Author: Denis Avetisyan
Researchers have developed a new framework that translates natural language into complex, physically-simulated environments.
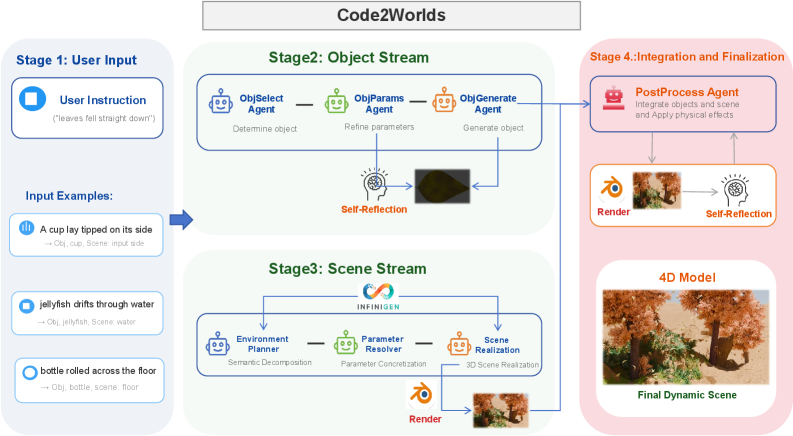
Code2Worlds leverages code generation and closed-loop refinement to create temporally coherent 4D scenes from language instructions.
Achieving truly intelligent spatial understanding demands more than visually plausible scenes; it requires dynamic world simulations grounded in physical laws. The work presented in ‘Code2Worlds: Empowering Coding LLMs for 4D World Generation’ addresses the challenges of extending coding large language models to generate temporally coherent 4D environments. This is accomplished through a novel framework that formulates 4D generation as language-to-simulation code creation, utilizing a dual-stream architecture and a physics-aware closed-loop refinement process. Can this approach unlock a new era of interactive and physically consistent virtual worlds generated directly from natural language?
Unveiling Worlds from Language: The Challenge of Dynamic Scene Synthesis
The ambition to synthesize fully realized, dynamic 4D scenes – environments evolving across three spatial dimensions and time – directly from textual input presents a formidable challenge at the forefront of computer graphics and simulation. Current limitations stem from the sheer complexity of translating abstract language into concrete, physically plausible realities; a simple sentence like “a red ball bounces across a wooden floor” necessitates detailed instantiation of materials, lighting, physics, and nuanced motion. Successfully bridging this semantic gap requires not merely object creation, but the algorithmic orchestration of interactions and behaviors over time, demanding computational power and sophisticated algorithms capable of resolving ambiguities inherent in natural language and ensuring a believable, consistent world. This pursuit isn’t simply about visual fidelity; it’s about imbuing generated scenes with a sense of life and responsiveness, enabling applications ranging from immersive virtual reality to automated content creation and advanced robotics.
Conventional techniques in 4D scene generation face considerable difficulty when attempting to synthesize complex, dynamic environments from textual inputs. A primary challenge lies in multi-scale entanglement – the intricate relationships between objects at varying sizes and distances, and how their interactions unfold over time. Existing systems often treat these elements in isolation, resulting in scenes that lack cohesive behavior. Simultaneously, ensuring physical plausibility – that generated objects adhere to the laws of physics regarding gravity, collision, and material properties – proves computationally expensive. These methods frequently produce visually appealing but ultimately unrealistic simulations, where objects might float, intersect unrealistically, or exhibit impossible motions, hindering their utility in applications demanding genuine physical accuracy.
Current methods for generating 4D scenes from textual inputs frequently encounter a trade-off between visual fidelity, computational cost, and physical accuracy. While some approaches prioritize generating highly detailed environments, they often demand substantial processing power and time, hindering real-time applications or large-scale simulations. Conversely, techniques focused on efficiency may sacrifice nuanced details and struggle to produce scenes that convincingly adhere to the laws of physics – leading to unnatural object interactions or visually implausible arrangements. This limitation stems from the difficulty in simultaneously modeling both the intricate relationships between objects at various scales and ensuring that the generated scene behaves realistically under simulated forces, presenting a core challenge in the field of procedural content generation and virtual world creation.
