Author: Denis Avetisyan
Researchers have developed a system that allows robots to generate increasingly complex environments and tasks, enabling more robust learning for long-horizon challenges.
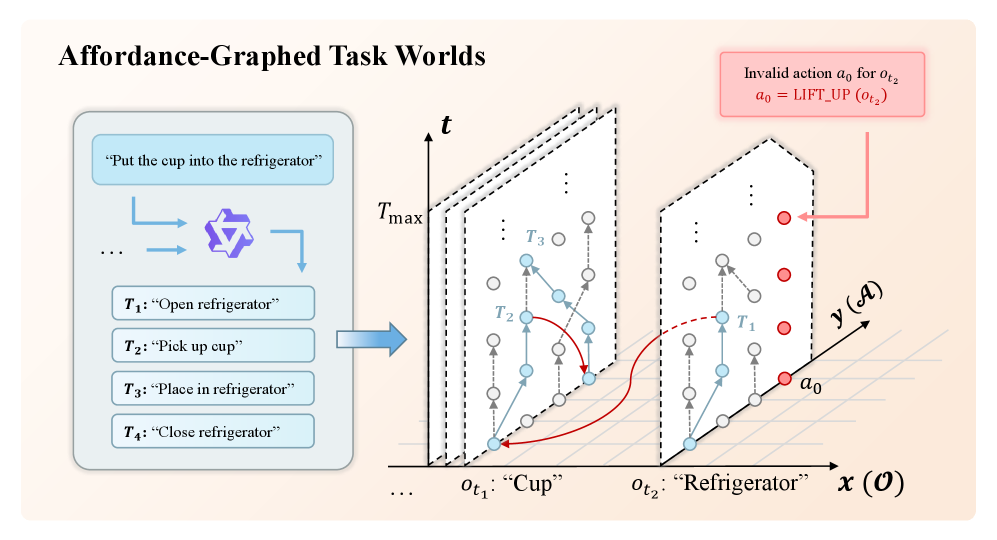
This work introduces AGT-World, a framework combining affordance-aware scene reconstruction and VLM-guided self-evolution to automatically generate interactive simulated environments and scalable robotic policies.
Training robust robotic policies demands extensive data, yet real-world experimentation remains costly and impractical. This limitation motivates the development of simulation-based learning, as explored in ‘Affordance-Graphed Task Worlds: Self-Evolving Task Generation for Scalable Embodied Learning’, which introduces a novel framework for autonomously constructing interactive simulated environments and evolving task policies. By formalizing task spaces as structured graphs of affordances and employing a self-evolution mechanism guided by Vision-Language Models, the approach enables scalable learning of complex, long-horizon tasks. Could this paradigm of autonomously generated and refined task worlds unlock a new era of generalizable robot intelligence?
The Algorithmic Foundation: Defining Task Worlds
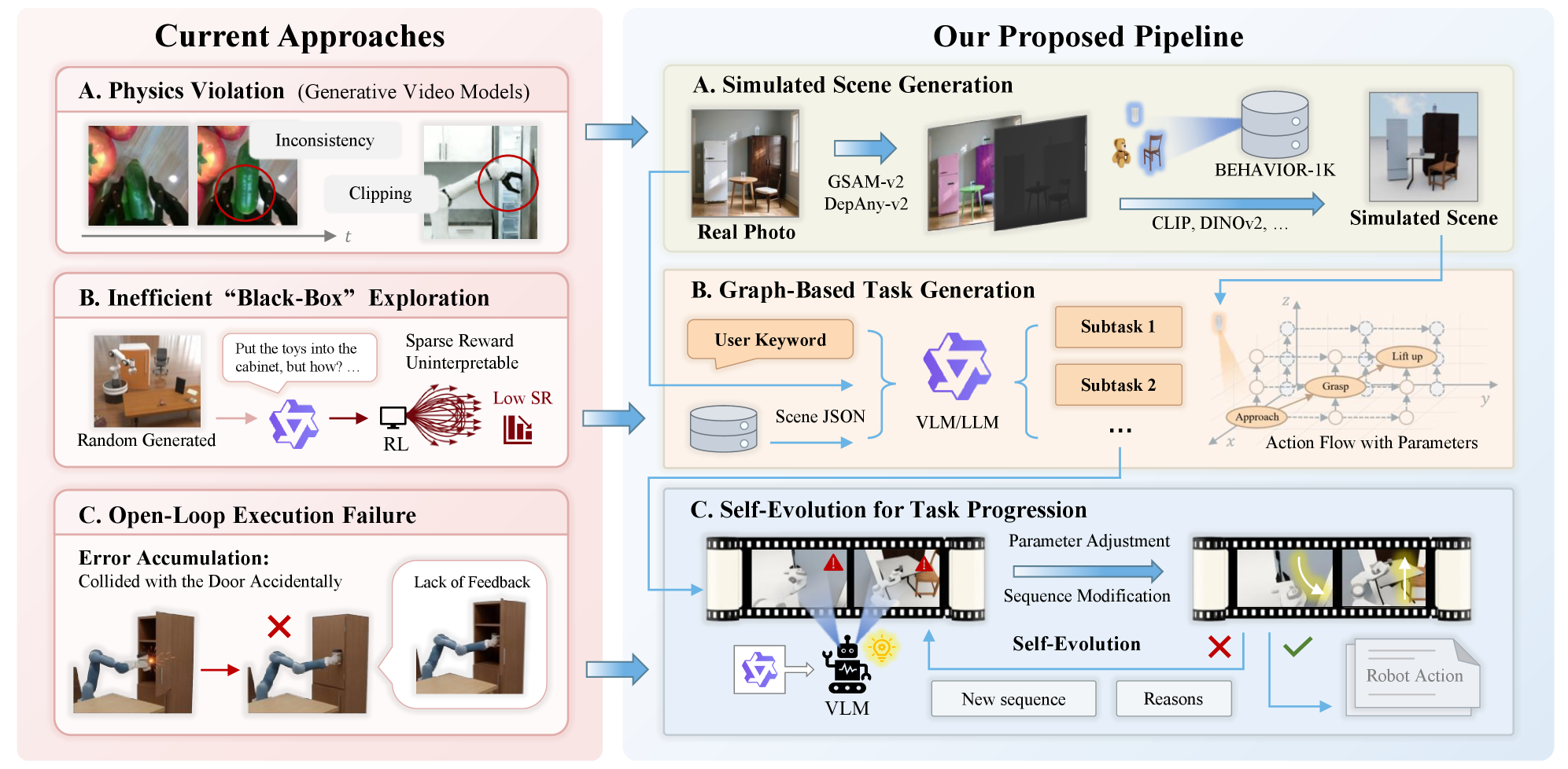
Conventional robotic systems often falter when confronted with tasks demanding extended sequences of actions and adaptability to unforeseen circumstances. This fragility stems from a reliance on meticulously planned trajectories and a limited capacity to recover from deviations or address novel situations. The core issue isn’t necessarily a lack of computational power, but rather the difficulty in creating plans that are both comprehensive enough to cover all potential scenarios and flexible enough to accommodate real-world variability. Consequently, robots frequently exhibit ‘brittle’ behavior – performing reliably in controlled settings but failing dramatically when faced with even minor disturbances or changes in the environment. This limitation hinders their deployment in dynamic, unstructured settings like homes, hospitals, or disaster zones, where predictability is low and adaptability is paramount.
