Author: Denis Avetisyan
Researchers have developed a novel framework that allows vision-language models to actively explore environments and generate their own training data, leading to more robust visual understanding.

Active-Zero leverages self-play and auto-curriculum to enhance multimodal reasoning in open-world scenarios.
Existing self-play methods for vision-language models often rely on static datasets, hindering their ability to adapt and efficiently learn complex reasoning skills. To address this, we introduce ‘Active Zero: Self-Evolving Vision-Language Models through Active Environment Exploration’, a framework that enables agents to actively seek out and curate visual learning experiences. This approach, leveraging co-evolving Searcher, Questioner, and Solver agents, facilitates the autonomous construction of an auto-curriculum, resulting in significant improvements in both reasoning and general visual understanding-a [latex]5.7\%[/latex] and [latex]3.9\%[/latex] gain, respectively, across 12 benchmarks. Could active exploration be the key to unlocking truly scalable and adaptive intelligence in multimodal AI systems?
Beyond Surface Recognition: Unlocking True Visual Understanding
Despite remarkable advancements, contemporary vision-language models often falter when confronted with tasks demanding more than superficial pattern recognition. These models excel at identifying objects and associating them with corresponding text, but struggle with scenarios requiring sequential inference or an understanding of causal relationships. For example, a model might accurately label objects in a scene depicting a kitchen, but fail to deduce the next logical step in a cooking process, or understand why a particular object is being used. This limitation stems from their reliance on statistical correlations within massive datasets, rather than a genuine ability to reason about the underlying semantics of visual information; they essentially ‘memorize’ associations without grasping the principles governing them, hindering performance on tasks that require flexible application of knowledge to novel situations.
Despite the remarkable progress achieved by increasing the size of vision-language models, a critical impasse remains: simply adding more parameters doesn’t fundamentally alter how these models process information. Current architectures often excel at identifying surface-level correlations within datasets, effectively memorizing associations rather than developing genuine understanding. This limitation becomes acutely apparent when presented with scenarios demanding complex reasoning-tasks requiring the integration of visual details with contextual knowledge and the ability to infer relationships beyond those explicitly encoded in the training data. The issue isn’t a lack of data or computational power, but an inherent constraint in the models’ capacity to move beyond pattern recognition towards a more robust and flexible form of visual comprehension, suggesting that architectural innovation, not just scale, is the key to unlocking true intelligence.
Current approaches to vision-language model development often prioritize increasing model size and data volume, yet performance plateaus indicate a critical need to shift training paradigms. The focus must move beyond rote memorization of visual features and associated text, towards cultivating genuine reasoning capabilities. Innovative training strategies are required – ones that explicitly encourage the model to decompose complex visual scenes, infer relationships between objects, and draw logical conclusions based on observed evidence. This involves developing curricula that present increasingly challenging reasoning tasks, employing techniques like causal reasoning and counterfactual analysis, and designing reward functions that incentivize not just accurate answers, but also the process of logical deduction. Ultimately, progress hinges on building models that don’t simply recognize what is present in an image, but rather, understand why it is there and what might happen next.
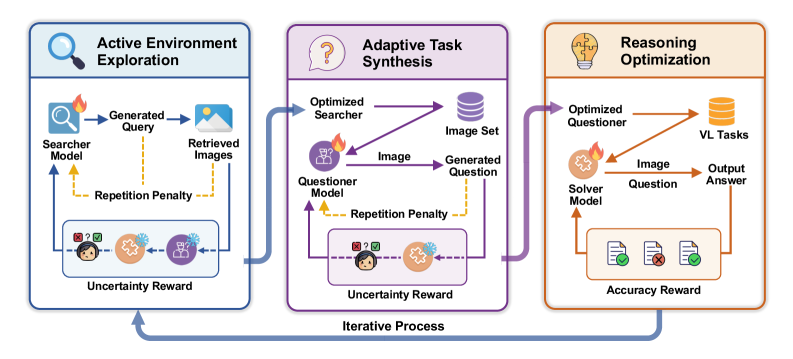
Active-Zero: A Framework for Self-Directed Learning
Active-Zero utilizes a self-play framework consisting of three interacting agents: the Searcher, Questioner, and Solver. The Searcher is responsible for sourcing visual data, which is then used by the Questioner to generate reasoning-based queries. These queries are presented to the Solver, which attempts to provide accurate answers. Critically, the performance of each agent directly influences the training of the others; the Questioner adapts its query difficulty based on the Solver’s success rate, and the Searcher modifies its image selection strategy to provide increasingly challenging, yet solvable, examples. This iterative process of challenge and refinement enables continuous, automated curriculum learning without the need for human-labeled data or pre-defined task difficulty levels.