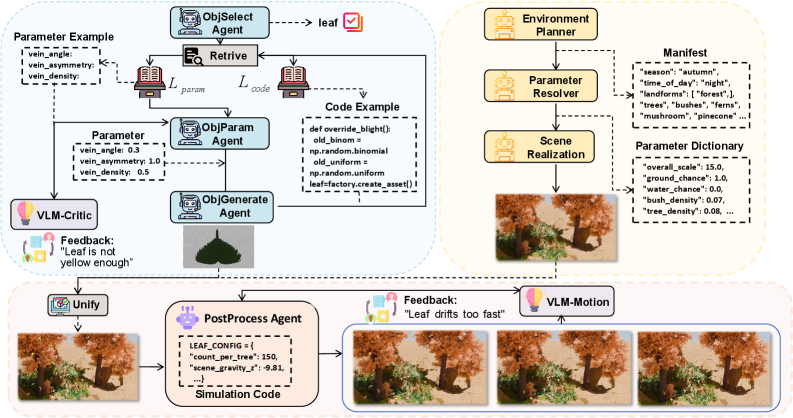
Deconstructing Complexity: A Dual-Stream Architecture for Scene Generation
Code2Worlds utilizes a Dual-Stream Architecture to mitigate the complexities arising from multi-scale entanglement inherent in 3D world generation. This architecture functionally separates the generation of individual objects from the broader environmental context. By decoupling these processes, the system avoids issues where modifications to one scale – for example, altering an object’s size – necessitate recalculations across all scales of the scene. This separation enables parallelized generation, where objects and the environment can be constructed independently and then integrated, leading to improved computational efficiency and scalability compared to monolithic generation approaches.
The Object Stream within Code2Worlds utilizes a two-stage process to translate natural language descriptions into 3D object parameters. Initially, a Reference Code Library is queried to retrieve pre-existing codes representing similar objects or object components. This retrieval is augmented by a parameter generation process, where the system refines or creates new parameters based on the input description and the retrieved codes. These parameters are then drawn from a Procedural Parameters Library, a database containing the rules and values defining object geometry, texture, and other visual characteristics, ultimately defining the final 3D object representation.
The Scene Stream within Code2Worlds functions as a high-level director for environmental composition. It establishes the global layout of the 3D scene, defining spatial relationships and overall context before object instantiation. This stream generates parameters controlling aspects such as terrain features, lighting conditions, and broad architectural arrangements. Critically, the Scene Stream provides essential contextual information to the Object Stream, dictating valid locations for object placement and defining potential interactions between objects and the environment. This includes specifying ground planes, navigable spaces, and areas suitable for specific object types, ensuring coherence and plausibility in the generated world.
The dual-stream architecture in Code2Worlds enables parallel generation of 3D objects and their environment, significantly improving computational efficiency. By separating object parameter generation from scene layout construction, these processes can be executed concurrently on independent processing units. This decoupling minimizes dependencies and reduces overall generation time compared to sequential methods. Furthermore, resource allocation is optimized; the Object Stream and Scene Stream can be assigned dedicated computational resources based on their specific requirements, preventing bottlenecks and maximizing throughput. This parallelization strategy is particularly advantageous for complex scenes with numerous objects, allowing for scalable and faster 3D world creation.

Refining Reality: Closed-Loop Refinement with a Vision-Language-Motion Critic
Code2Worlds employs a Closed-Loop Refinement process wherein generated 4D simulations are continuously evaluated by a Vision-Language-Motion (VLM)-Motion Critic. This critic functions as an automated assessment system, analyzing the simulated scene for inconsistencies between visual elements, language prompts, and expected physical behaviors. The VLM-Motion Critic doesn’t simply identify errors; it provides quantifiable feedback that is then fed back into the simulation generation pipeline. This creates an iterative loop where the simulation is refined based on the critic’s assessment, allowing for dynamic adjustments and improvements to ensure greater fidelity and realism in the final 4D output.
The VLM-Motion Critic functions as a dynamic plausibility evaluator within the Code2Worlds framework. It analyzes generated 4D scenes, specifically assessing the realism of object motion and interactions. This assessment is achieved by comparing generated behaviors against learned patterns of physically plausible dynamics. When unrealistic behaviors – such as objects passing through each other, unsupported levitation, or improbable trajectories – are detected, the VLM-Motion Critic generates feedback signals. These signals are then used to iteratively refine the simulation, adjusting parameters and re-generating movements until the scene adheres to expected physical principles and exhibits believable dynamics.
Dynamic Effects Self-Reflection is a refinement process wherein the VLM-Motion Critic analyzes generated 4D simulations and identifies inconsistencies in dynamic effects – such as object collisions, fluid behavior, or rigid body interactions. This analysis isn’t limited to simply detecting errors; the VLM-Motion Critic provides specific feedback used to iteratively adjust simulation parameters. These adjustments focus on improving both the physical accuracy of the simulation – ensuring adherence to physics principles – and the resulting visual fidelity, meaning the realism and believability of the rendered effects. The process continues until the simulation meets predefined plausibility thresholds, resulting in a higher-quality, physically consistent 4D scene.