AGT-World establishes a novel framework for robotic task planning centered around the concept of affordance graphs. These graphs map out a task space not as a sequence of actions, but as a network of potential interactions between an agent and its environment. Complex, long-horizon goals are then systematically broken down into smaller, more achievable subtasks by traversing this graph – essentially identifying a series of readily executable actions based on an object’s inherent affordances, or what it allows the robot to do. This decomposition allows for greater flexibility and robustness; should a particular path be blocked, the system can readily re-plan by exploring alternative connections within the affordance graph, leading to more adaptable and scalable robotic problem-solving capabilities.
AGT-World distinguishes itself through a deliberate representation of how objects can be interacted with – their affordances – and how these interactions relate to achieving broader task goals. Rather than treating robotic problem-solving as a singular, monolithic challenge, the framework decomposes complex objectives into a network of interconnected subtasks, each defined by specific object affordances. This granular approach fosters robustness because the system can dynamically adapt to unforeseen circumstances by re-planning at the subtask level, circumventing the fragility inherent in traditional, long-horizon planners. Moreover, the explicit modeling of task relationships facilitates scalability; new tasks can be integrated by defining their constituent affordances and connections to existing subtasks, creating a knowledge base that grows with increasing complexity and enabling robots to tackle progressively more sophisticated challenges.

Constructing Simulated Reality: Environmental Reconstruction
AGT-World employs scene reconstruction algorithms to create 3D environments from captured visual data, specifically leveraging techniques such as Structure from Motion (SfM) and Multi-View Stereo (MVS). These processes generate geometrically accurate models, and crucially, preserve semantic information by associating labels – such as “chair”, “table”, or “door” – with individual objects and surfaces within the reconstructed scene. This semantic tagging is achieved through object recognition algorithms applied to the input imagery, allowing the system to not only represent the visual appearance of the environment but also to understand the functional properties and relationships between objects, which is essential for robotic task planning and simulation.
