Author: Denis Avetisyan
Researchers have developed a novel approach to train robots to perform complex tasks by combining visual perception, language understanding, and action planning.

VLAW iteratively refines vision-language-action policies using a physically-grounded world model and synthetic data generated via flow-matching and offline reinforcement learning.
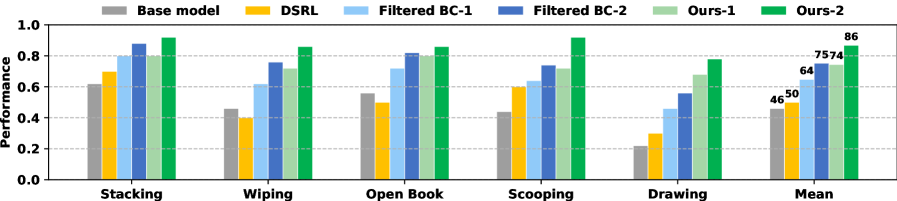
Achieving robust robotic manipulation requires substantial real-world data, a resource often limited in practice. This paper introduces ‘VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model’, a framework addressing this challenge by iteratively refining both a vision-language-action (VLA) policy and a physically-grounded world model through mutual improvement. Specifically, VLAW leverages a learned simulator to generate synthetic data, enhancing policy learning and overcoming the limitations of existing world models trained on insufficient or biased datasets. Our experiments demonstrate a [latex]39.2\%[/latex] absolute success rate improvement on real-world robotic tasks, raising the question of how such iterative co-improvement strategies can further unlock the potential of embodied AI.
Bridging the Reality Gap: The Challenge of Efficient Robotic Learning
Conventional reinforcement learning methods often demand a prohibitively large amount of real-world interaction for robots to acquire even basic skills. This sample inefficiency stems from the need for exhaustive trial-and-error-a robot must repeatedly attempt actions and receive feedback to refine its behavior. The sheer volume of data required poses a significant obstacle, as each physical experiment consumes valuable time and resources, and can lead to wear and tear on robotic hardware. Consequently, training robots to operate effectively in unstructured, dynamic environments becomes a laborious and expensive undertaking, limiting the practical deployment of these systems beyond highly controlled settings. The challenge isn’t a lack of algorithms, but rather the difficulty in acquiring sufficient data to reliably train them.
The practical application of robotic systems is significantly hampered by the sheer volume of data required for effective learning in real-world scenarios. Unlike algorithms trained on readily available datasets, robots operating in complex environments – think bustling warehouses, unpredictable construction sites, or even domestic homes – must learn through direct physical interaction. Each attempt, whether successful or not, consumes valuable time and resources, and can even lead to wear and tear on the robot itself. This makes data acquisition not only slow and expensive, but also potentially damaging to the equipment. Consequently, deploying robots in dynamic, real-world settings presents a substantial logistical and financial hurdle, limiting their widespread adoption despite advancements in artificial intelligence and robotic hardware.
Roboticists increasingly turn to simulation as a means of efficiently training robots, yet a significant hurdle persists: the disparity between simulated environments and the complexities of the real world. While a robot may learn a task flawlessly within a virtual space, transferring that knowledge to a physical setting often results in diminished performance due to unmodeled dynamics, sensor noise, and unforeseen environmental factors. This ‘sim-to-real’ gap isn’t merely a matter of increased noise; it represents a fundamental difference in the probability distributions governing robot behavior, meaning a policy optimized in simulation may operate far from the optimal solution when deployed on a physical robot. Consequently, research focuses on techniques to make simulation more representative of reality, or to develop policies robust enough to generalize across these domains, often involving domain randomization, adaptive simulation, and sophisticated transfer learning algorithms.
Overcoming the limitations of transferring skills learned in simulation to the real world necessitates innovative strategies in both data enrichment and decision-making refinement. Current research explores techniques like domain randomization, where simulated environments are intentionally varied to force the robot to learn robust policies, and generative adversarial networks (GANs) to create synthetic data that more closely mirrors real-world sensor inputs. Simultaneously, advanced policy optimization algorithms, including those leveraging meta-learning and hierarchical reinforcement learning, aim to improve the efficiency with which robots adapt to new situations and generalize learned behaviors. These combined efforts seek to minimize the discrepancy between simulated and real-world dynamics, ultimately enabling robots to learn more quickly and reliably in complex, unpredictable environments – a crucial step toward widespread robotic autonomy.
