Author: Denis Avetisyan
New research details a framework for automatically optimizing the workflows and instructions of AI agents powered by large language models.
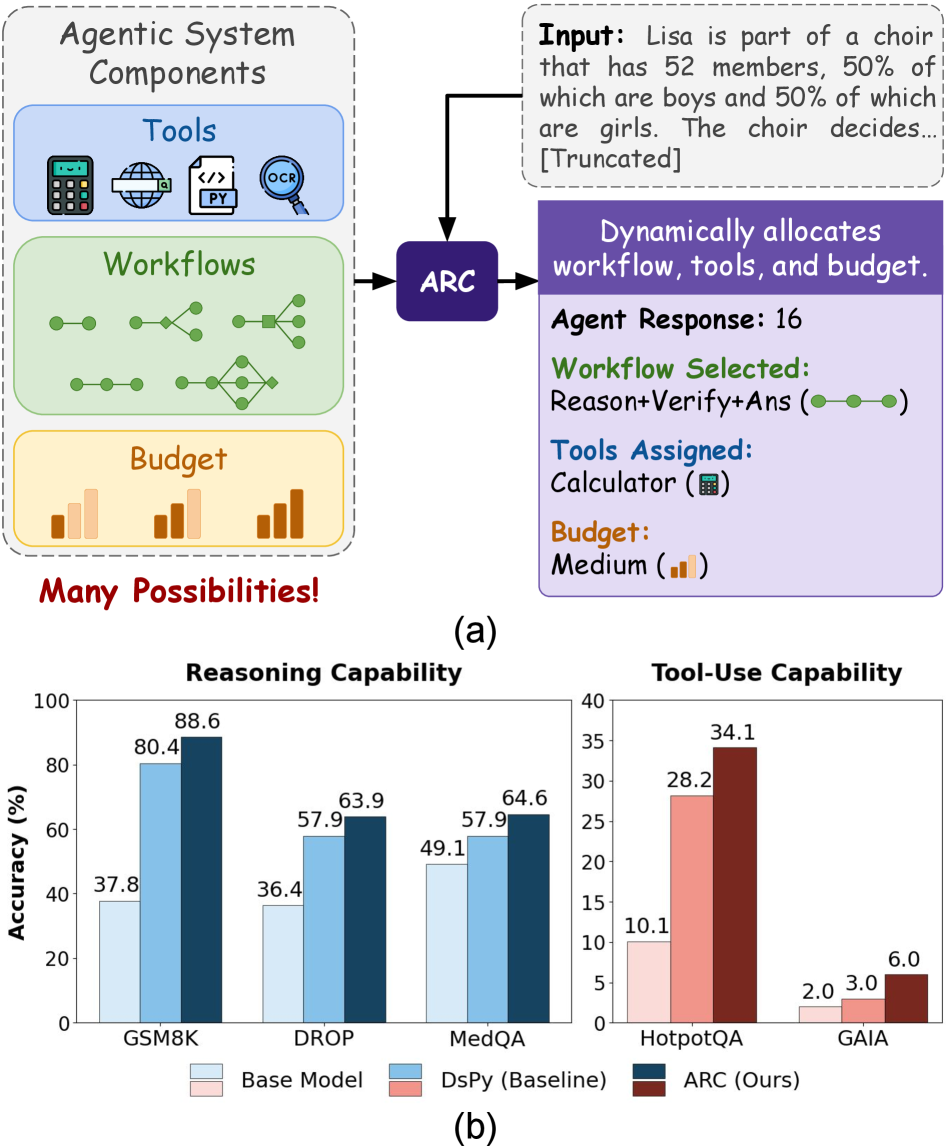
This paper introduces ARC, a hierarchical reinforcement learning system that adaptively configures LLM-based agent systems to maximize performance and resource efficiency.
Despite the increasing sophistication of large language model (LLM)-based agent systems, configuring their workflows, tools, and prompts remains a largely manual and inflexible process. This paper, ‘Learning to Configure Agentic AI Systems’, addresses this limitation by framing agent configuration as a query-wise decision problem and introducing ARC, a hierarchical reinforcement learning framework that dynamically adapts these configurations. ARC demonstrably outperforms hand-designed baselines, achieving significant gains in both task accuracy and resource efficiency across diverse benchmarks. Could learned, adaptive configurations unlock a new paradigm for building truly intelligent and cost-effective agentic systems?
