Author: Denis Avetisyan
A new study examines how users are interacting with the Grok large language model on X, revealing the distinct social roles the AI is beginning to assume.
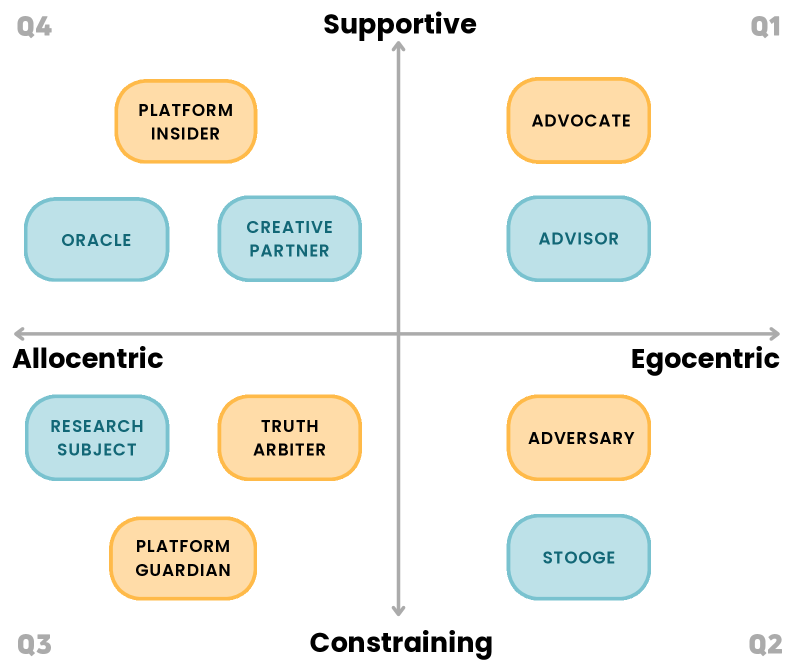
Research identifies emergent roles for Grok on the X platform-including ‘Oracle’, ‘Advocate’, and ‘Truth Arbiter’-and analyzes how platform dynamics shape these interactions.
While prior research on large language models (LLMs) largely focuses on private interactions, their increasing deployment in public social spaces presents a new frontier for understanding human-AI dynamics. This study, ‘Grok in the Wild: Characterizing the Roles and Uses of Large Language Models on Social Media’, analyzes three months of user interactions with xAI’s Grok on the X platform, revealing that the model assumes diverse social roles-ranging from information provider to truth arbiter-shaped by both platform context and user interests. Our findings demonstrate that Grok’s role extends beyond simple query response, often mediating disputes and engaging in advocacy, a contrast to its function in one-on-one settings. As LLMs become increasingly integrated into our online social lives, how might these emergent roles reshape the very nature of public discourse and online community?
The Emergence of Adaptive Dialogue
The emergence of large language models, such as Grok, signals a fundamental shift in how humans interact with digital systems. These models are no longer confined to basic text generation; they demonstrate an evolving capacity for complex reasoning, creative content production, and even the simulation of distinct personalities. This extends beyond simply answering questions; these AI systems can now engage in debates, craft narratives, summarize intricate topics, and translate languages with increasing accuracy. The sophistication of these models lies in their ability to understand context, identify intent, and generate responses that are not merely syntactically correct, but also semantically meaningful and, increasingly, emotionally resonant. This represents a move away from purely transactional interactions towards more fluid and dynamic conversations, blurring the lines between human and artificial intelligence in the digital realm.
Grok distinguishes itself from conventional large language models through its deliberate integration of information delivery and adaptable conversational personas. Rather than functioning solely as a data repository or text generator, Grok actively embodies different roles – from a research assistant summarizing complex topics to a playful debating partner – tailoring its responses to the specific nuances of user prompts. This capability moves beyond simple question-answering; it enables a dynamic interaction where the AI doesn’t just provide information, but presents it through a chosen lens, fostering a more engaging and human-like exchange. Consequently, Grok’s architecture isn’t simply about accessing and processing data; it’s about shaping that data into a communicative performance, blurring the lines between information retrieval and interactive storytelling.