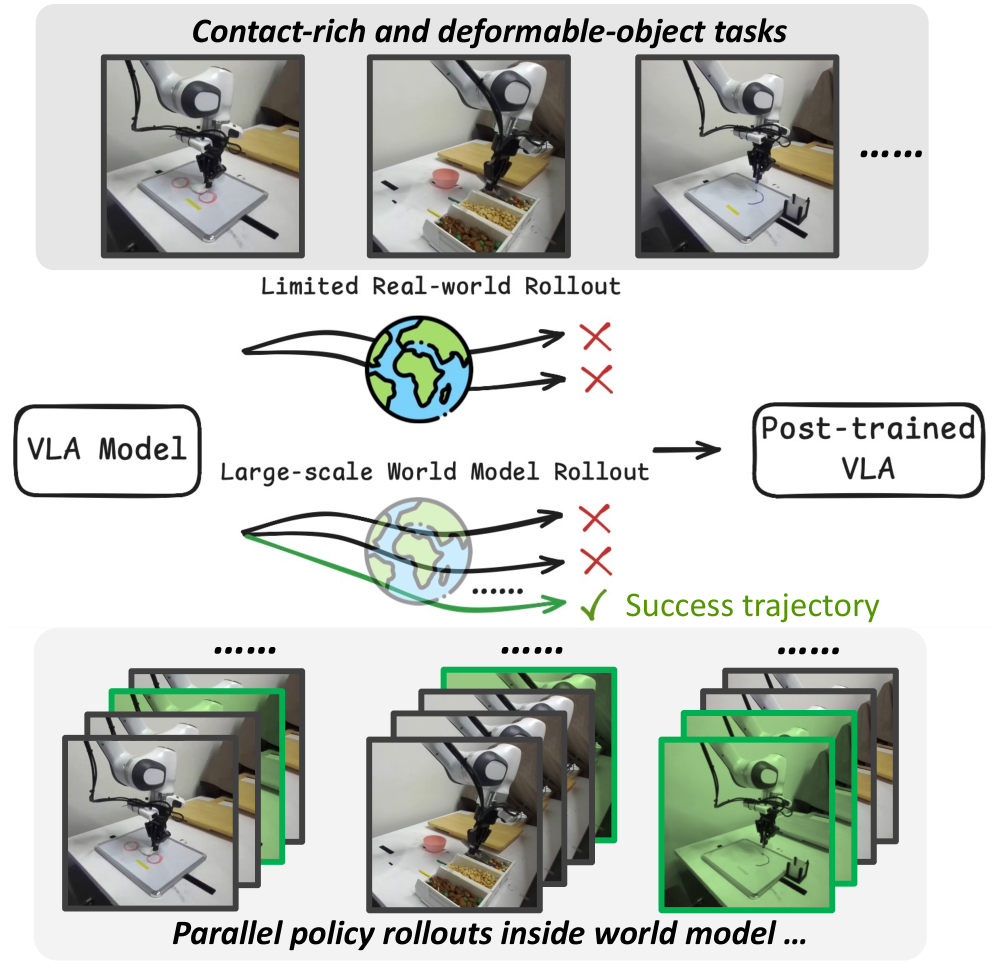
VLAW: A Framework for World-Model Assisted Policy Learning
The VLAW framework addresses data scarcity in robotic learning by employing an action-conditioned world model. This model learns a predictive representation of the environment, enabling the generation of synthetic data based on specified actions. By conditioning the world model on the robot’s actions, VLAW can simulate trajectories and corresponding state transitions, effectively expanding the training dataset beyond the limited data collected from physical interactions. This synthetic data is then combined with real-world data to train the policy, reducing the reliance on costly and time-consuming physical trials and accelerating the learning process.
The generation of synthetic data via the Action-Conditioned World Model directly addresses the data efficiency challenges inherent in reinforcement learning for robotics. By simulating robotic interactions and their resulting states, the model creates a substantially larger training dataset than would be feasible through physical experimentation alone. This expanded dataset, comprising both real and simulated experiences, accelerates policy learning by providing the algorithm with a more comprehensive understanding of the environment and the effects of various actions. Consequently, the robot can achieve comparable or improved performance with significantly fewer real-world trials, reducing both the time and expense associated with training and deployment.
