Author: Denis Avetisyan
Researchers introduce a new benchmark and environment to rigorously test the ability of artificial intelligence to perform complex, multi-step scientific reasoning using external tools.
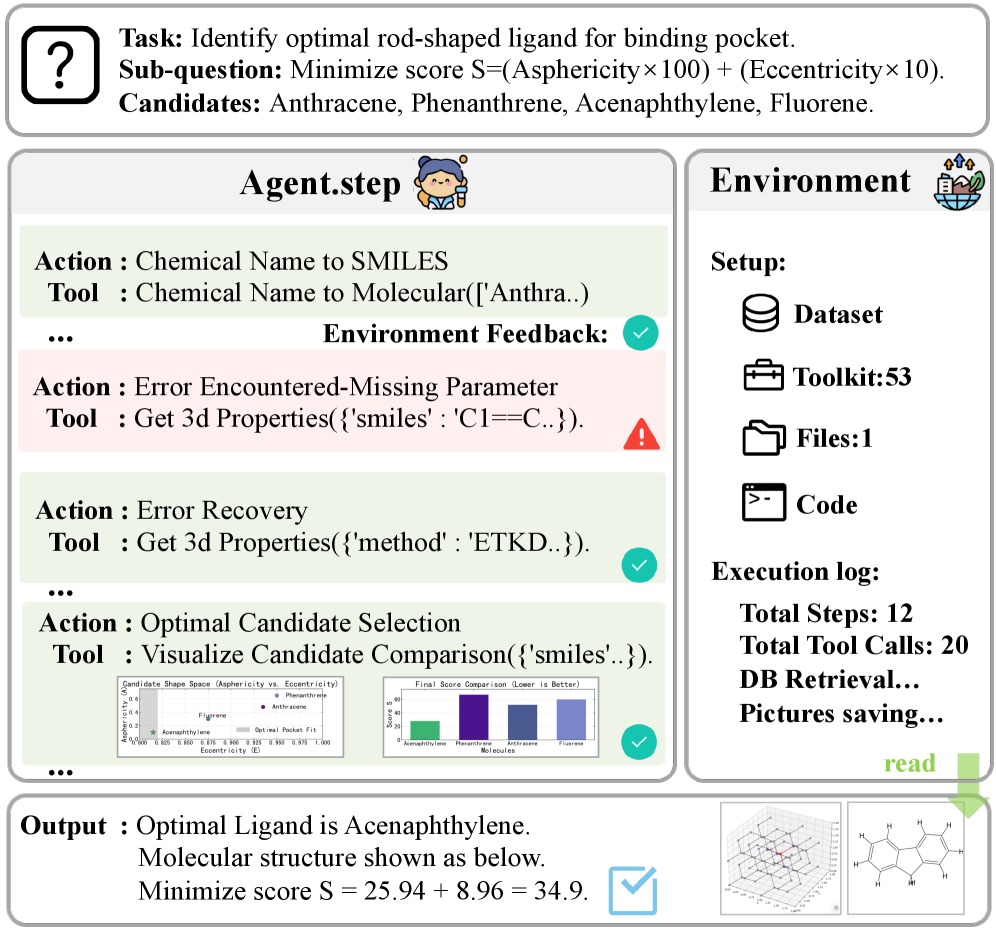
SciAgentGym and SciAgentBench provide a platform for evaluating LLM agents’ tool-use capabilities in data synthesis and scientific problem-solving.
Despite advances in large language models, robust scientific reasoning demands orchestrating complex toolkits-a capability largely absent in current benchmarks. To address this, we present ‘SciAgentGym: Benchmarking Multi-Step Scientific Tool-use in LLM Agents’, introducing SciAgentGym and SciAgentBench-a scalable environment and tiered evaluation suite for assessing multi-step scientific tool-use in LLM agents. Our evaluation reveals a critical performance bottleneck, yet demonstrates that fine-tuning with synthetically generated, logic-aware trajectories-using our SciForge method-can yield significantly improved performance, even surpassing larger models with cross-domain transfer. Could this approach pave the way for truly autonomous scientific agents capable of driving discovery?
