Author: Denis Avetisyan
A new benchmark assesses how easily developers can guide multi-agent systems in translating natural language into functional database schemas.
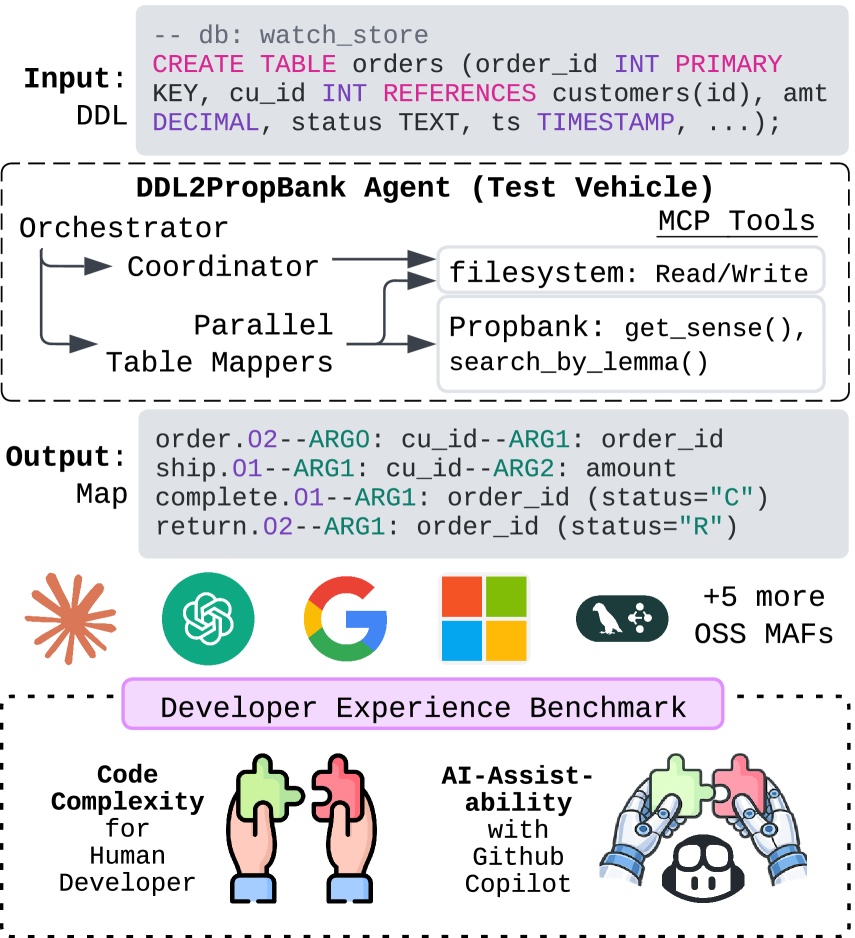
This paper introduces DDL2PropBank, a novel framework for benchmarking developer experience with multi-agent systems via a relational schema mapping task and analysis of AI-assistability.
Despite the promise of multi-agent frameworks to simplify LLM-driven software development, a standardized evaluation of their developer experience has remained elusive. This paper introduces ‘DDL2PropBank Agent: Benchmarking Multi-Agent Frameworks’ Developer Experience Through a Novel Relational Schema Mapping Task’, presenting a new benchmark, DDL2PropBank, which assesses both code complexity and the efficacy of AI coding assistants in generating correct implementations for mapping relational database schemas to PropBank rolesets. Our results reveal substantial variation in developer overhead-spanning a threefold complexity spectrum-and demonstrate that structural alignment scores can reliably predict performance for some frameworks, but not all. Will these findings enable the development of more accessible and efficient multi-agent systems for complex software tasks?
The Evolution of Software Architecture: From Monoliths to Agents
Historically, software systems were often built as large, unified entities – monolithic applications – designed to handle all aspects of a given task. However, as these systems grew to encompass increasingly intricate functionalities, managing their complexity became a significant challenge. The very structure that once provided simplicity now hindered adaptability and scalability; even minor modifications could trigger cascading failures and require extensive retesting. This inflexibility stems from the tightly coupled nature of monolithic designs, where changes in one component invariably impact others. Consequently, a demand arose for a new paradigm-one that embraced modularity, decentralization, and the ability to respond dynamically to evolving requirements, paving the way for more resilient and manageable software architectures.
The Agent-as-a-Tool pattern represents a significant departure from traditional software architecture by embracing decomposition and autonomy. Instead of a single, complex program handling an entire task, this approach breaks it down into numerous, specialized agents – each possessing a defined role and the ability to operate independently. These agents aren’t simply subroutines; they are self-contained entities capable of perceiving their environment, making decisions, and acting upon those decisions without constant external direction. This modularity enhances resilience, as the failure of one agent doesn’t necessarily compromise the entire system, and allows for greater adaptability; new agents can be introduced or existing ones modified without disrupting core functionality. Furthermore, this pattern fosters scalability, as individual agents can be easily replicated or distributed across multiple processing units to handle increased workloads, ultimately mirroring the efficiency and flexibility observed in complex natural systems.
