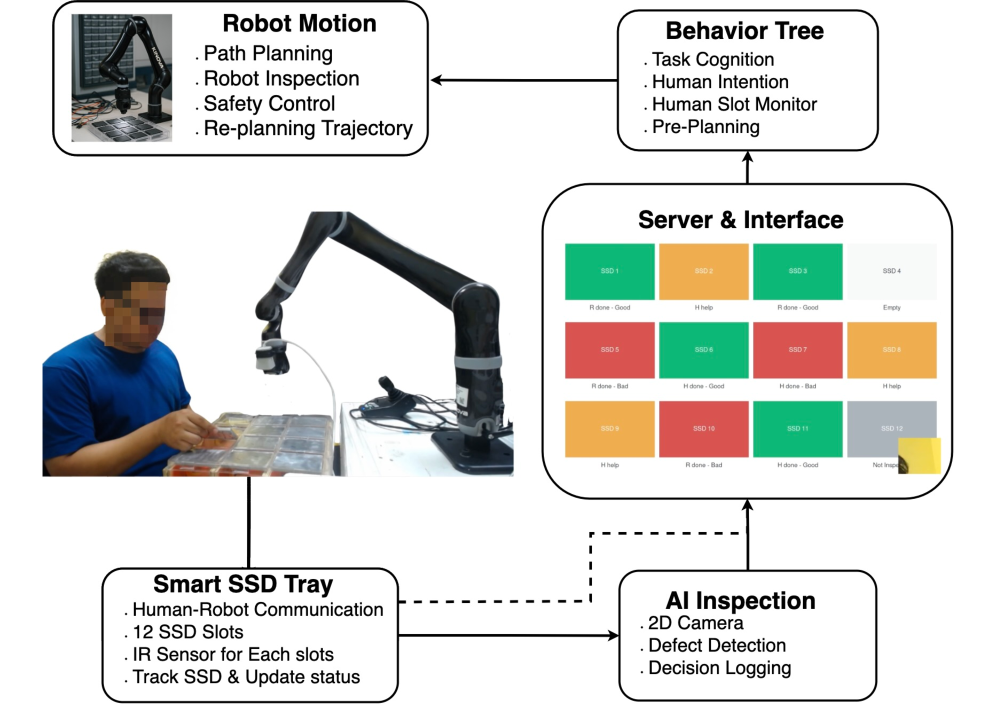
The developed system underwent rigorous evaluation through the application of SSD Case Inspection, a deliberately complex robotic task mirroring real-world scenarios demanding precise procedural adherence. This inspection process isn’t simply about task completion; it necessitates that the robot articulate how it is executing each step, providing a traceable narrative of its actions. Such a requirement moves beyond mere automation, pushing the system to demonstrate not only capability, but also transparency and explainability – crucial elements for building trust and enabling effective human-robot collaboration. The complexity inherent in SSD Case Inspection, involving numerous sequential steps and potential failure points, served as a demanding benchmark for assessing the system’s robustness and its capacity for intelligent, communicative action.
The robotic system’s efficacy was rigorously determined through quantifiable metrics directly tied to real-world applicability. Specifically, researchers tracked ‘Cost’, representing the number of times human intervention was required to assist the robot during task execution – a direct measure of autonomy and reliability. Simultaneously, ‘Makespan’, the total time taken to complete the entire inspection procedure, provided insight into the system’s operational speed and efficiency. By focusing on these two key performance indicators, the study moved beyond theoretical capabilities to demonstrate practical improvements in robotic task completion, offering a clear benchmark for future advancements in automated inspection systems.
Rigorous statistical analysis, employing the Highest Density Interval (HDI), revealed a substantial improvement in robotic task performance during SSD case inspection. The HDI method quantified the range within which the true reduction in both ‘Cost’ – measured by human assistance requests – and ‘Makespan’ – the total time to complete the inspection – likely falls. Results indicated not merely a trend, but a statistically significant decrease in both metrics, suggesting the implemented system demonstrably enhances efficiency and effectiveness in complex robotic procedures. This reduction signifies a move towards greater automation and a lessened reliance on human intervention, ultimately streamlining the inspection process and lowering associated operational costs.
Human evaluation consistently affirmed the utility of the system’s explanatory narratives during the SSD Case Inspection task. Evaluators reported that the generated text provided a clear and understandable account of the robot’s actions, facilitating comprehension of the complex procedural steps. This clarity wasn’t merely descriptive; it actively aided in trust and transparency, allowing human observers to readily identify why the robot performed specific actions and to anticipate subsequent steps. The consistently high ratings suggest that the system’s ability to articulate its reasoning isn’t simply a byproduct of the process, but a valuable component that enhances human-robot collaboration and improves overall task efficiency.