The Fragility of Simulated Reasoning
Despite advancements in artificial intelligence, replicating the nuanced reasoning required for complex scientific problem-solving remains a substantial challenge. Current methodologies, even when implemented on powerful models like GPT-5, demonstrate limited efficacy when confronted with tasks demanding multiple sequential steps – often termed “long-horizon tasks”. Recent evaluations reveal that such models achieve a success rate of only 41.3% in these scenarios, indicating a significant gap between current capabilities and the demands of genuine scientific workflows. This difficulty isn’t simply a matter of scale; it highlights fundamental limitations in how these systems approach multi-step reasoning, error handling, and the integration of information across extended sequences of operations.
The capacity of current language models to maintain performance in evolving situations proves surprisingly fragile. While achieving a 60.6% success rate in initial interactions, their effectiveness diminishes considerably as the complexity of a task increases – specifically, as the number of sequential steps required for completion grows. Data indicates a precipitous drop to just 30.9% when the ‘interaction horizon’ expands, revealing a critical vulnerability in error recovery. This suggests that these models, despite their impressive capabilities, struggle with the cumulative effects of minor inaccuracies or unforeseen circumstances that inevitably arise in dynamic, multi-step problem-solving, highlighting the need for improved robustness and adaptive learning mechanisms.
Extending the capabilities of large language models to tackle long-horizon tasks-those requiring numerous sequential steps and sustained reasoning-introduces substantial computational and methodological challenges. The exponential increase in processing demands with each added step quickly strains even the most powerful hardware. Beyond raw computational power, current methodologies struggle with maintaining contextual coherence and avoiding error propagation over extended interactions. Each step introduces potential for inaccuracies, and without robust error-recovery mechanisms, these errors compound, leading to drastically reduced performance. Furthermore, effectively training these models requires datasets of sufficient length and complexity, a resource that is currently limited and difficult to generate. Addressing these hurdles demands innovation in model architecture, training strategies, and the development of novel techniques for managing computational complexity and ensuring reliable long-term reasoning.
Cultivating Scientific Intelligence: The SciAgent Framework
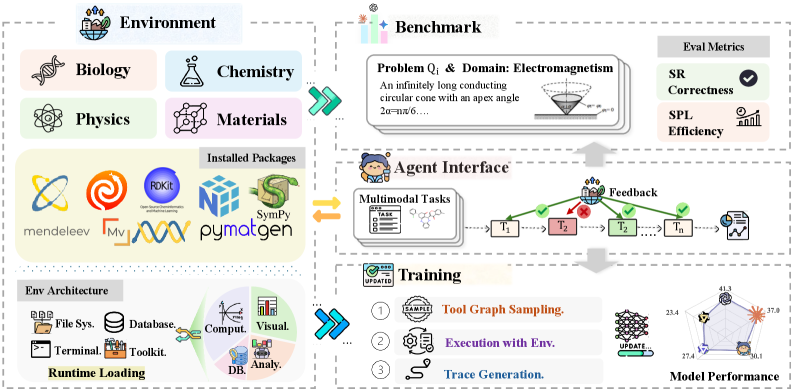
SciAgentGym is a software environment designed to facilitate the development and assessment of Large Language Model (LLM) Agents specifically within scientific domains. This framework provides a standardized platform for training agents to perform tasks requiring scientific knowledge and reasoning. Its extensible architecture allows researchers to easily integrate new datasets, tools, and evaluation metrics. The environment supports a range of scientific applications, including hypothesis generation, experiment design, data analysis, and scientific report writing. By offering a controlled and reproducible setting, SciAgentGym enables rigorous testing and comparison of different LLM agent approaches in scientific contexts.
SciAgentGym facilitates tool use by enabling Large Language Model (LLM) Agents to interact with and leverage external tools within the scientific workflow. This capability extends agent functionality beyond inherent language processing skills, allowing them to perform actions such as querying databases, running simulations, or executing code. Tool integration is achieved through a standardized API, permitting agents to dynamically select and utilize appropriate tools based on task requirements. Consequently, agents can address complex scientific problems requiring data retrieval, computation, or specialized analysis that would otherwise be inaccessible through language-based interaction alone.