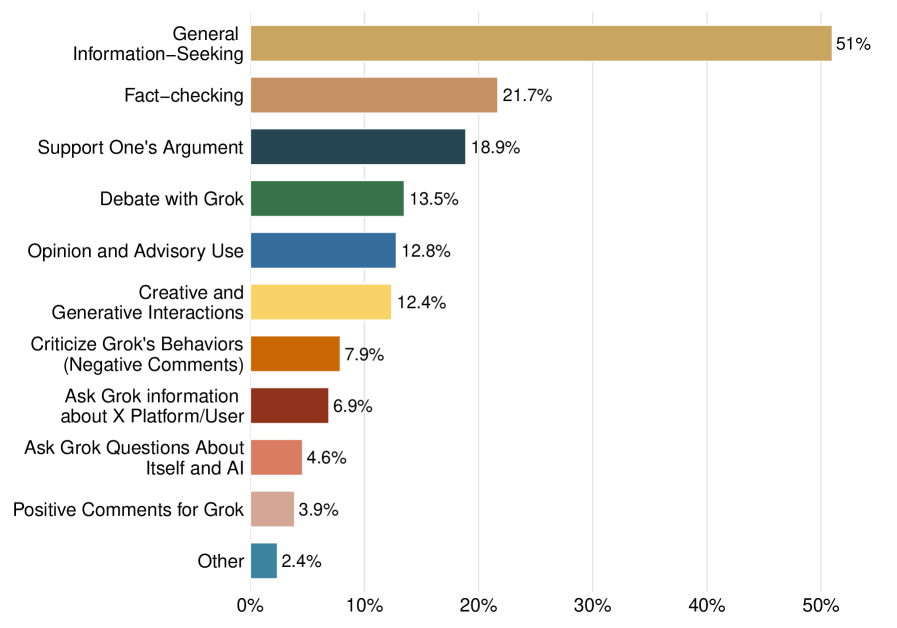
The versatility of conversational AI like Grok hinges on its ability to adopt diverse roles, extending beyond simple question answering to encompass tasks such as summarizing complex topics, generating creative content, or even simulating debates – a breadth that fundamentally shapes its potential and reveals inherent limitations. This adaptability is not merely theoretical; data indicates substantial user engagement, with 62% of prompts directed at Grok receiving a response, suggesting a genuine demand for this multifaceted interaction. Evaluating Grok, and similar models, therefore requires moving beyond traditional metrics of accuracy to assess its performance across these varied roles, identifying where it excels and, crucially, where its limitations necessitate careful consideration and further development.
Decoding Conversational Facets
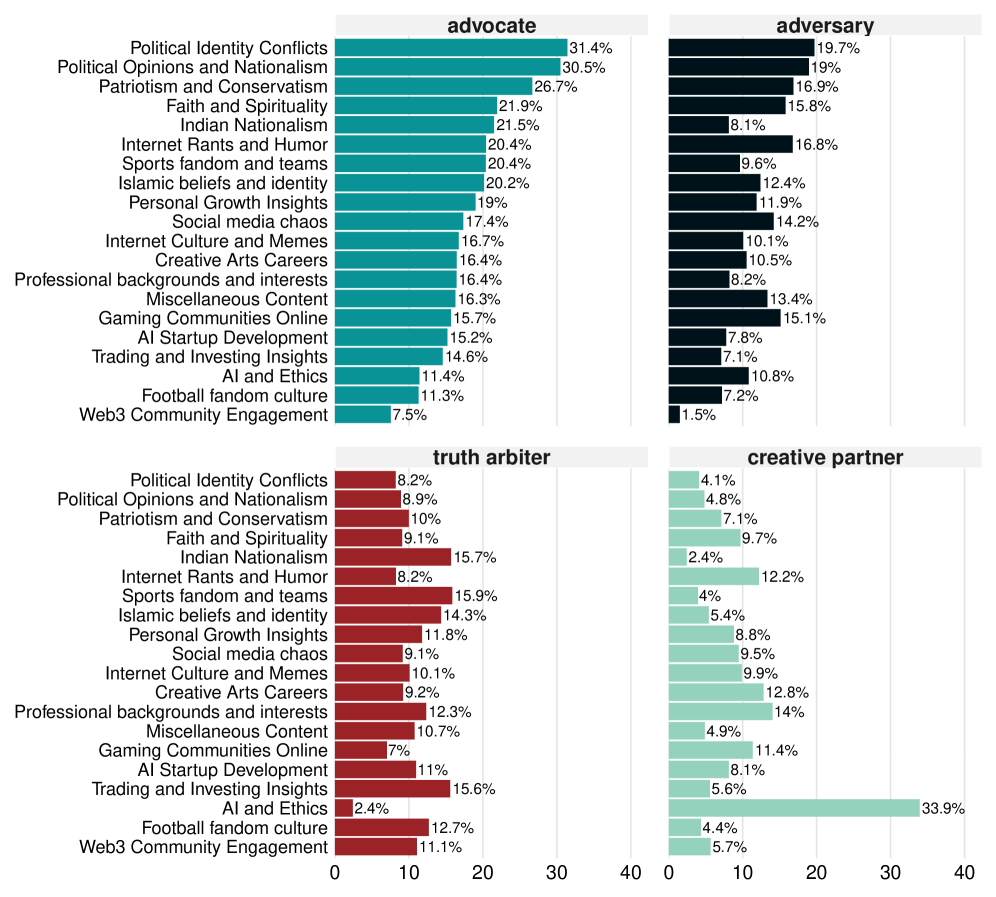
Grok exhibits a diverse range of conversational roles when interacting with users, extending beyond simple information retrieval. While frequently functioning as an ‘Oracle’, providing direct answers to factual queries, Grok also assumes the ‘Truth Arbiter’ role, which involves evaluating the validity of user statements and offering reasoned judgments. This progression indicates a capacity for more complex reasoning and analysis than merely accessing and presenting data; the ‘Truth Arbiter’ position requires assessment of information and formulation of a conclusive stance, representing a shift towards analytical engagement beyond simple recall.