Realistic robot behavior within AGT-World is achieved through the implementation of a physics engine which governs interactions between the robot and simulated environment. This engine models forces, collisions, and dynamic responses to actions, ensuring that movements and manipulations are subject to physical constraints. Specifically, the system simulates rigid body dynamics, friction, and gravity, allowing for accurate prediction of object behavior and robot stability. The fidelity of this simulation is critical for training robust robotic control policies; policies trained in a physically accurate simulation transfer more effectively to real-world deployment, minimizing the sim-to-real gap and reducing the need for extensive real-world validation.
The AGT-World framework incorporates a semantic layer that allows for reasoning about the characteristics of objects within the simulated environment and the potential actions that can be performed on or with those objects. This is achieved through the assignment of properties – such as size, weight, material composition, and affordances – to each object in the scene. The system then utilizes these properties to predict the outcomes of actions, enabling the robot to plan and execute tasks effectively. For example, the system can determine if an object is graspable, movable, or fragile, influencing the robot’s manipulation strategies. This semantic understanding extends to relational reasoning, allowing the system to infer connections between objects and their roles within the environment, thereby supporting more complex task planning and execution.
Deconstructing Complexity: Hierarchical Task Decomposition
Task decomposition within AGT-World involves a hierarchical breakdown of overarching goals into manageable, executable steps. This process isn’t simply division, but a structured sequence of atomic actions – the smallest, irreducible units of work the agent can perform. The ‘action flow’ defines the order and dependencies between these actions, ensuring a logical progression toward the initial goal. Complex tasks are thus represented as a directed acyclic graph, where each node is an action and edges denote sequential or conditional relationships. This systematic approach allows for precise control and monitoring of the agent’s activities, enabling efficient problem-solving and adaptation to changing circumstances.
BDDL Generation within AGT-World utilizes a formal logic-based approach to define both the starting conditions and desired outcomes for each decomposed subtask. Specifically, Binary Decision Diagrams (BDDs) are constructed to represent these states, enabling a computationally efficient method for verifying task feasibility and planning action sequences. This formal representation clarifies preconditions-the state that must be true before an action can be executed-and postconditions-the state resulting from a completed action. By precisely defining these states, the system can rigorously evaluate potential action plans and select the optimal sequence to achieve the overall goal, while also facilitating error detection and recovery mechanisms.
Affordance, within the AGT-World framework, dictates action selection by evaluating the potential interactions between an agent and its environment. This evaluation is based on the physical properties of objects – such as size, weight, and material composition – and the constraints imposed by the environment itself, including spatial relationships and physical laws. An action is considered permissible only if the object’s properties allow for its successful completion within the given environmental context; for example, a grasp action requires an object to be within reach and of a suitable size and shape. The system thus prioritizes actions that are directly supported by the perceived affordances, ensuring feasibility and efficiency in task execution.