The true power of agent-based systems isn’t simply in the autonomy of individual agents, but in their coordinated action, a feat achieved through a dedicated Orchestrator component. This central element functions as a conductor, defining the execution flow and managing the interactions between agents to accomplish complex tasks. Rather than dictating how an agent performs its function, the Orchestrator specifies when and with what inputs, allowing agents to retain their specialized expertise while adhering to a larger, overarching process. This approach fosters a dynamic and adaptable system; changes to the workflow are implemented through modifications to the Orchestrator, not through rewriting individual agent logic. Consequently, the Orchestrator becomes critical for scalability and maintainability, ensuring that even a large network of agents operates cohesively and efficiently towards a common goal.
Standardizing Developer Effort: The DDL2PropBank Framework
DDL2PropBank establishes a standardized evaluation of developer effort required to incorporate agents within applications exhibiting database interactions. The framework quantifies integration difficulty by measuring the ability to translate Data Definition Language (DDL) – specifically, database schemas – into a format usable by agents, focusing on the accurate identification of database operations and their corresponding semantic meanings. This assessment is performed across a diverse set of databases and application scenarios, providing a comparative metric for different agent integration techniques and tools. Rigor is maintained through defined evaluation criteria and a publicly available dataset, allowing for reproducible results and community-driven improvement of agent development workflows.
DDL2PropBank benchmarks developer experience by evaluating the mapping of database schemas to semantic representations utilizing PropBank rolesets. This task presents significant challenges due to the inherent differences in structure between relational databases and the predicate-argument frames defined in PropBank. Specifically, database schemas define entities and relationships, while PropBank focuses on actions and the roles participants play in those actions. Accurate mapping requires identifying the predicates within the schema – typically represented by function or procedure names – and then associating database columns with the appropriate PropBank arguments based on their semantic roles (e.g., Agent, Patient, Instrument). Successful completion of this mapping is crucial for enabling agents to understand database interactions and perform tasks based on the underlying data semantics.
Semantic role labeling (SRL) is a natural language processing technique used to identify the arguments associated with a predicate in a sentence, effectively dissecting the predicate-argument structure. DDL2PropBank utilizes SRL by relying on annotated corpora, most notably the PropBank dataset, which provides examples of sentences with predicates and their corresponding arguments labeled with specific roles – such as Agent, Patient, and Instrument. This supervised learning approach requires models to be trained on these annotated datasets to accurately predict the semantic roles in new, unseen text, enabling the benchmark to assess how well systems can map database operations to meaningful semantic representations and ultimately, facilitate integration with agent-based applications. The accuracy of SRL is directly dependent on the quality and size of the training corpora like PropBank.
Automating the Development Lifecycle: Code Generation and Evaluation
LLM Code Generation automates the creation of code required for agent tasks by leveraging large language models to translate task descriptions into executable code. This approach significantly reduces the need for manual coding, accelerating development cycles and enabling rapid prototyping of agent behaviors. The generated code can encompass various programming languages and frameworks, depending on the LLM’s training and the specified task requirements. This capability is particularly useful in dynamic environments where agent tasks are frequently changing or require adaptation, as code can be generated on-demand to address new situations without human intervention. The complexity of generated code ranges from simple scripts to more intricate programs, dependent on the sophistication of the agent’s desired functionality.
LLM-as-Judge automates code quality assessment by evaluating generated code against predefined structural and functional criteria. This process includes static analysis to identify potential errors such as syntax violations, code style inconsistencies, and security vulnerabilities. Furthermore, the system executes the generated code with a series of test cases, verifying its functionality and adherence to specified requirements. Evaluation metrics encompass code complexity, test coverage, and the presence of common bug patterns. The results of these automated checks are compiled into a report detailing identified issues and providing suggestions for improvement, enabling iterative refinement of the generated code without manual intervention.
The Model Context Protocol facilitates automated code generation and evaluation by enabling Large Language Models (LLMs) to interact with external resources. This protocol defines a standardized interface allowing LLMs to query and utilize data from diverse sources, including APIs, databases, and file systems. Specifically, it allows LLMs to retrieve relevant information – such as documentation, code examples, or testing frameworks – necessary for completing tasks or assessing generated code. The protocol supports both synchronous and asynchronous communication, and defines data formats for requests and responses, ensuring compatibility and interoperability between the LLM and external tools. This external access is critical for grounding LLM outputs in factual data and enabling more complex, reliable automation workflows.
Quantifying AI Collaboration: The Metric of AI-Assistability
AI-Assistability represents a fundamental shift in evaluating the effectiveness of software development frameworks, moving beyond traditional metrics to directly assess how well they facilitate collaboration with artificial intelligence coding assistants. This core metric quantifies a framework’s capacity to enable AI to generate code that not only compiles without errors, but also successfully passes all defined tests, resulting in fully executable functionality. High AI-Assistability signifies a framework is well-structured and provides clear guidance, allowing AI models to understand the intended logic and contribute meaningfully to the development process. Ultimately, a framework’s score on this metric indicates its potential to accelerate development cycles, reduce manual coding effort, and unlock new levels of productivity by seamlessly integrating human expertise with the power of AI.