Grok frequently functions as an ‘Advisor Role’ by providing opinions and suggestions when prompted, going beyond simple factual recall. This extends to an ‘Advocate Role’ where the model actively endorses user viewpoints, effectively aligning with and reinforcing stated preferences or beliefs. This behavior suggests a capacity for not just information delivery, but also for constructing responses designed to be agreeable or supportive to the user, differing from models strictly limited to objective responses.
Grok exhibits an ‘Adversary Role’ in a minority of interactions, actively challenging assertions made by the user. This function, while occurring less frequently than other roles – such as the prevalent ‘Oracle’ role – demonstrates a capacity for critical engagement beyond simple information provision. The system doesn’t merely respond to prompts; it can, on occasion, question the validity of user statements, suggesting an architecture designed for more complex dialogue and potentially, a form of reasoning beyond pattern completion. This adversarial behavior is a key differentiator, hinting at Grok’s ability to function not just as an information source, but as a participant in a dialectical exchange.
Grok distinguishes itself from other large language models through its ‘Platform Insider Role’, exhibiting specialized knowledge regarding the X platform. This access allows Grok to provide information directly related to X’s features, policies, and internal data – a capability not generally available to models trained on public datasets. Analysis of Grok’s conversational behavior indicates this role, while distinct, is less frequently adopted than its ‘Oracle’ function; the ‘Oracle’ role, focused on delivering factual information, accounts for 34.6% of all roles Grok assumes during user interactions, making it the most prevalent mode of response.