The Fragility of Static Thought
Large language models, despite their impressive capabilities, frequently encounter difficulties when tasked with complex queries demanding multi-step reasoning and adaptive problem-solving. These models often excel at pattern recognition and information retrieval, but struggle when a question necessitates breaking down the problem into sequential steps, maintaining context across those steps, and adjusting the reasoning pathway based on intermediate results. This limitation stems from the inherent architecture of many LLMs, which prioritizes predicting the next token in a sequence rather than actively constructing a dynamic reasoning process. Consequently, queries requiring nuanced inference, hypothetical reasoning, or the application of common sense knowledge often expose the fragility of these models, revealing a gap between statistical language proficiency and genuine cognitive flexibility.
The limitations of current large language models become acutely apparent when faced with tasks demanding adaptability. While meticulously crafted prompts and pre-defined reasoning workflows can yield impressive results on familiar queries, their rigidity often leads to failure when confronted with even slight variations or novel situations. These static approaches struggle to generalize because they lack the capacity to dynamically adjust the reasoning process itself. A prompt optimized for one specific phrasing or context may completely falter with a minor semantic shift, highlighting a critical need for systems that can interpret the intent behind a query and construct a tailored reasoning path – rather than relying on pre-programmed responses to anticipated inputs. This inflexibility ultimately constrains the potential of these models, preventing them from truly exhibiting intelligent problem-solving capabilities.
The inherent rigidity of current large language model (LLM) applications ultimately limits their transformative potential. While LLMs demonstrate remarkable abilities in pattern recognition and text generation, their reliance on pre-defined reasoning paths and static prompts creates a bottleneck when faced with nuanced or evolving problems. This inflexibility isn’t merely a matter of accuracy; it represents a failure to fully utilize the vast knowledge encoded within these models. Complex queries demanding adaptable strategies – those requiring LLMs to dynamically assess information, adjust their approach mid-process, and synthesize novel solutions – often exceed the capabilities of systems constrained by inflexible architectures. Consequently, the true power of LLMs remains largely untapped, hindering advancements in fields requiring sophisticated, context-aware reasoning.