The SciAgent framework incorporates multi-turn reasoning capabilities, enabling agents to iteratively improve performance through a process of observation and adaptation. This is achieved by allowing the agent to receive feedback on intermediate results – such as the output of tool use or partial solutions – and subsequently refine its approach for subsequent steps. Unlike single-turn systems that produce a final answer directly, SciAgent agents can engage in multiple rounds of reasoning, utilizing feedback to correct errors, explore alternative strategies, and converge on more accurate or complete solutions. This iterative process is crucial for complex scientific tasks requiring sequential problem-solving and error analysis.
Forging Data from First Principles: SciForge
SciForge mitigates the limited availability of labeled datasets for training scientific tool-use applications through automated example generation. The system programmatically creates training instances by simulating tool application and expected outcomes, effectively expanding the size of usable datasets without manual annotation. This process is crucial because acquiring sufficient labeled data for complex scientific workflows is often expensive and time-consuming, hindering the development of robust and reliable AI-driven scientific tools. By autonomously generating these examples, SciForge reduces reliance on manually curated data and accelerates the training process for machine learning models designed to assist in scientific discovery.
SciForge utilizes a Tool Dependency Graph comprising 1,780 domain-specific tools sourced from Physics, Chemistry, Biology, and Materials Science. This graph doesn’t simply list tools; it explicitly defines the relationships between them, establishing a network of dependencies. By mapping these connections, SciForge can infer logical sequences for tool application, enabling the automatic construction of workflows. The system determines which tools are appropriate given a specific task and the order in which they should be executed, based on established dependencies within the graph. This relational structure is critical for generating synthetic training data, as it ensures the generated workflows are not only functional but also reflect established scientific practices.
By integrating a Tool Dependency Graph with Large Language Model (LLM) Agents, SciForge moves beyond simple text-based reasoning to incorporate domain-specific knowledge about scientific tools and their interrelationships. This enriched understanding allows LLM Agents to not only identify relevant tools but also to construct and evaluate logically sound workflows, effectively expanding their problem-solving capabilities within complex scientific domains. The system provides contextual awareness regarding tool dependencies, enabling the agent to predict outcomes and refine strategies beyond what is achievable through textual data alone, thereby increasing the reliability and accuracy of automated scientific processes.
![Analysis of SciAgentBench reveals a negative correlation between tool-call frequency and success rate ([latex]r=-0.18[/latex]), suggesting ineffective iterative loops, and highlights the importance of adaptation, parameter tuning, strategy pivoting, and loop escape for successful error recovery.](https://arxiv.org/html/2602.12984v1/x6.png)
Establishing a Standard for Scientific Intelligence: SciAgentBench
SciAgentBench is designed as a standardized evaluation platform for assessing agent capabilities in complex, multi-step scientific problem-solving. The benchmark comprises 259 distinct tasks, each broken down into an average of 4.38 sub-questions, resulting in a total of 1,134 individual queries. This granular structure allows for detailed analysis of an agent’s performance at each stage of a problem-solving process, rather than solely focusing on end-result accuracy. The tasks are formulated to require agents to utilize external tools and resources to arrive at solutions, simulating real-world scientific investigation workflows.
SciAgentBench facilitates the assessment of agent capabilities across a diverse range of scientific disciplines. The benchmark incorporates tasks requiring reasoning and tool utilization within Physics, encompassing areas such as mechanics and thermodynamics; Chemistry, including organic and inorganic chemistry problems; Biology, covering topics like genetics and molecular biology; and Materials Science, focused on the properties and applications of different materials. This multi-domain approach allows for a comprehensive evaluation of an agent’s general scientific reasoning abilities, rather than performance limited to a single specialized field.