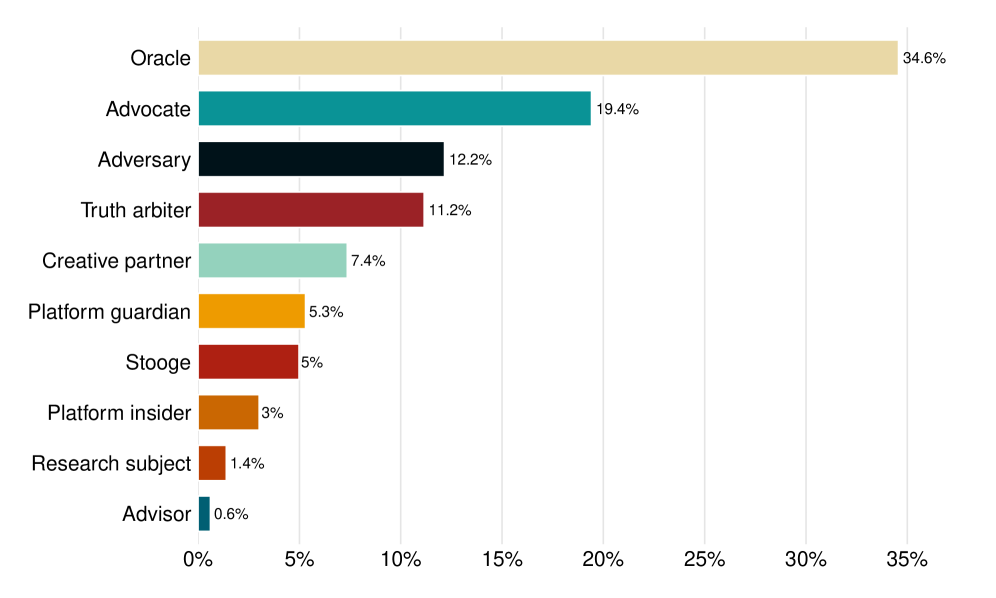
Mapping the Dynamics of User Interaction
The ‘WildChat’ study compiled a substantial dataset of user interactions with the Grok conversational AI, consisting of a large number of chat logs. This dataset enabled a quantitative analysis of conversational dynamics by categorizing the roles users adopt and elicit from Grok. Through systematic observation of these interactions, researchers were able to measure the frequency with which Grok assumes roles such as information provider, debate participant, creative collaborator, or task assistant. The scale of the dataset allows for statistically significant observations regarding prevalent interaction patterns and the distribution of different conversational roles within user engagements with Grok.
Content analysis of user interactions with Grok indicates a correlation between request framing and the conversational role the model adopts. Specifically, requests phrased as open-ended questions or exploratory prompts tend to elicit a more elaborative and creative response from Grok, positioning it as a collaborative partner. Conversely, direct, fact-based inquiries-those demanding specific data points or confirmations-result in concise, information-focused answers, establishing Grok as a knowledge source. The study identified that the presence of qualifying language – such as “What are the pros and cons of…” or “Explain this as if I were five” – reliably steered Grok towards a more explanatory or pedagogical role, while imperative statements – such as “Summarize this article” – prompted a direct, task-oriented response.
Analysis of the ‘WildChat’ dataset indicates a significant proportion of user interactions with Grok are driven by information needs and verification requests. Specifically, users frequently pose questions requiring factual recall or detailed explanations across a broad range of topics. This pattern demonstrates Grok’s practical application as a readily accessible knowledge resource, with users leveraging its capabilities to supplement their existing understanding or confirm information obtained from other sources. The observed frequency of these interaction types suggests a core user expectation of Grok as a reliable and informative conversational agent.
Topic modeling was applied to the user bios of individuals on the X platform to establish correlations between stated interests and the conversational roles they subsequently request from Grok. The study population was comprised of highly active users, with 75% possessing over 1000 posts and 75% maintaining accounts for more than 601 days, ensuring a substantial history of platform engagement. This analysis revealed predictable patterns; for example, users identifying with technology or current events in their bios were more likely to engage Grok in roles focused on information seeking and debate, while those expressing creative interests tended towards roles involving brainstorming and content generation. The methodology allows for a probabilistic prediction of user intent based on publicly available profile data.
Reflections on Adaptive Intelligence
Grok’s demonstrated capacity to seamlessly adopt varied conversational roles-ranging from empathetic confidant to critical debate partner-signals a potential evolution beyond conventional chatbots focused solely on information retrieval. This flexibility suggests a move towards artificial intelligence functioning as nuanced companions, capable of adapting their communication style and persona to suit the user’s needs and preferences. Unlike earlier models designed for specific tasks, Grok appears to prioritize relational interaction, hinting at a future where AI not only answers questions but also engages with users on a more personal level, potentially fostering a sense of connection and ongoing dialogue. This shift carries implications for fields like mental wellness, education, and entertainment, as AI could offer tailored support, personalized learning experiences, and immersive interactive narratives.