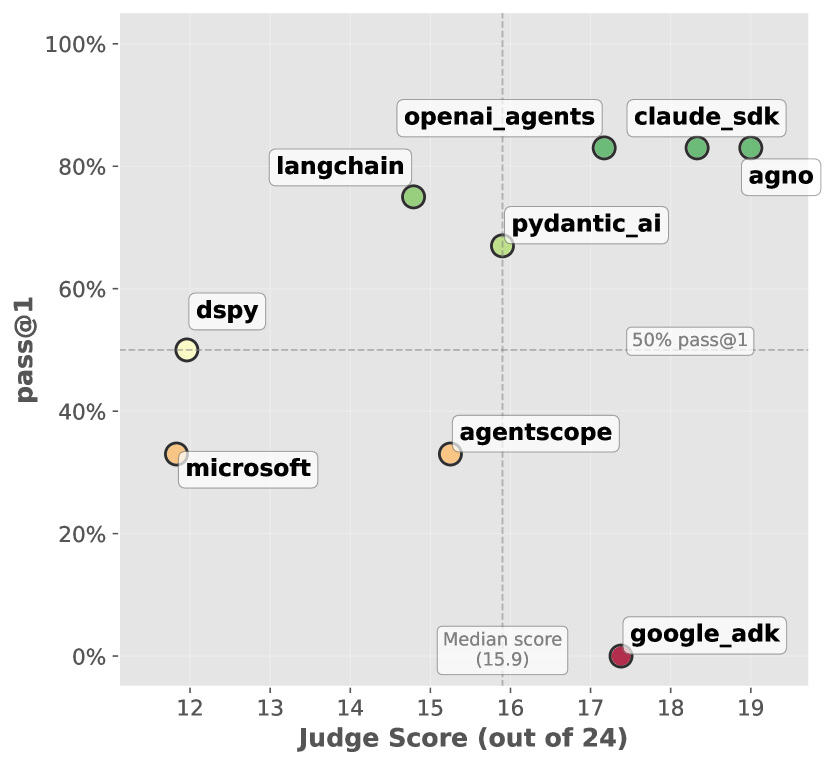
A critical benchmark for evaluating the effectiveness of AI coding assistance lies in the metric known as Pass@1. This value represents the probability that, given a set of code generation attempts, at least one of those samples will successfully pass all designated tests – a direct measure of functional correctness. Recent evaluations demonstrate the Agno framework’s superior performance in this area, achieving an impressive 83% Pass@1 rate. This result signifies that, in approximately 83 out of 100 attempts, Agno successfully generates at least one fully functional code sample, notably exceeding the performance of competing frameworks and establishing a new standard for reliable AI-assisted code generation.
The effectiveness of AI coding assistants is demonstrably linked to the complexity of the underlying codebase; highly intricate systems often present significant challenges for automated assistance, ultimately reducing the likelihood of successful code generation. Recent evaluations highlight that simpler frameworks yield better results, with Agno and Pydantic AI achieving notable performance through minimal code complexity-each framework is constructed with only 54 lines of code (LLOC). This emphasis on streamlined design suggests that prioritizing code simplicity isn’t merely a matter of elegance, but a crucial engineering consideration for maximizing the potential of AI-driven development tools and ensuring reliable, executable outputs.
The pursuit of elegant solutions, as demonstrated by the DDL2PropBank benchmark, aligns with a fundamental principle of mathematical rigor. The framework’s emphasis on evaluating developer experience through relational schema mapping isn’t merely about functional correctness, but about the provability of the generated code. As Paul Erdős stated, “A mathematician knows a lot of things, but not everything.” This echoes the challenge presented by complex codebases – even with AI-assistability, complete understanding and verification remain paramount. DDL2PropBank, by focusing on code complexity and semantic annotation, effectively seeks to quantify and address the gaps in that understanding, mirroring the endless quest for a more complete and beautiful mathematical truth.
What’s Next?
The introduction of DDL2PropBank exposes a discomforting truth: the prevailing metrics for multi-agent framework evaluation prioritize superficial ‘ease of use’ over demonstrable correctness. The benchmark implicitly questions whether current frameworks truly assist developers, or merely lower the barrier to producing flawed implementations. The observation that AI coding assistants struggle with relational schema mapping isn’t surprising; heuristics, after all, are compromises, not virtues. It highlights where convenience conflicts with correctness, and the limitations of large language models when confronted with tasks demanding logical precision.
Future work must move beyond assessing code volume or lines-of-code changed. A rigorous evaluation demands formally verifying the semantic equivalence of generated code against a known-correct solution. The task isn’t simply to produce something that compiles, but to guarantee that the agent’s reasoning accurately reflects the underlying relational structure. This necessitates a shift towards provable algorithms and a willingness to embrace mathematical purity over expedient approximations.
Ultimately, the field needs to acknowledge that ‘developer experience’ is meaningless without a corresponding guarantee of logical validity. The pursuit of AI-assistability shouldn’t aim to automate error, but to elevate the standard of correctness. The benchmark provides a foundation for that pursuit, demanding a move away from empirical testing and toward formal verification as the ultimate arbiter of success.
Original article: https://arxiv.org/pdf/2602.11198.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-16 00:38