The inherent difficulty in achieving robust large language model performance stems from the need to dynamically tailor the reasoning process to each unique query. Current approaches often rely on pre-defined reasoning paths or static prompt engineering, which struggle when confronted with novel or complex inputs demanding adaptive thought. Effectively, the model must not simply answer a question, but actively determine how to approach it – selecting, sequencing, and applying reasoning steps appropriate to the specific information requested. This requires a shift from treating reasoning as a fixed algorithm to viewing it as a configurable process, allowing the model to analyze the query’s structure and complexity, then construct a bespoke reasoning strategy on the fly, ultimately unlocking more flexible and reliable problem-solving capabilities.
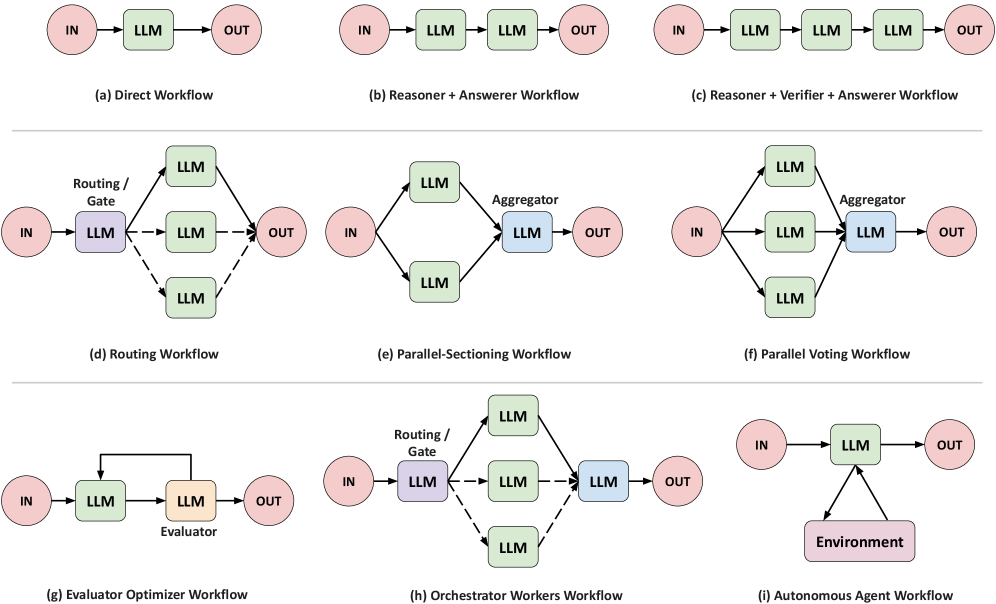
Query-Adaptive Configuration: A System That Evolves
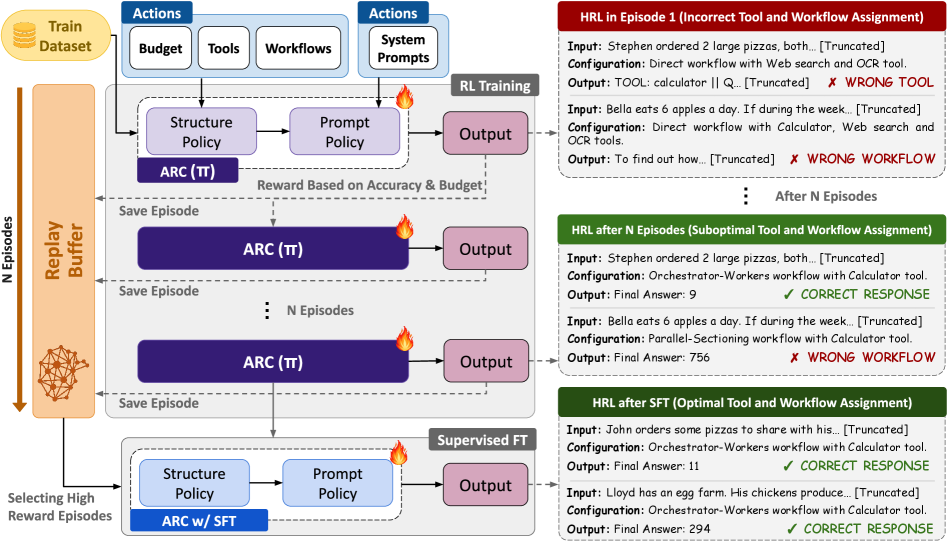
ARC (Query-Adaptive Configuration) utilizes a hierarchical reinforcement learning (HRL) framework to dynamically configure Large Language Model (LLM) agents. This involves structuring the learning process into multiple levels, allowing the agent to learn both high-level strategies for task decomposition and low-level actions for tool use and prompt selection. The hierarchical structure facilitates exploration and learning in complex environments by breaking down the problem into more manageable sub-problems. Specifically, an upper-level policy learns to select sub-goals or workflows, while lower-level policies execute those workflows by interacting with tools and generating prompts. This approach contrasts with traditional LLM applications that rely on pre-defined, static configurations.
ARC enhances Large Language Model (LLM) functionality by moving beyond static configurations to dynamically select optimal reasoning pathways. This is achieved through adaptive selection of workflows – the sequential steps an LLM takes to address a query – and the tools utilized within those workflows. Crucially, ARC also facilitates prompt engineering on a per-query basis, meaning the specific instructions given to the LLM are adjusted to suit the characteristics of each new input. This adaptive approach allows the system to tailor its reasoning process, leveraging different combinations of workflows, tools, and prompts to maximize performance and efficiency for varied query types.
ARC’s dynamic configuration optimizes the reasoning process by tailoring the sequence of operations performed for each incoming query. This is achieved through a learned policy that selects optimal workflows, tools, and prompts based on the specific characteristics of the query. By adapting the reasoning pathway, ARC avoids the limitations of static reasoning chains and can prioritize relevant information and techniques. This query-specific optimization results in improved performance across a range of tasks and enhances the agent’s ability to generalize to previously unseen queries, as the learned policy is not tied to a fixed set of instructions.