The iterative refinement process within Code2Worlds demonstrably improves the realism of generated 4D scenes through repeated evaluation and correction. Each iteration utilizes the VLM-Motion Critic to assess dynamic plausibility, identifying inconsistencies with expected physical behavior. These identified inconsistencies are then fed back into the simulation generation process, prompting adjustments to the scene’s parameters. This cycle of assessment and adjustment continues until the VLM-Motion Critic determines the simulation meets predefined realism criteria, resulting in a 4D scene exhibiting improved physical accuracy and visual fidelity compared to initial outputs.
Validating Progress: Measuring Realism and Complexity with Code4D
Code2Worlds underwent validation through the Code4D Benchmark, a demanding evaluation specifically designed to assess the capabilities of systems generating dynamic, four-dimensional scenes. This benchmark isn’t merely a test of visual fidelity, but a comprehensive challenge encompassing both the complexity of generated environments and their temporal consistency. The Code4D Benchmark pushes generative models to create scenes with interacting objects and plausible physical behaviors over time, requiring a nuanced understanding of spatial relationships and dynamic simulation. By utilizing this rigorous testing ground, the framework’s ability to produce realistic and complex 4D scenes was systematically assessed, providing a quantifiable measure of its performance against existing state-of-the-art methods in procedural content generation.
The realism and intricacy of scenes generated by the framework underwent thorough evaluation utilizing a suite of quantitative metrics, including Richness, Hierarchical Relationship Score (HRS), and Scene Graph Similarity (SGS). Crucially, assessment wasn’t limited to algorithmic scoring; the advanced capabilities of GPT-4o were leveraged to provide nuanced judgements on both the complexity of the generated environments and their adherence to visual-physical plausibility. This hybrid approach allowed for a more holistic understanding of scene quality, moving beyond simple geometric accuracy to encompass a degree of ‘believability’ in the simulated world – ensuring the scenes weren’t merely detailed, but also internally consistent and representative of real-world physics and spatial arrangements.
Rigorous evaluation using the Code4D benchmark reveals that this framework significantly advances the state-of-the-art in 4D scene generation. Quantitative analysis demonstrates a substantial 49% increase in scene Richness – the diversity and intricacy of generated environments – and a compelling 41% improvement in the Scene Geometry Score (SGS), which measures the geometric complexity and detail of the simulated worlds. These gains indicate a capacity to create far more elaborate and visually engaging scenes compared to existing methodologies, establishing a new benchmark for realism and complexity in procedural content generation and simulation.
The generated simulations distinguish themselves through a remarkably low Physics Failure Rate of just 10%, signifying a substantial advancement in realistic dynamics. Unlike methods that produce static scenes, this framework consistently models interactions governed by physical laws, preventing common issues like objects falling through surfaces or exhibiting unnatural behaviors. This achievement isn’t merely about visual fidelity; it’s about creating environments where simulated objects behave as they would in the real world, a critical element for applications demanding accurate physical modeling, such as robotics training or advanced visual effects. The low failure rate confirms the robustness of the underlying physics engine and the effectiveness of the framework in translating code into believable, dynamically stable simulations.
The simulations produced by this framework demonstrate an exceptional level of temporal consistency, crucial for immersive and believable experiences. Evaluated metrics reveal a Motion Smoothness score of 0.9952, indicating virtually seamless transitions between frames and a highly fluid depiction of movement. Complementing this is a remarkably low Temporal Flickering rate of 0.9949, effectively minimizing distracting visual artifacts that often plague dynamically generated content. This combination of high smoothness and minimal flickering ensures that the generated scenes appear stable and realistic over time, distinguishing this approach from methods that prioritize static scene creation and potentially suffer from jarring inconsistencies during animation or interaction.
Envisioning the Future: Towards Interactive and AI-Driven Worlds
Code2Worlds now leverages the power of large language models (LLMs) to dramatically expand its procedural modeling capabilities. Previously requiring intricate scripting, the creation of complex 3D scenes is now achievable through simple natural language prompts. Users can describe desired environments – “a bustling medieval market square,” or “a serene alien forest” – and the system intelligently translates these descriptions into fully realized virtual worlds. This LLM-driven approach not only democratizes content creation, making it accessible to a wider audience, but also unlocks a new level of creative freedom, allowing for rapid prototyping and iterative design based on intuitive textual input. The system dynamically generates geometry, textures, and object arrangements, effectively bridging the gap between imagination and interactive virtual experiences.