The Active-Zero framework utilizes a three-agent system for iterative learning. The process begins with the Searcher agent, which retrieves images from a designated dataset. These images are then presented to the Questioner agent, responsible for generating reasoning questions specifically designed to test understanding of the visual content. Finally, the Solver agent attempts to answer the questions posed by the Questioner, providing a response that is subsequently evaluated to refine the system’s learning process. This sequential interaction-image retrieval, question formulation, and answer solving-forms the core of the framework’s operational cycle.
The Active-Zero framework dynamically adjusts the difficulty and content of training examples presented to the Solver agent. This is achieved through continuous interaction with the Questioner and Searcher; the Questioner generates questions specifically targeting areas where the Solver demonstrates weakness, as identified through its responses. The Searcher then retrieves images relevant to these targeted questions. This iterative process creates a curriculum that prioritizes the Solver’s current limitations, effectively focusing training efforts on the most impactful areas for improvement and facilitating accelerated learning compared to static or pre-defined curricula. The system doesn’t rely on human-labeled difficulty levels but instead adapts based on the Solver’s real-time performance.
Guiding the Search: A Reward System for Targeted Exploration
The Challenge Reward mechanism functions by assessing the Solver’s performance on a given image and assigning a higher reward value to images that elicit incorrect classifications. This is achieved through monitoring the Solver’s confidence in its predictions; lower confidence, or incorrect classifications, trigger an increased reward for the