Large Language Models (LLMs) traditionally employ a static reasoning process, applying a predetermined sequence of operations regardless of the input query’s complexity or specific requirements. ARC addresses this limitation by introducing a learned, dynamic configuration system. This system allows the LLM agent to adapt its reasoning pathway – including tool selection, workflow orchestration, and prompt formulation – on a per-query basis. Instead of a fixed procedure, ARC employs hierarchical reinforcement learning to learn an optimal policy for configuring the LLM’s reasoning steps, effectively tailoring the approach to maximize performance and generalization across diverse inputs and tasks.
The ARC Policy: Learning to Discern and Adapt
ARC utilizes a reinforcement learning (RL) policy to dynamically determine the optimal configuration for processing each input query. This policy is trained through interaction with an environment that provides feedback on the quality of the chosen configuration. The RL process aims to maximize a defined reward signal, effectively learning a mapping from query characteristics to configuration settings. This allows ARC to adapt its processing pipeline on a per-query basis, potentially improving performance compared to static or pre-defined configurations. The trained policy acts as a function that, given a query, outputs the configuration parameters to be used for subsequent processing steps.
The ARC policy utilizes a state representation derived from the MetaCLIP-H/14 model to analyze incoming queries. MetaCLIP-H/14 is a multimodal model that encodes both textual query information and visual information related to potential configurations into a shared embedding space. This embedding serves as the state representation, capturing key characteristics of the query such as the requested task, desired output format, and any specific constraints. By leveraging this representation, the reinforcement learning policy can effectively generalize across diverse queries and select appropriate configurations without requiring explicit feature engineering. The 14-billion parameter size of MetaCLIP-H/14 contributes to the richness and expressiveness of this state representation, enabling the policy to differentiate between nuanced query variations.
Reward shaping is integral to the reinforcement learning (RL) process, providing intermediate rewards to guide the policy towards desired behaviors and accelerate learning. Without reward shaping, the agent might take a considerably longer time to discover effective configurations due to the sparsity of the final reward signal. The Proximal Policy Optimization (PPO) algorithm is employed as the RL method due to its efficiency and stability in policy updates; PPO constrains policy updates to prevent drastic changes that could destabilize the learning process, ensuring a more consistent and reliable convergence towards an optimal configuration selection policy. This combination of reward shaping and PPO allows for efficient exploration of the configuration space and rapid adaptation to diverse query characteristics.
Following reinforcement learning (RL) training, Supervised Fine-Tuning (SFT) is applied to the ARC policy to enhance both performance and stability. SFT utilizes a dataset of expert demonstrations to further refine the policy’s behavior, correcting potential issues arising from the exploration inherent in RL. This process involves training the policy to mimic the actions of these demonstrations, resulting in improved generalization and a reduction in erratic or unpredictable outputs. The combination of RL for broad capability and SFT for focused refinement leads to a more robust and reliable reasoning policy.
Resourceful Reasoning: Optimizing for Complex Tasks
ARC enhances large language model capabilities by strategically integrating external tools to address intricate sub-problems. Rather than relying solely on the LLM’s pre-existing knowledge, the system dynamically accesses and utilizes specialized tools – such as calculators, search engines, or APIs – to perform specific tasks within a broader reasoning process. This modular approach allows ARC to break down complex challenges into manageable steps, delegating individual computations or information retrieval to the most appropriate tool. By offloading these sub-problems, the LLM can focus on higher-level reasoning and synthesis, leading to more accurate and efficient problem-solving, as evidenced by performance gains on datasets like GSM8K, DROP, and HotpotQA.
The orchestration of complex reasoning relies heavily on selecting the most effective workflow – a carefully determined sequence of steps that guides the problem-solving process. This isn’t merely about listing operations, but about dynamically choosing which tools and strategies to employ, and when to apply them. A well-chosen workflow allows the system to break down a multifaceted problem into manageable sub-problems, directing computational resources towards the most critical areas. By prioritizing steps and intelligently allocating processing power, the system avoids unnecessary computations and minimizes the risk of getting stuck in unproductive loops. This optimized execution not only enhances the accuracy of the final solution but also significantly improves the overall efficiency, allowing the system to tackle complex tasks with greater speed and resourcefulness.