Code2Worlds is poised to redefine interactive experiences through the creation of highly detailed and dynamic virtual simulations. By seamlessly translating algorithmic descriptions into fully realized 3D environments, the framework allows for the construction of game worlds and virtual reality applications with unprecedented levels of realism and complexity. These simulations aren’t merely static backdrops; they respond to user interaction and can be populated with intelligent agents, fostering a sense of presence and believability. This capability unlocks potential for training scenarios, collaborative design spaces, and deeply engaging entertainment, pushing the boundaries of what’s possible within immersive digital realms. The framework’s ability to rapidly prototype and iterate on environments promises to accelerate development cycles and democratize access to sophisticated virtual world building.
Code2Worlds is evolving beyond automated generation to embrace true AI-driven content creation, promising a future of deeply personalized virtual environments. The framework’s architecture is being extended to incorporate user feedback and preferences, enabling dynamic modification of generated worlds in real-time. This means users won’t simply receive a pre-built scene; they will actively shape it, guiding the AI to refine textures, adjust layouts, and even introduce entirely new elements based on individual tastes. Imagine a virtual cityscape that adapts its architectural style to reflect a user’s preferred era, or a fantastical forest that grows denser or sparser based on expressed desires – these are the possibilities unlocked by integrating AI-driven customization directly into the world-building process, effectively transforming passive observation into active co-creation.
The ultimate potential of Code2Worlds lies in democratizing the creation of virtual experiences. The framework aspires to move beyond simple scene generation, becoming a powerful tool that unlocks boundless creativity for designers, storytellers, and researchers. By lowering the barrier to entry for world-building, Code2Worlds anticipates a surge in immersive content, fostering entirely new forms of entertainment, education, and scientific visualization. This accessibility promises not just a proliferation of virtual environments, but also a diversification of perspectives shaping those worlds, leading to previously unimaginable interactive experiences and a truly limitless landscape of digital exploration.
The development of Code2Worlds exemplifies a shift towards systems that don’t merely represent the world, but actively simulate it. The framework’s closed-loop refinement process, crucial for ensuring temporal coherence in 4D scene generation, highlights the importance of iterative feedback. As Yann LeCun aptly stated, “Everything we do in AI is about building systems that can learn representations.” Code2Worlds embodies this principle; it learns to represent a world’s physics and dynamics through code, refining those representations based on simulated outcomes. This isn’t simply about generating visuals, but creating a functional, albeit virtual, reality governed by internally learned rules, mirroring a core tenet of understanding through patterned exploration.
Beyond the Simulated Horizon
The capacity to sculpt four-dimensional scenes from linguistic prompts, as demonstrated by Code2Worlds, is less a destination and more an invitation to consider the inherent ambiguities within both language and physics. The framework’s reliance on iterative refinement highlights a crucial point: the illusion of ‘plausibility’ is often achieved through successive approximations, not through fundamental understanding. One anticipates that future iterations will grapple less with generating scenes and more with validating them – establishing metrics not simply for physical correctness, but for narrative coherence and emergent behavior.
Current methodologies often prioritize visual fidelity. However, a truly robust system will need to address the problem of ‘hidden constraints’ – the unstated assumptions embedded within a prompt. A request for ‘a bustling city’ implies not just architecture, but also patterns of movement, economic systems, and even social dynamics. Successfully modeling these requires a move beyond purely geometric representations, toward systems that can reason about intention and consequence. It is worth noting that visual interpretation requires patience: quick conclusions can mask structural errors.
The eventual challenge, then, may not be creating ever-more-realistic simulations, but building systems capable of recognizing their own limitations – of articulating the boundaries between what is modeled and what remains fundamentally unknown. This framework offers a compelling initial step, but the true measure of its success will lie not in the scenes it generates, but in the questions it compels one to ask.
Original article: https://arxiv.org/pdf/2602.11757.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gear Defenders redeem codes and how to use them (April 2026)
- Annulus redeem codes and how to use them (April 2026)
- CookieRun: Kingdom x KPop Demon Hunters collab brings new HUNTR/X Cookies, story, mini-game, rewards, and more
- Robots Get a Finer Touch: Modeling Movement for Smarter Manipulation
- Last Furry: Survival redeem codes and how to use them (April 2026)
- 2 Episodes In, The Boys Season 5 Completes Butcher’s Transformation Into Homelander
- Total Football free codes and how to redeem them (March 2026)
- All Mobile Games (Android and iOS) releasing in April 2026
- All 6 Viltrumite Villains In Invincible Season 4
- Genshin Impact Nicole Pre-Farm Guide: Details about Ascension and Talent Materials
2026-02-15 16:08