Searcher, incentivizing the retrieval of visually challenging examples. This process actively directs the Searcher towards images where the Solver demonstrates deficiencies, facilitating targeted learning and improving overall robustness by exposing weaknesses in the Solver’s perceptual capabilities. The magnitude of the reward is directly proportional to the degree of the Solver’s failure, ensuring a focused and efficient exploration of the image space.
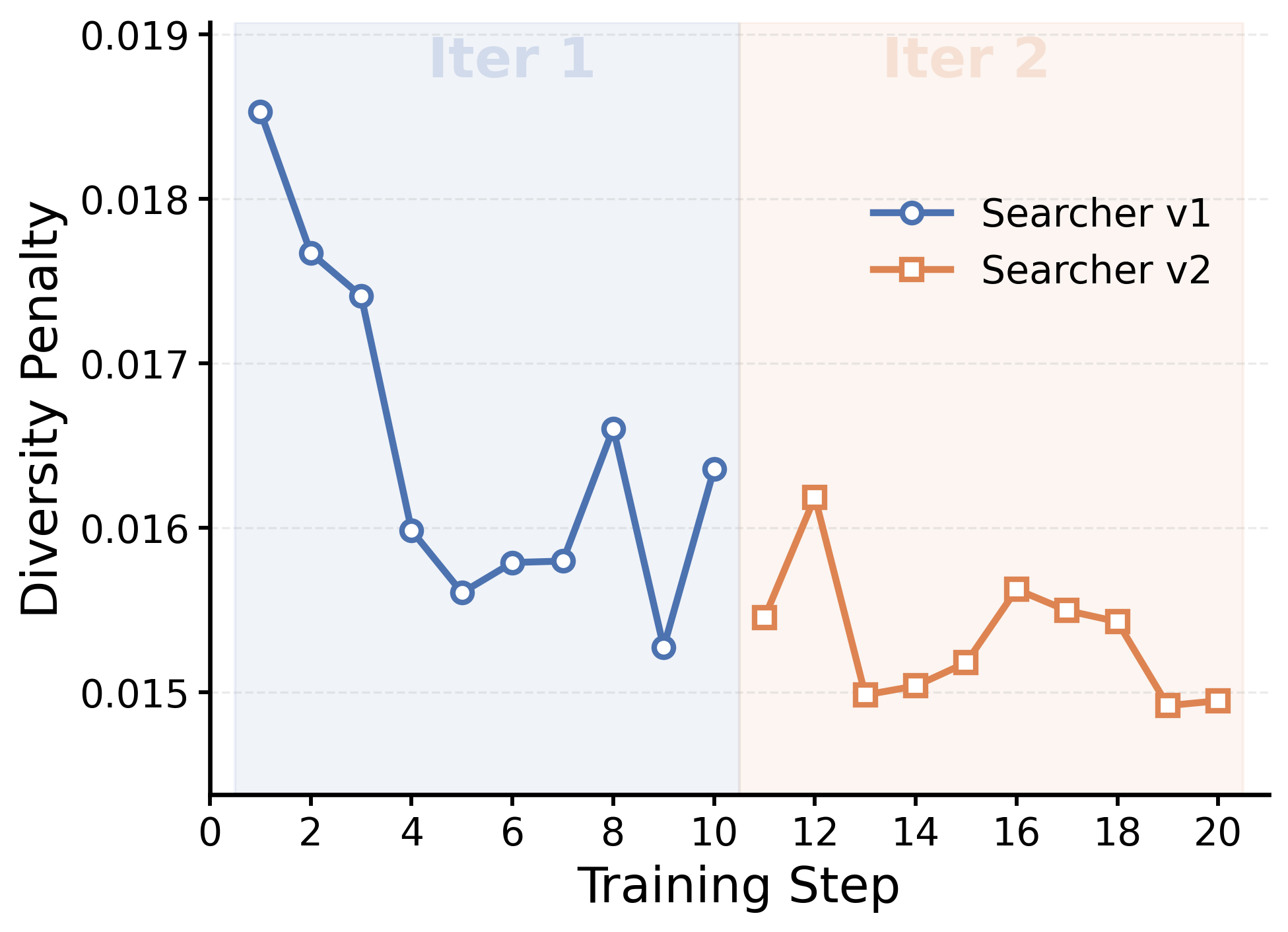
The system employs both Repetition Penalty and Visual Redundancy Control to optimize the image retrieval process. Repetition Penalty discourages the Searcher from repeatedly presenting images similar to those already retrieved, based on feature similarity metrics. Visual Redundancy Control further refines this by actively identifying and filtering images that offer minimal new visual information, as determined by a perceptual image hash. These mechanisms work in tandem to ensure the Solver receives a diverse and informative set of images, maximizing the efficiency of the learning process and preventing the Solver from being exposed to redundant data.
Domain Conditioning enhances the Solver’s learning process by directing the Searcher to retrieve images from specifically defined visual domains. This is achieved through the application of domain-specific priors during the search phase, effectively biasing the image selection towards areas where the Solver exhibits limited knowledge. By focusing exploration on these diverse domains – such as textures, objects, or scenes – the system actively expands the Solver’s training data beyond its initial scope, improving generalization and overall performance across a wider range of visual inputs. This targeted approach contrasts with random exploration, enabling a more efficient and focused broadening of the Solver’s knowledge base.