Flow matching is employed to update the VLA Policy by reformulating the policy learning problem as a continuous normalization flow. This technique transforms the complex, high-dimensional distribution of robot states and actions into a simpler, tractable distribution, enabling efficient optimization. Specifically, flow matching learns a velocity field that transports samples from the initial distribution – comprising both real robotic experiences and synthetically generated data from the world model – to a target distribution, typically a Gaussian. By optimizing this velocity field, the policy is updated to maximize the likelihood of successful actions, effectively leveraging the augmented dataset and accelerating convergence compared to traditional reinforcement learning methods. The process avoids explicit density estimation, further improving computational efficiency and stability.
The accelerated learning enabled by VLAW directly addresses a key barrier to robotic deployment: the extensive data requirements for complex manipulation tasks. Traditional reinforcement learning methods often necessitate millions of physical interactions to achieve acceptable performance, a process that is time-consuming, expensive, and potentially damaging to robotic hardware. By leveraging a world model to generate synthetic data, VLAW significantly reduces the need for real-world trials, allowing robots to acquire proficiency in tasks like grasping, assembly, and tool use with fewer physical interactions. This increased data efficiency translates to faster training times, reduced development costs, and improved robustness, ultimately facilitating the wider application of robots in manufacturing, logistics, healthcare, and other real-world environments.

Evaluating Success with Vision-Language Reward Modeling
The reward modeling process utilizes the `Qwen3-VL-4B-Instruct` vision-language model to quantitatively assess the success of robotic actions. This model takes visual observations as input and generates a scalar reward signal indicating the degree to which the observed state satisfies the task requirements. Specifically, the model is prompted with a description of the desired outcome and then analyzes the visual input to determine the correspondence between the observed scene and the stated goal. The resulting reward value serves as a proxy for task completion, enabling automated evaluation of robotic trajectories without requiring manually defined metrics or human intervention. This approach allows for flexible assessment criteria, adapting to variations in environmental conditions and task specifications based on the model’s understanding of the visual input and the provided textual prompts.
The utilization of a vision-language model as a reward function allows for task success criteria to be defined through natural language instructions paired with visual observations, rather than requiring manually engineered reward functions or precise state-space definitions. This approach facilitates adaptation to new environments and goals without retraining the core robotic system; the reward model can interpret varying visual contexts and adjust success assessments accordingly. Specifically, the model processes both visual input from the robot’s sensors and textual descriptions of the desired outcome, enabling it to generalize success criteria across diverse scenarios and providing a flexible framework for specifying complex tasks without explicit programming of every possible condition.
The reinforcement learning policy is updated iteratively based on the reward signals provided by the vision-language reward model. Specifically, the model evaluates completed trajectories – sequences of robot states and actions – and assigns a scalar reward value reflecting the degree of success. This reward is then used to calculate a policy gradient, which adjusts the robot’s control parameters to increase the probability of selecting actions that lead to higher rewards. Consequently, the policy directly optimizes for behaviors that the reward model deems successful, effectively guiding the robot toward improved performance and adaptation to the specified task.
The effectiveness of robotic learning is directly correlated to the quality of the reward signal; aligning this signal with readily interpretable visual cues ensures the robot accurately understands task completion. This approach bypasses the need for complex, hand-engineered reward functions and instead leverages the model’s capacity to associate visual states with successful outcomes. By directly linking observed visual features – such as object presence, position, or configuration – to reward values, the robot can efficiently learn policies that consistently achieve the desired results in a given environment. This visual grounding facilitates robust performance, particularly in scenarios with variations in lighting, object appearance, or environmental layout, as the reward function remains consistent regardless of these factors.
![By simulating diverse trajectories with a world model, the system identifies successful alternatives [latex]\pi_{0.5}[/latex] for failure cases observed in real-world rollouts, enabling improved policy learning for tasks like grasping and circular motion.](https://arxiv.org/html/2602.12063v1/x8.png)
Theoretical Underpinnings and Future Directions
The foundation of this research lies in the principles of Regularized Reinforcement Learning, a framework that addresses a critical challenge in robotic control: efficiently learning policies from limited real-world data. This approach introduces regularization terms into the policy optimization process, encouraging the learned policy to stay close to a prior distribution – often informed by synthetic data. By strategically combining real and synthetic experiences, the algorithm mitigates the risks associated with exploring potentially dangerous or costly states. This isn’t simply about augmenting the dataset; the regularization actively shapes the learning process, ensuring that the synthetic data guides the policy towards safer and more effective behaviors. The theoretical underpinnings demonstrate how carefully calibrated regularization can reduce variance and accelerate convergence, ultimately enabling robots to learn complex tasks with greater efficiency and robustness, even when real-world data is scarce.