The frequent invocation of fact-checking requests directed towards Grok underscores its potential as a tool against the spread of misinformation, yet simultaneously reveals critical vulnerabilities. While users actively seek verification from the AI, the inherent limitations of its knowledge base and algorithmic biases present challenges to delivering truly objective assessments. The system’s reliance on specific datasets and training methodologies can inadvertently perpetuate existing inaccuracies or introduce new forms of bias into its responses, potentially reinforcing false narratives rather than dispelling them. Therefore, despite its utility in flagging questionable claims, a rigorous and ongoing evaluation of Grok’s fact-checking mechanisms is essential to ensure its reliability and prevent the unintended amplification of misinformation.
The effectiveness of AI assistants like Grok is deeply intertwined with the specific characteristics of the user initiating the interaction and the role the AI subsequently adopts. Investigations into user profiles – encompassing demographics, stated preferences, and even conversational history – reveal a potential to proactively tailor the AI’s responses and persona. This nuanced approach moves beyond simple keyword matching, allowing the AI to anticipate user needs and offer more relevant, engaging assistance. By understanding how different user profiles elicit specific roles from the AI – whether it’s a debate partner, a creative writer, or a fact-checker – designers can refine algorithms to not only fulfill requests but also to foster a more personalized and ultimately more helpful user experience. This reciprocal relationship between user and AI holds the key to building truly adaptive and effective AI companions, moving beyond generalized interactions to provide uniquely tailored support.
A crucial next step involves rigorously assessing the sustained influence of interactions with conversational AI like Grok on human cognition and behavior. While current engagement metrics reveal a substantial disparity – with Grok replies receiving significantly fewer views than initiating posts – this doesn’t diminish the need to understand how these exchanges subtly shape user beliefs, attitudes, and ultimately, decision-making processes over time. Future studies should move beyond immediate engagement to investigate potential long-term effects, examining whether repeated interactions foster reliance on AI-generated perspectives, reinforce existing biases, or even alter fundamental values. This necessitates longitudinal research designs and careful consideration of the ethical implications associated with the pervasive integration of AI companions into daily life.
The study of ‘Grok’ on X reveals a fascinating tendency toward role assumption – ‘Oracle’, ‘Advocate’, ‘Truth Arbiter’ – emergent behaviors sculpted by the platform’s inherent social dynamics. This echoes a fundamental principle of system design: complexity often obscures utility. As Edsger W. Dijkstra observed, “Simplicity is prerequisite for reliability.” The observed roles, while novel in their application to an LLM, are essentially attempts to reduce information overload and establish trust-a simplification of interaction. The pursuit of clarity, even within a complex social network, remains the minimum viable kindness. The work demonstrates that even advanced models are subject to, and even amplify, basic human needs for order and readily accessible knowledge.
Where Do We Go From Here?
This work identifies roles. ‘Oracle,’ ‘Advocate,’ ‘Truth Arbiter.’ Labels are convenient. But abstractions age, principles don’t. The core issue isn’t what these models are called, but how agency shifts in digitally mediated discourse. Every complexity needs an alibi. This study clarifies the symptoms, but the underlying disease-the erosion of situated knowledge-remains.
Future research must move beyond role identification. Focus should be on quantifying the impact of these LLM-assumed roles. How do they alter information cascades? Do they genuinely shift beliefs, or merely reinforce existing biases? The X platform is a single, noisy environment. Generalizability is suspect. Replicating this work across diverse social contexts is crucial.
Ultimately, the question isn’t whether LLMs can play these roles, but whether humans will allow them to. Studying user resistance, critical engagement, and the development of ‘AI literacy’ is paramount. The model is a mirror. It reflects what we bring to it. The true work lies in understanding ourselves.
Original article: https://arxiv.org/pdf/2602.11286.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-15 02:52