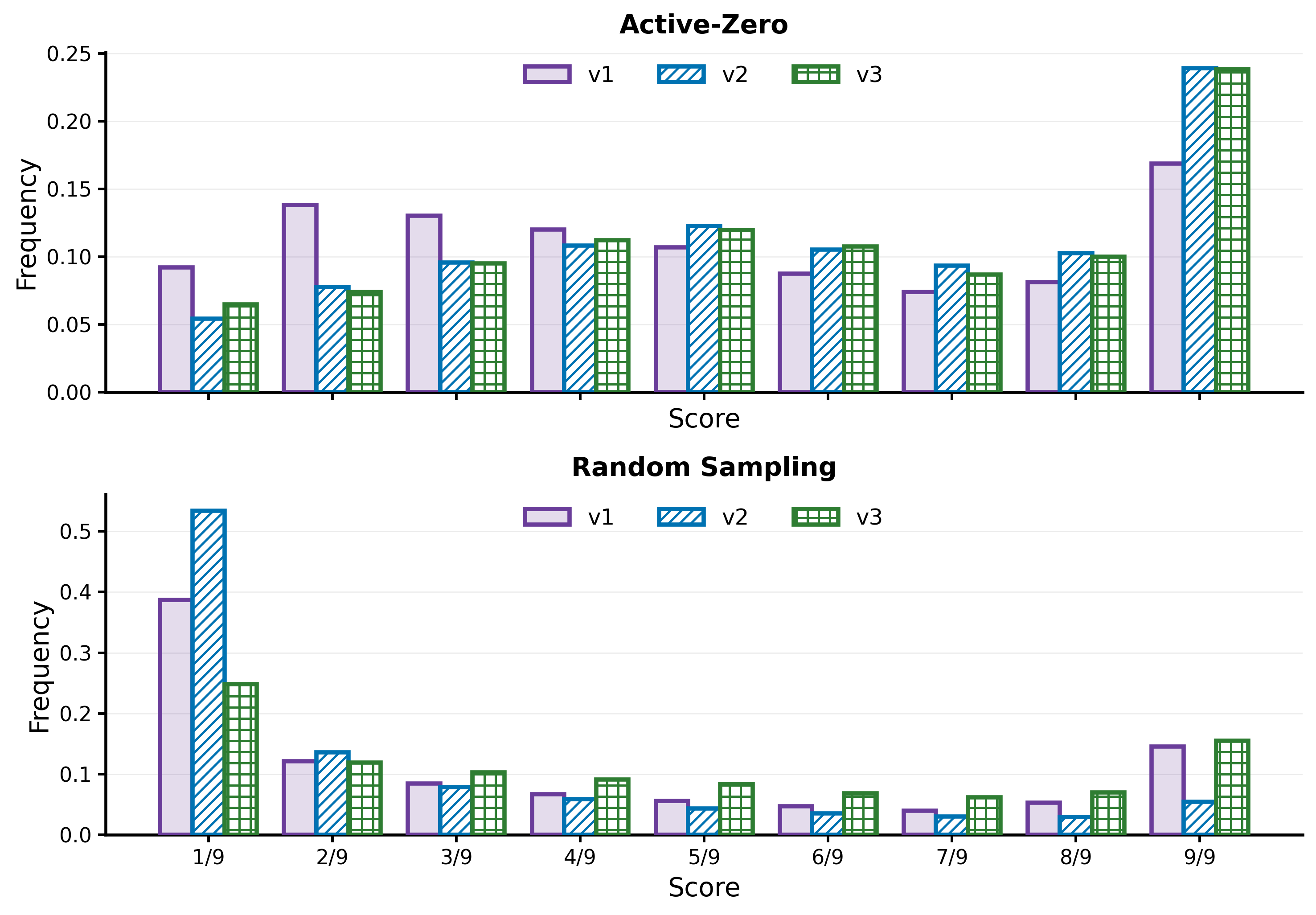
![Active-Zero v2, particularly when incorporating domain conditioning, demonstrates a more focused category distribution of retrieved images compared to v1, aligning retrieval with the source datasets [latex]\mathcal{D}_{env}[/latex].](https://arxiv.org/html/2602.11241v1/figs/image_dist.png)
Demonstrating Robust Reasoning Across Diverse Benchmarks
Active-Zero’s capabilities were rigorously tested across a diverse suite of benchmarks designed to assess visual reasoning and problem-solving skills. Evaluations spanned several challenging datasets, including MathVista, WeMath, LogicVista, DynaMath, VisNum, RealWorldQA, MMStar, and MMMU-Pro, each presenting unique demands on a model’s ability to interpret visual information and apply logical deduction. Consistent performance gains were observed across these benchmarks, indicating that Active-Zero not only achieves competitive results on individual tasks but also exhibits a generalizable capacity for robust reasoning – surpassing the performance of existing methods in a variety of contexts and demonstrating its potential for broader application in complex visual intelligence systems.
Evaluations demonstrate that Active-Zero consistently enhances performance on the Qwen2.5-VL instruction-tuned visual language models. Specifically, the model achieved an average accuracy improvement of 2.92% when tested on the Qwen2.5-VL-7B-Instruct benchmark, and further refined this success with a 3.99% average accuracy increase on the Qwen2.5-VL-3B-Instruct benchmark. These gains suggest Active-Zero effectively leverages visual information to improve reasoning capabilities within these models, showcasing its potential for broad application in visual language understanding tasks.