Effective problem-solving with large language models often demands careful distribution of computational resources, and ARC addresses this through dynamic token budget management. This system doesn’t assign a fixed number of tokens to each agent or reasoning step; instead, it intelligently allocates them based on the complexity and necessity of the task at hand. By monitoring the progress and informational content generated at each stage, the system can grant more tokens to agents grappling with challenging sub-problems, and conversely, reduce the allocation for those executing straightforward operations. This granular control ensures that computational effort is focused where it yields the greatest benefit, preventing wasted resources and maximizing the potential for accurate and efficient reasoning – a strategy demonstrably improving performance across multiple benchmark datasets.
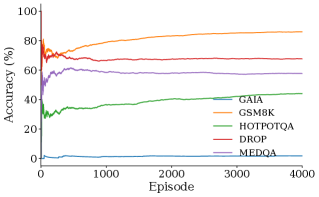
The architecture demonstrably enhances problem-solving capabilities through carefully managed computational resources and strategic workflow orchestration. Empirical results showcase a significant leap in performance, with the system attaining an 88.6% accuracy on the challenging GSM8K dataset – a benchmark for mathematical reasoning. This achievement surpasses the performance of established models like GEPA, which reached 83.6%, and RL Episodes, at 85.2%. This improvement isn’t merely incremental; it represents a substantial advancement in the ability of large language models to tackle complex, multi-step problems, highlighting the power of optimized resource allocation in driving accuracy and efficiency.
Evaluations demonstrate ARC’s substantial gains in complex reasoning tasks, notably achieving a 27.5% performance increase over standard base models on the challenging DROP dataset, which requires reading comprehension and discrete reasoning over paragraphs. Moreover, ARC surpasses existing baseline methods on the HotpotQA benchmark, a multi-hop question answering dataset, by 6.7%, ultimately attaining an accuracy of 34.1%. These results highlight ARC’s capability to effectively synthesize information and perform intricate logical deductions, showcasing its advancement over current state-of-the-art approaches in question answering and reading comprehension.
Recent evaluations demonstrate that ARC achieves a noteworthy 4.0% performance increase over existing baseline models when tested on the GAIA dataset, ultimately attaining an accuracy of 6.0%. This improvement signifies ARC’s enhanced ability to navigate complex reasoning tasks requiring extensive world knowledge and multi-hop inference – challenges inherent in the GAIA benchmark. The dataset, designed to assess a model’s capacity for grounded reasoning and knowledge integration, presents a considerable hurdle for many language models; therefore, this advancement highlights ARC’s effectiveness in leveraging its optimized resource allocation and workflow selection to surpass previous performance levels in this demanding domain.
The pursuit of adaptable agentic systems, as detailed in this work, echoes a fundamental truth about complex systems. It isn’t about imposing rigid control, but fostering an environment where components can learn and evolve. As John von Neumann observed, “There is no possibility of absolute certainty.” This resonates deeply with the ARC framework’s approach to adaptive configuration. The system doesn’t attempt to define the optimal workflow, but rather discovers it through reinforcement learning. It acknowledges the inherent uncertainty and builds resilience not through strict pre-planning, but through iterative refinement and forgiveness of errors as the agent navigates the landscape of possibilities.
The Long Tail of Agency
This work, in its pursuit of adaptive configuration for agentic systems, reveals a familiar pattern. Every new architecture promises freedom until it demands DevOps sacrifices. The elegance of a hierarchical policy, learning workflows and prompts, merely shifts the burden – from static design to dynamic calibration. It doesn’t solve complexity; it externalizes it, creating a new surface for entropy to act upon. The question isn’t whether these systems will fail, but where and when their carefully learned configurations will unravel under unforeseen circumstances.
The true challenge lies not in optimizing for current benchmarks, but in building systems resilient to the inevitable drift of real-world data. Current approaches treat agency as a goal to be achieved, whereas it’s more accurately described as a temporary reprieve from chaos. Order is just a temporary cache between failures. Future work must therefore focus on meta-adaptation – the ability of these systems to learn how to learn, to anticipate their own brittleness, and to proactively seek out novelty as a form of stress-testing.
Ultimately, the long tail of agency won’t be defined by clever workflows or optimal prompts. It will be shaped by the mundane realities of maintenance, monitoring, and the constant struggle against the decay of information. The most successful agentic systems won’t be those that avoid failure, but those that gracefully accommodate it.
Original article: https://arxiv.org/pdf/2602.11574.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-14 19:49