Advantage-weighted regression represents a crucial refinement within the policy optimization process, directly addressing the challenge of efficiently learning from complex data. This technique prioritizes learning from experiences that demonstrate a significant advantage over the average performance, effectively amplifying the signal from valuable actions. By weighting regression targets based on the advantage function – the difference between an action’s actual reward and the expected reward – the algorithm focuses on improving policies in ways that yield substantial gains. This targeted approach accelerates convergence towards optimal performance by diminishing the influence of suboptimal or irrelevant data, ultimately leading to more robust and effective policies. The method avoids being bogged down by noisy or uninformative experiences, enabling the agent to rapidly refine its strategy and achieve superior results.
Virtual Learning with World Models (VLAW) represents a significant advancement in robotic learning by integrating the predictive capabilities of world models with learned reward functions. This synergistic approach allows robots to simulate and evaluate potential actions within a virtual environment, dramatically increasing sample efficiency and accelerating the learning process. Through this method, VLAW achieves a demonstrable performance gain, exhibiting an 11.6% improvement in task success rates when contrasted with traditional reinforcement learning techniques. This enhancement stems from the system’s ability to proactively explore optimal policies in simulation before deployment in the real world, effectively mitigating the risks and costs associated with physical experimentation and paving the way for more robust and adaptable robotic automation.
Continued development of VLAW prioritizes scaling its capabilities to address increasingly intricate challenges within robotics and automation. Researchers intend to move beyond current benchmarks by testing the system in more varied and unpredictable environments, demanding greater adaptability and resilience. A key focus will be on enhancing the generalizability of learned policies, aiming for performance that isn’t limited to the specific conditions of the training data. This includes investigating techniques such as domain randomization, meta-learning, and robust optimization to ensure VLAW can reliably execute tasks even when faced with unforeseen circumstances or perturbations, ultimately paving the way for wider deployment in real-world applications.
The presented VLAW framework embodies a holistic approach to robot learning, mirroring the interconnectedness of systems. It isn’t simply about improving a vision-language-action policy in isolation, but about iteratively refining it through a physically-grounded world model and synthetic data generation. This resonates with Blaise Pascal’s observation: “The eloquence of a man is never so great as when he does not speak.” In this context, the ‘silence’ represents the initial limitations of the policy; it’s through the interaction with the world model-the ‘speaking’-and the generation of synthetic data that the system truly learns and becomes eloquent in its manipulation tasks. The iterative process acknowledges that structure – the VLAW framework itself – dictates behavior, but that behavior is ultimately emergent, shaped by continuous interaction and refinement.
The Road Ahead
The introduction of VLAW suggests a critical point: attempting to refine a policy without simultaneously addressing the generative engine underpinning it is akin to polishing the leaves while the roots remain untended. The iterative co-improvement strategy, while promising, merely shifts the question – to what extent can a synthetic world, however physically grounded, truly capture the subtle, often unpredictable, nuances of reality? One suspects the devil, as always, will reside in the distribution shift.
Future work must address the limitations inherent in any simulation. Expanding the fidelity of the world model is a natural progression, but a more fundamental challenge lies in developing methods to actively detect and correct for discrepancies between simulation and reality. Simply generating more data is not a solution; a system needs the capacity for self-assessment, a feedback loop that acknowledges the inherent imperfection of its internal representation.
Ultimately, the pursuit of robust robot manipulation hinges on building systems that understand not just what to do, but why – and that requires a level of abstraction that transcends mere pattern recognition. The architecture must allow for causal reasoning, for anticipating unforeseen circumstances, and for gracefully adapting when the world refuses to conform to expectations. A complex organism does not simply react; it anticipates, adjusts, and endures.
Original article: https://arxiv.org/pdf/2602.12063.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-15 22:53