Evaluations revealed substantial performance gains for the model on benchmarks demanding complex reasoning skills; notably, a 5.13% improvement was registered on LogicVista and a 5.12% improvement on WeMath. These results, achieved utilizing the Qwen2.5-VL-7B-Instruct model, highlight the system’s enhanced capacity to solve problems requiring logical deduction and mathematical understanding. The consistent gains across both benchmarks suggest the model isn’t merely recognizing patterns, but actively applying reasoning processes to arrive at correct answers, demonstrating a robust capability for tackling diverse, challenging visual reasoning tasks.
Evaluations reveal that Active-Zero consistently enhances performance across a suite of general Visual Language Model (VLM) benchmarks, achieving an average accuracy improvement of 2.26% when paired with the Qwen2.5-VL-7B-Instruct model. This improvement signifies a substantial step forward in visual reasoning capabilities, demonstrating the model’s ability to more effectively interpret and process complex visual information. The observed gains aren’t limited to specific datasets; rather, they represent a broad-based enhancement in accuracy, suggesting a robust and adaptable approach to visual problem-solving. Such consistent gains across diverse benchmarks underscore Active-Zero’s potential for real-world applications requiring reliable and accurate visual understanding.
The consistent performance gains exhibited by Active-Zero across diverse visual reasoning benchmarks suggest a capability extending beyond rote memorization. Rather than simply recalling previously seen solutions, the model appears to be developing a genuine capacity for interpreting and processing visual information to arrive at novel answers. Improvements on challenging datasets like LogicVista and WeMath, which require complex deductive reasoning, support this conclusion; the model isn’t merely identifying patterns but is actively engaging with the underlying logic of the problems presented. This ability to generalize and apply reasoning skills to unseen scenarios marks a significant step towards more robust and adaptable visual intelligence, indicating Active-Zero’s potential to tackle complex real-world challenges that demand true understanding, not just pattern recognition.
The pursuit of Active-Zero exemplifies a dedication to elegant system design, mirroring the belief that true intelligence arises from harmonious interaction with the world. This research isn’t merely about improving vision-language models; it’s about fostering a dynamic interplay between exploration and learning, allowing the model to organically build its understanding. As Fei-Fei Li once stated, “AI is not just about building machines that think, but about building machines that care.” The self-play framework, where the model actively constructs its curriculum through environmental engagement, embodies this ‘caring’ – a proactive approach to knowledge acquisition that moves beyond passive data reception. This aligns perfectly with the core concept of auto-curriculum, creating a cohesive system where form – the active exploration – and function – the improved reasoning – are inextricably linked.
The Horizon Beckons
The pursuit of genuine intelligence in machines often fixates on passive reception – a relentless ingestion of labeled data. This work, with its emphasis on active exploration, suggests a different path. Active-Zero doesn’t merely learn from the world; it tentatively, and perhaps clumsily, probes it. This is a subtle, but crucial, distinction. The elegance lies not simply in achieving better performance on benchmarks, but in framing the learning process itself as an ongoing dialogue with the environment. The question, of course, is whether this approach can scale beyond carefully constructed simulations.
Current limitations center on the brittleness of self-play. The ‘curriculum’ constructed by the agent, while demonstrably effective, remains tethered to the initial conditions of the environment. A truly robust system must exhibit a capacity for transfer – to adapt its exploratory strategies to novel, unpredictable contexts. One wonders if a degree of ‘forgetting’-a willingness to discard previously successful tactics-might be a necessary component of true general intelligence.
The future likely involves hybrid approaches. Combining the benefits of active learning with the stability of supervised pre-training could yield systems that are both adaptable and reliable. Perhaps the most intriguing challenge is to imbue these agents with a sense of ‘aesthetic’ – a preference for solutions that are not merely functional, but also, in some elusive sense, beautiful. For it is in such simplicity and clarity that the deepest understanding resides.
Original article: https://arxiv.org/pdf/2602.11241.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-15 09:31