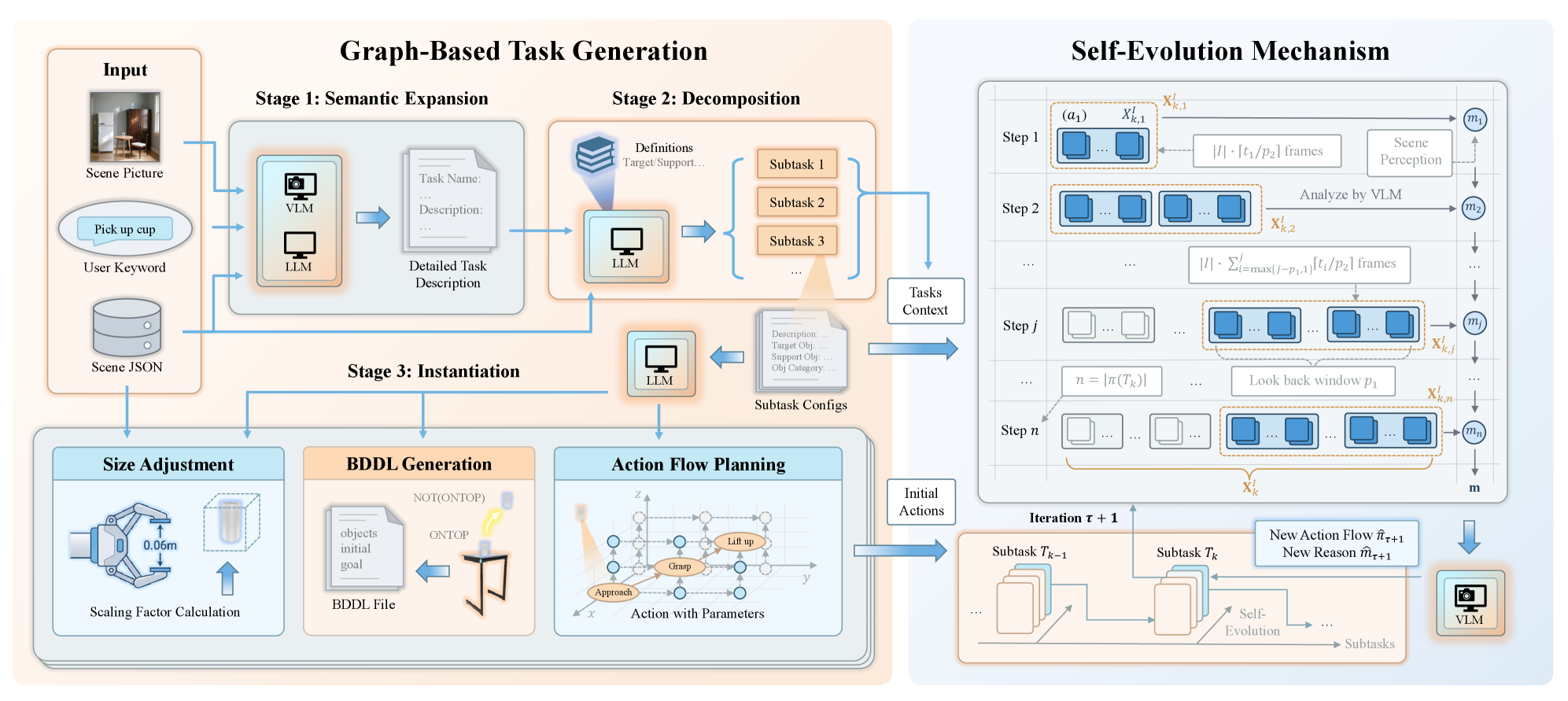
Adaptive Execution: Self-Evolution and Refinement
AGT-World’s self-evolution mechanism operates through continuous monitoring of task execution, enabling the identification of both successful and failed action sequences. This monitoring process isn’t simply pass/fail; it includes detailed logging of environmental states, robot actions, and resulting outcomes. When a failure occurs, the system employs diagnostic routines to pinpoint the root cause, analyzing the preceding actions and environmental factors that contributed to the unsuccessful outcome. This analysis focuses on discrepancies between expected and observed results, utilizing sensor data and internal state estimates to reconstruct the event timeline and isolate the initiating failure point. The identified root causes are then used to inform policy adjustments, facilitating iterative refinement of the robot’s behavior.
VLM-Guided Feedback within AGT-World functions by leveraging a Vision-Language Model to analyze robot actions during execution. This analysis generates critiques of performed actions, identifying areas for improvement based on observed outcomes and the task objectives. These critiques are then translated into actionable suggestions that directly modify the robot’s policy, iteratively refining its behavior. The feedback loop prioritizes adjustments that address identified failures or inefficiencies, allowing the system to learn from its mistakes and enhance performance over time without requiring explicit reprogramming.
Traditional robotic planning typically employs an open-loop system where a pre-defined plan is executed without real-time adaptation to changing conditions. In contrast, AGT-World’s adaptive execution utilizes a closed-loop system, continuously sensing the environment, evaluating the impact of actions, and modifying the execution plan accordingly. This feedback loop enables the system to recover from failures and adjust to unforeseen circumstances, significantly increasing robustness in dynamic and unpredictable environments where pre-planned sequences are likely to be disrupted. The continuous monitoring and iterative refinement inherent in a closed-loop system provide a marked advantage over the rigid nature of open-loop approaches, particularly when operating in real-world scenarios.
![Comprehensive evaluations across diverse real-world scenes demonstrate successful task completion, with performance metrics including cumulative iteration progress, cost distribution per subtask, and ablation studies revealing the importance of both camera views and historical context [latex]p1p\_{1}[/latex] for maximizing success rate when utilizing the Qwen3-VL model.](https://arxiv.org/html/2602.12065v1/figure/combined_results.png)
Towards Autonomous Agents: Impact and Future Directions
AGT-World represents a significant step forward in robotic autonomy by uniquely integrating two key components: affordance-graphed task worlds and adaptive execution. Traditional robotic systems often struggle with unpredictable environments and require precise programming for each specific task. This framework overcomes these limitations by representing environments as graphs of potential actions – affordances – allowing the robot to understand what is possible within a scene. Crucially, AGT-World doesn’t just plan a sequence of actions; it adapts its execution in real-time based on sensory feedback and unexpected changes. This combination enables robots to navigate complex, dynamic situations and successfully complete tasks even when faced with unforeseen obstacles or variations, effectively bridging the gap between simulated planning and robust real-world performance.