Beyond the Hype: Towards Adaptable, Reliable Systems
The system’s future development centers on the incorporation of episodic memory, a cognitive function allowing it to record and recall specific past experiences. This isn’t simply data storage; the AI will learn from the outcomes of previous interactions, effectively building a case history of successful and unsuccessful explanations. By referencing these ‘episodes’, the system can refine its approach to future queries, tailoring explanations not just to the current question, but to what has demonstrably worked – or failed – with similar situations. This adaptive capacity moves beyond static knowledge bases, enabling the AI to progressively improve its communication strategy and offer increasingly relevant and effective support, ultimately fostering a more intuitive and productive human-AI collaboration.
Researchers are investigating the potential of Syntactic Priming – a well-documented human phenomenon – to personalize AI explanations. This approach aims to mirror a user’s own linguistic patterns when formulating responses, effectively ‘speaking their language’ by adopting similar sentence structures and phrasing. The system analyzes a user’s communication style – perhaps gleaned from previous interactions or initial prompts – and subtly adjusts its explanations to align with those patterns. This isn’t simply about vocabulary; it’s about cognitive fluency, where explanations become easier to process because they resonate with the user’s pre-existing linguistic habits. By reducing cognitive load, Syntactic Priming promises to enhance comprehension, build trust, and ultimately foster a more effective and natural human-AI collaboration.
The development of genuinely collaborative artificial intelligence necessitates a shift from simple task execution to seamless integration within existing human workflows. This envisioned agent operates not as a replacement for human expertise, but as an intelligent support system, anticipating needs and providing transparent reasoning behind its actions. Such an AI will move beyond merely doing and focus on explaining its processes, fostering trust and enabling effective partnership. By prioritizing clarity and adaptability, the agent aims to augment human capabilities, facilitating more efficient problem-solving and informed decision-making in dynamic environments. This future hinges on creating an AI that understands not only what to do, but also how to communicate its rationale in a manner that is readily understandable and consistently reliable.
Effective operation within real-world scenarios demands more than static knowledge; a robust system necessitates a deep connection between its understanding of the world – the ontology – and its capacity for action via robot plans. Future development will center on tightly integrating these components, enabling the system to not merely know about its environment, but to dynamically adjust its plans in response to unforeseen changes. This integration allows for a shift from pre-programmed responses to adaptive behaviors, where the system can reassess goals, modify strategies, and even learn from its interactions with a fluctuating world, ultimately enhancing its reliability and usefulness in complex, unpredictable settings.
The pursuit of semantically coherent explanations, as detailed in the paper, feels…familiar. It’s a lovely ambition to ground robot actions in ontological frameworks and express them via large language models. However, one anticipates the inevitable drift. The system will confidently explain why a robot bumped into a table, using perfectly structured language, while the actual cause remains a slightly miscalibrated sensor. As Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything.” This framework, no matter how elegant, will only reflect the data-and the limitations-fed into it. The ‘contrastive explanations’ might clarify what didn’t happen, but predicting the chaotic reality of production environments remains a different problem entirely.
The Road Ahead
The coupling of ontologies with large language models, as demonstrated, offers a temporary reprieve from the inherent opacity of complex systems. It allows for the generation of explanation, but does not address the fundamental problem: that any sufficiently detailed explanation simply reveals further layers of inexplicable decision-making. The semantic coherence achieved is, at best, a locally stable state; production environments will inevitably introduce edge cases that expose the brittleness of even the most carefully curated knowledge representation. Anything labelled ‘self-healing’ simply hasn’t broken yet.
Future work will undoubtedly focus on scaling these systems to more complex robotic behaviors. However, the more pressing concern isn’t scale, but fidelity. The current reliance on human-readable language as the primary interface for explanation assumes a shared understanding that rarely exists. A truly robust system wouldn’t tell a human why it acted, but demonstrate a consistent, predictable response to identical stimuli. If a bug is reproducible, one has a stable system, not an explanation.
The inevitable consequence of this line of inquiry is the realization that documentation itself is collective self-delusion. Formal ontologies, while theoretically elegant, are ultimately abstractions-useful fictions maintained by a priesthood of knowledge engineers. The real challenge lies not in representing knowledge, but in building systems that are simple enough to be understood through direct observation.
Original article: https://arxiv.org/pdf/2602.13800.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-17 08:47