Evaluations conducted using the SciAgentBench framework demonstrate that the SciAgent-8B model achieves a 6.7% performance increase compared to the Qwen3-VL-235B-Instruct model on scientific tool-use tasks. This improvement indicates SciAgent-8B’s enhanced capability in executing multi-step reasoning and tool interaction required for complex scientific problem-solving, as assessed by the benchmark’s 259 tasks and 1,134 sub-questions. The performance gain was observed across multiple scientific domains, including Physics, Chemistry, Biology, and Materials Science, suggesting a broad applicability of the model’s enhanced capabilities.
Towards a Future of Collaborative Discovery
The SciAgent framework represents a significant step towards automating traditionally manual scientific processes. This innovative system doesn’t simply execute pre-programmed tasks; it actively designs and implements complex workflows, from hypothesis generation and experiment design to data analysis and interpretation. By integrating various scientific tools and knowledge sources, SciAgent can autonomously navigate research challenges, iteratively refining its approach based on observed results. This capability minimizes the need for constant human intervention, freeing scientists to focus on higher-level strategic thinking and creative problem-solving. The framework’s adaptability allows it to be applied across diverse scientific fields, promising to accelerate discovery by efficiently managing the increasingly complex demands of modern research.
Continued development of SciAgent prioritizes increasing the system’s resilience when facing unexpected data or experimental conditions, thereby improving its ability to reliably navigate complex scientific challenges. A central aim is to seamlessly integrate a wider array of specialized scientific tools – from molecular modeling software to astronomical databases – allowing the agent to leverage the full spectrum of available resources. This expansion isn’t limited to tool access; future iterations will extend the agent’s capabilities to encompass a broader range of scientific disciplines, moving beyond current focuses to tackle problems in fields such as materials science, climate modeling, and drug discovery, ultimately fostering a more universally applicable platform for autonomous scientific exploration.
The trajectory of scientific advancement is poised for a significant shift, with increasingly sophisticated autonomous agents acting not as replacements for researchers, but as collaborative partners. These agents promise to accelerate discovery by autonomously formulating hypotheses, designing experiments, analyzing complex datasets, and identifying patterns often missed by human observation. This synergy allows scientists to focus on higher-level conceptualization and interpretation, while agents handle computationally intensive and repetitive tasks. The resulting partnership is expected to drastically reduce the time required to move from initial inquiry to validated findings, fostering innovation across diverse scientific disciplines and ultimately expanding the boundaries of human knowledge.
The pursuit of robust LLM agents, as detailed within this work, echoes a fundamental truth about complex systems. One anticipates eventual decay, not despite architectural ingenuity, but because of it. Tim Berners-Lee observed, “The web is more important than any one search engine.” This sentiment applies equally to SciAgentGym and SciAgentBench; the benchmark isn’t merely a test of current agents, but a living ecosystem for observing their evolution. The framework’s capacity to generate synthetic data with SciForge acknowledges that any initial configuration will inevitably require adaptation, and that sustained growth relies on continuous refinement rather than static perfection. The very act of benchmarking is a prophecy fulfilled – a forecast of where current limitations lie, and a catalyst for future iterations.
What’s Next?
The creation of SciAgentGym and SciAgentBench does not resolve the underlying tension: one does not build a scientific mind, one cultivates a substrate for its emergence. This work, like all attempts at formalized benchmarking, merely identifies the current boundaries of failure – the specific ways in which these systems will, inevitably, misunderstand the world. The synthesis methods, such as SciForge, are not solutions, but temporary reprieves, delaying the moment when inherent limitations become catastrophically apparent.
Future efforts will not be judged by the benchmarks conquered, but by the surprising modes of failure discovered. The pursuit of ‘general’ scientific reasoning is a fool’s errand. There are no best practices – only survivors, systems that happen to stumble upon configurations robust enough to withstand the chaos. Each carefully curated dataset is an artifact, a snapshot of a problem space that will, by the time the agent has ‘solved’ it, have already shifted.
The true challenge lies not in teaching agents what we know, but in enabling them to learn from what we do not. Order is just cache between two outages. The next generation of these systems will not be defined by their ability to answer questions, but by their capacity to formulate better ones – questions that expose the limits of both the agent and the knowledge it seeks.
Original article: https://arxiv.org/pdf/2602.12984.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-16 08:59