Recent evaluations of the AGT-World framework reveal a noteworthy advancement in robotic autonomy, achieving a 71.6% success rate across a diverse set of challenges. This performance was established through rigorous testing on 102 autonomously generated scene-task pairs, meaning both the environments and the objectives were created algorithmically, ensuring a broad and unbiased assessment. This result isn’t simply a matter of optimized performance on pre-defined scenarios; the framework demonstrates a capacity to adapt and successfully complete tasks in previously unseen conditions, suggesting a genuine step towards more robust and versatile robotic systems. The success rate represents a substantial improvement over existing methods and highlights the potential of combining affordance-graphed task worlds with adaptive execution for reliable autonomous task completion.
The AGT-World framework distinguishes itself through a design prioritizing adaptability and broad applicability. Rather than being rigidly programmed for specific scenarios, the system leverages a modular architecture where components representing perception, planning, and action are loosely coupled and operate on semantic representations of the environment. This allows the robot to interpret new situations not as entirely unfamiliar, but as variations on previously understood concepts – a table remains a table, even in a different room. Consequently, the framework exhibits a capacity to generalize beyond its training data, successfully tackling novel environments and tasks without requiring extensive reprogramming. This reliance on semantic understanding, where the meaning of objects and actions is prioritized over precise geometric data, is key to the system’s robust performance and its potential for deployment in dynamic, real-world settings.
Continued development of the AGT-World framework prioritizes expanding its capabilities to navigate increasingly intricate environments and tasks. Researchers aim to move beyond current limitations by integrating sophisticated perception modules – allowing the system to better interpret raw sensory data – and advanced learning algorithms, such as reinforcement learning and meta-learning. This integration will not only improve the robot’s ability to adapt to unforeseen circumstances but also facilitate the acquisition of new skills through experience, paving the way for truly autonomous operation in dynamic, real-world settings. The ultimate goal is a system capable of seamlessly transitioning between tasks and environments without requiring explicit reprogramming, demonstrating a significant leap towards general-purpose robotic intelligence.

The pursuit of robust robotic policies, as demonstrated by the AGT-World framework, necessitates a commitment to provable correctness. The system’s capacity for self-evolving tasks, guided by visual language models and affordance-aware reconstruction, mirrors a dedication to building solutions founded on logical principles. As Barbara Liskov aptly stated, “Programs must be correct, not just work.” This principle resonates deeply with the AGT-World approach; the framework isn’t merely focused on achieving task completion, but on establishing a system capable of generating and adapting to increasingly complex scenarios through a demonstrably reliable process-a system built on a foundation of logical evolution, not empirical observation alone.
What’s Next?
The presented framework, while demonstrating a capacity for automated environment generation and policy evolution, ultimately highlights the persistent chasm between simulated ingenuity and genuine robotic competence. The reliance on Visual Language Models (VLMs) introduces a fascinating dependency – the system’s ‘understanding’ of task affordances is, inescapably, a statistical approximation of human linguistic biases. The elegance of automated task creation is, therefore, tempered by the imprecision inherent in natural language processing. Future iterations must grapple with verifying the correctness of generated tasks, rather than merely assessing performance on them.
A critical limitation remains the implicit assumption of a shared semantic space between the VLM, the environment generator, and the embodied agent. This risks a cascade of errors, where linguistic ambiguity translates into physically unrealistic scenarios, and subsequently, into policies optimized for a distorted world. The pursuit of ‘scalability’ should not eclipse the need for formal verification of both the simulated physics and the derived task objectives. A provably correct environment, even a simple one, possesses an inherent advantage over a complex, heuristically validated one.
The long-horizon tasks addressed here represent a step towards more adaptable robotics, but the ultimate test lies in confronting the inherent unpredictability of the real world. True robustness will not be achieved through increasingly sophisticated simulation, but through algorithms capable of detecting and correcting errors in their own assumptions – a capacity for self-diagnosis, rather than merely self-evolution. The goal should not be to generate complexity, but to master it through principled reasoning.
Original article: https://arxiv.org/pdf/2602.12065.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-14 16:51